- GitHub Code
- 実施内容
- 実行環境
- シミュレーション条件
- トレーニング履歴
- 性能評価
- 生成された戦術
- ロバスト性(汎化能力)
- 生成された戦術例
- 少数群vs少数群で訓練した結果との比較、及び将来の発展性
- まとめ
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
(その3)とは逆方向に検討を行います。すなわち、
- はじめに、Red teamの初期エージェント数(群数)を [7, 8]、Blue teamの初期エージェント数(群数)を [6 ,7] として、多数群 vs 多数群の設定で共有ネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、各チームのエージェント数(群数)を増減して戦闘性能がどう変化するのか評価します。
- (その3)の「少数群 vs 少数群」で訓練した結果と比較し、夫々のトレーニング形態の特徴を分析します。併せて、これらを元に、将来の発展性について考えます。
実行環境
- (その3)と同じ
PPOハイパーパラメータ
- (その3)と同じ
シミュレーション条件
- (その3)と同じ
トレーニング履歴
縦軸は平均エピソード報酬、横軸が更新ステップです。
グラフの途中で色が変わり、一部グラフが重なっているのは、前実験と同じく GCP のPreemptive vm が最大24時間で強制シャットダウンされるため、シャットダウン後、保存したチェックポイントから継続学習を行っているためです。
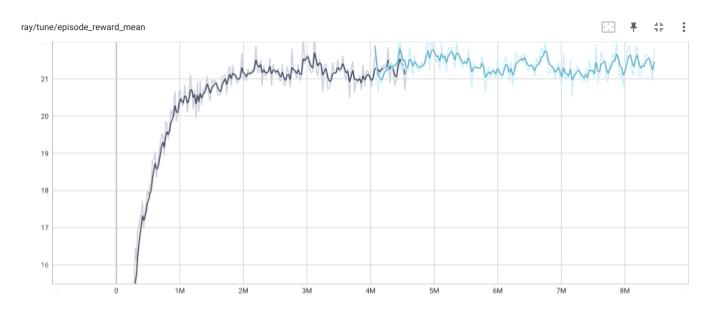
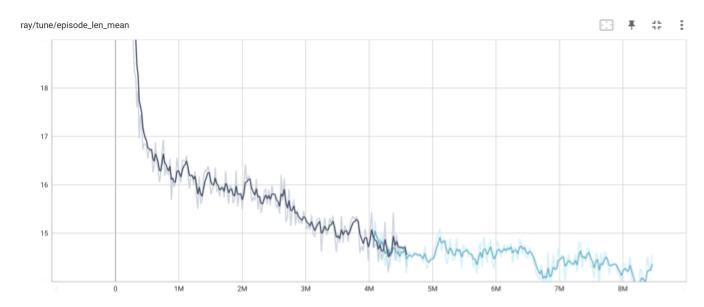
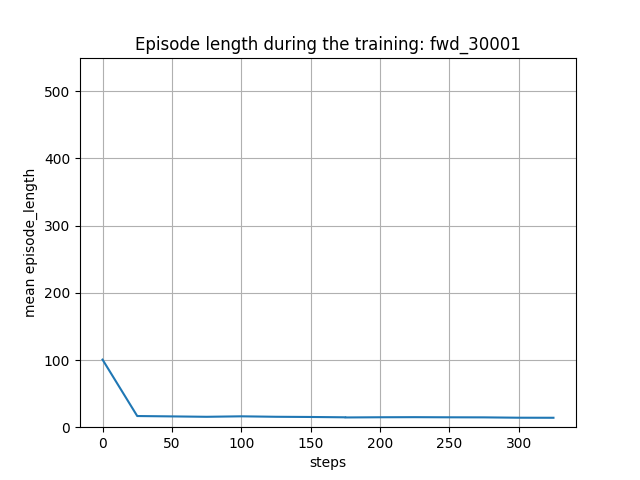
以下のトレーニング中の平均エピソード長の遷移を見ると、未だ収束していない感じがするので、もう少しトレーニングを継続したほうが良いと思われます。(趣味の範囲でやっているので、お金と時間をかけないように48時間で打ち切りました)。
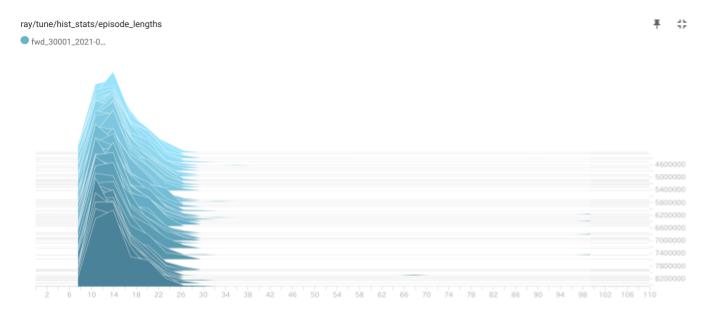
トレーニング後半のエピソード長分布の履歴です。
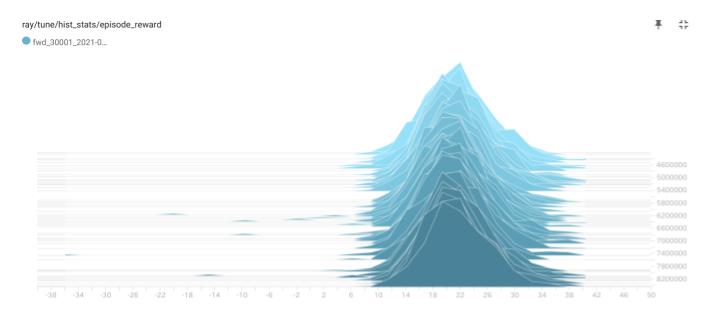
チーム報酬も分布は「少数群 vs 少数群」の時とは異なり、単峰性になりました。
トレーニング時の評価結果
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。途中の段差は、GCPのpreemptiveの継続に依るものですので、無視してください。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [7, 8] で乱択しているので、学習が進んだ時の平均残存数=5 ~ 6 は、1~ 2 個のエージェントが戦闘で消耗することを意味します。
