マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その5):少〜多数群で訓練する
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
(その3)では「少数群 vs 少数群」、(その4)では「多数群 vs 多数群」でトレーニングを行いました。その結果、それぞれにおいて、各エージェントは、ある程度の汎化能力を有する少数群戦闘エキスパート、多数群戦闘エキスパートのように学習できることが判りました。また、それらをセレクタを用いて、Subsumption architectureのような構造で組み合わせて用いる案を示しました。
今回は、これら両方の群数をカバーする、広いダイナミックレンジの群数での戦闘によってトレーニングを行ってみます。群数のダイナミックレンジが広くなるほど学習は困難になることが予想されるので、本手法が、ダイナミックレンジを広くしても通用するのか確認したいと思います。
実施内容は以下の通りです。
- はじめに、Red team のエージェント数(群数)を [1, 8]、Blue team のエージェント数(群数)を [1, 7]として、ネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、各チームのエージェント数(群数)を外挿方向に増やして戦闘性能がどう変化するのか見てみます。
実行環境
- (その3)と同じ
PPOハイパーパラメータ
- (その3)と同じ
シミュレーション条件
- (その3)と同じ
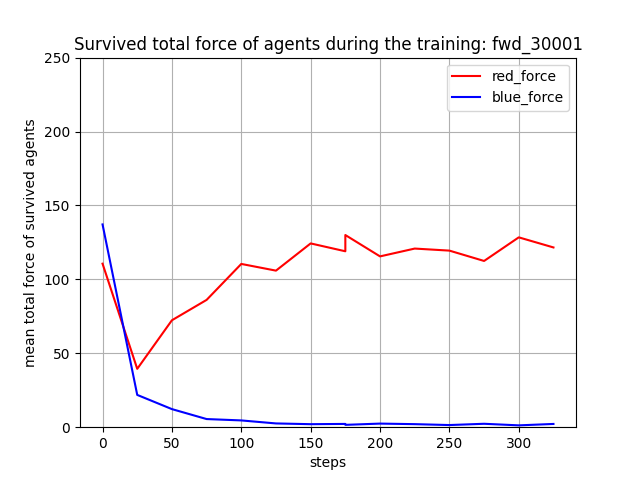
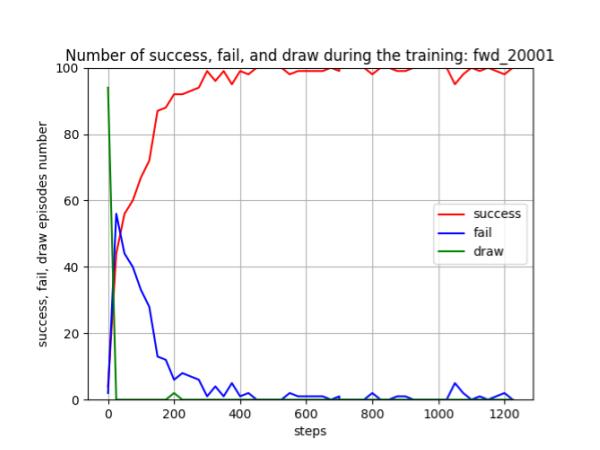
トレーニング履歴
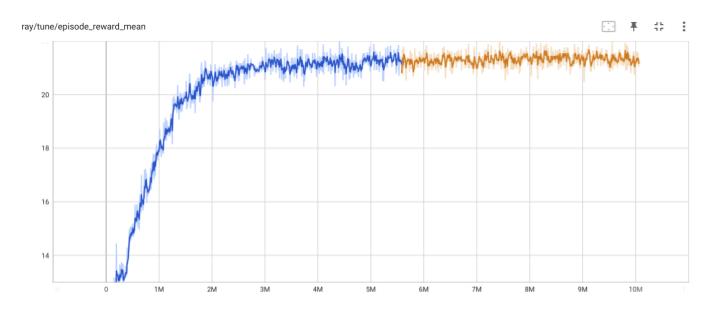
