- Keyword
- GitHub Code
- 最初の一歩として、シンプルな問題を設定する
- 各エージェントの観測量(Observation)
- 各エージェントの報酬設計(マルチエージェント強化学習では、これが難しい)
- 各エージェントのアーキテクチャ
- まとめ
Keyword
Swarm, Company, Platoon, Autonomous, Mass, Consolidation of force, Economy of force, Multi-agent, Reinforcement learning, Lanchester combat model, DenseNet, ResNet, PPO
群、小隊、中隊
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
最初の一歩として、シンプルな問題を設定する
いきなり複雑な問題にあたる前に、まずはシンプルな問題設定で解いてみて、解決の見通しについて感触を得てみようと思います。このため、以下の仮定を置いて問題をシンプルにしました。なお、海兵隊の研究と同様に、我が Red team、彼が Blue team としています。
- 戦域は、10x10のグリッドとする。(少し小さいですが、海兵隊の研究も同サイズで実施していました)。
- Red team, Blue team の戦闘効率(Efficiency)は同じとする。また、戦闘における確率的要素はないものとします。したがって、兵力(Force、軍の構成メンバー数)のみが勝敗に影響することになります。
- 学習が上手くいけば必ず Red team が勝利できるよう、以下の兵力関係を仮定する(学習が上手く行くいったことが確認できるようにするための仮定です):
Red team の兵力の合計 > Blue teamの兵力の合計
- Blue team は静止しているものとします。
- 各エージェントの観測は、部分観測ではなく、マップ全体とします。(部分観測マルコフ過程になることを避けるための仮定です)。
- マップの情報は100%正確で、ノイズは無いものとします。
- 環境は均一で、障害物などは無いものとします。
- 全エージェントは、同一のニューラルネット・アーキテクチャと重みを共有するものとします。それでも、各エージェントに与えるマップ情報が異なる(自群位置が異なる)ので、エージェントは異なった行動を示すことになります。さらに、今回は、自身の特徴量(ForceとEfficiency)もマップでそれぞれ与えているため、仮に同じ位置に複数のエージェントが位置しても、エージェント毎に異なる振る舞いをすることになります。つまり、エージェントは、構造的には互いに均質(Homogeneous)ですが、性格的には異質(Heterogeneous)なものとなります。
その他:
- 1回のタイムステップでの経過時間は1とする。つまり、Lanchester model の Δt=1 です。(この場合、微分方程式では近似できません)。
- シミュレーションの最大ステップ数=100。最大ステップに達した段階で勝負がついていなければ、戦闘結果はドローで打ち切ります。
各エージェントの観測量(Observation)
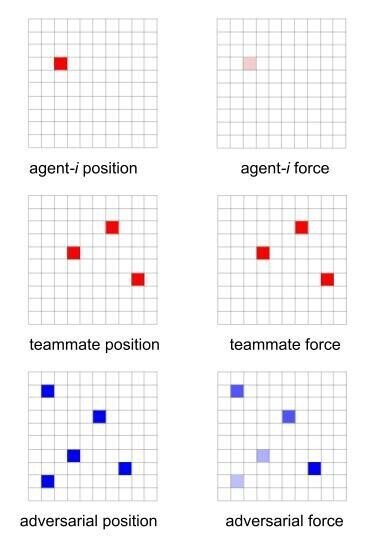
各エージェントのObservationは、シンプルに以下の6マップとします。
- 自群位置、自群兵力(Force)
- 友群位置、友群兵力(Force)
- 敵群位置、敵群兵力(Force)
彼我の群の戦闘効率はすべて同じなので、戦闘効率のマップは不要と考え省略します。障害物などは何もない環境なので、環境マップも不要と考え省略します。
従って、各タイム・ステップでエージェントに与えられる情報は下図の6チャンネルとなります。位置のマップについては、同一マスに複数エージェントがいる場合、以下の式で [0,1] の範囲になるように正規化しました:
position map =
そのマスにいるエージェントの数 / 現在のエージェント総数
同様に、兵力(Force)も、[0, 1] の範囲になるように正規化しました:
force map =
そのマスにいるエージェントのforce合計 / 全エージェントの初期兵力(Force)
これは、コードで書くと以下となります。Observationは、エージェント毎に辞書として定義しています。
def get_observation_5(env):
observation = {}
for i in range(env.num_red):
if env.red.alive[i]:
my_matrix = np.zeros((env.grid_size, env.grid_size))