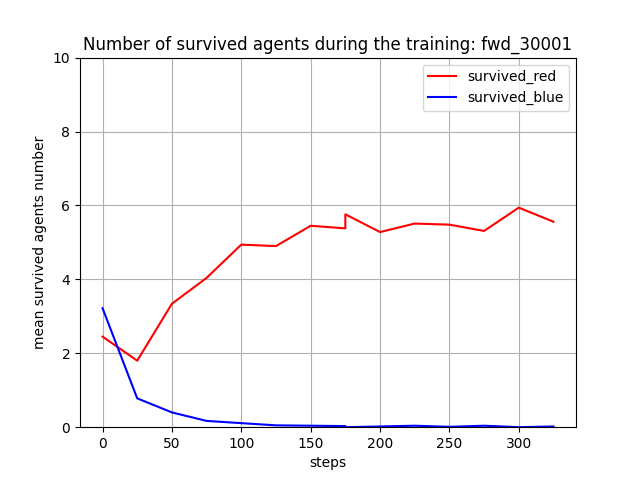
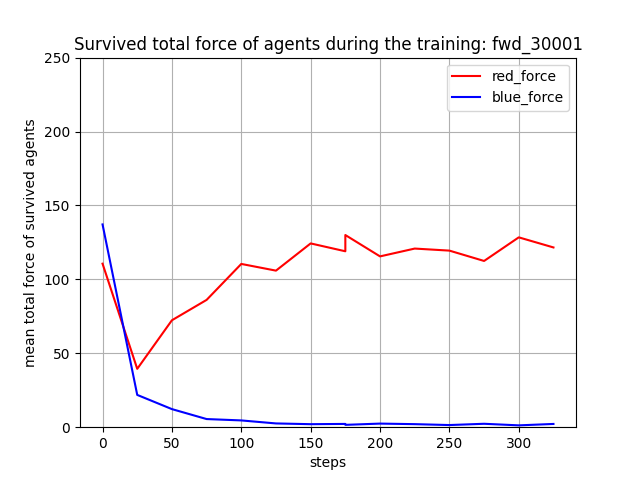
残存兵力(Force)の評価履歴は下記となりました。Blue team の残存兵力は0に近くなっていて、Red team の各エージェントは、上手く戦える戦術を生成し実行していることが分かります。ただ、「少数群 vs 少数群」でトレーニングした時の様に、Blue team の残存兵力を完全に0にはできていないので、もう少しトレーニングを続けた方がよさそうです。
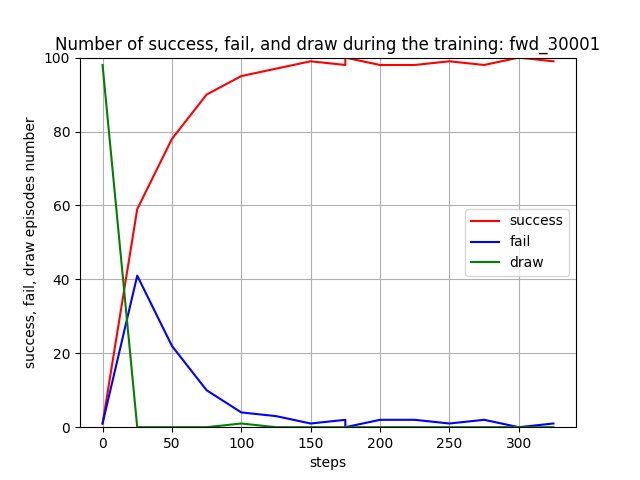
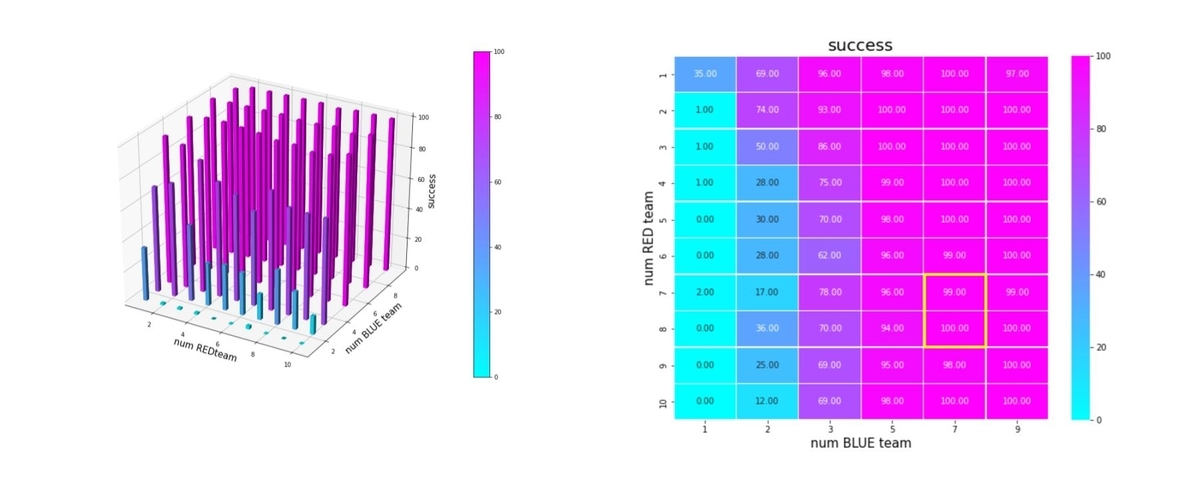
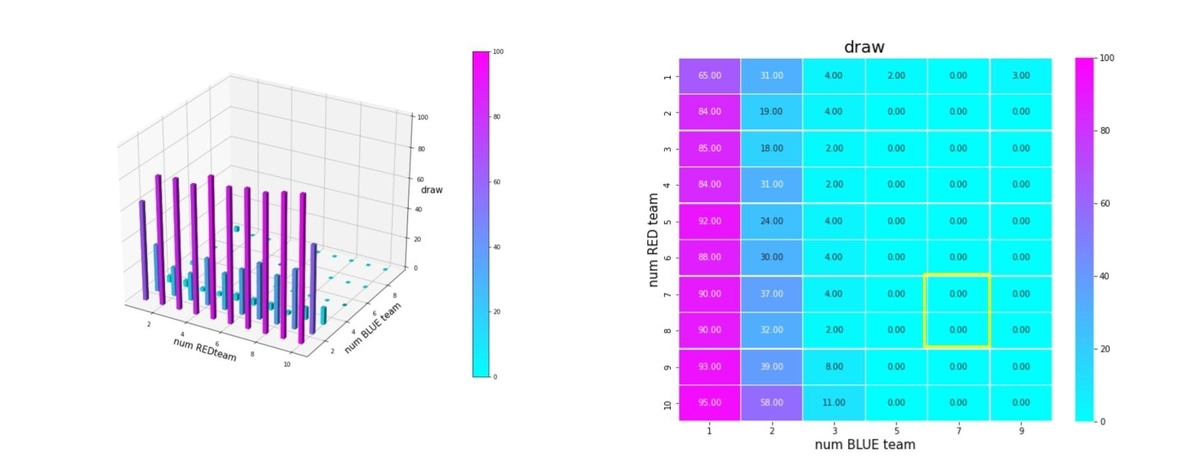
Blue team の残存兵力を0にできたエピソードを success、逆に Red team の残存兵力が0になってしまったエピソードを fail、どちらの兵力も0とはならなかったエピソードを draw と定義して、これらを100回のエピソードから算出したのが下図です。学習が進むと、success=100%、つまり、Blue team の残存兵力を0に近づけられることが判ります。
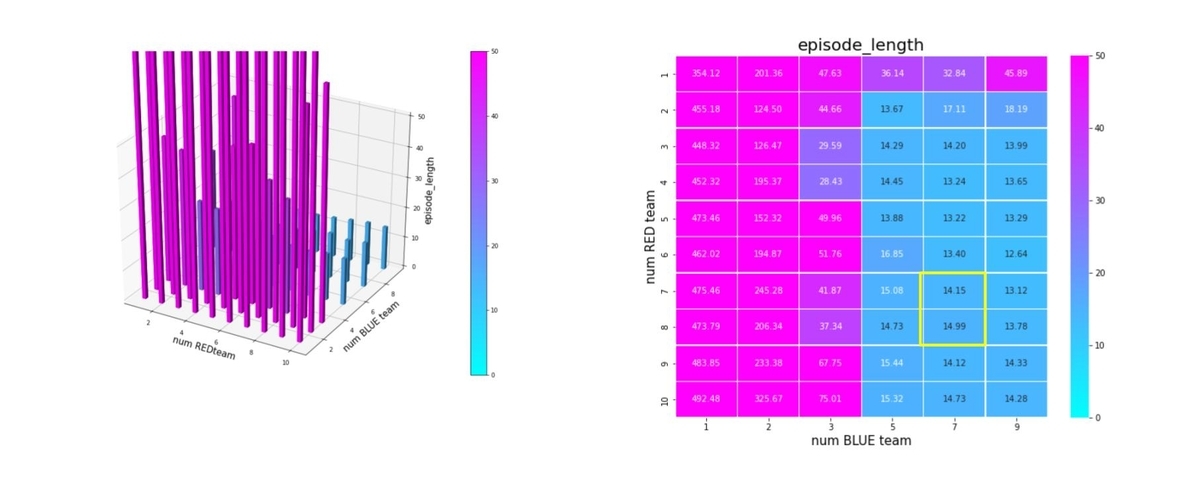
下図は、エピソードの長さから学習の進捗状況を見たものです。(その3)の検討よりも、エージェント数が多くなったので、学習が進展した後の平均エピソード長は少し長くなっています。
性能評価
下表は、学習後に、チームの性能を100回のシミュレーションを行って、定量的に確認したものです。ここで、
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
です。red team の残存エージェント数は74~80%と割と多いのですが、残存兵力は25%程度になっています。もし、red team の各エージェントが、完全に一丸となって戦うことを学んでいれば、少なくとも「少数群 vs 少数群」の時と同程度の30%以上のred team残存兵力になるはずですので、完全に一丸となって戦っているとまでは言えないようです。(時間の都合で、Blue agent 数=7の場合だけを計算しています)。
この点に注意しながら、生成された戦術を見てみます。動画の見方は、(その3)と同様です。
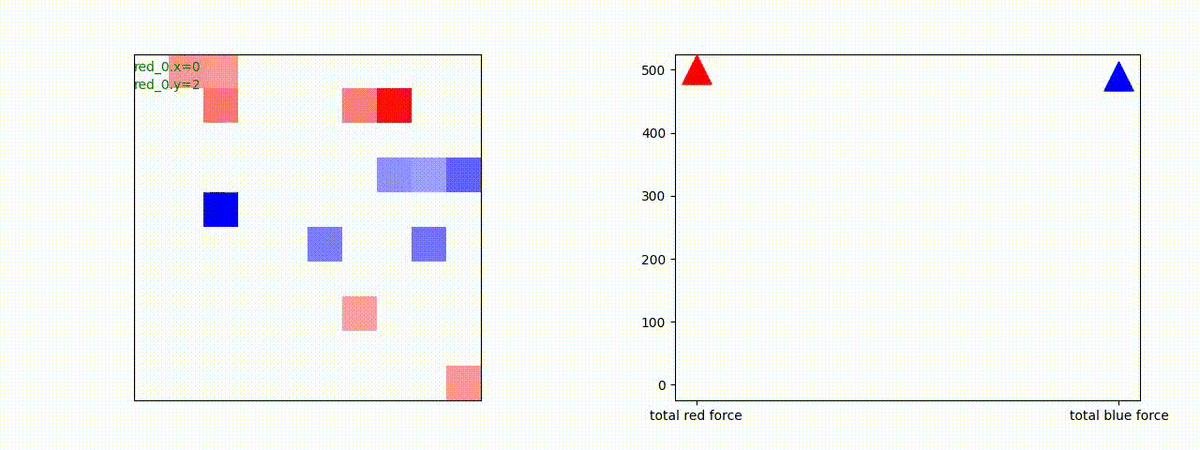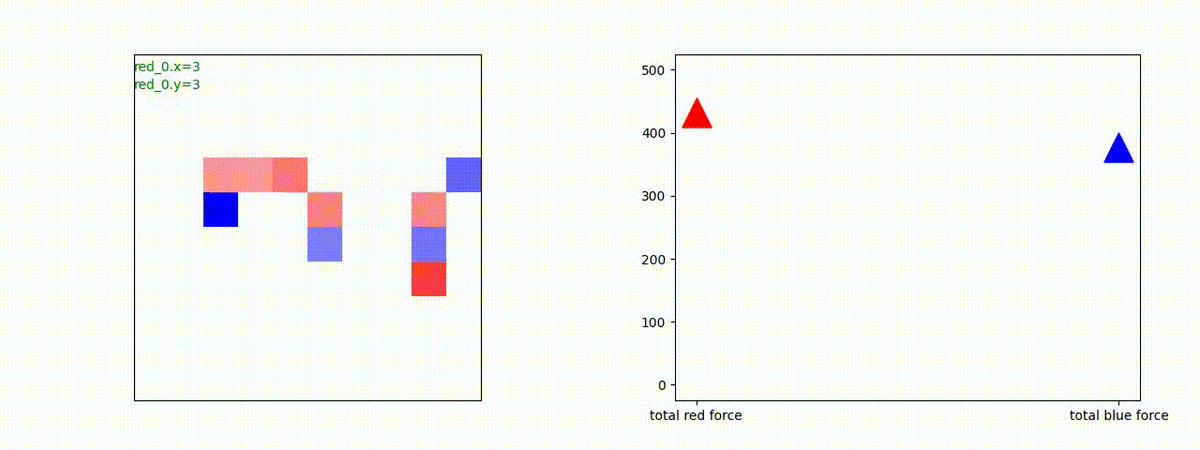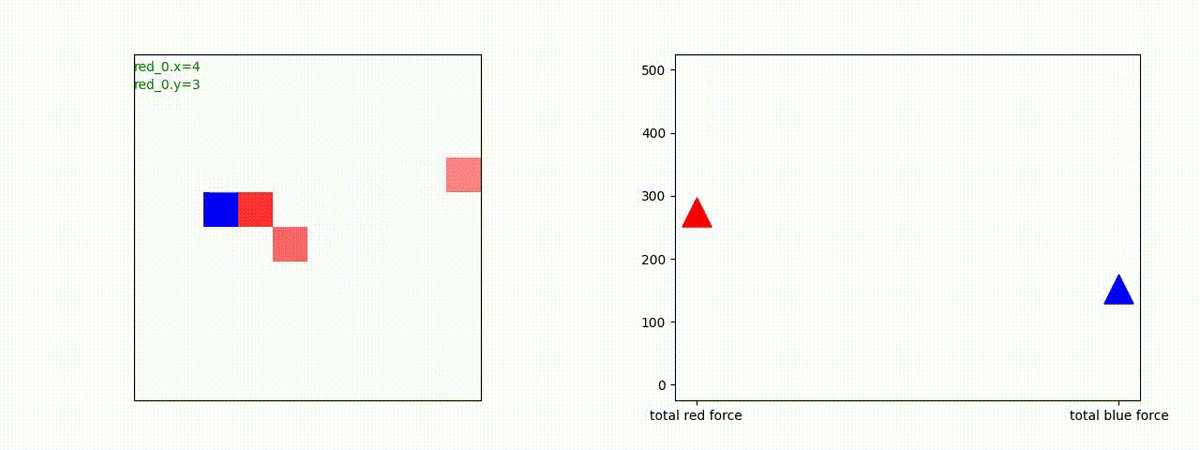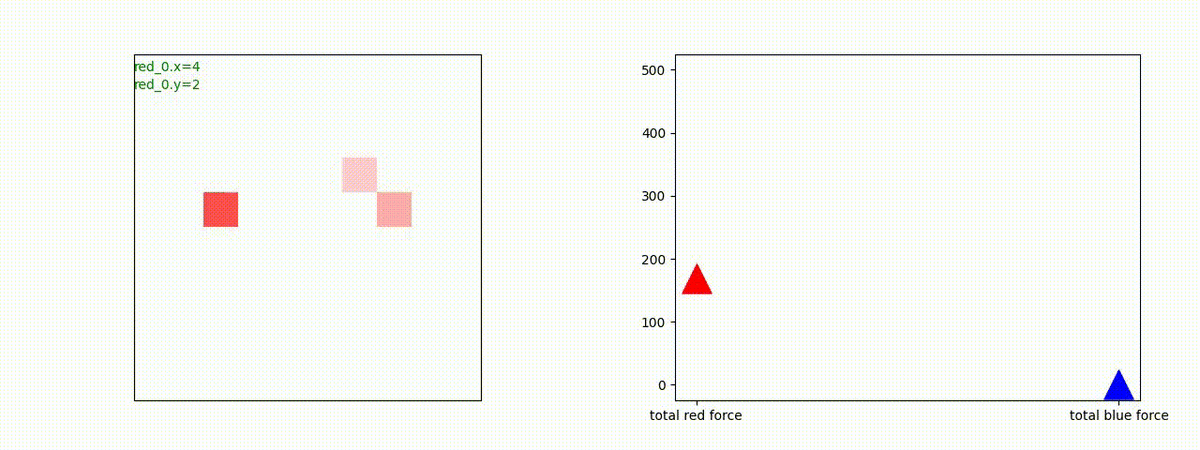
生成された戦術