グラフの途中で色が変わっているのは、GCP の Preemptive vm が最大24時間でシャットダウンされてしまうので、シャットダウン後、継続学習を行っているためです。
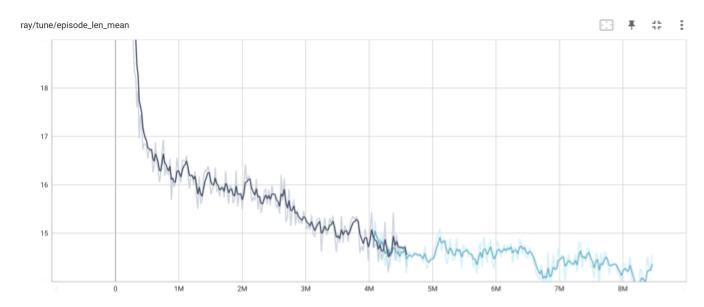
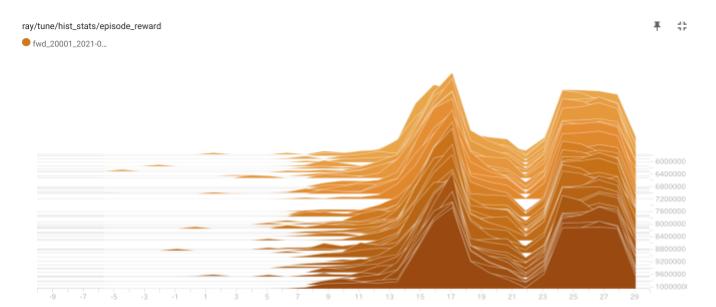
下図で、縦軸はエピソード報酬、横軸が更新ステップです。安定して学習しています。ただし、(その3)、(その4)のエキスパートの学習ほどには安定していません。学習が、より難しくなったということだと思われます。
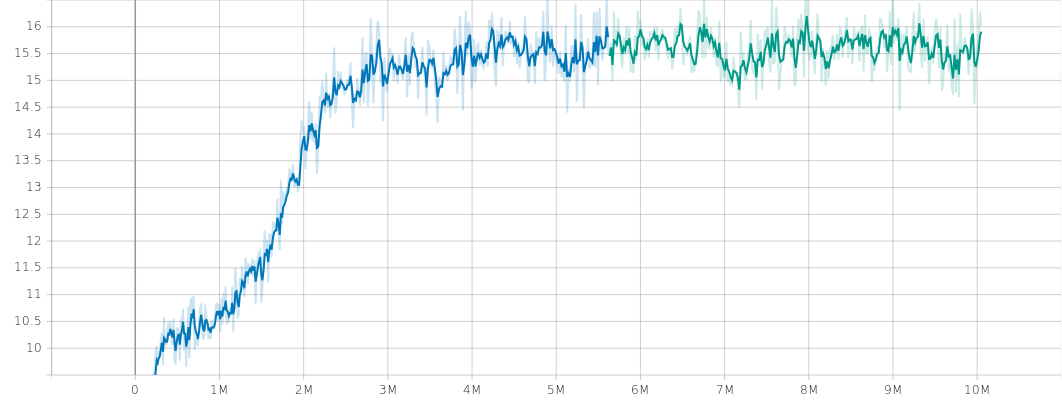
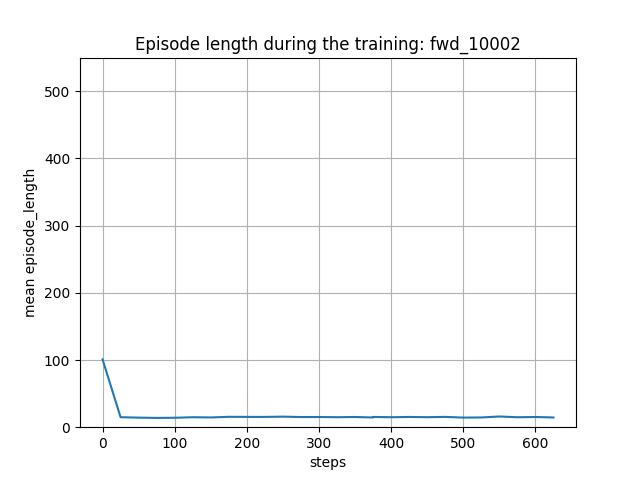
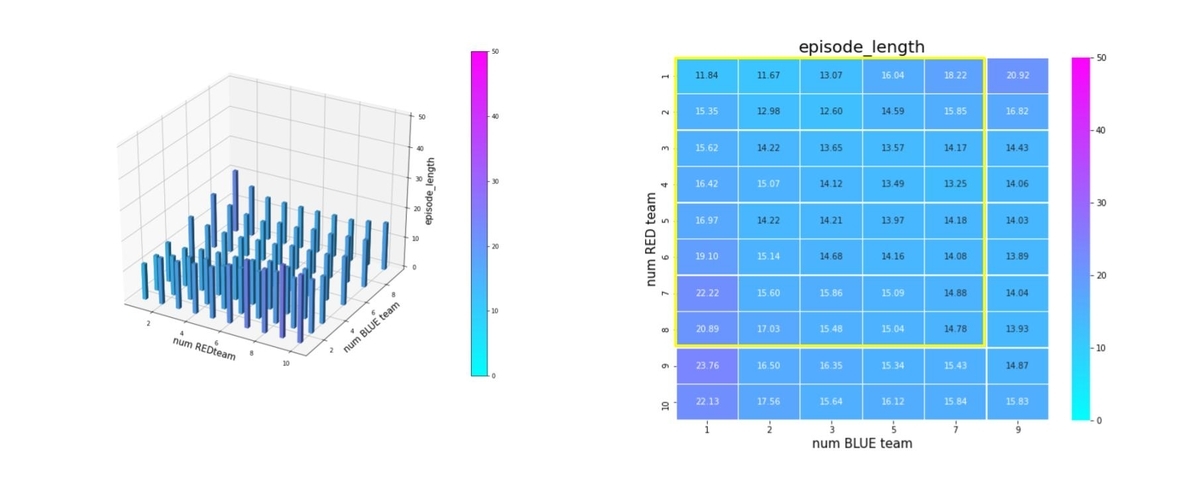
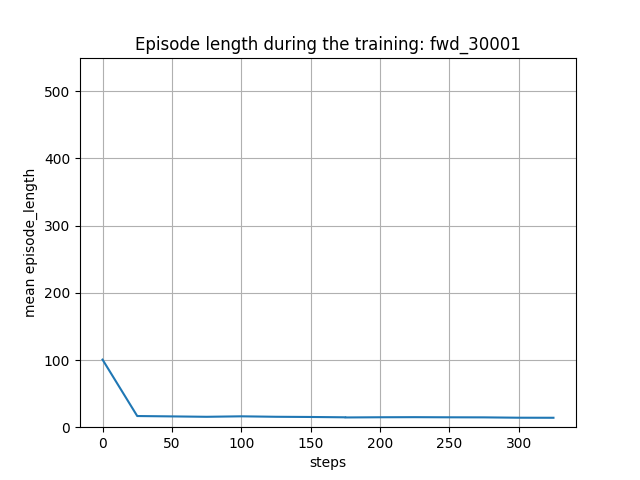
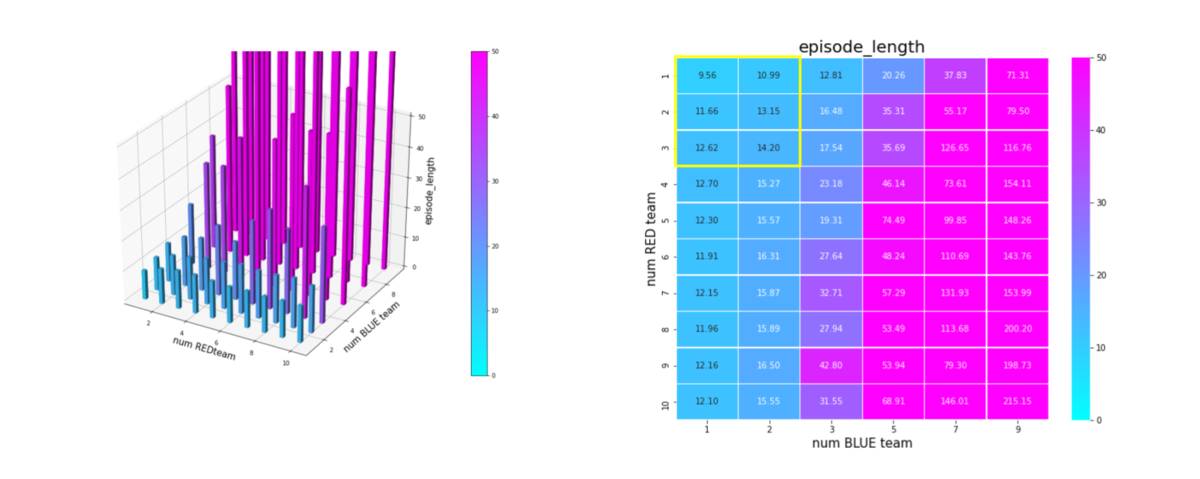