teammate_matrix = np.zeros((env.grid_size, env.grid_size))
adversarial_matrix = np.zeros((env.grid_size, env.grid_size))
my_matrix_pos = np.zeros((env.grid_size, env.grid_size))
teammate_matrix_pos = np.zeros((env.grid_size, env.grid_size))
adversarial_matrix_pos = np.zeros((env.grid_size, env.grid_size))
# my position & force map
my_matrix_pos[env.red.pos[i][0], env.red.pos[i][1]] += 1
my_matrix[env.red.pos[i][0], env.red.pos[i][1]] += env.red.force[i]
# teammate position & force map
teammate_id = [j for j in range(env.num_red) if j != i]
for j in teammate_id:
if env.red.alive[j]:
teammate_matrix_pos[env.red.pos[j][0], env.red.pos[j][1]] += 1
teammate_matrix[env.red.pos[j][0], env.red.pos[j][1]] += env.red.force[j]
# Don't care because env.red.force[j]=0 if not env.red.alive[j]
# adversarial position & force map
for j in range(env.num_blue):
if env.blue.alive[j]:
adversarial_matrix_pos[env.blue.pos[j][0], env.blue.pos[j][1]] += 1
adversarial_matrix[env.blue.pos[j][0], env.blue.pos[j][1]] += env.blue.force[j]
# Don't care because env.blue.force[j]=0 if not env.blue.alive[j]
# stack the maps
my_matrix_pos = np.expand_dims(my_matrix_pos, axis=2)
my_matrix = np.expand_dims(my_matrix, axis=2)
teammate_matrix_pos = np.expand_dims(teammate_matrix_pos, axis=2)
teammate_matrix = np.expand_dims(teammate_matrix, axis=2)
adversarial_matrix_pos = np.expand_dims(adversarial_matrix_pos, axis=2)
adversarial_matrix = np.expand_dims(adversarial_matrix, axis=2)
# normalize the maps
my_matrix = my_matrix / env.max_force
teammate_matrix = teammate_matrix / env.max_force
adversarial_matrix = adversarial_matrix / env.max_force
# Normalize teammate_matrix_pos & adversarial_matrix_pos by current number of agents
teammate_matrix_pos = teammate_matrix_pos / np.sum(env.red.alive)
adversarial_matrix_pos = adversarial_matrix_pos / np.sum(env.blue.alive)
obs = np.concatenate([my_matrix_pos, my_matrix,
teammate_matrix_pos, teammate_matrix,
adversarial_matrix_pos, adversarial_matrix], axis=-1)
observation['red_' + str(i)] = obs.astype(np.float32)