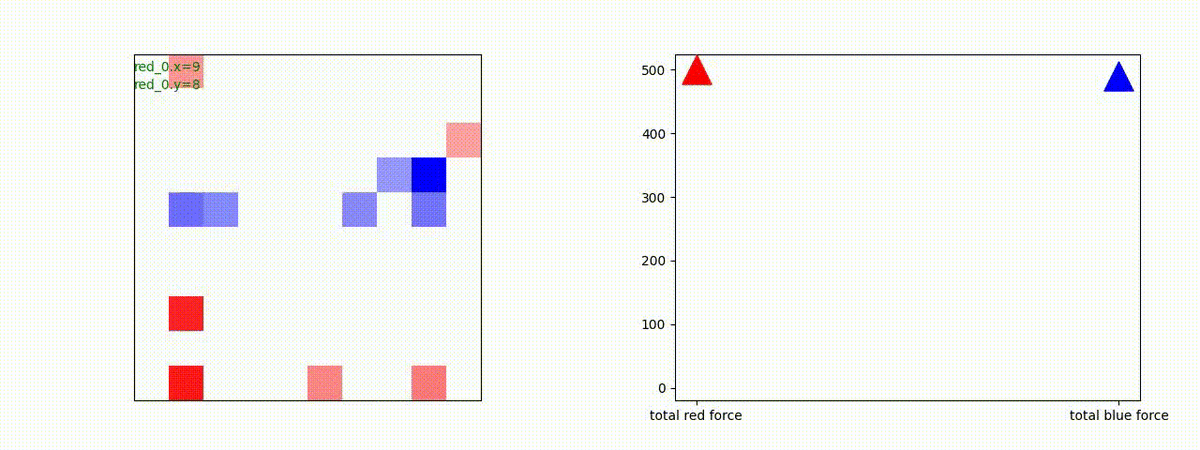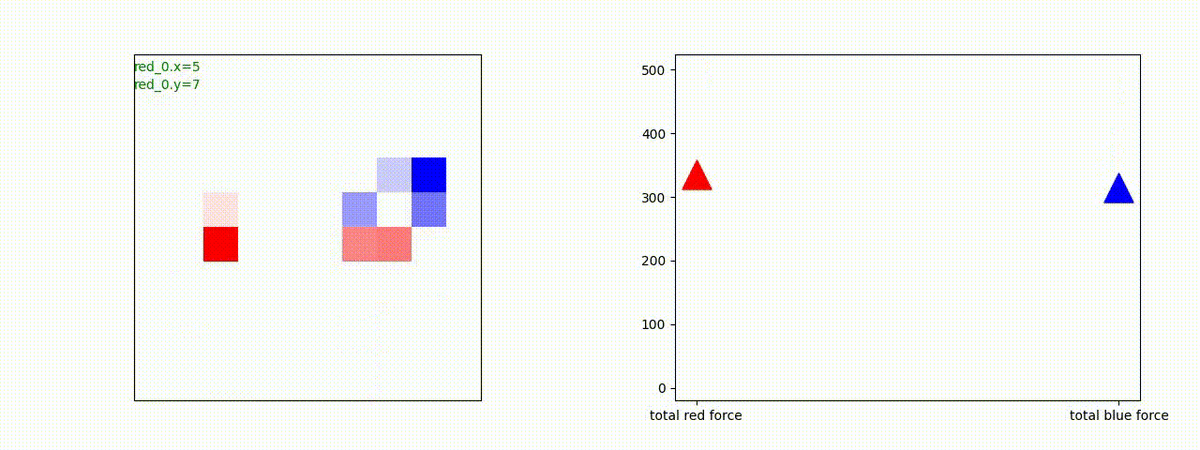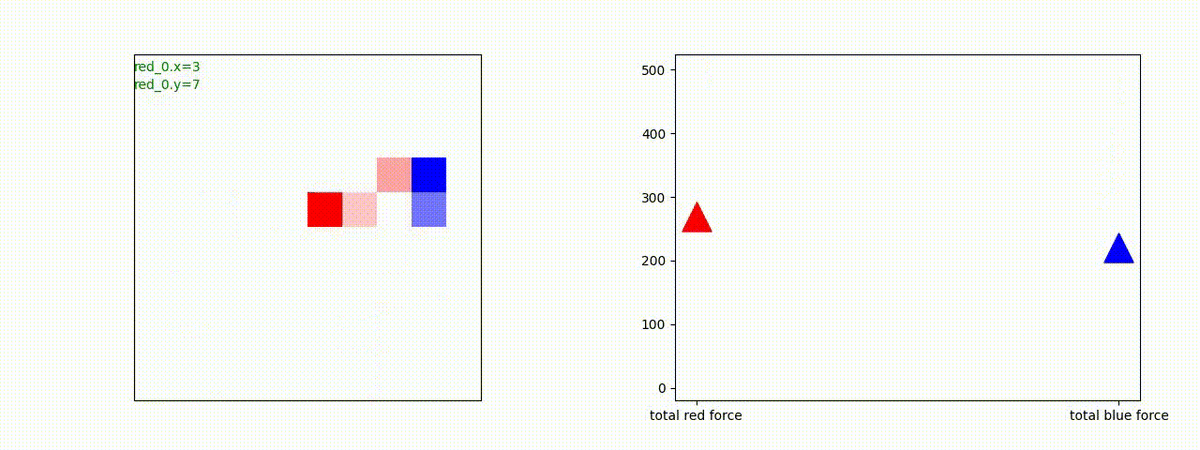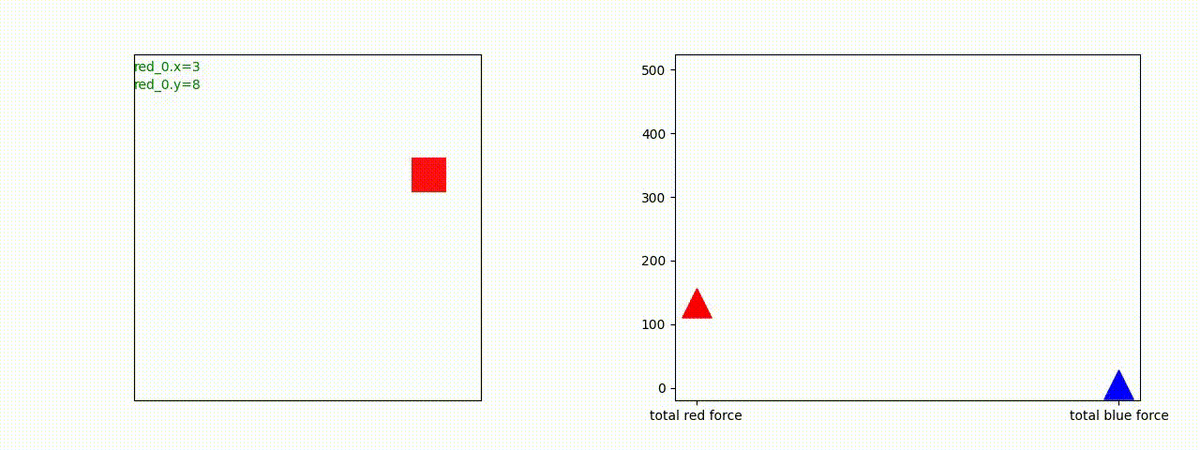
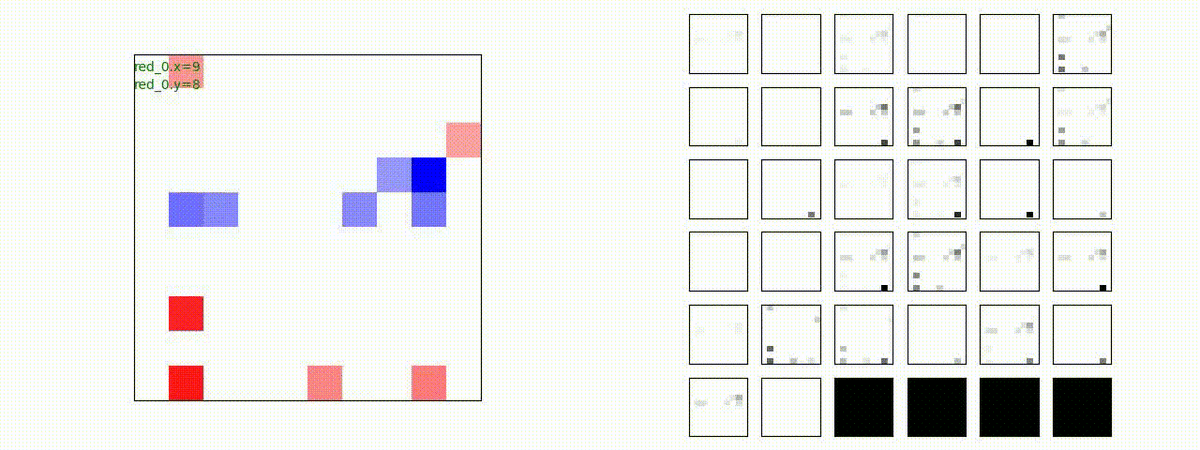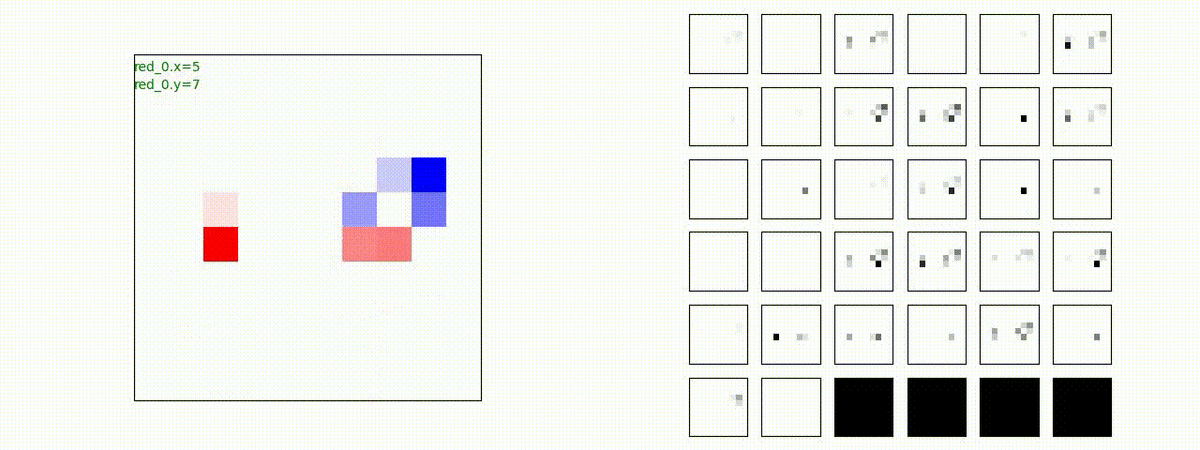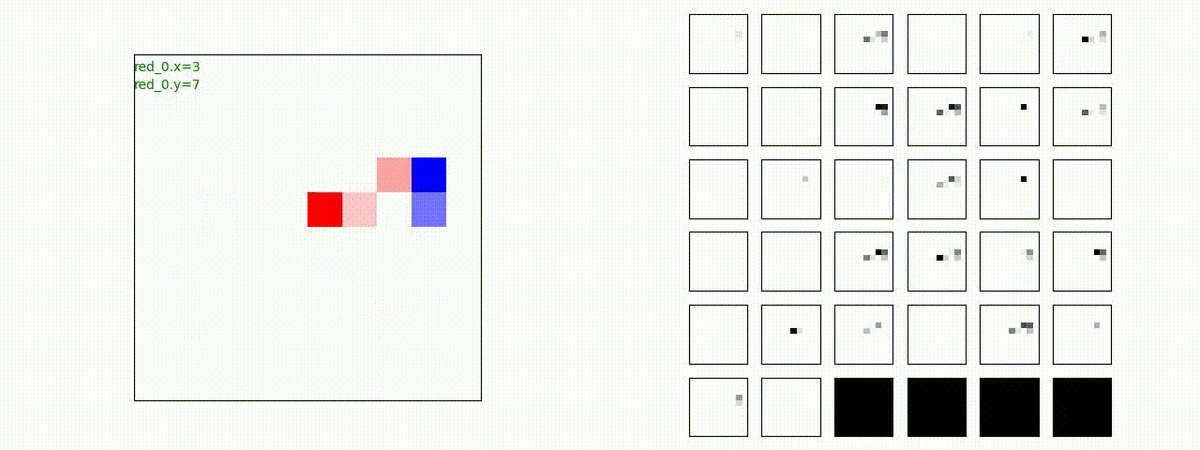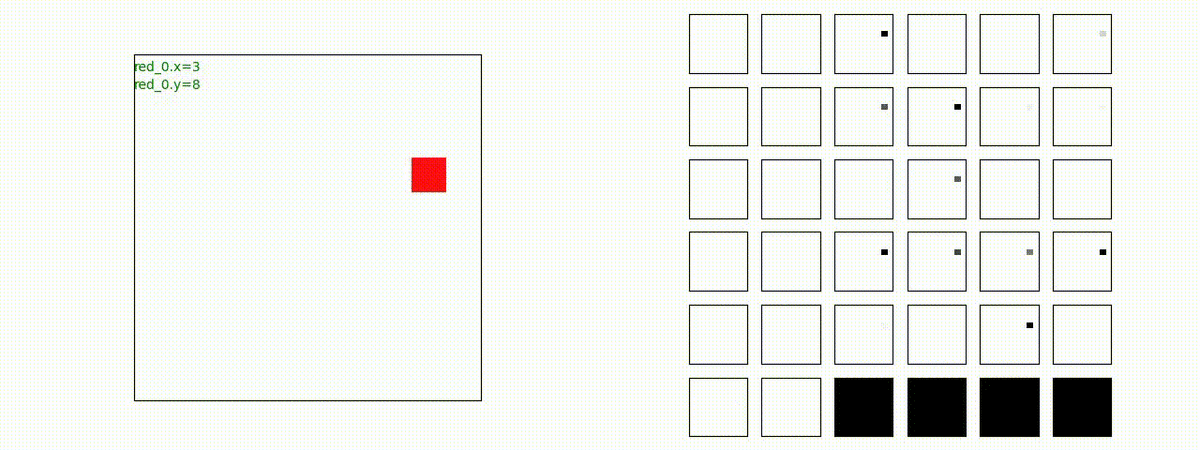
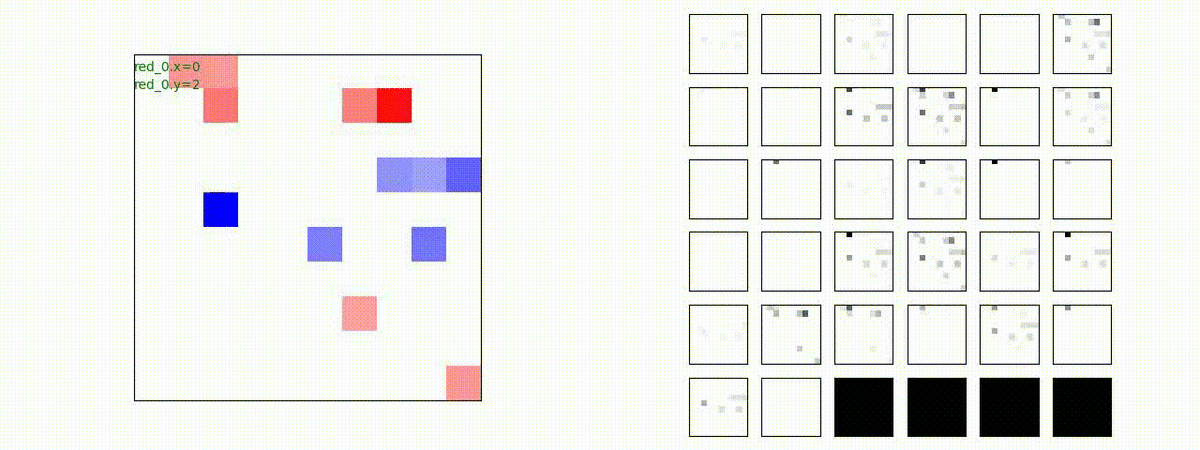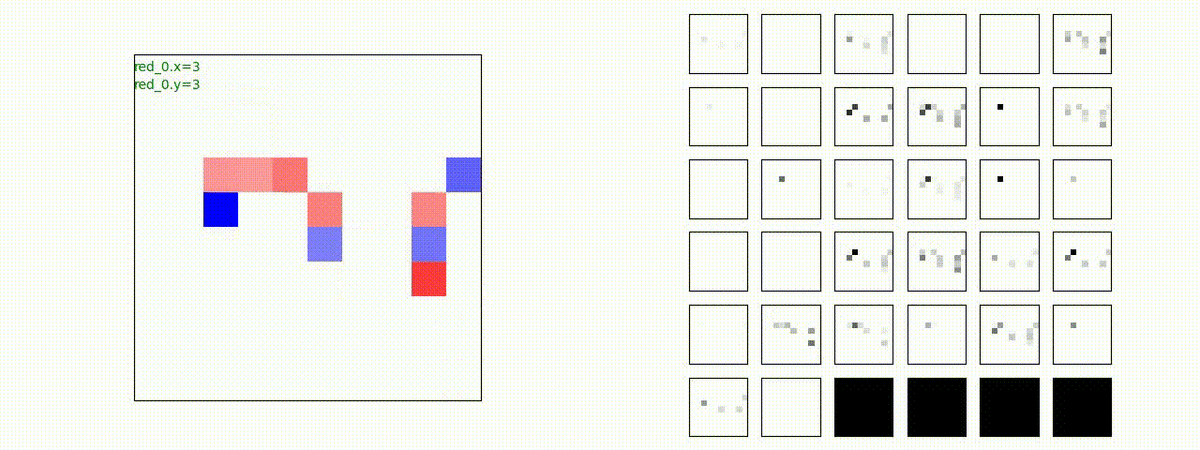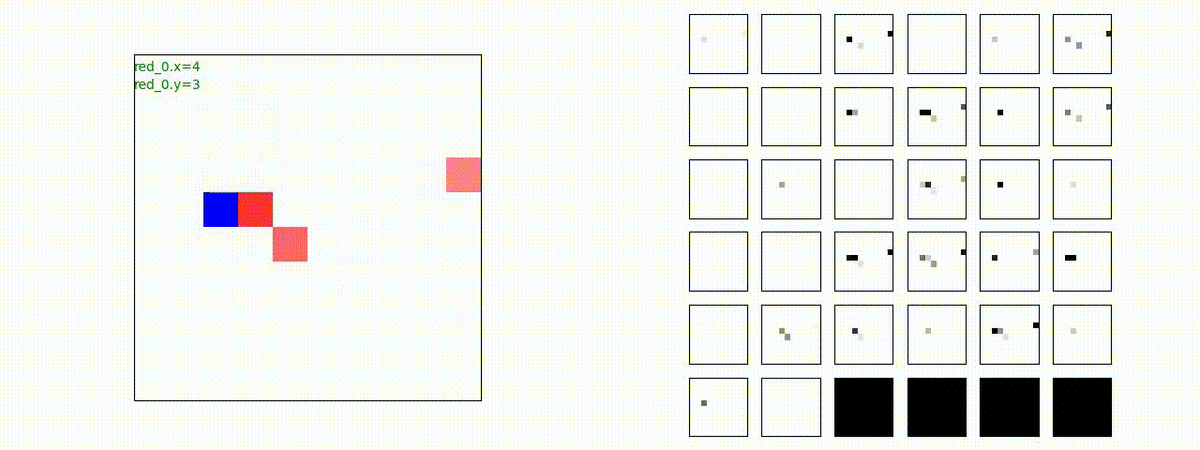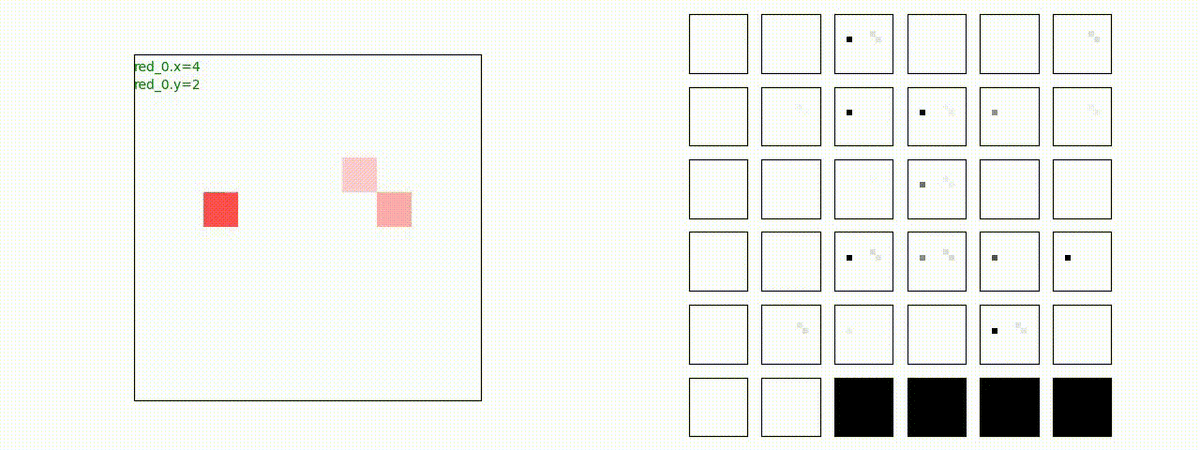
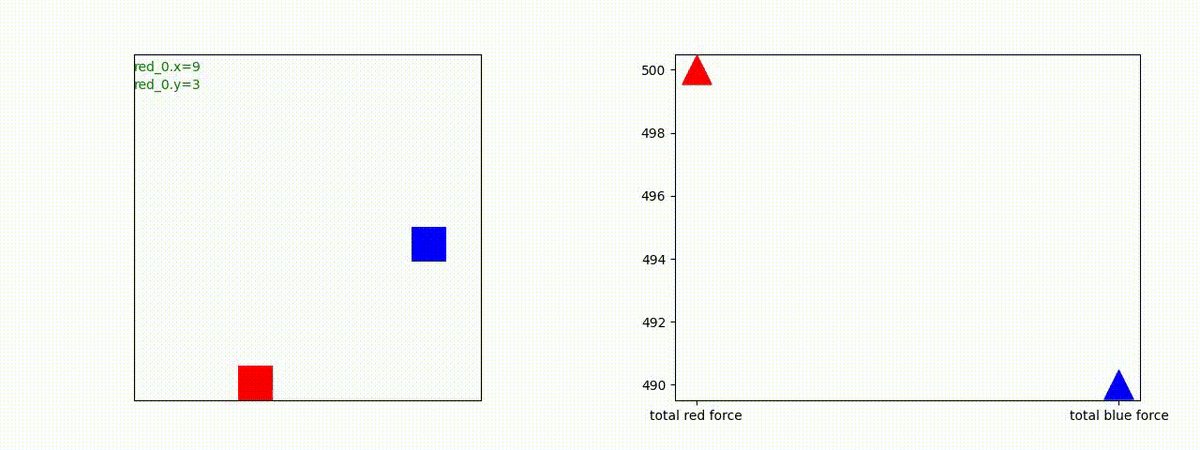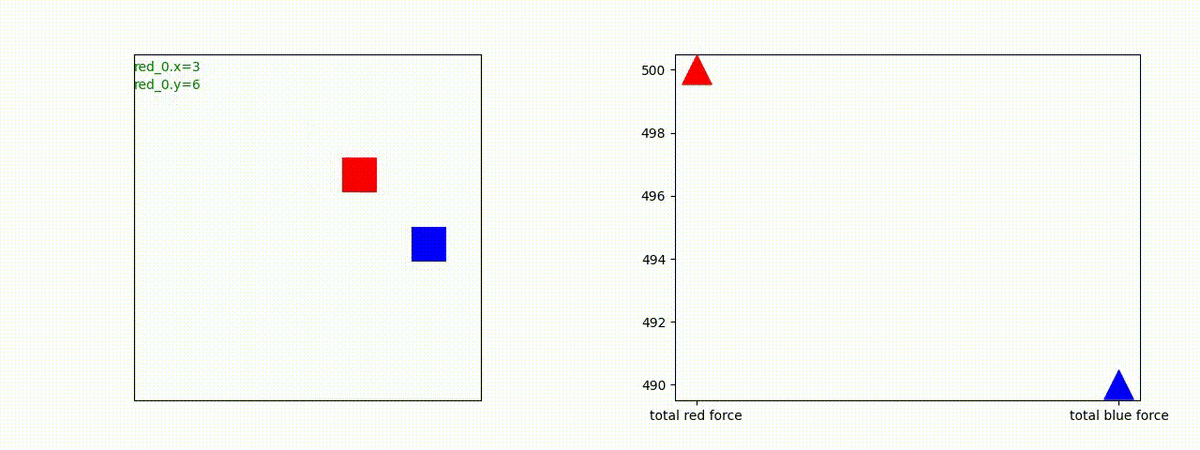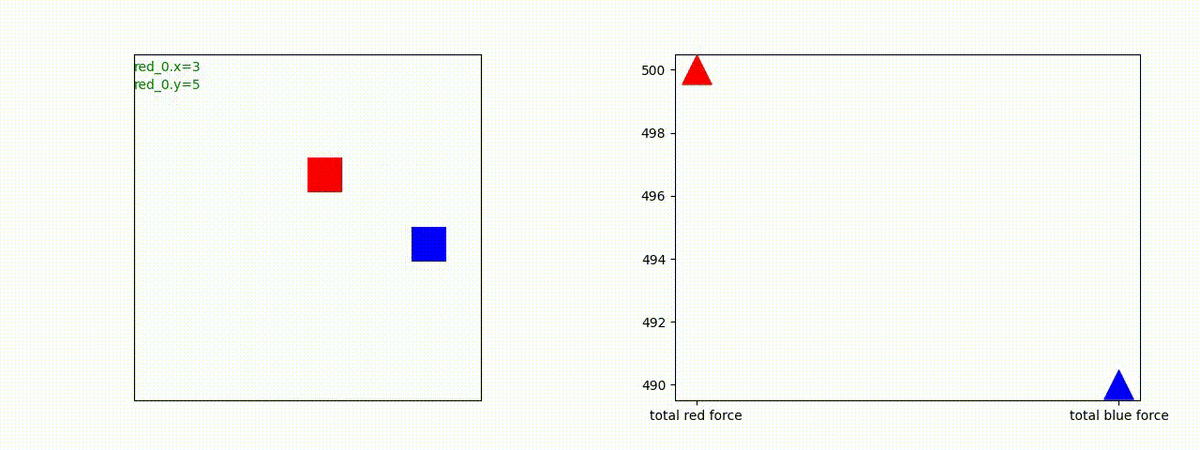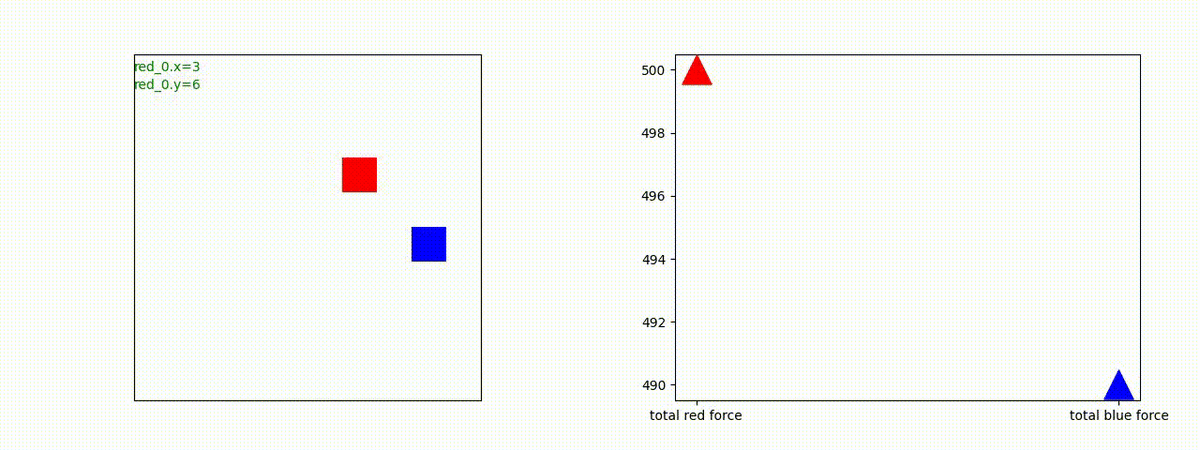
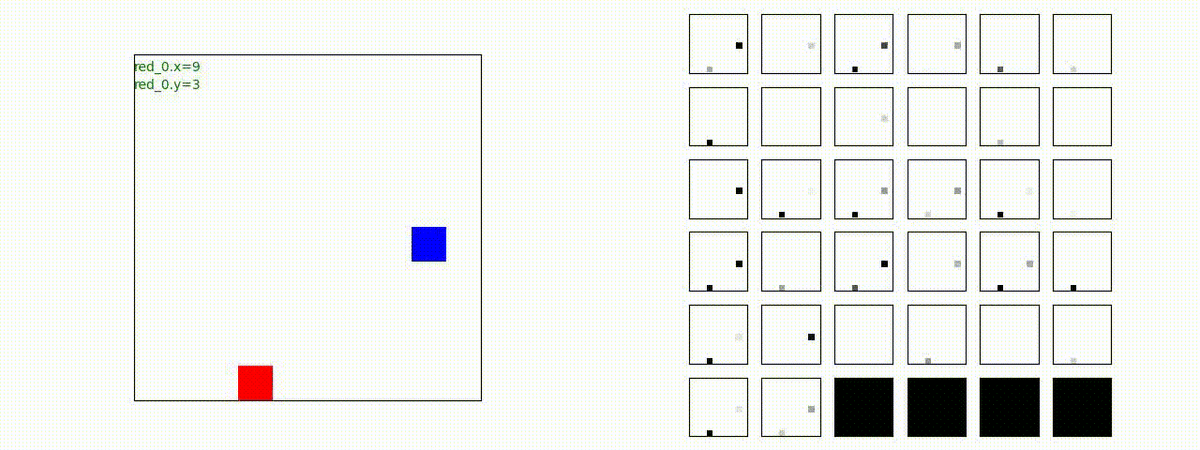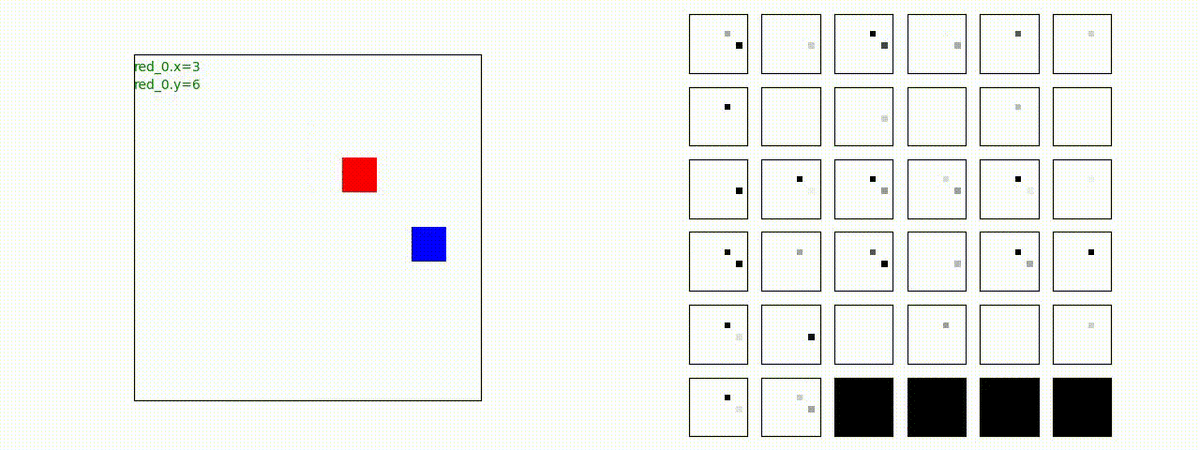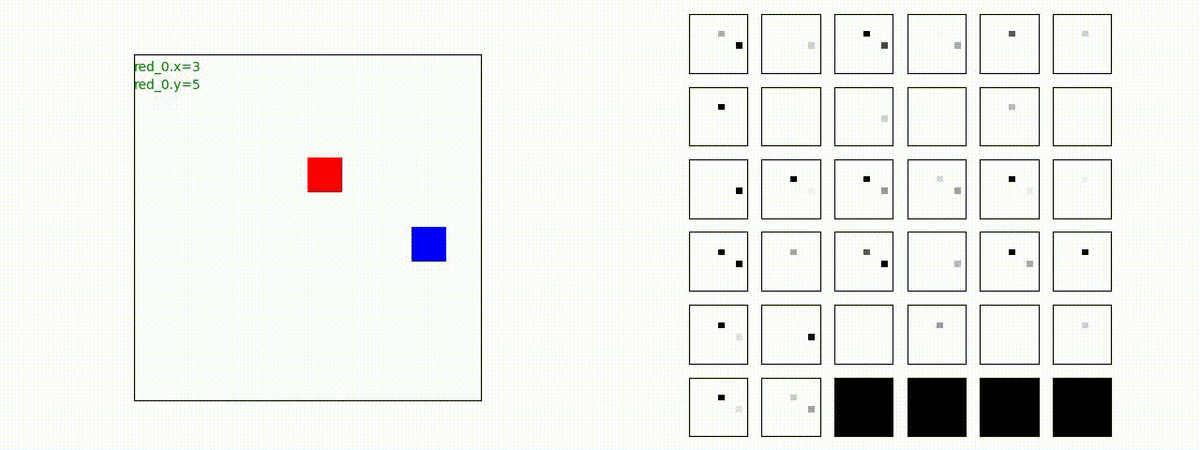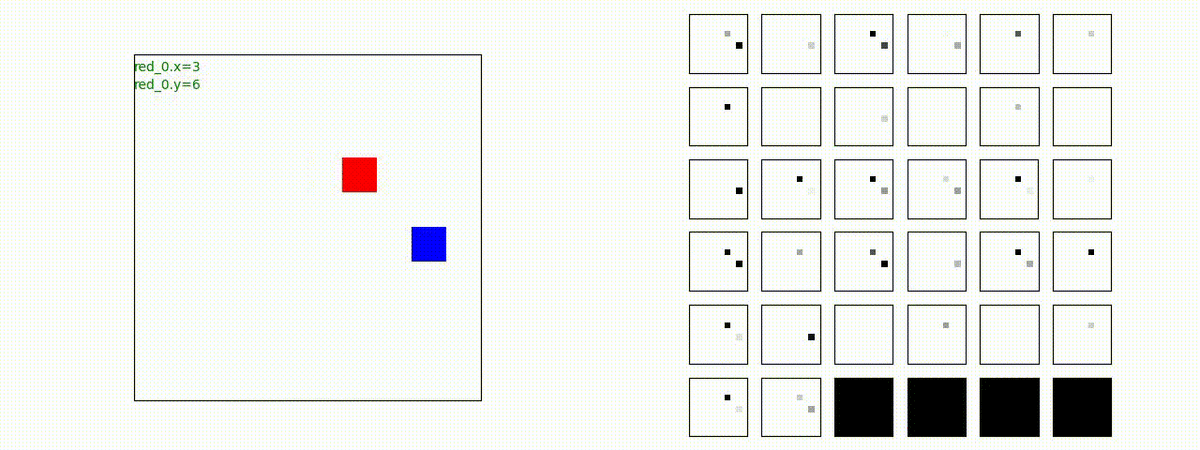
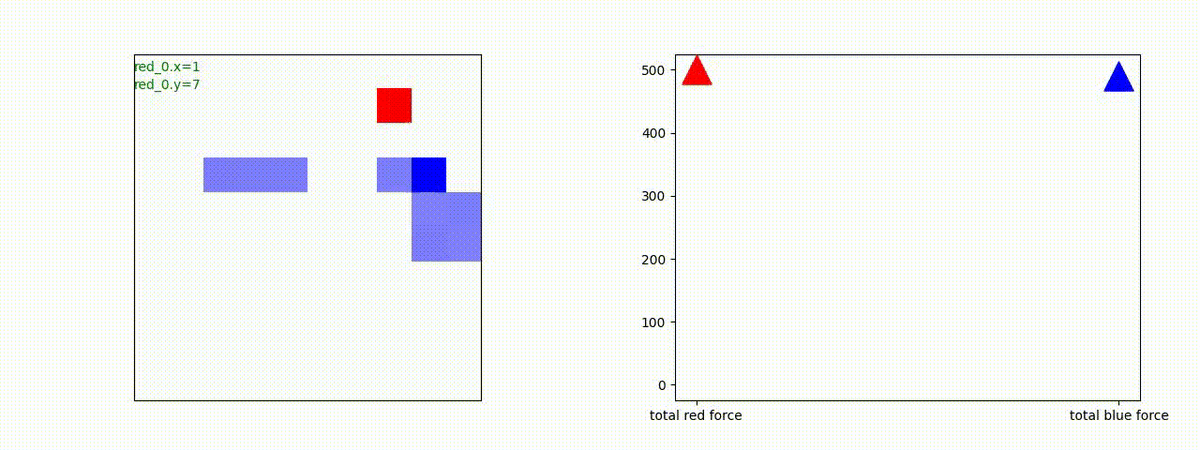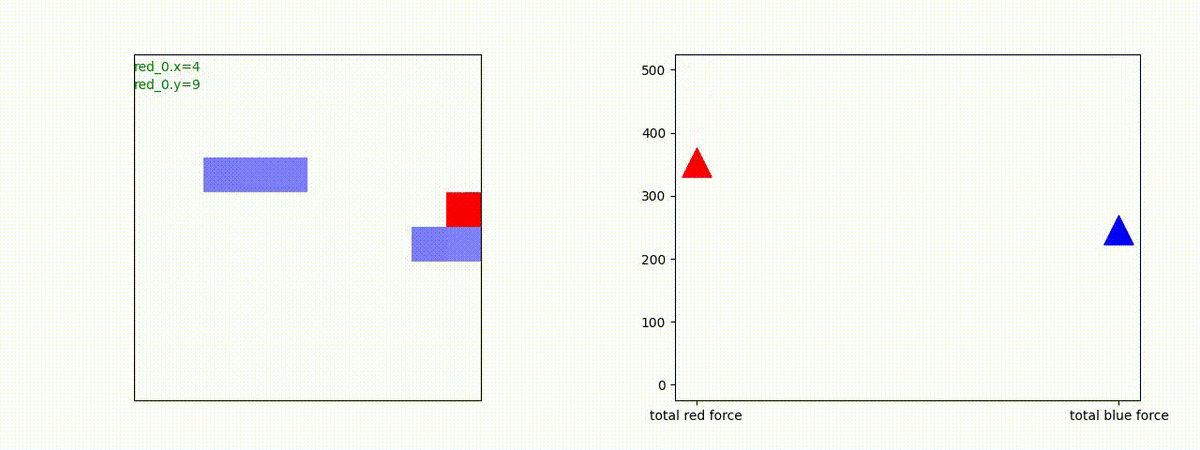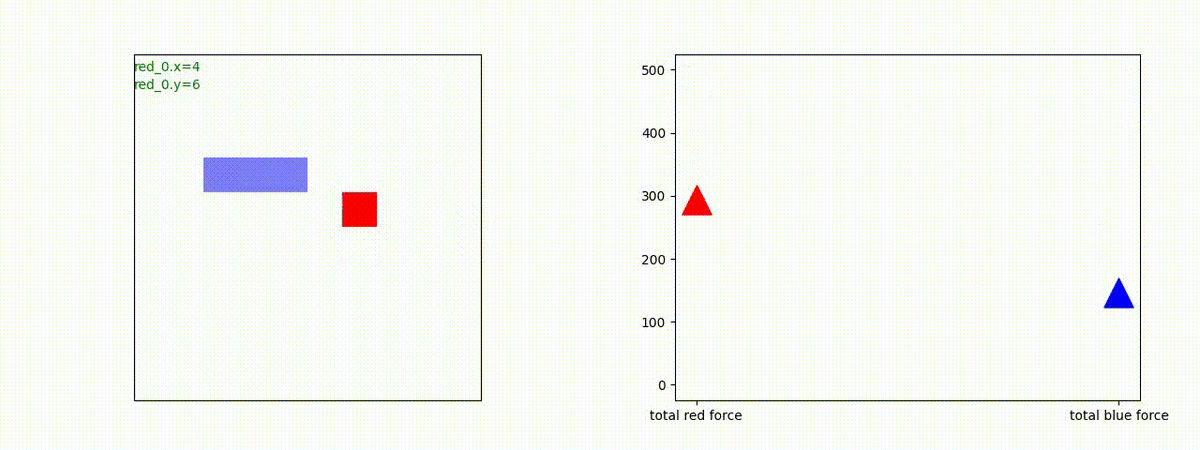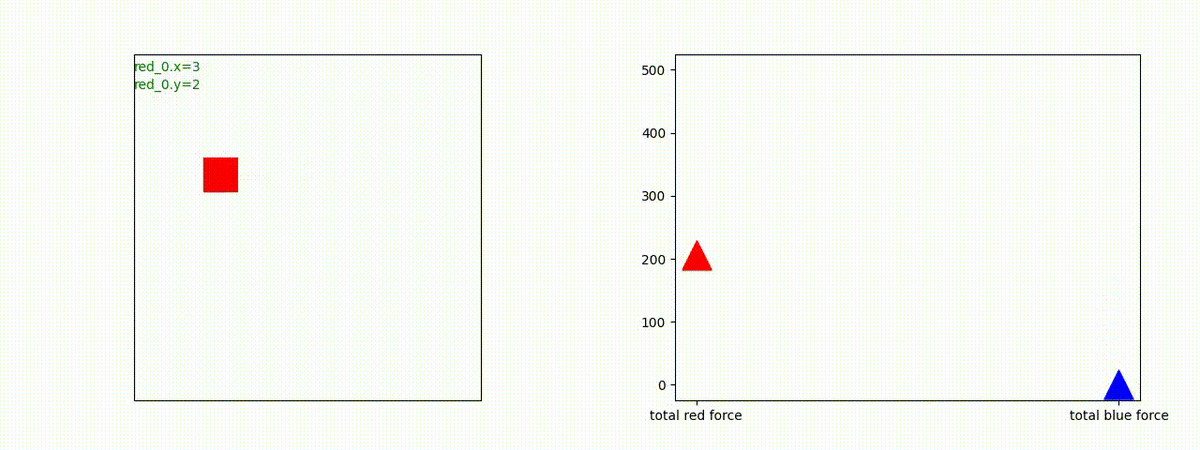
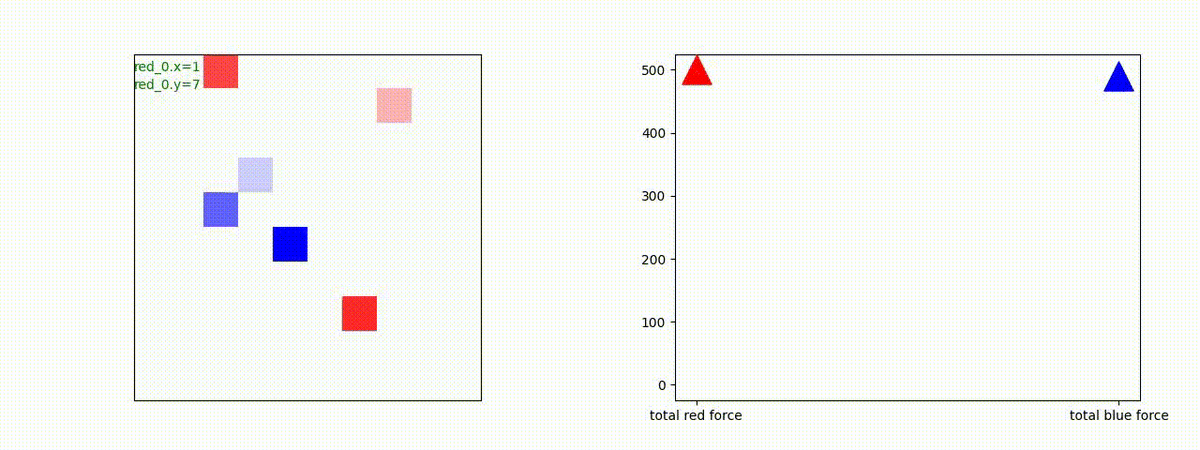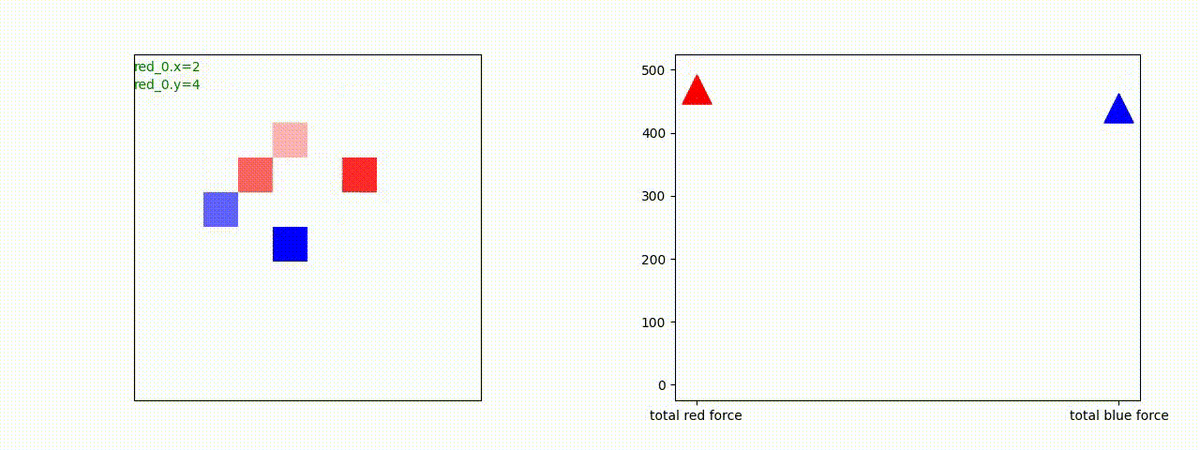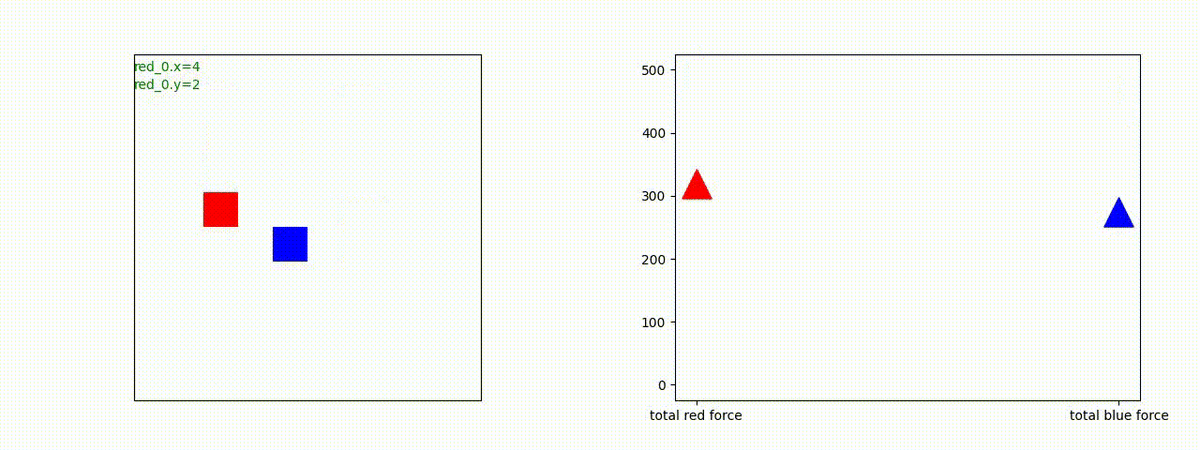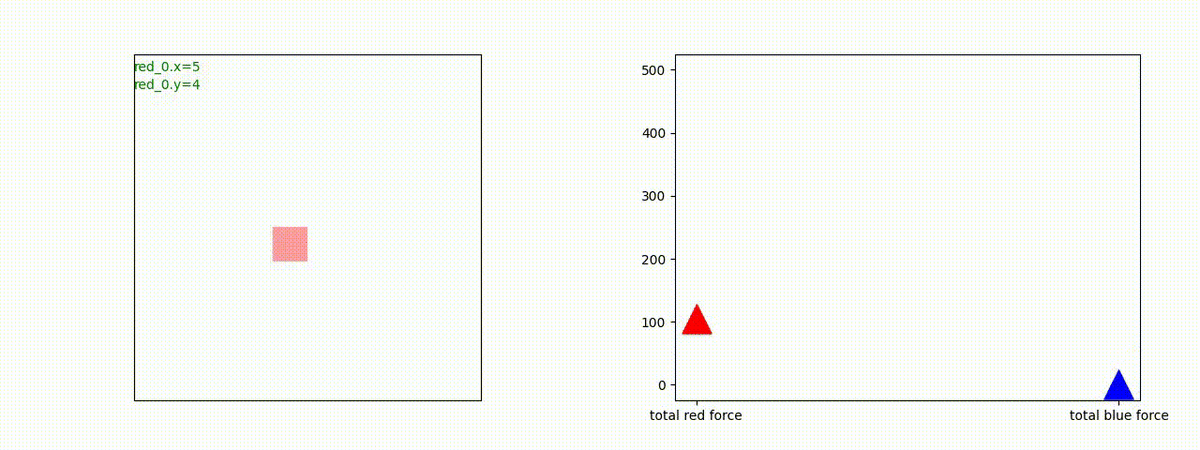
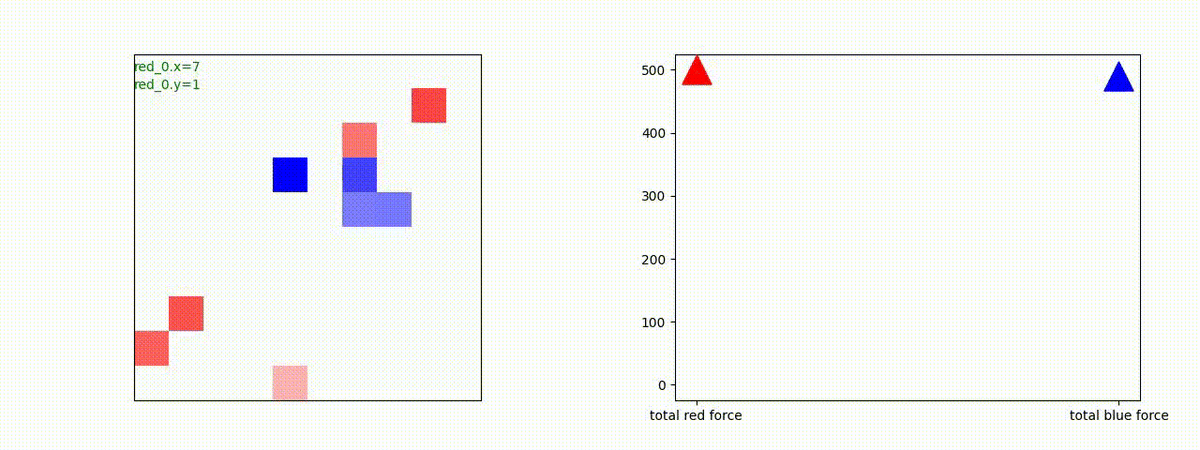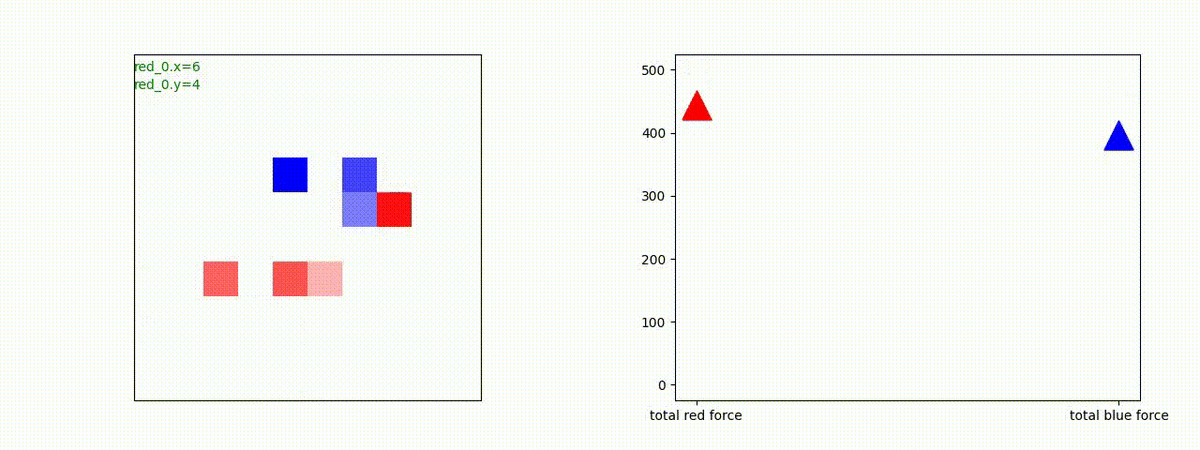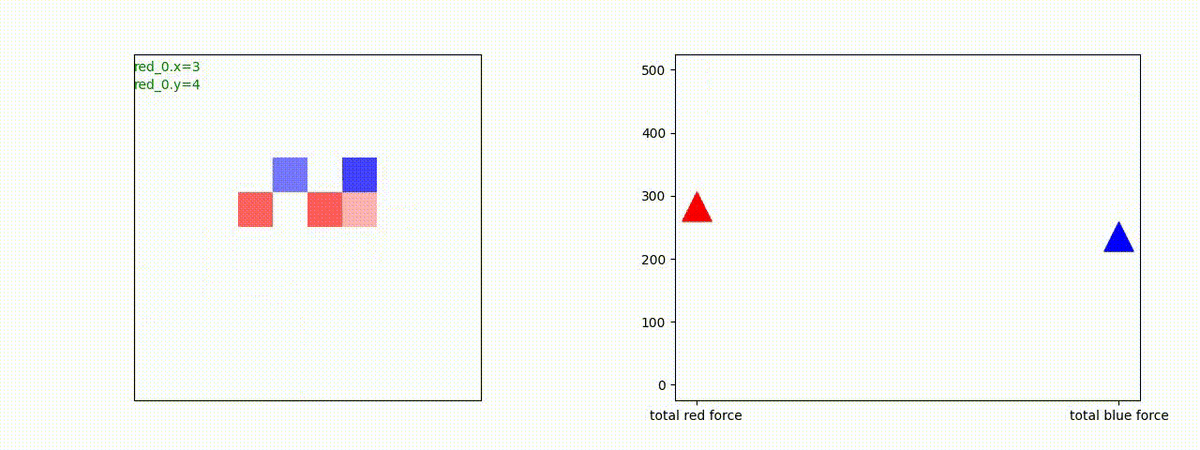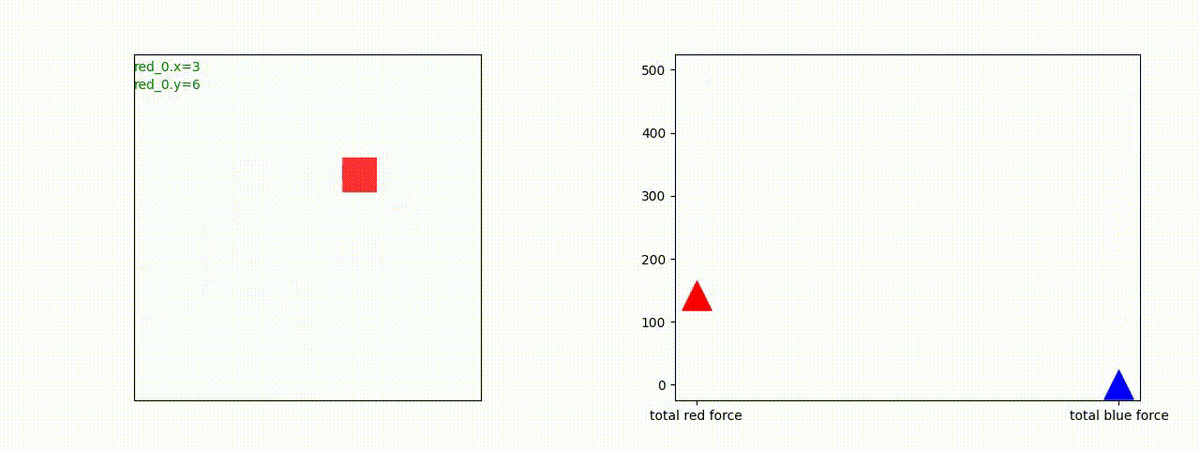