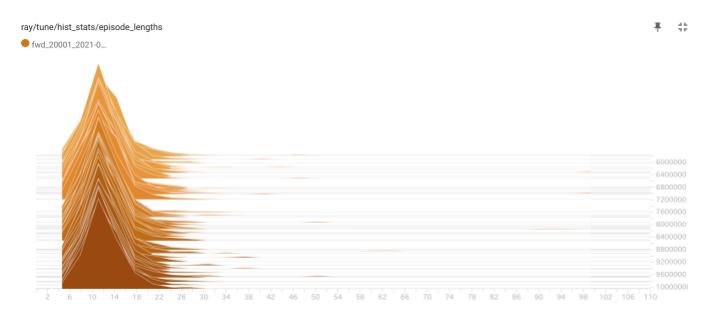
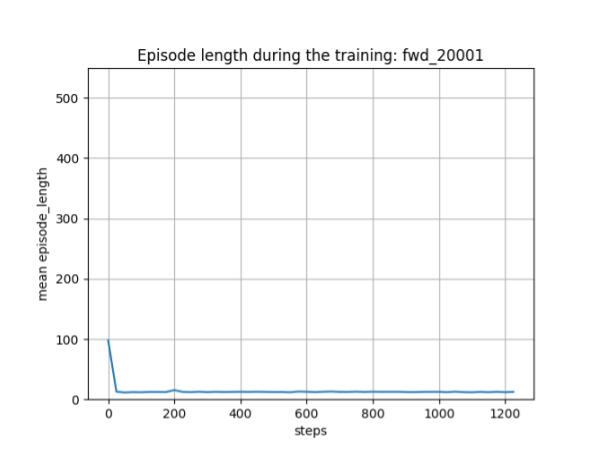
下図は、トレーニング時の平均エピソード長の履歴です。戦場サイズが 10x10 なので、群の数も考慮すると、平均エピソード長が15ぐらいになっていて、妥当ではないでしょうか。
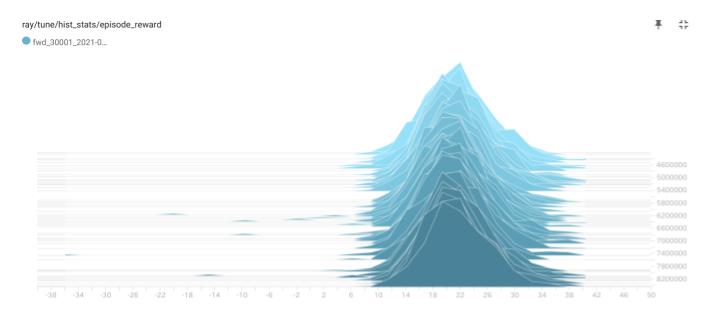
下図は、学習後半のチーム報酬の分布です。
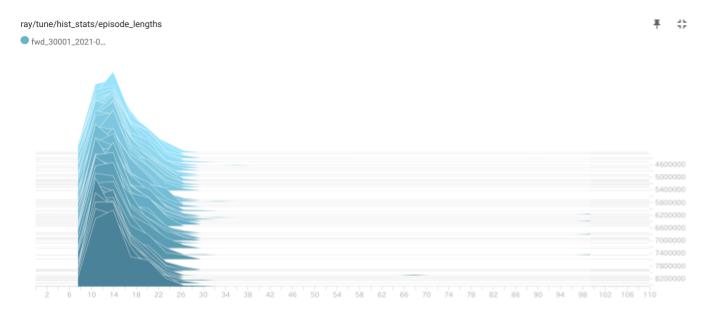
下図は、学習後半のエピソード長の分布履歴です。
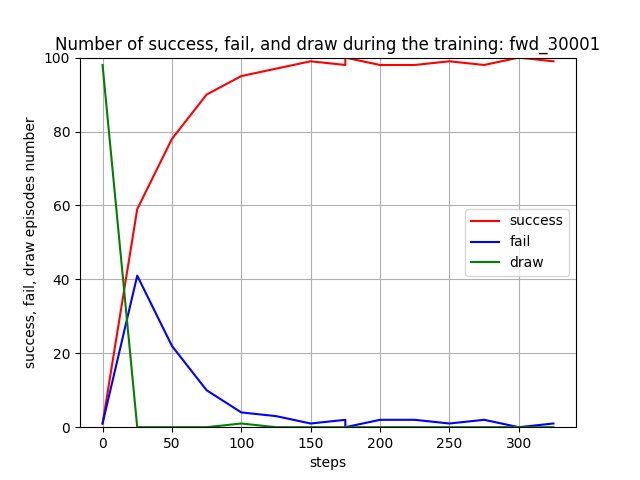
トレーニング時の評価結果
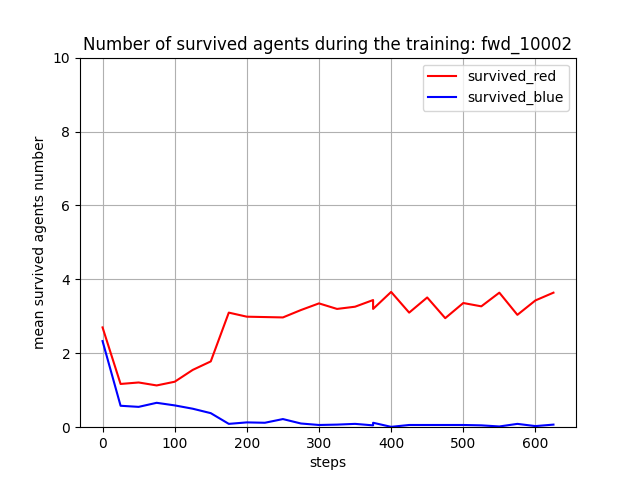
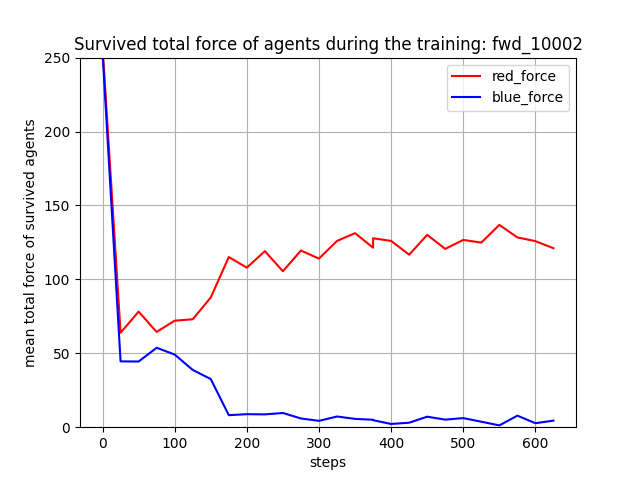