return observation
各エージェントの報酬設計(マルチエージェント強化学習では、これが難しい)
マルチエージェント強化学習で難しいのは、エージェントに与える報酬設計です。
例えば、red team は (490, 20) という兵力を有する2エージェント(2群)で構成され、Blue team は 500 の兵力を有する1エージェントで構成されている初期条件を考えます。(彼我の群の戦闘効率は同じとします)。
この時、Lanchester model によれば、red team が勝つためには、兵力20の群が、兵力490 の群と一丸になって(つまり、510 の兵力となって)blue teamに当たることが必須です。しかしながら、兵力 20 の群は弱小なので戦いの途中で消耗し殲滅されてしまいます。この場合、通常の強化学習の枠組みでは、ゲームの勝敗に応じて報酬が与えられるため、兵力 20 の群には、負の報酬(ペナルティ)が与えられることになります。この結果、小さな兵力の群は戦闘に参加しない方向に学習してしまいます。しかし、実際には、チームの勝利のためには、この小さな群の犠牲が必須なので、正の報酬(ご褒美)を与える必要があります。多数エージェントと多数エージェントが、戦域のあちらこちらで戦闘する場合、話はもっと複雑になるので、いつ正の報酬を与え、いつ負の報酬を与えればよいのか訳が分からなくなります。このため、マルチエージェント強化学習では、普通の強化学習以上に、報酬設計を考える必要があります。
色々と試行錯誤して、戦闘の勝敗で報酬を与えるのではなく、大きな敵の "mass" に、大きな "mass" でぶつかった場合に、その "mass" の大きさに応じて報酬を与えることにしました。これは、前記の海兵隊の研究、海兵隊教本(MCDP "1-0 Operations")、ランチェスター・モデルの分割戦略から試行錯誤で考案しました。背景にあるアイデアは、「確率的要因が無い場合、勝敗の結果は、戦闘が行われているグリッドでの彼我の "mass" のサイズで決まる(戦う前に勝負は決まっている)」です。
具体的には、タイムステップ t で、以下の式でグリッド (i, j) に位置するRed teamエージェントに報酬を与えました。"*100"は、報酬の大きさが適当になるように設定した係数です。(もう少し、小さいほうが良かったかもしれません)。
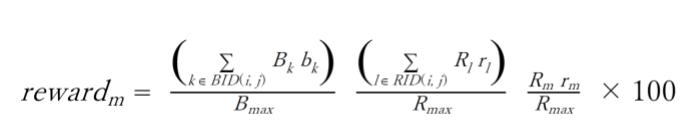
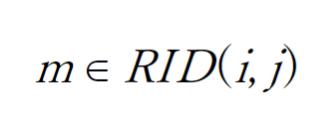
where
- BID(i, j):グリッド (i, j) に位置する Blue team のエージェントの ID
- RID(i, j):グリッド (i, j) に位置する Red team のエージェントの ID
- Bk: Blue team のエージェント k の force
- bk: Blue team のエージェント k の efficiency
- Rl: Red team のエージェント l の force
- rl: Red team のエージェント l の efficiency
- Bmax: Blue team のエージェントの初期 force の合計
- Rmax: Red team のエージェントの初期 force の合計
上式右辺で、
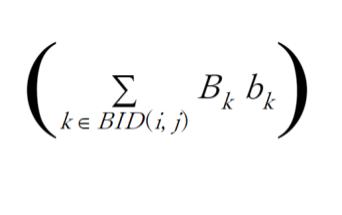
が、グリッド (i, j) に位置する Blue team エージェントの戦闘力('mass')= 兵力 x 武器性能 = force x efficiency の合計、
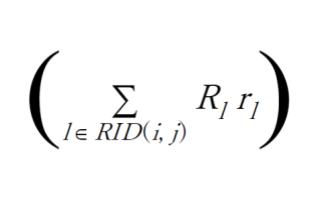
が、グリッド (i, j) に位置する Red team エージェント 闘力('mass')= 兵力 x 武器性能 = force x efficiency の合計に対応します。また、戦闘に参加したエージェントへの報酬配分は、
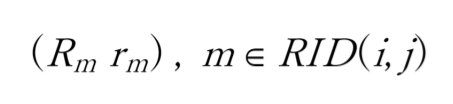
に従って与えます。これは、グリッド (i, j) での戦闘に参加した Red team エージェントの戦闘力 ('mass')に比例して報酬配分していることになります。したがって、大きな 戦闘力('mass') を提供するエージェントほど大きな報酬を受け取りますが、小さな戦闘力('mass')しか提供しないエージェントでも、戦闘力を提供する限りは応分の報酬を受け取ることになります。