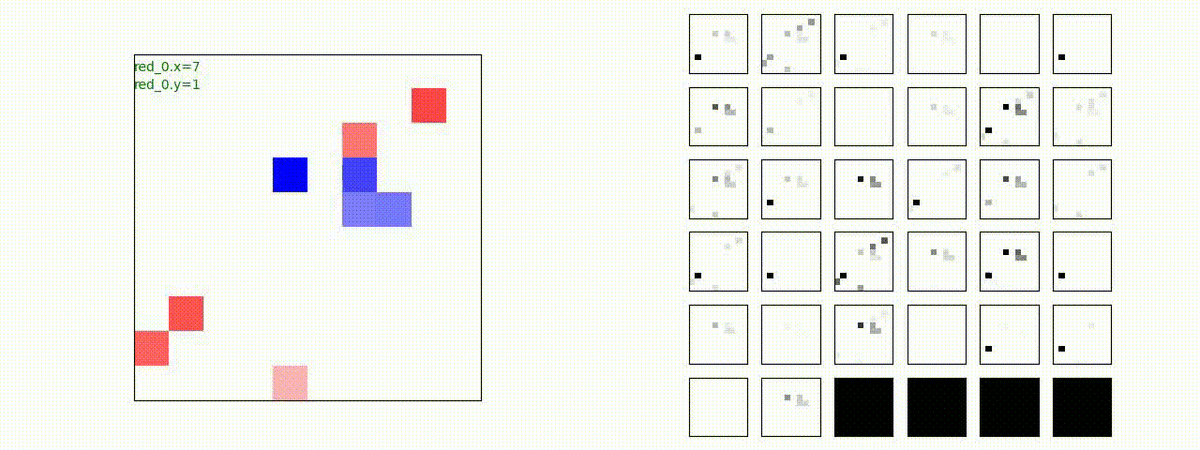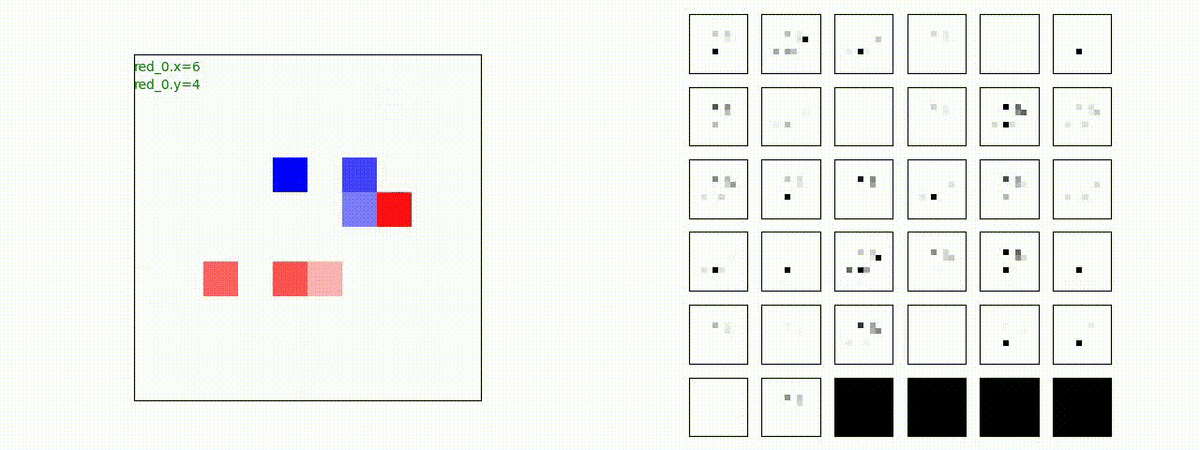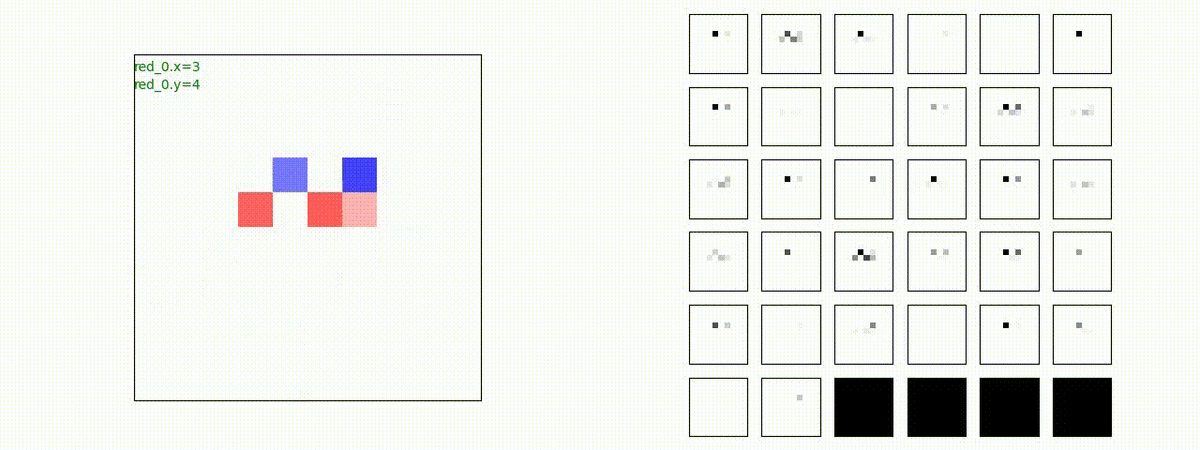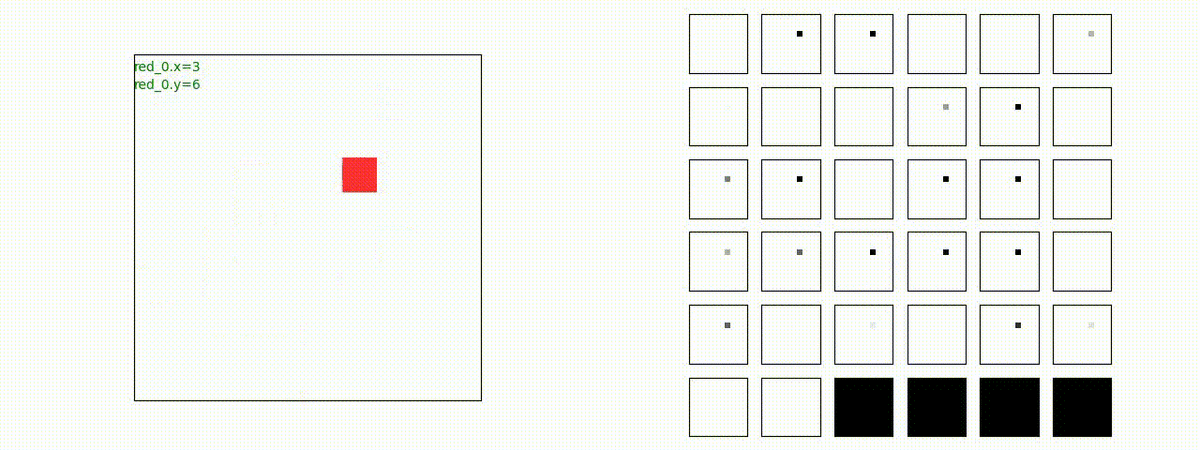
下図(左)は、戦闘状況を示します。赤い正方形が Red team のエージェント(群)、青い正方形が Blue team のエージェント(群)を示します。画面左上の座標値は、red team の0番目のエージェント( "red_0" と呼称)の位置を示します。また、色の濃さが戦闘力(Force)の大きさを表し、色が濃いほど大きな戦闘力であることを示します。したがって、戦闘が進むに連れ、戦闘力は消耗して色が薄くなってゆきます。また、同一グリッドに Red team と Blue team が混在する場合は、チームの戦闘力の差を表していますので、色が薄いほど拮抗した戦闘がそのグリッドで行われていることになります。戦闘が進んだ時に色が濃くなるのは、それだけその色のチームの戦闘力が相対的に優位になったことを表しています。
下図(右)の赤、青三角は、夫々 Red team, Blue team の残存戦闘力(群の構成メンバー数)を示します。
Red teamの各エージェントは、勝率 100% ですが、完全に一つの塊となって 'mass' 重視の戦闘をする訳ではありませんでした。ここは、もう少しトレーニングを継続すると改善するのかもしれません。(やっていないので分かりません)。
Red team = 8 swarms vs Blue team = 7 swarms
下図(左)も(その3)と同様に、各エージェントが、認知系(DenseNet)に入力するために 1x1 Conv を使って新たに生成した32枚のマップを示しています。どういったマップを生成しているのか把握するのは結構大変そうなのでやりませんでした。
別の例を示します。やはり、完全に一つの塊となって 'mass' 重視の戦闘をする訳ではありません。他の例も調べたのですが、同様の結果でした。
ロバスト性(汎化能力)
ここでは、エージェント数を Red team = [1, 10], Blue team = [1, 9] の範囲で振ってみて、トレーニング時には全く未経験の戦況にどこまで対応できるのか測って見ました。(トレーニング時のエージェント数は Red team = [7, 8], Blue team = [6, 7] です)。
初期エージェント数が Red team = [1, 6], Blue team = [1, 5] のようなケースでは、初期マップはトレーニング時に見たことが無いような、エージェントが少ない疎なマップになります。
しかしながらこれと類似したエージェント数のマップは、戦闘が進んで、初期兵力が消耗すると現れてくるはずです。もちろん兵力(Force)が異なるのでマップとして同じわけではありませんが、多少のロバスト性(汎化能力)は期待できるのではないかと当初は考えました。(結果は、そうはなりませんでした)。