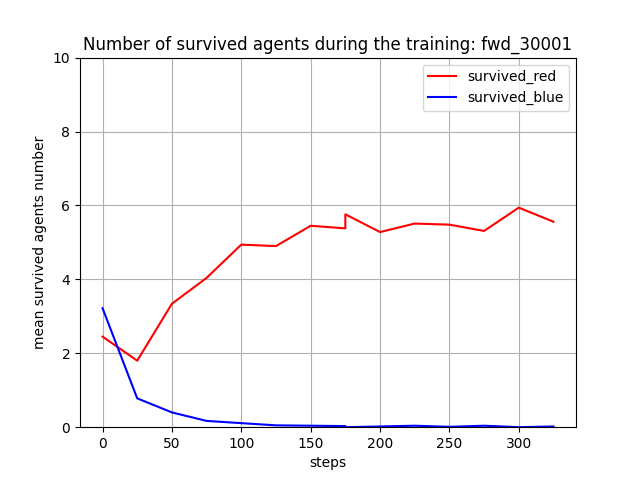
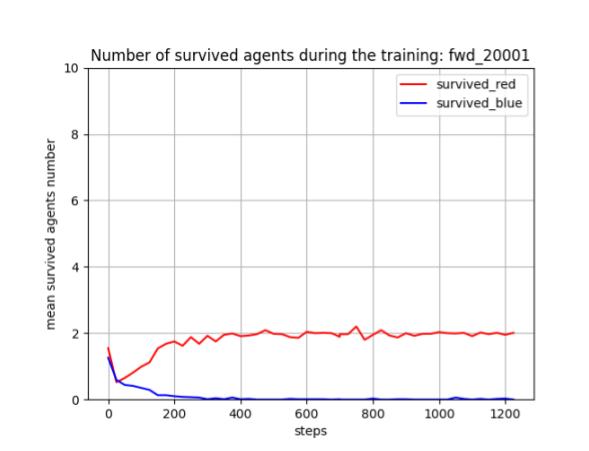
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [7, 8] で乱択しているので、学習が進んだ時の平均残存数=5 ~ 6 は、1~ 2 エージェントが戦闘で消耗することを意味します。
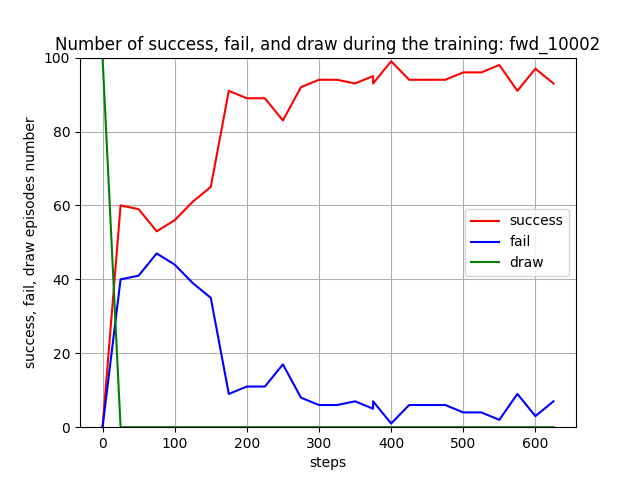
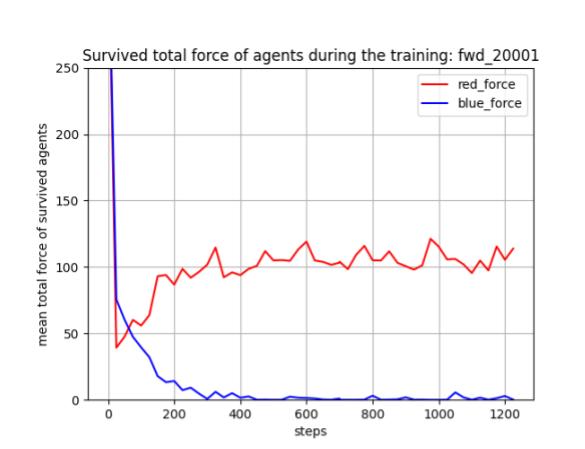
Blue team の残存エージェント数や残存兵力を完全に0にはできていませんが、学習は進んでいるので、手法としてはトレーニング時の群数のダイナミックレンジを拡げても本手法は機能すると考えられます。ただし、評価結果が安定し始めたぐらいの感じがするので、もう少しトレーニングは長くやった方がよさそうです。