あるグリッドにおけるチーム戦闘という観点でこの報酬を見ると、1つのグリッドに沢山のエージェントが集まって、強力な敵に当たり続けるほど大きな報酬を受け取ることになります。つまり、'mass' を重視し、(重要と思われる) 'mass' の大きな敵に当たる戦術を採るほど大きなチーム報酬を得ることになります。
また、戦闘の勝敗を報酬として与えた場合、1エピソードの最後に1回だけ報酬を与えることになりますが、この報酬は、各タイムステップで与えることが出来ます。従って、学習効率の向上も期待できます。
前記の海兵隊の研究でも、(少し違う形ですが)同じような考え方で報酬を与えた場合を検討していました。
また、戦闘を長引かせないインセンティブを各エージェントに与えるために、上記の報酬に加えて、各タイムステップで、全エージェントに -0.1 のペナルティ(負の報酬)を追加で与えました。
一方、チームとしての勝敗結果についての報酬ですが、チームとしての勝敗は各タイムステップでの戦闘力の大小で決定論的に決まるので、チームとしての勝敗結果についての報酬は与える必要が無いと考えました。
以上から、Red team全体としては、次の目的函数を最大化するようにトレーニングされることになります。E[・] は期待値(Expectation)です。
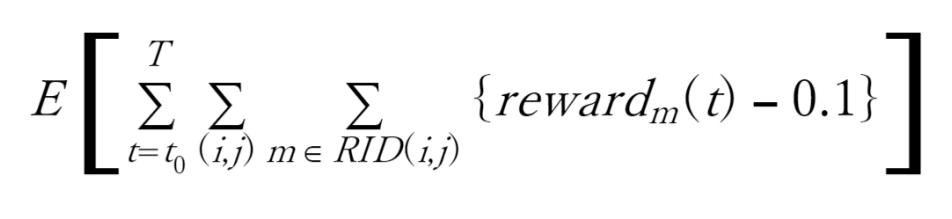
或いは、将来の曖昧さを割引率γで考慮した次の目的函数を最大化するようにトレーニングされることになります。
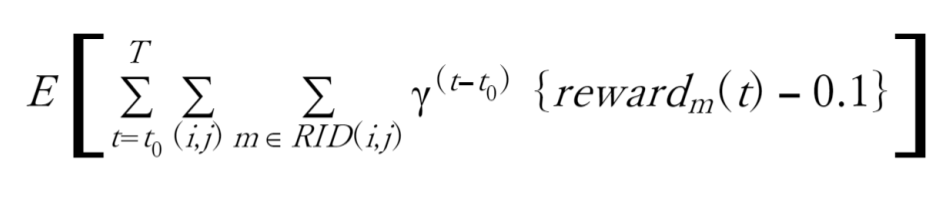
これをコード化した報酬が下記のコードです。
戦闘に参画している限り、提供できる戦闘力がどんなに少なくても最低 1.1 の報酬を与えることにしました(試行錯誤で決めました)。
def get_reward_8C(env, red_team_force, previous_red_team_force, blue_team_force, previous_blue_team_force,
red_team_efficiency, blue_team_efficiency):
# 8Bの足切り 0.5 → 1.1
blue_size = np.sum(previous_blue_team_force * blue_team_efficiency)
red_size = np.sum(previous_red_team_force * red_team_efficiency)
red_reward = (blue_size / env.blue_max_force) * (red_size / env.red_max_force) \
* (previous_red_team_force * red_team_efficiency) / env.red_max_force * 100
# red_reward = (blue_size / env.blue_max_force) * (red_size / env.red_max_force) \
# * (previous_red_team_force * red_team_efficiency) / env.red_max_force * 100 * 3
# red_reward = np.maximum(red_reward, 0.1 / env.dt * 0.5)
red_reward = np.maximum(red_reward, 1.1)
return red_reward
各エージェントのアーキテクチャ
グリッド状のゲームの代表例は、囲碁、将棋、チェスです。これらを統一的に取り扱ったのが有名な AlphaZero や MuZero です。これらでは、MCTS(モンテカルロ木探索)とニューラ ルネットを組み合わせて盤面から状況を認識し、行動決定しています。盤面を認識するニューラルネットには、ResNet(をベースとしたもの)が用いられています。DeepMind は、ResNet が好きなようで、AlphaStar でも使っています。
画像の認識では、ResNet は確かに重要な一つの選択肢なのですが、本件では、多数の異なるマップとしての画像を取り扱うので、CVPR-2017 で Best paper award を取った DenseNet の方が適当と考え、使ってみることとしました。とは言え、本件はチェスと考え方は似ているので、ResNet も実装して、比較してみる必要があると思います。ただ、DenseNet も ResNet もオリジナルはとても深いネットワークなので、私のビンテージマシンを使って強化学習で最適化するには、かなり浅めのネットワークにする必要があります。したがって、正しい比較のためには、それぞれを最適化したうえで比較しないと意味がないので、計算リソースに余裕がない私としては見送らざるを得ませんでした。(学習済みの DenseNet や ResNet を転移させる方法もあるのですが、マップサイズを(224, 224, 3)等の特定のサイズに変換する必要があるため、不整合が起きそうな気がしたので今回は使用しませんでした)。