一方、初期エージェント数が Red team = [9, 19], Blue team = [8, 9] のケースでは、初期マップがトレーニング時よりも密になりますが、「少数群 vs 少数群」の時の経験から、これくらいの違いであればロバスト性(汎化能力)が期待できます。
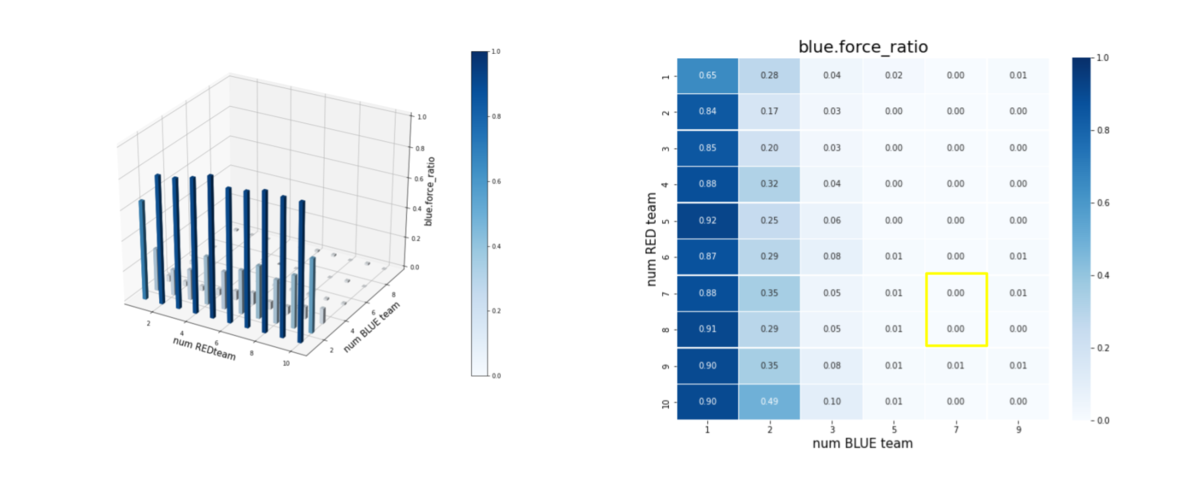
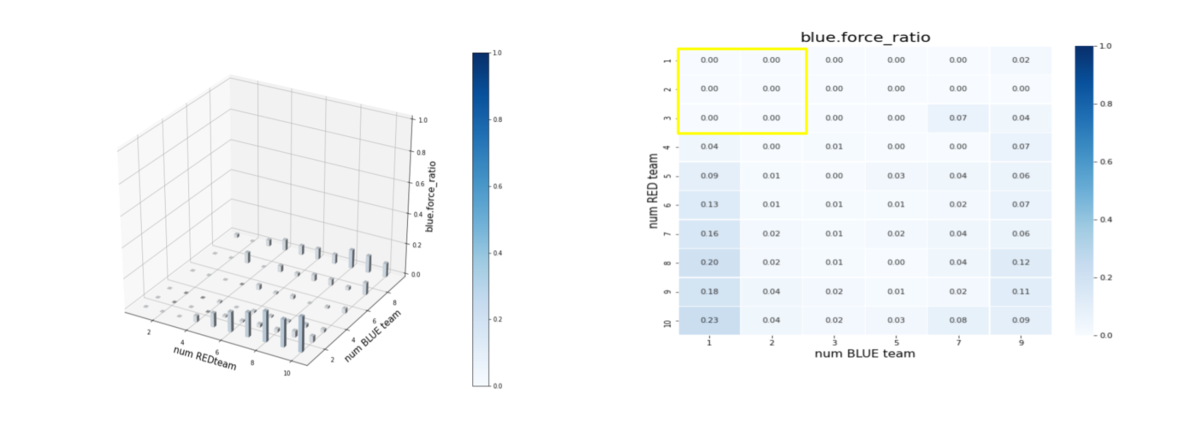
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。
num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸 blue_force_ratioは、
blue_force_ratio = Blue team残存兵力/Blue team初期兵力
を表します。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。トレーニング時のエージェント数は、red_team = [7, 8], blue team = [6. 7] ですが、Blue_team = {1,2,3,5,7,9} でやっているので、図のような長方形の黄枠になっています。いずれにせよ、黄色から外れるほど、トレーニング時に見たことがない戦闘環境になります。
これから、以下を読み取ることが出来ます。
- Blue teamのエージェント数が、トレーニング時の1/2である3程度までは、そこそこ上手く戦える。
- Blue teamのエージェント数が、トレーニング時の1/2以下である1や2になるとうまく戦えない。
- Blue team, Red team のエージェント数が多少増えても、問題なく対処できる。
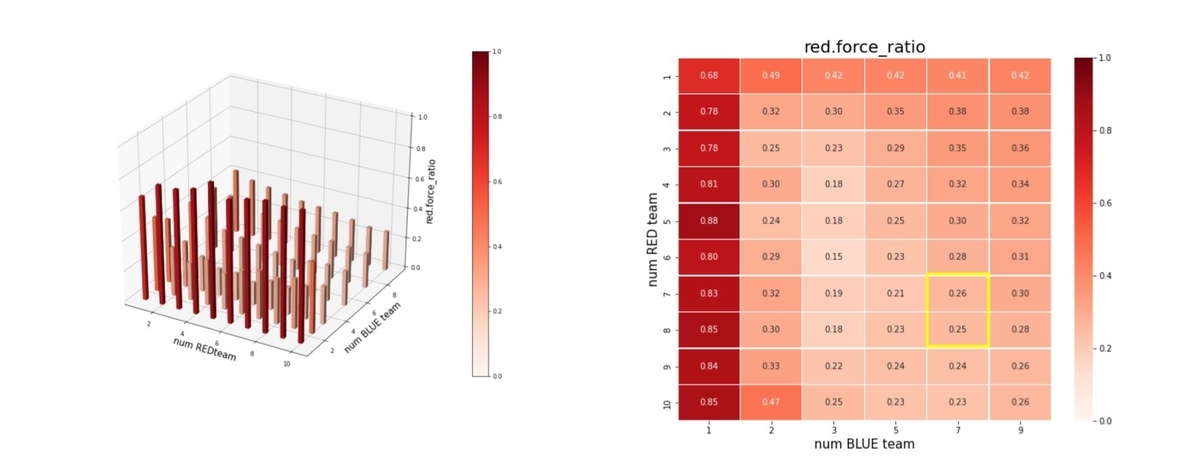
この時の red teamの残存兵力は下図になります。red_force_ratio は以下で定義しています。
red_force_ratio = Red team残存兵力/Red team初期兵力
Blue teamのエージェント数が少ない場合、red teamの残存兵力も大きくなっています。したがって、このトレーニング方法では、強大な兵力の群に、小分けの群で戦う汎化能力は十分ではないことが分かります。
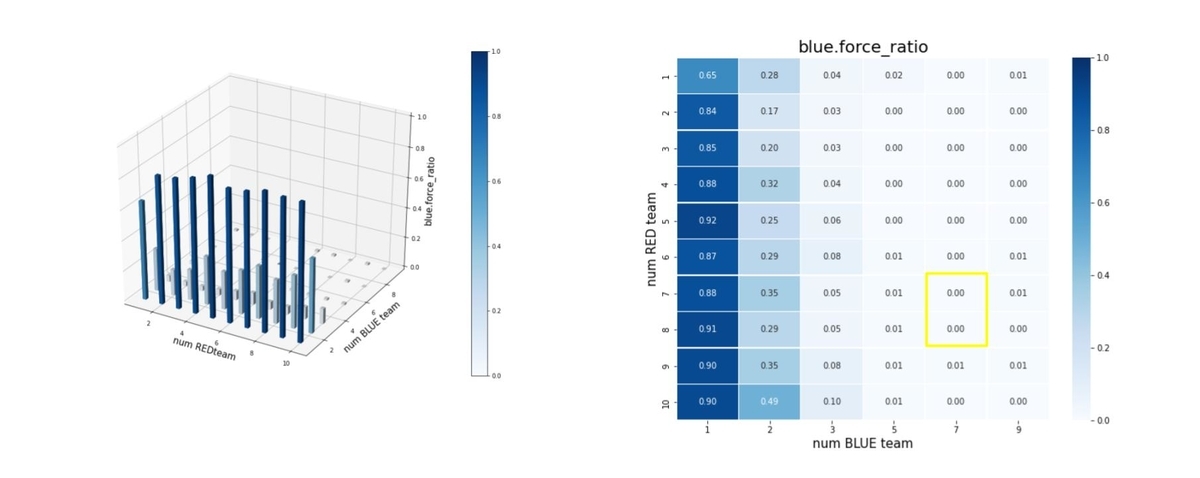
以上のことは、残存兵力ではなく、残存エージェント数(群数)からも読み取ることが出来ます。blue_alive_ratio は以下で定義しています。
blue_alive_ratio = Blue team残存エージェント数/Blue team初期エージェント数
= Blue team残存群数/Blue team初期群数
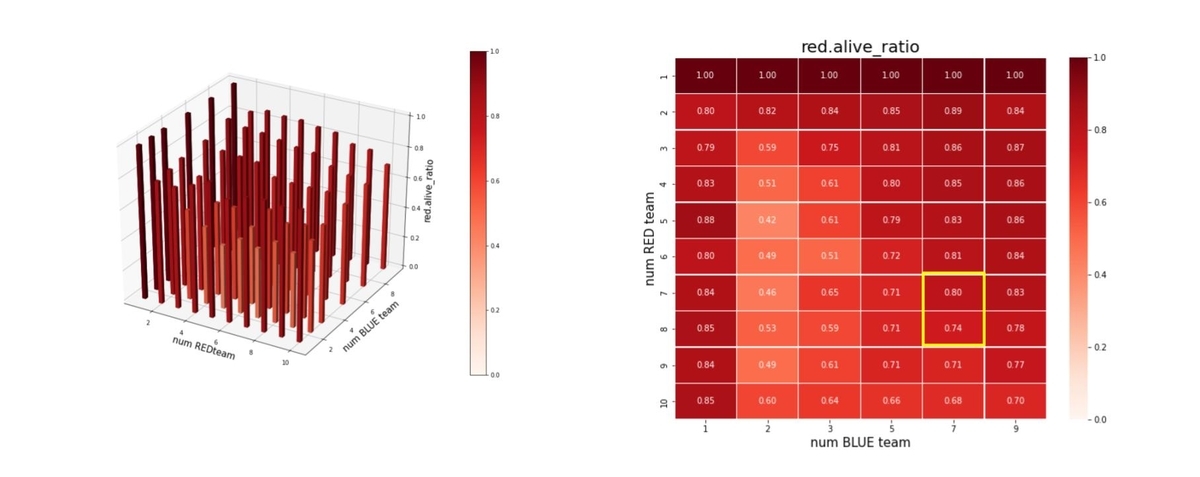