性能評価
下表は、学習後のチームの性能を100回のシミュレーションを行って、定量的に確認したものです。ここで、
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
になっています。(これまでと同じです)。
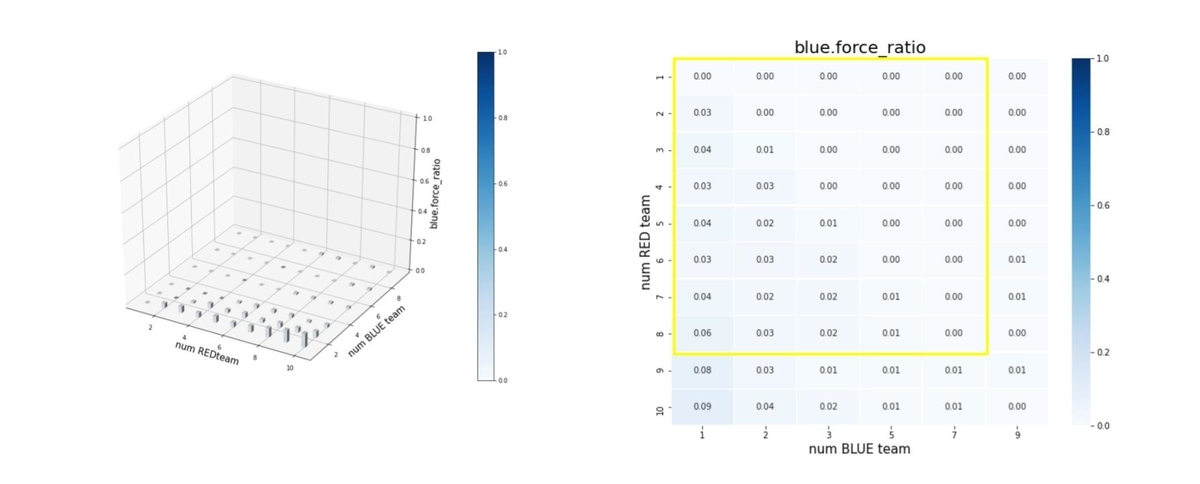
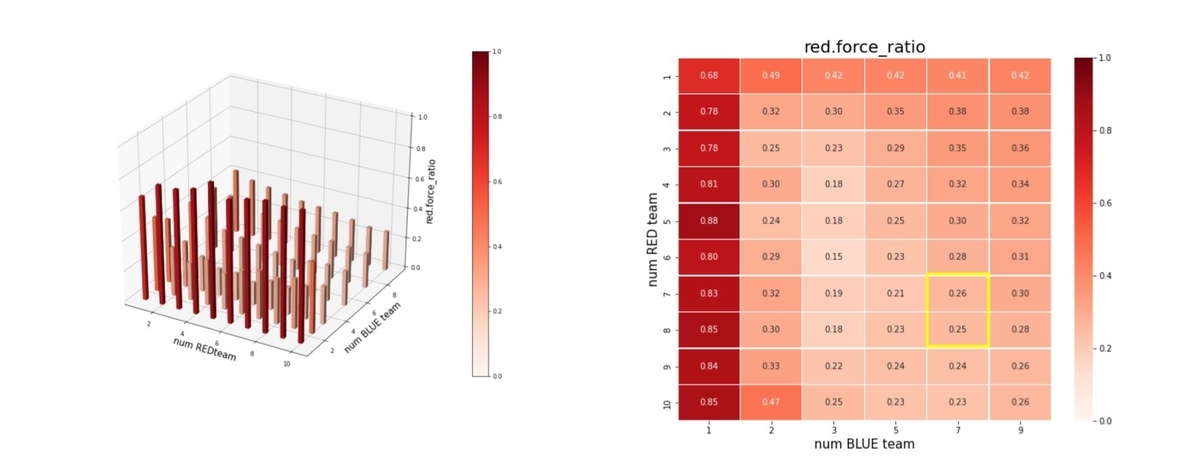
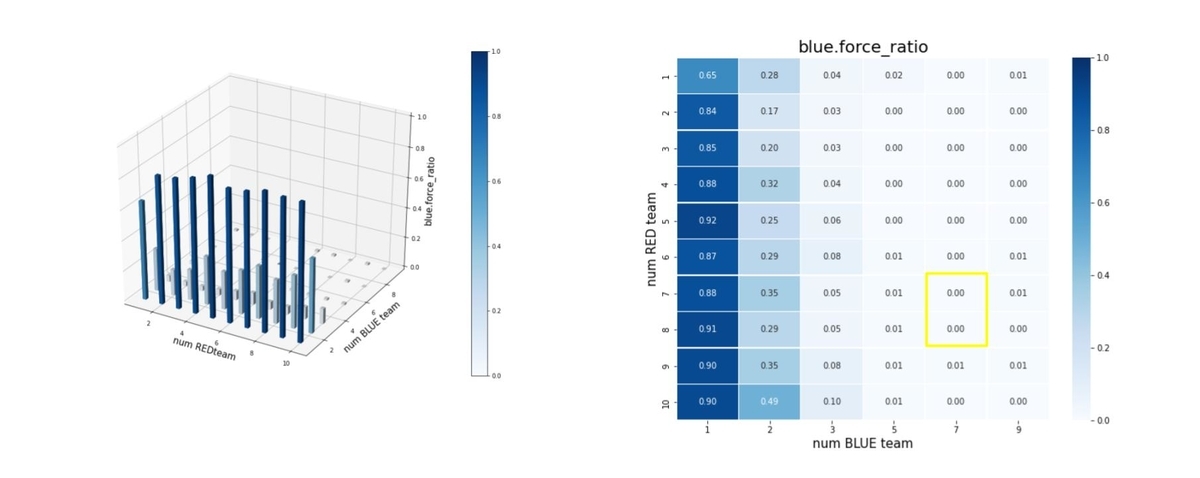
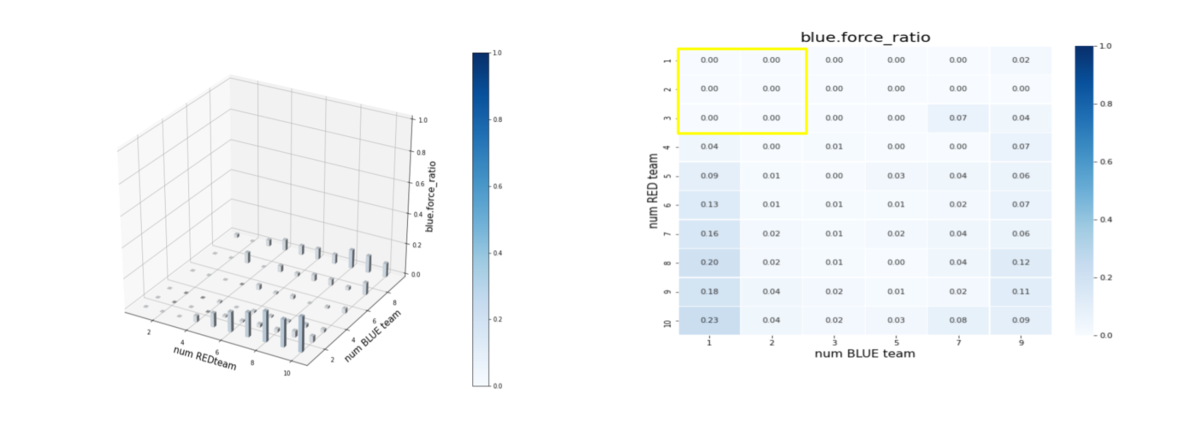
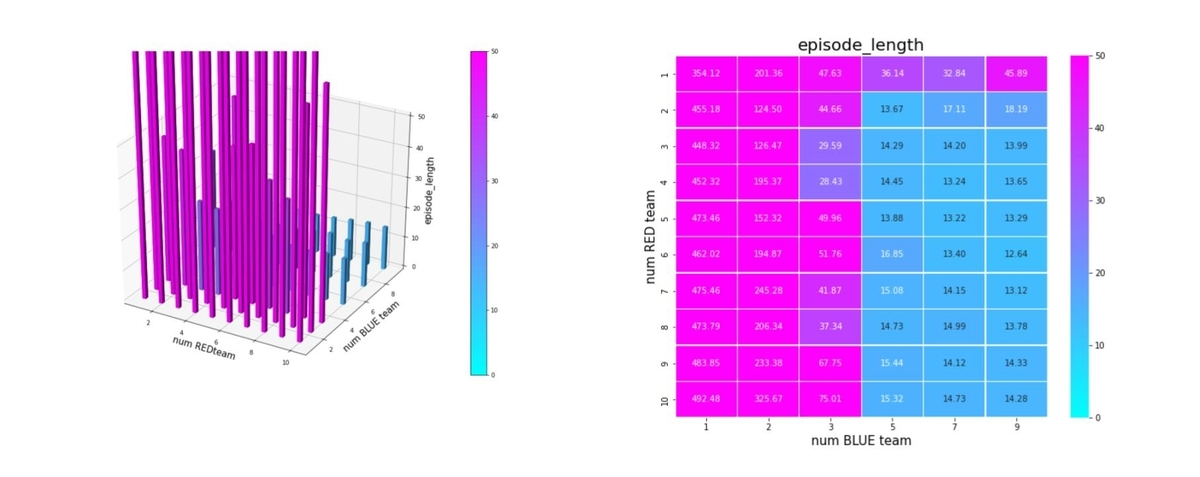
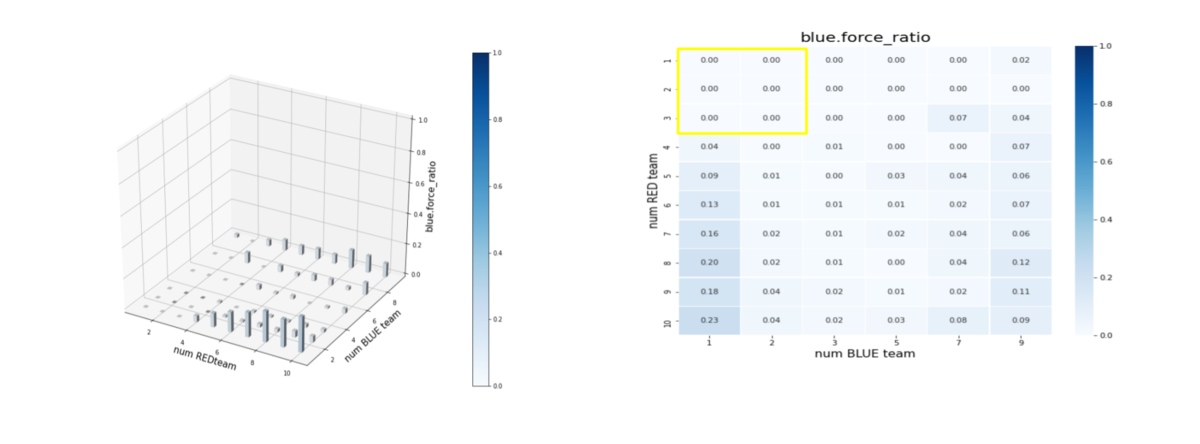
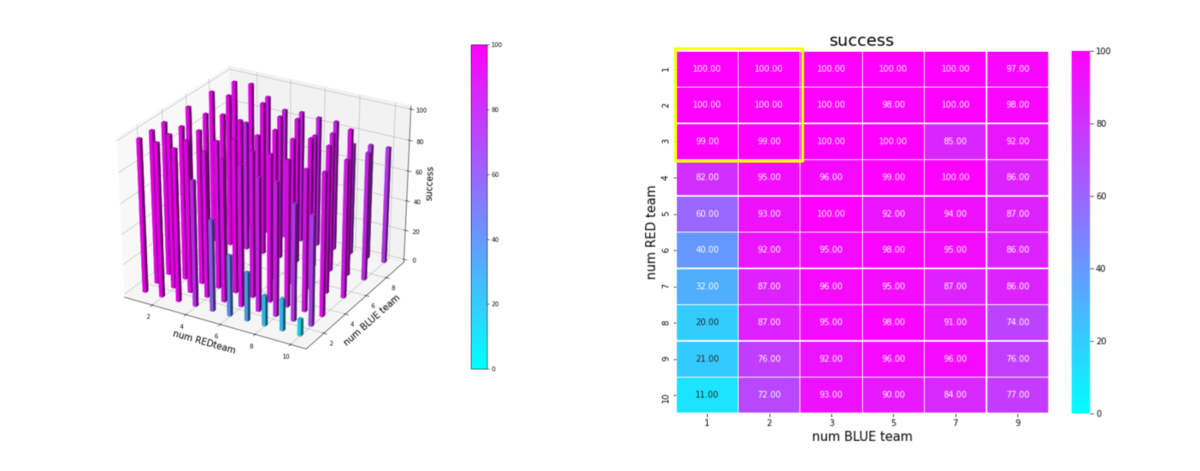