また、人間は、行動を考えるにあたって、与えられたマップを統合したり、新たなマップを作成するのが普通です。この働きをさせるために、入力マップと DenseNet の間に 1x1 Convolution 層を挿入しました。(オリジナルの DenseNet では、ここは MaxPooling を使っています。リソースが無いので、オリジナルとの比較はしていません。ゴメンナサイ)。これにより、入力された6枚のマップ(チャネル)から、同じサイズの多数(とりあえず32枚と設定しました。根拠はありません)のマップ(チャネル)を生成し ResNet に入力することとしました。ここで、どのようなマップが自動生成されるのかは非常に興味があります。
AlphaZero や MuZero では、過去数手の盤面も入力としていますが、さしあたっては、問題がシンプルなので、現在の状態を示すマップのみの入力でそれなりに行けるはずと考え、履歴情報の入力は無いものとしました。他エージェントの意図を察するためには、他エージェントの動きの履歴(= 過去の盤面)が必要なので、履歴情報を使うことで性能が向上する可能性はあると思っています。あるいは、network をリカレント型にしたり、Transformer 形にしたりしてシーケンス・データを取り扱うことで、履歴情報をエージェントの内部に埋め込む方法もあります。これらの方法は非常に興味深いのですが、一般的には、性能向上と引き換えに学習時間が猛烈に増大するので、後回しにしました。
以上を踏まえ、最初の一歩の Agent Architecture は下図としました。1x1 Convolution 以外は、Policy network と Value network の重み共有はしない形としました。一般論としては、「Policy network と Value network は、一部重み共有した方が汎化能力が高くなる」と、どこかで読んだことがあるのですが、何処まで共有するのかという問題があるので、まずはシンプルな設定として極端な形でやってみることにしました。FC は全結合(Full Connection)層、π(a|s) はポリシー出力(アクション)、v(s) は value 出力を表します。
アーキテクチャの意図は、Shared 1x1 Conv から DenseNet までが「戦況の認知系」、DenseNet 出力が、エージェントが認知した戦況全体(Big picture)や、その中で自分が置かれた状況等の「戦況コンテキスト(Context)が集約された表現(Representation)」、FCが戦況コンテキストからアクションを生成する「行動決定系」です。また、価値函数V(s)は、「現在の戦況 s の良し悪しの程度」の推定値、π(a|s) は現在の戦況 s におけるエージェントの行動選択確率です。
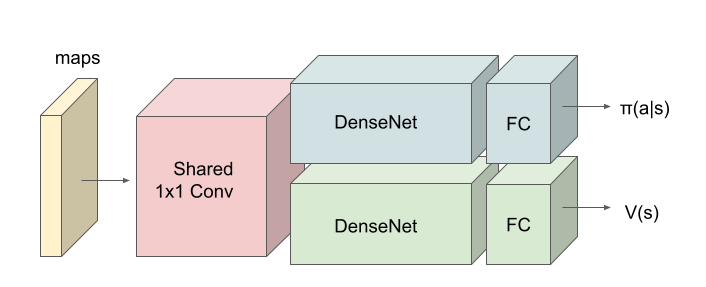
具体的には、エージェントは次のアーキテクチャとしています。問題に対して、ネットが深すぎるような気はしたのですが、将来、マップサイズを大きくすることも想定して、深めに設定しました。
DenseNet のブロック数、成長率(Growth factor)、圧縮率(Compression factor)、フィルタ数等のハイパラは気分だけで決めました。したがって、最適化の余地は多分にあります。
最下段にある Dense 層は全結合(FC)層のことです。(Tensorflow では、全結合層を Dense layer と呼んでいます。DenseNet のことではありませんので、混同しないでください)。
また、最下段の全結合層(Dense 層)の前で、普通は画像から Flatten( ) で、チャンネル内の個々の画像を1次元アレイに変換することが多いのですが、DenseNet では、GlobalAberagePooling2D( ) で1次元アレイに変換します。これは、DenseNet では、チャンネル単位で積層するため、ここもチャンネル毎のサマリーを取得するのが適当との考え方に依ります。実際には、 Flatten( ) の方が良いのか、GlobalAberagePooling2D( ) の方が良いのかはやって見ないと分かりません。これは性能に対しインパクトがありそうなのですが、確認に時間がかかるので省略しました。
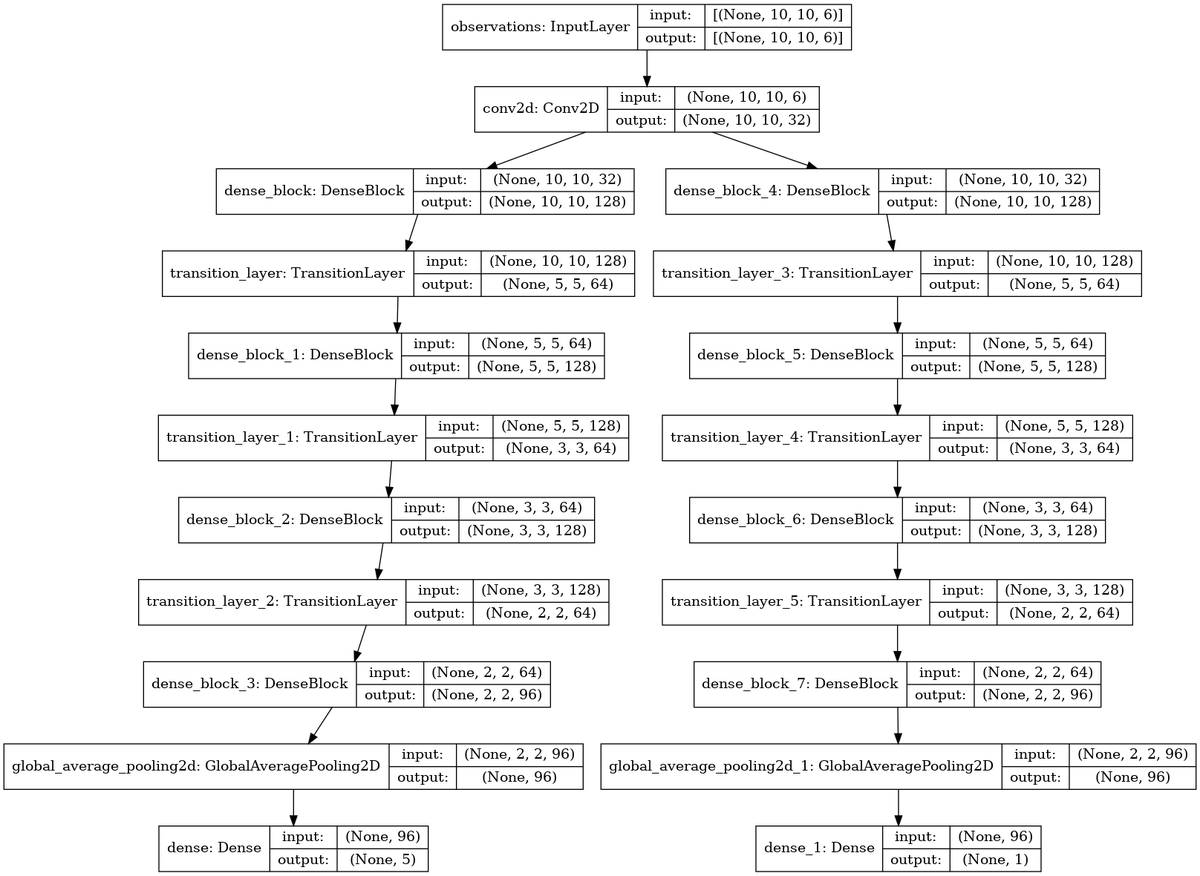