Red team については、下図になります。red_alive_ratio は以下で定義しました。
red_alive_ratio = Red team残存エージェント数/Red team初期エージェント数
= Red team残存群数/Red team初期群数
上記をもう少し分析します。成功率、引き分け率を以下で定義することにします。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
draw = どちらの tem の残存兵力も0にならなかったエピソード数/全エピソード数
これらをバーグラフと heatmap にしたのが下図です。
Blue teamが少数の巨大な群になると成功率が急激に下がり、引き分け率が急激に増加します。失敗率が下がるのではなく、引き分け率が増加するので、Red team のエージェントは、「戦いもせずにウロウロしているだけ」、といった状態になります。
エピソード長で見てみます。戦場サイズが 10x10 なので、上手く戦っていれば平均10~20ぐらいのエピソード長で戦闘は終了するはずです。
Blue teamが少数の巨大な群になると、エピソード長は急激に長くなり、エージェントが戦おうとせずに右往左往しているのが分かります
生成された戦術例
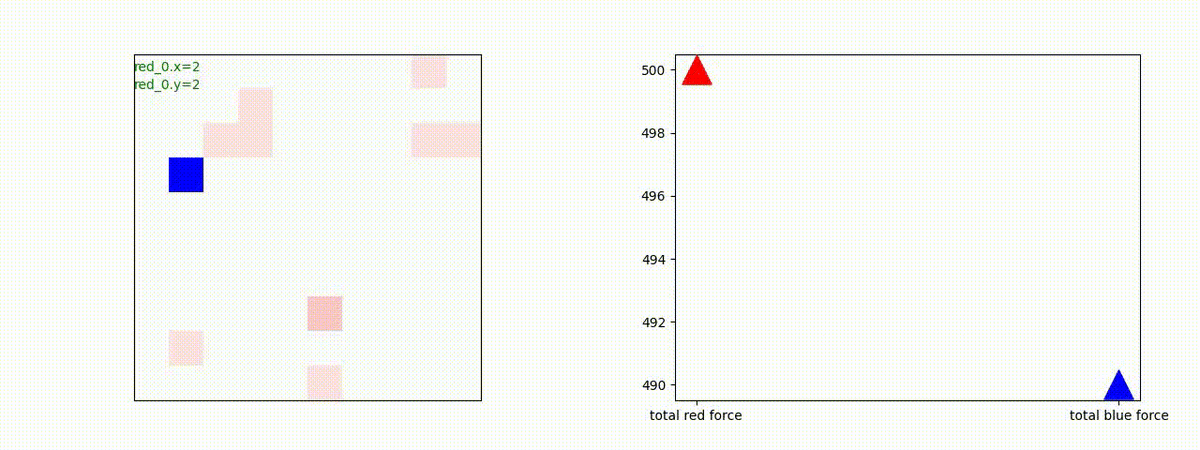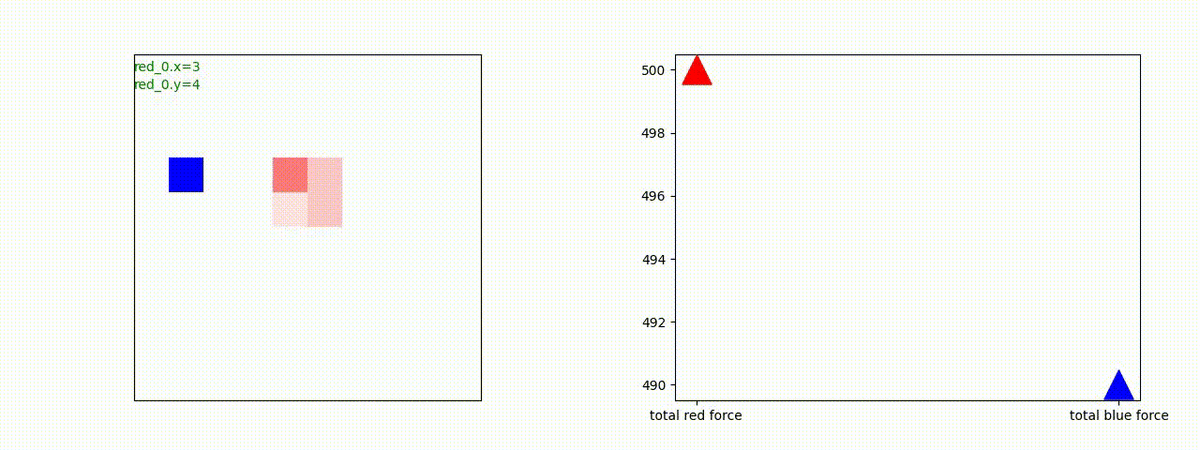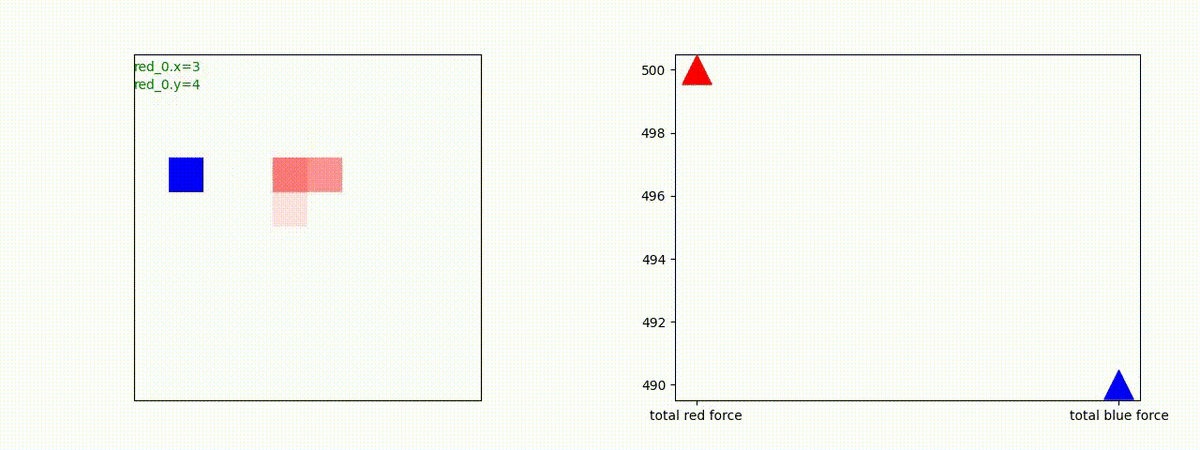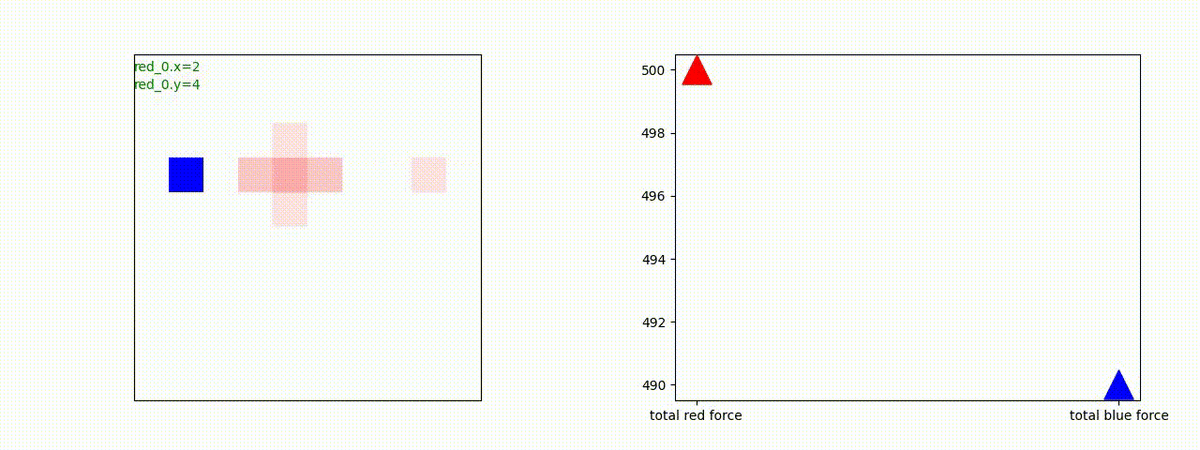
Red team = 1 swarm vs Blue team = 1swarm
Blue team が少数群の初期状態の場合、やはり、red team は上手く戦えません。
Red team = 10 swarms vs Blue team = 1 swarm
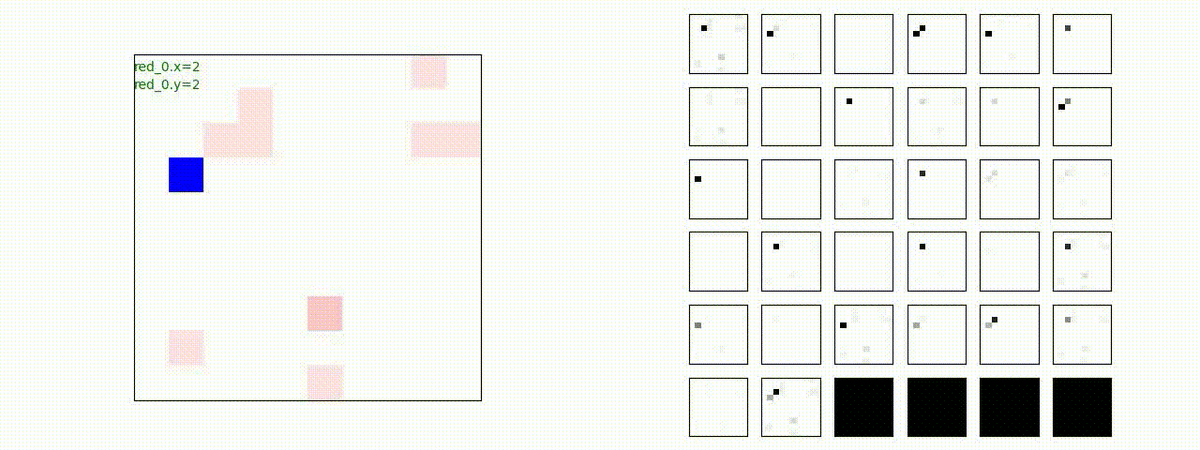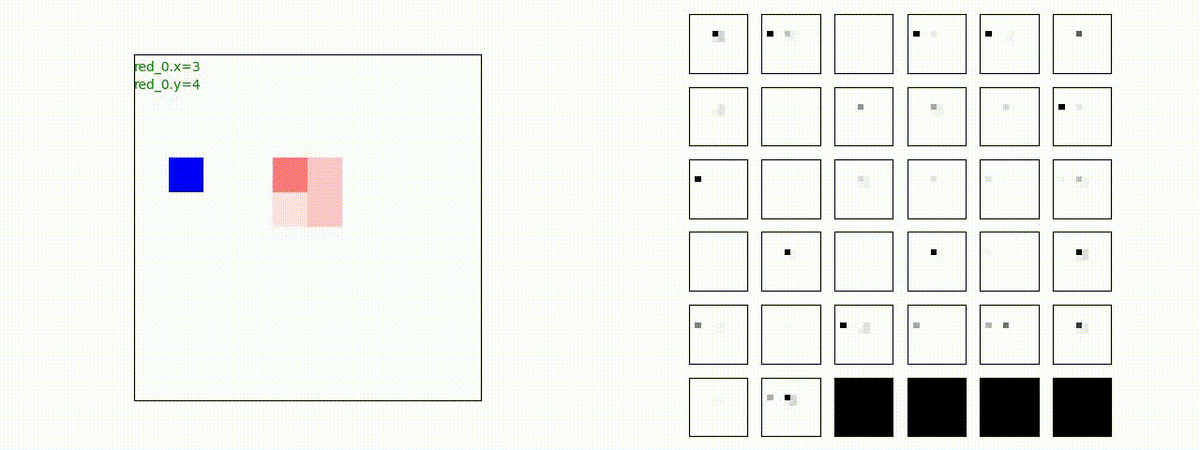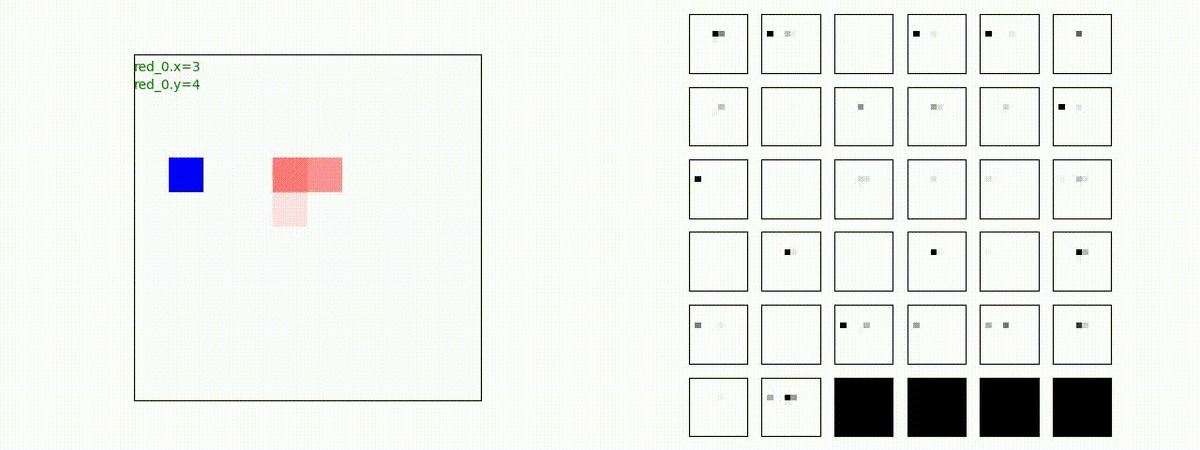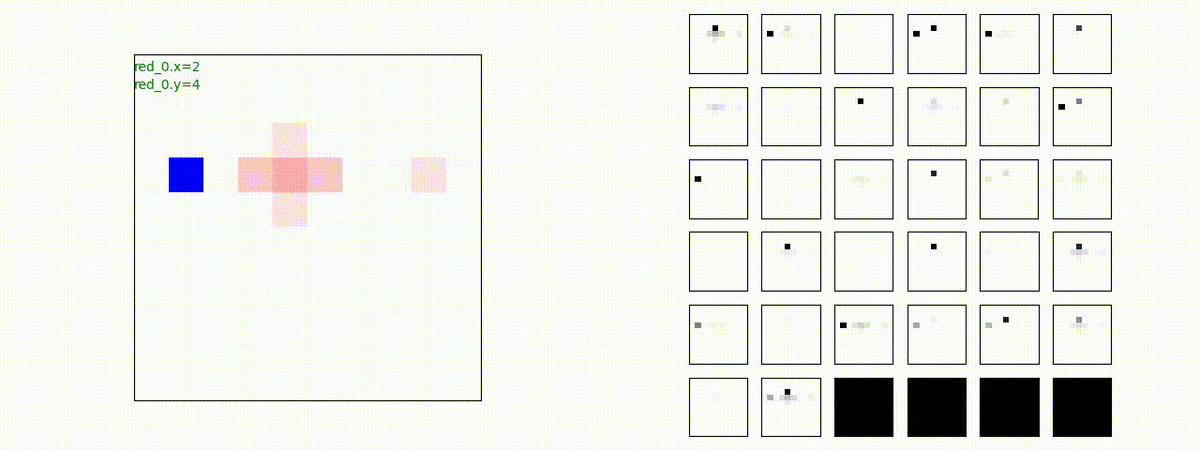
Red team = 1 swarm vs Blue team = 10 swarms
Blue team が多数群に分割されていれば、問題なく戦える戦術が生成されます。
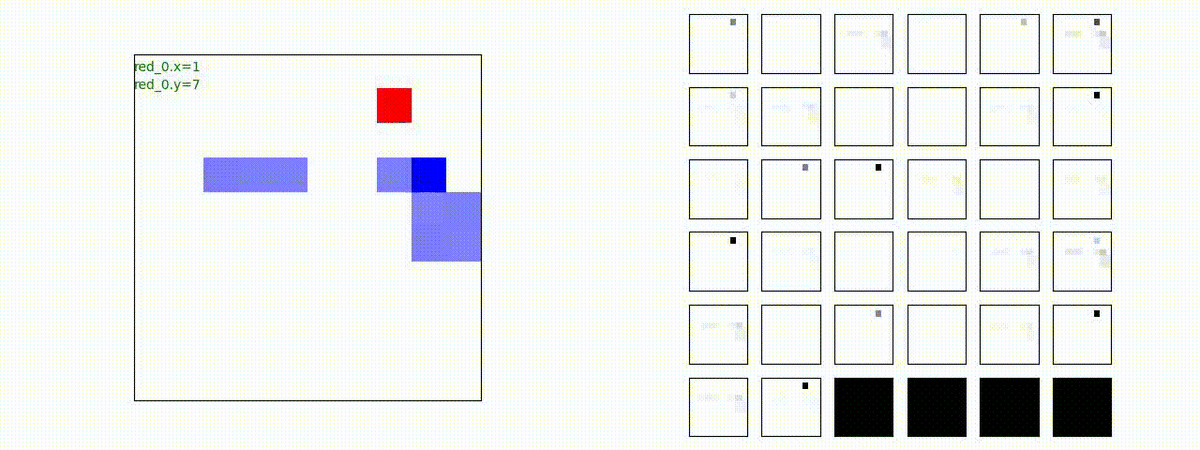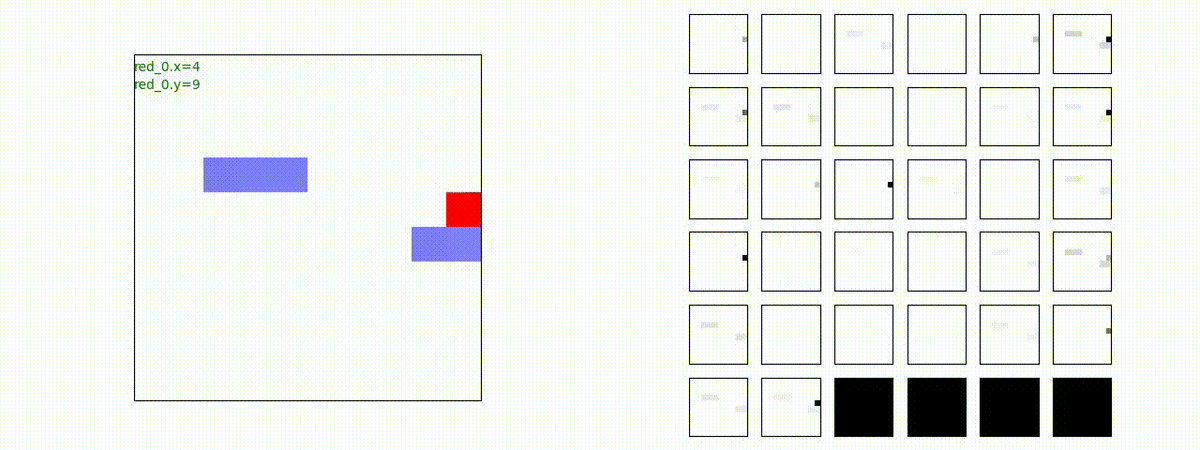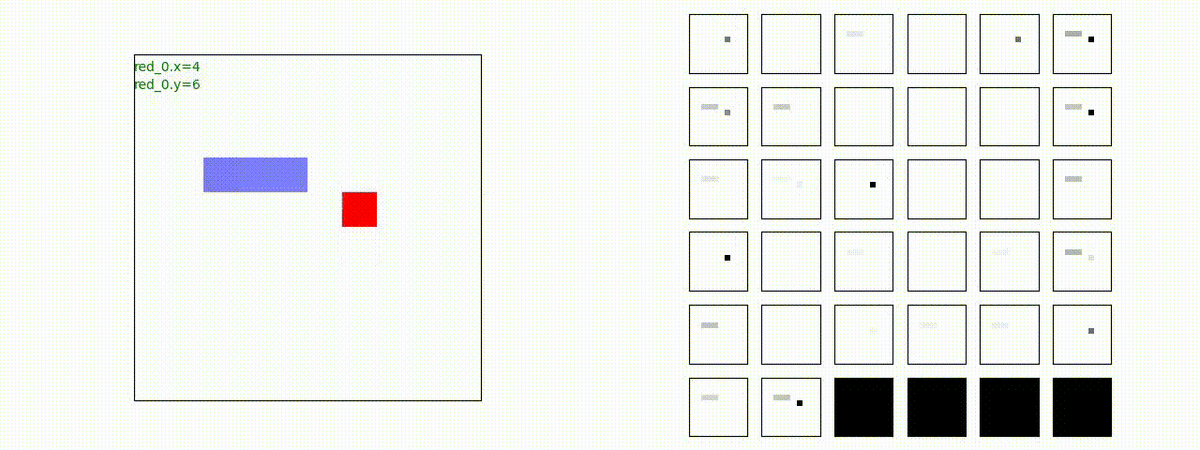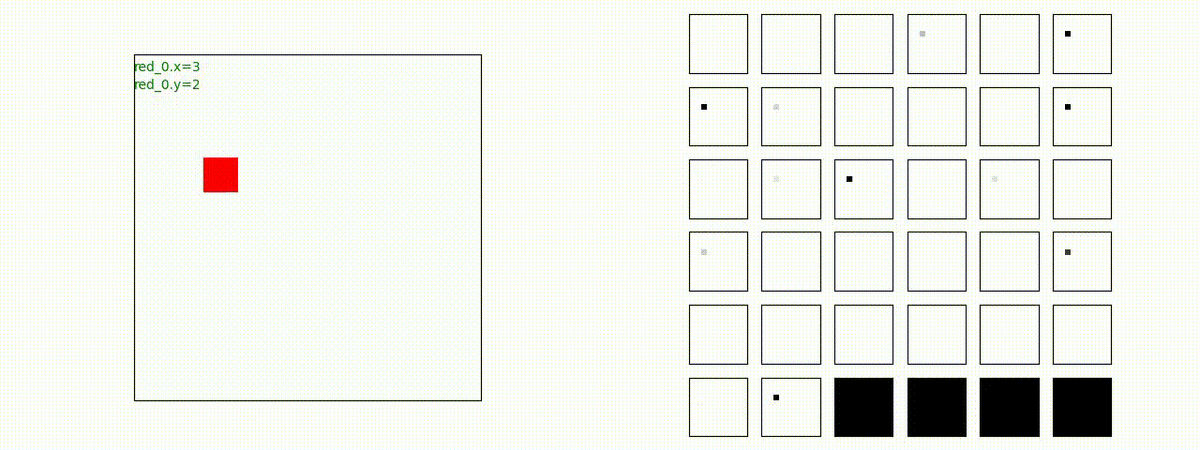
Red team = 3 swarms vs Blue team = 3 swarms
トレーニング条件の半分ぐらいの群数への外挿に対しては、問題なく戦える戦術が生成できます。
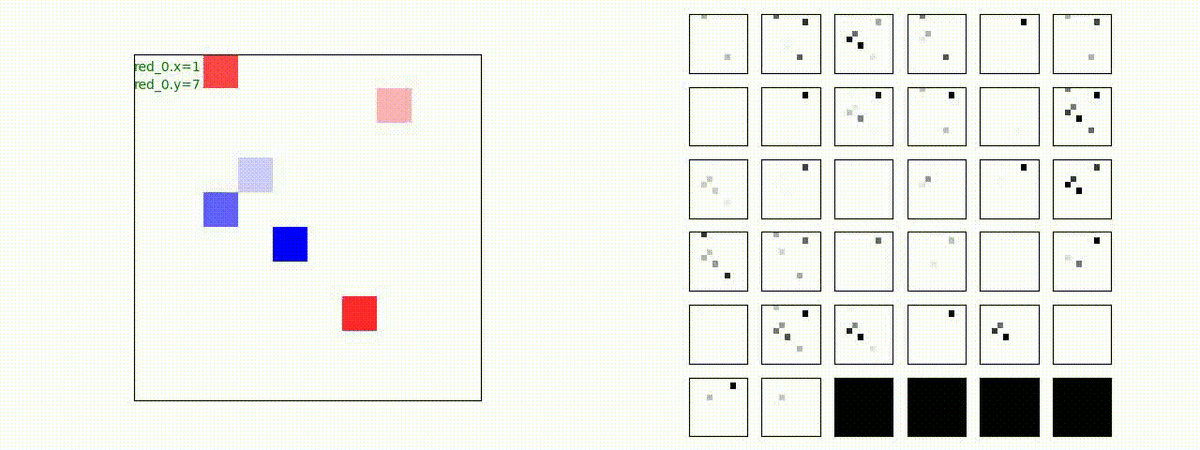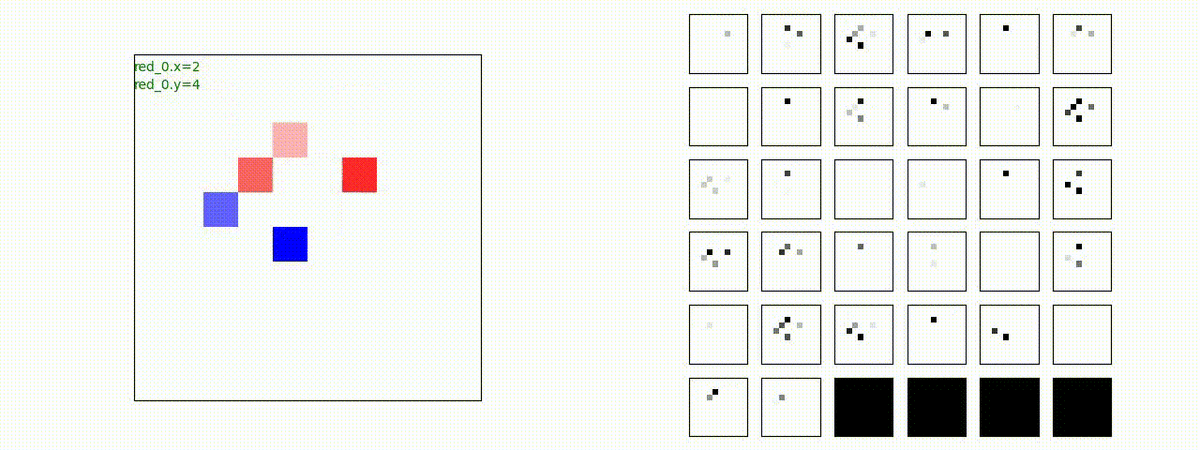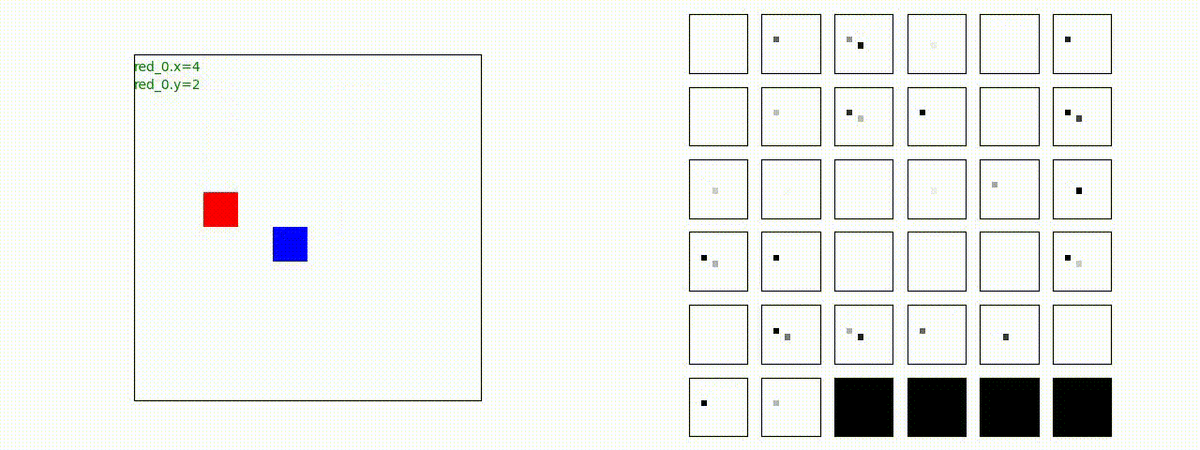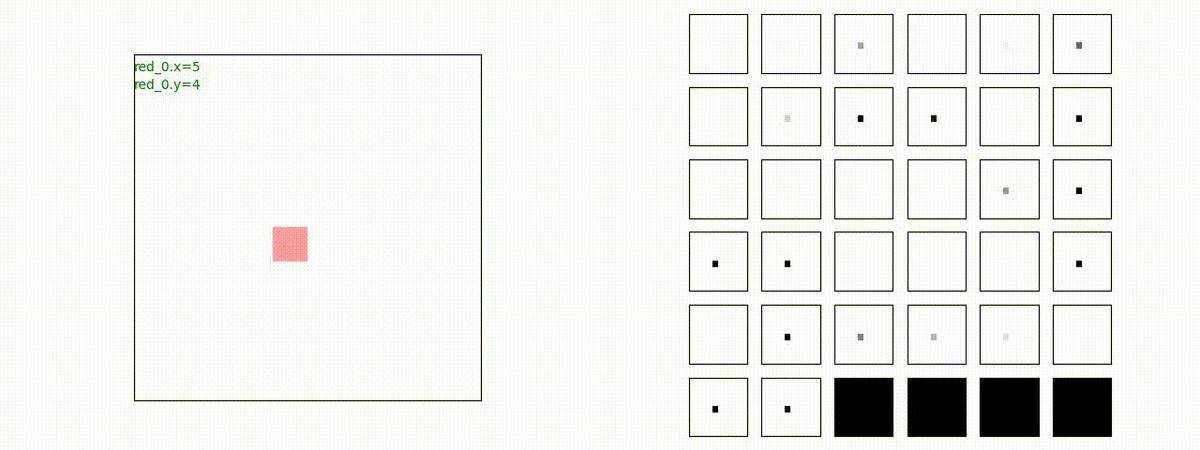
Red team = 5 swarms vs Blue team = 5 swarms
完全に一丸とまでは行っていませんが、うまく戦う戦術を生成したいます。
少数群vs少数群で訓練した結果との比較、及び将来の発展性
少数群vs少数群で訓練した結果と比較してみます。
Blue team の残存兵力で見ると、少数群vs少数群で訓練した Red teamに対しては下図でした。
一方、多数群vs多数群で訓練したRed teamの場合、Blue teamの残存兵力は下図でした。
これらから、敵を殲滅する平均的な汎化能力は、この範囲であれば、少数群 vs 少数群で訓練したteamのほうがやや優れていると言えます。これは、特に、強力な相手に、小分けになった多数の群で当たるには、
- 多数の群が一丸となって攻撃する、
- 多数の群のタイミングを合わせる、
必要があるのですが、彼我ともに多数群の初期条件だけでトレーニングした場合は、これが学習しきれないためと思われます。
ただ、少数群vs少数群で訓練したteamの方が平均的な汎化能力が優れていると言っても、あくまで比較の問題です。平均エピソード長を比較してみると、少数群 vs 少数群で訓練したRed teamに対しては、
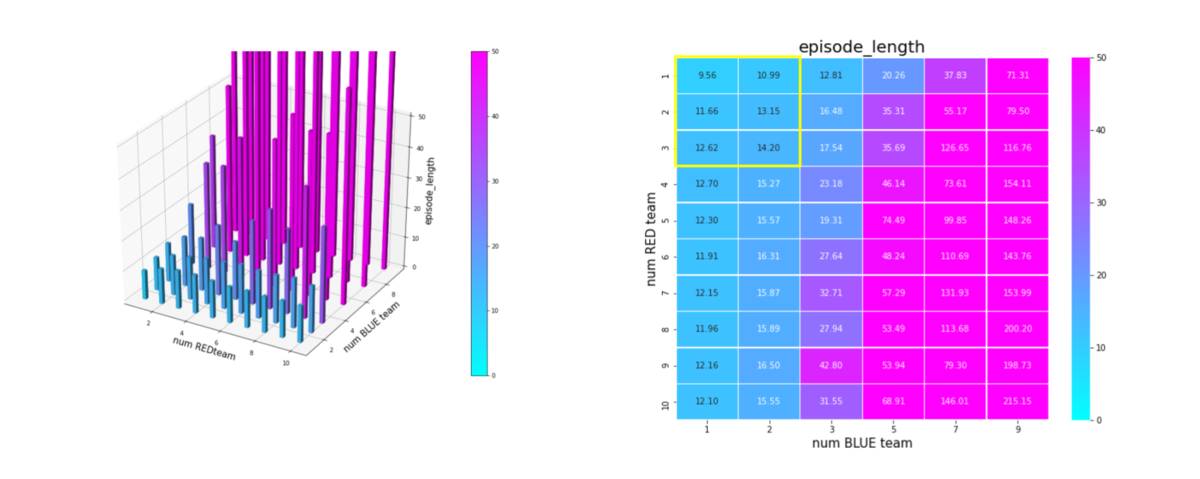
多数群vs多数群で訓練したRed teamに対しては、
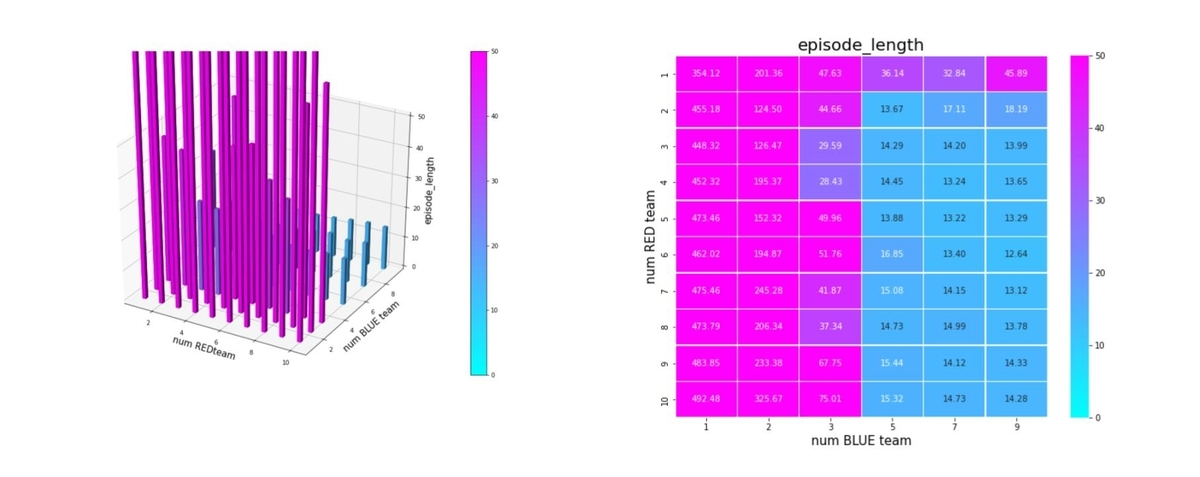
となっていますので、訓練時の環境から離れると右往左往するのは間違いありません。
纏めて言うと、トレーニング時の条件の倍や1/2倍程度のエージェント数までの外挿であれば対処できますが、それを超えた外挿になると厳しくなってくるようです。
結果を踏まえて発展性を考える
これらの結果から、以下のような方向への発展が考えられます。
少数群 vs 少数群で訓練したRed team のニューラルネットを「エキスパート1」、多数群 vs 多数群で訓練した Red team のニューラルネットを「エキスパート2」と呼ぶことにします。
この時、下図のように、セレクタ・ニューラルネットを使って戦況に応じて、2つのエキスパートを切り替えて使う方法が考えられます。セレクタ・ニューラルネットの強化学習時には、既に学習させた2つのエキスパート・ニューラルネットは固定します(学習しないようにします)。
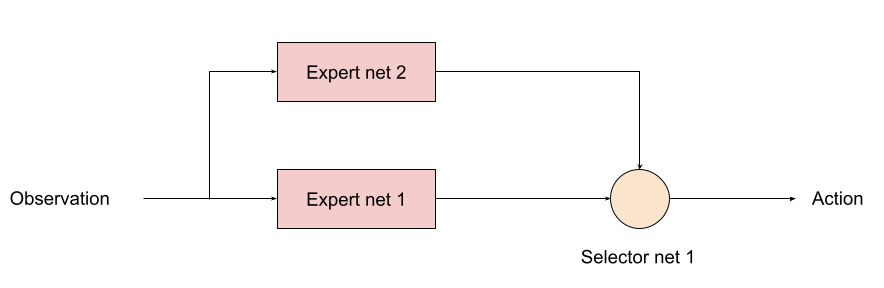