トレーニング可能なパラメータ数は、798,118です。
以上は、コードで書くと下記となります。DenseNet の構成要素となる Dense ブロック、Transition 層は、適当に設定しました(最適化は、全くしていません)。
コーディングは、
Custom DenseNet of Tensorflow2.0 - Programmer Sought を参考にしました。
Bottleneck 層は、基本ブロックで、特徴量マップを追加します。
class Bottleneck(Model):
def __init__(self, growth_facotr, drop_rate):
super(Bottleneck, self).__init__()
self.bn1 = BatchNormalization()
self.av1 = Activation('relu')
self.conv1 = Conv2D(filters=4 * growth_facotr,
kernel_size=(1, 1),
strides=1,
padding='same')
self.bn2 = BatchNormalization()
self.av2 = Activation('relu')
self.conv2 = Conv2D(filters=growth_facotr,
kernel_size=(3, 3),
strides=1,
padding='same')
self.dropout = Dropout(rate=drop_rate)
self.list_layers = [self.bn1,
self.av1,
self.conv1,
self.bn2,
self.av2,
self.conv2,
self.dropout]
def call(self, x):
y = x
for layer in self.list_layers:
y = layer(y)
y = Concatenate(axis=-1)([x, y])
return y
DenseBlock 層は、基本ブロックである Bottleneck を積層したものです。
class DenseBlock(Model):
def __init__(self, num_layers, growth_factor, drop_rate):
super(DenseBlock, self).__init__()
self.num_layers = num_layers
self.growth_factor = growth_factor
self.drop_rate = drop_rate
self.list_layers = []
for _ in range(num_layers):
self.list_layers.append(Bottleneck(growth_facotr=self.growth_factor,
drop_rate=self.drop_rate))
def call(self, x):
for layer in self.list_layers:
x = layer(x)
return x
Transition 層は、チャネル数とマップサイズを圧縮する層です。
class TransitionLayer(Model):
def __init__(self, out_channels):
super(TransitionLayer, self).__init__()
self.bn = BatchNormalization()
self.av = Activation('relu')
self.conv = Conv2D(filters=out_channels,
kernel_size=(1, 1),
strides=1,
padding='same')
self.avgpool = AveragePooling2D(pool_size=(2, 2),
strides=2,
padding='same')
self.list_layers = [self.bn,
self.av,
self.conv,
self.avgpool]
def call(self, x):
for layer in self.list_layers:
x = layer(x)
return x
DenseNet 本体です。DenseNetは、DenseBlock と Transition 層を交互に積層したものですので、特徴量マップを追加し圧縮する作業を繰り返します。最後に、GlobalAveragePooling2D で各特徴量マップを代表させます。この代表特徴量から、全結合層を通してポリシー π(a|s) と価値函数 V(s) を予測します。
class DenseNetModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs, Model_config, name):
super(DenseNetModel, self).__init__(obs_space, action_space, num_outputs, Model_config, name)
num_init_features = 16
growth_factor = 16
block_layers = [2, 2, 2, 1]
compression_factor = 0.5
drop_rate = 0.2
# First convolutin + batch normalization + pooling
self.conv = Conv2D(filters=num_init_features,
kernel_size=(1, 1),
strides=1,
padding='same')
### Policy net
# DenseBlock 1
self.pol_num_channels = num_init_features
self.pol_dense_block_1 = DenseBlock(num_layers=block_layers[0],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 1
self.pol_num_channels += growth_factor * block_layers[0]
self.pol_num_channels *= compression_factor
self.pol_transition_1 = TransitionLayer(out_channels=int(self.pol_num_channels))
# DenseBlock 2
self.pol_dense_block_2 = DenseBlock(num_layers=block_layers[1],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 2
self.pol_num_channels += growth_factor * block_layers[1]
self.pol_num_channels *= compression_factor
self.pol_transition_2 = TransitionLayer(out_channels=int(self.pol_num_channels))
# DenseBlock 3
self.pol_dense_block_3 = DenseBlock(num_layers=block_layers[2],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 3
self.pol_num_channels += growth_factor * block_layers[2]
self.pol_num_channels *= compression_factor
self.pol_transition_3 = TransitionLayer(out_channels=int(self.pol_num_channels))
# Dense Block 4
self.pol_dense_block_4 = DenseBlock(num_layers=block_layers[3],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Output global_average_pooling + full_connection
self.pol_avgpool = GlobalAveragePooling2D()
self.pol_fc = Dense(units=5, activation=None)
# Define policy model
inputs = Input(shape=obs_space.shape, name='observations')
conv1_out = self.conv(inputs)
x = self.pol_dense_block_1(conv1_out)
x = self.pol_transition_1(x)
# x = self.pol_dense_block_2(x)
# x = self.pol_transition_2(x)
# x = self.pol_dense_block_3(x)
# x = self.pol_transition_3(x)
x = self.pol_dense_block_4(x)
x = self.pol_avgpool(x)