これを、もっと格好良く、まとめてやってしまう階層型強化学習(Hirerarchical reinforcement learning、下記に参考文献を示しました)という世界もあるのですが、本件ぐらいのアプリケーションであれば、セレクタ型で対応できる気がします。
[1609.05140] The Option-Critic Architecture
[1710.09767] Meta Learning Shared Hierarchies
[1703.01161] FeUdal Networks for Hierarchical Reinforcement Learning
[1811.11711] Neural probabilistic motor primitives for humanoid control
[1805.08296] Data-Efficient Hierarchical Reinforcement Learning
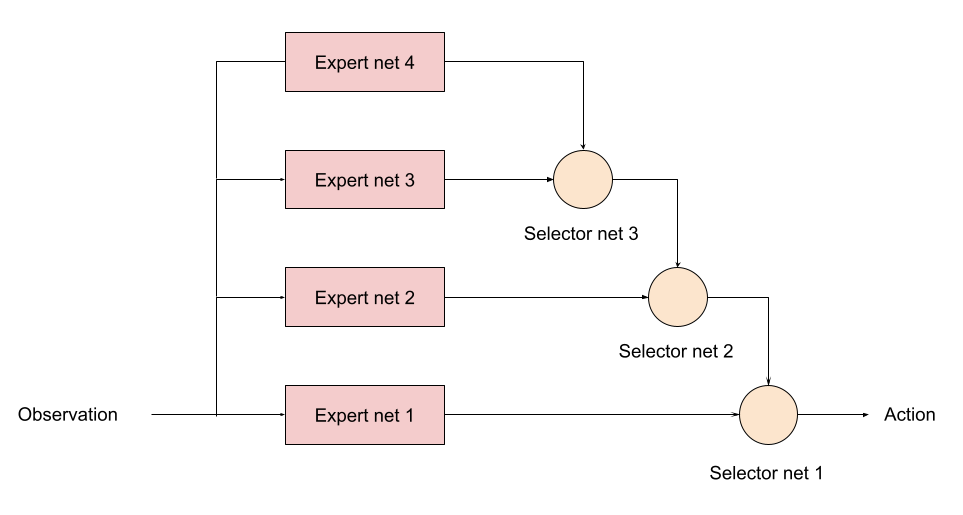
また、工業製品の観点から見ると、エキスパートが増えた場合に、セレクタ型であれば、もう一度学習をやり直すのではなく、下図に示す Subsumption architecture のように、既存の固定したネットワークに順次エキスパートとセレクタを追加していくことが出来るはずなので非常に便利だと思われます。(コーディングもずっと楽です)。
これについては、ひと段落したらやって見ようと思います。
まとめ
- Red team の初期エージェント数(群数)を [7, 8]、Blue team の初期エージェント数(群数)を [6, 7] として、多数群 vs 多数群の設定でネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、完璧ではありませんが、"mass" を構成して戦う戦術を学習でき、上手く戦況をハンドリングできている(ほとんどいつも Blue team を殲滅できる)ことが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を外挿方向に減らして(つまり、戦力の大きな少数群にして)戦闘性能がどの程度劣化するのか見てみました。
- (その3)、(その4)の結果から、将来の研究の方向性として Subsumption architecture likeなアーキテクチャを提案しました。(提案だけで、未実施です)。
過去2回の実験は、少数群 vs 少数群、或いは多数群 vs 多数群といった比較的ダイナミックレンジが狭い群数でトレーニングしました。この結果、「少数群 vs 少数群」用エキスパート、或いは「多数群 vs 多数群」用エキスパートのようなマルチエージェント・システムがトレーニング出来ました。
では、Red team, Blue teamのトレーニングに使用する群の数のダイナミックレンジを増やした場合、性能はどうなるのでしょうか。これも興味があります。次回記事では、これを評価してみます。