pol_out = self.pol_fc(x) # (None, 5)
### Value net
# DenseBlock 1
self.val_num_channels = num_init_features
self.val_dense_block_1 = DenseBlock(num_layers=block_layers[0],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 1
self.val_num_channels += growth_factor * block_layers[0]
self.val_num_channels *= compression_factor
self.val_transition_1 = TransitionLayer(out_channels=int(self.val_num_channels))
# DenseBlock 2
self.val_dense_block_2 = DenseBlock(num_layers=block_layers[1],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 2
self.val_num_channels += growth_factor * block_layers[1]
self.val_num_channels *= compression_factor
self.val_transition_2 = TransitionLayer(out_channels=int(self.val_num_channels))
# DenseBlock 3
self.val_dense_block_3 = DenseBlock(num_layers=block_layers[2],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 3
self.val_num_channels += growth_factor * block_layers[2]
self.val_num_channels *= compression_factor
self.val_transition_3 = TransitionLayer(out_channels=int(self.val_num_channels))
# Dense Block 4
self.val_dense_block_4 = DenseBlock(num_layers=block_layers[3],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Output global_average_pooling + full_connection
self.val_avgpool = GlobalAveragePooling2D()
self.val_fc = Dense(units=1, activation=None)
# Define value model
y = self.val_dense_block_1(conv1_out)
y = self.val_transition_1(y)
# y = self.val_dense_block_2(y)
# y = self.val_transition_2(y)
# y = self.val_dense_block_3(y)
# y = self.val_transition_3(y)
y = self.val_dense_block_4(y)
y = self.val_avgpool(y)
val_out = self.val_fc(y) # (None, 1)
self.base_model = Model(inputs, [pol_out, val_out])
self.register_variables(self.base_model.variables)
def forward(self, input_dict, state, seq_lens):
obs = input_dict['obs']
model_out, self._value_out = self.base_model(obs) # (None,5), (None,1)
return model_out, state
def value_function(self):
return tf.reshape(self._value_out, [-1])
まとめ
手始めに解いてみて感触を得るのに手ごろな問題を設定し、報酬やエージェント・アーキテクチャを設計しました。
次回は、マルチエージェント強化学習を行って性能確認します。