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。ここで、num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸が blue_force_ratioです。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。
Blue teamの残存兵力はかなり小さくできているので、Red teamのエージェントは、彼我の群数が大きく変動しても戦えるような戦術を学習していることが判ります。
図を見ると戦術全体のバランスは悪くはないのですが、特に、少ないエージェント(群)で構成された Blue team に、多数のエージェント(群)で構成された Red team で攻撃するようなシナリオになると、性能が少し劣化しています。やはり、巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するシナリオほど、学習が困難なようです。
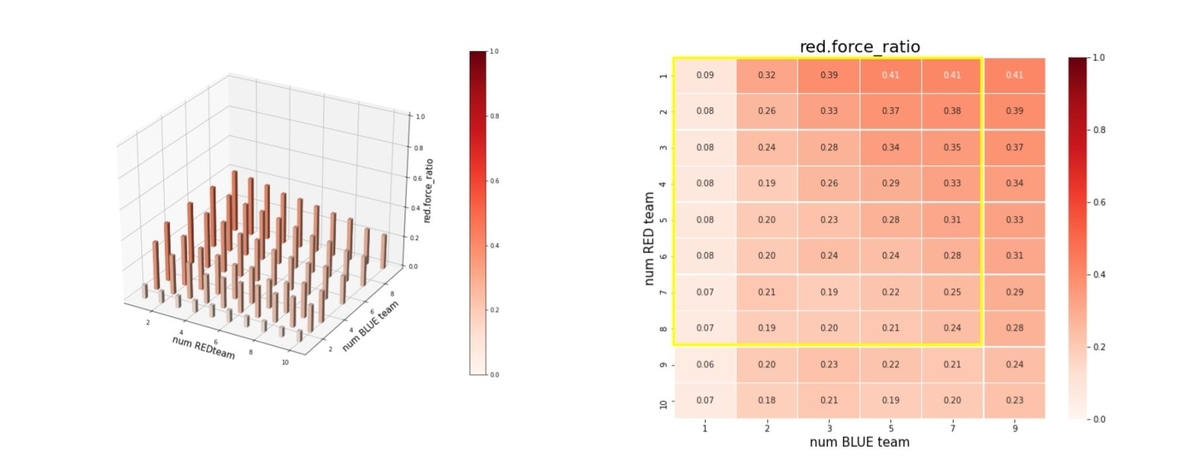
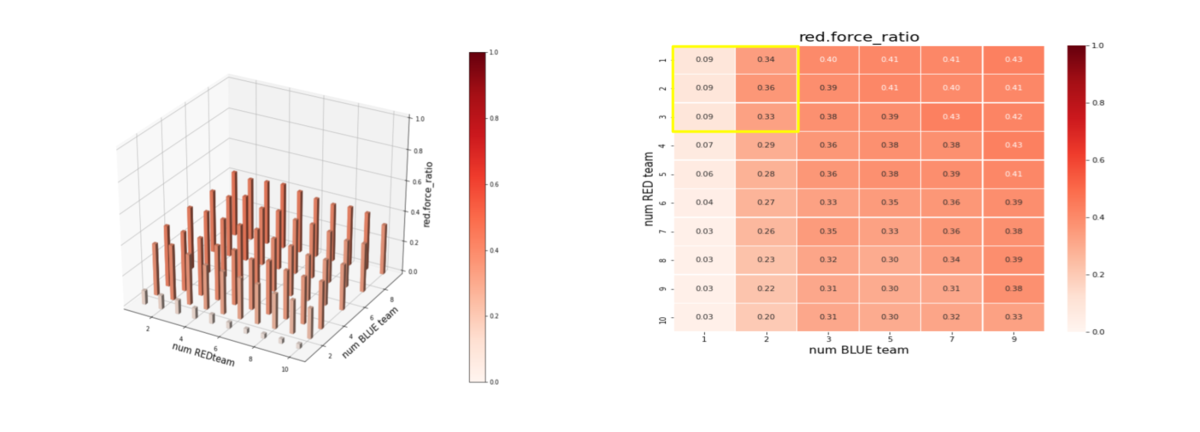
この時の red teamの残存兵力は下図になります。red_force_ratio は以下で定義しています。左図のバーグラフの縦軸が red_force_ratioです。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するケースでは、残存兵力が僅かになっています。
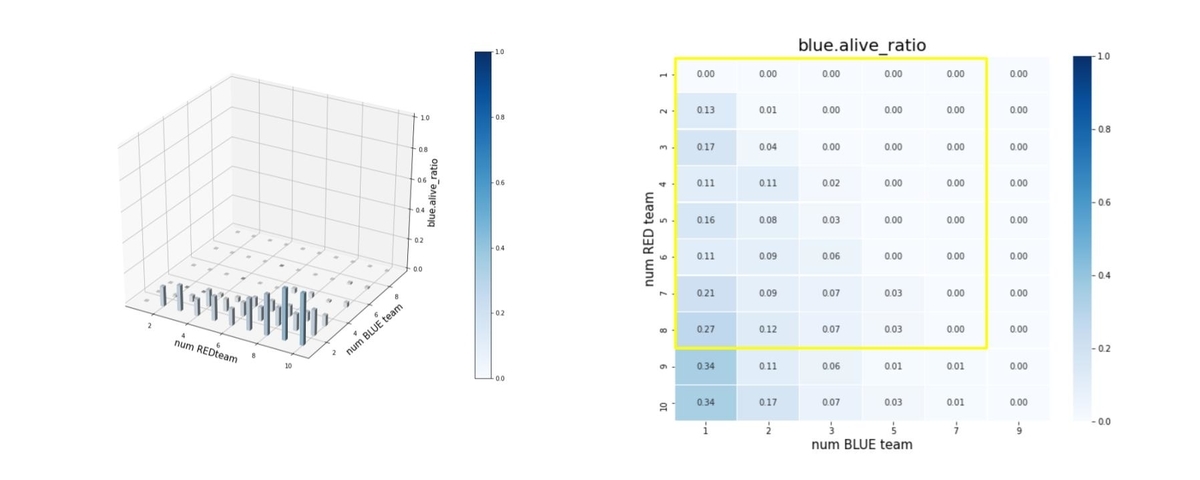
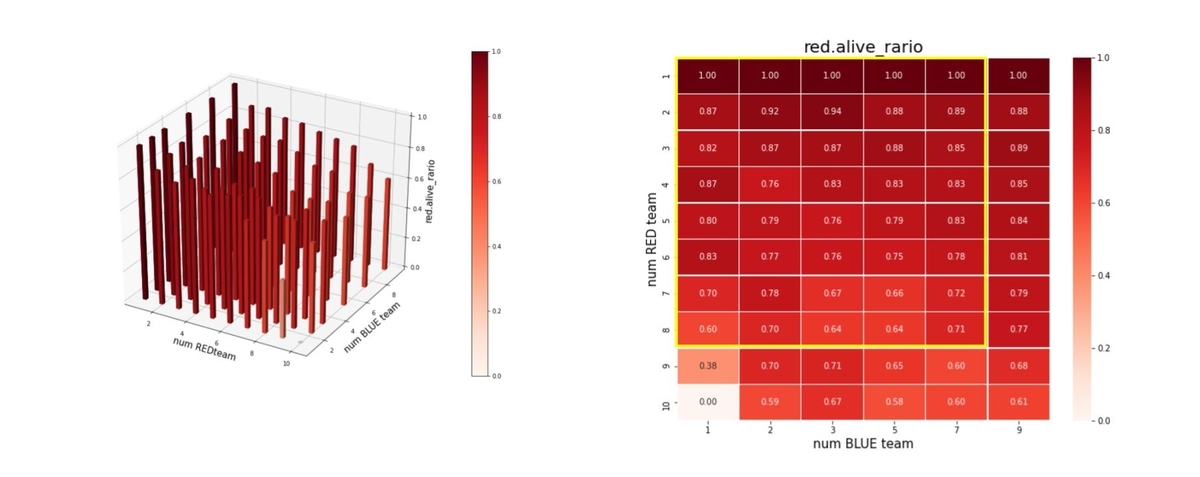
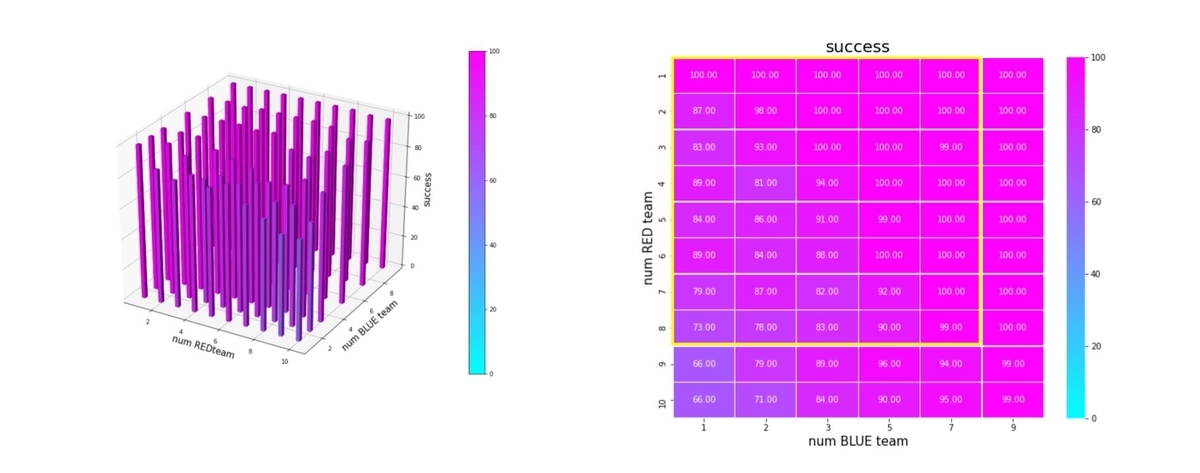
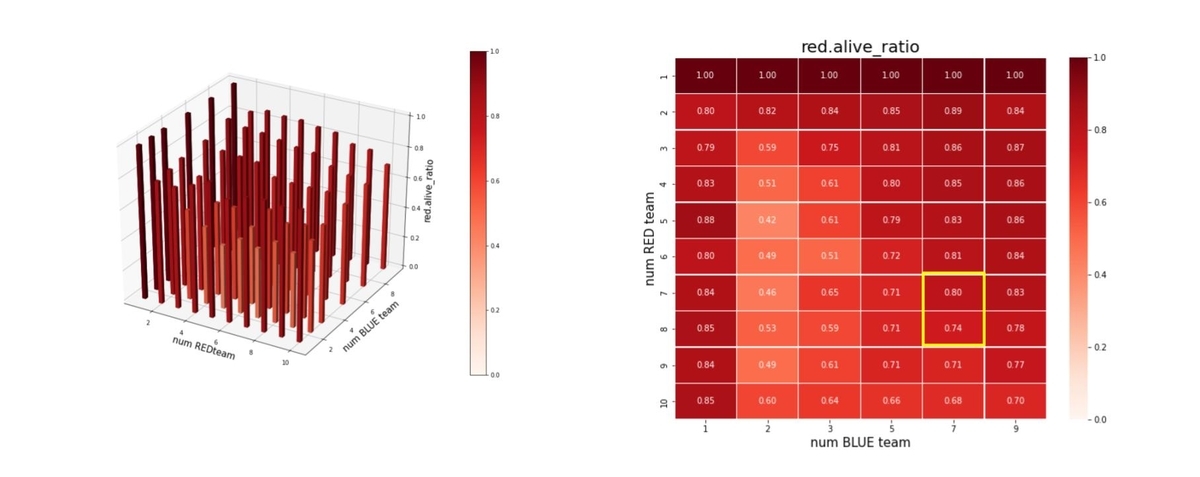
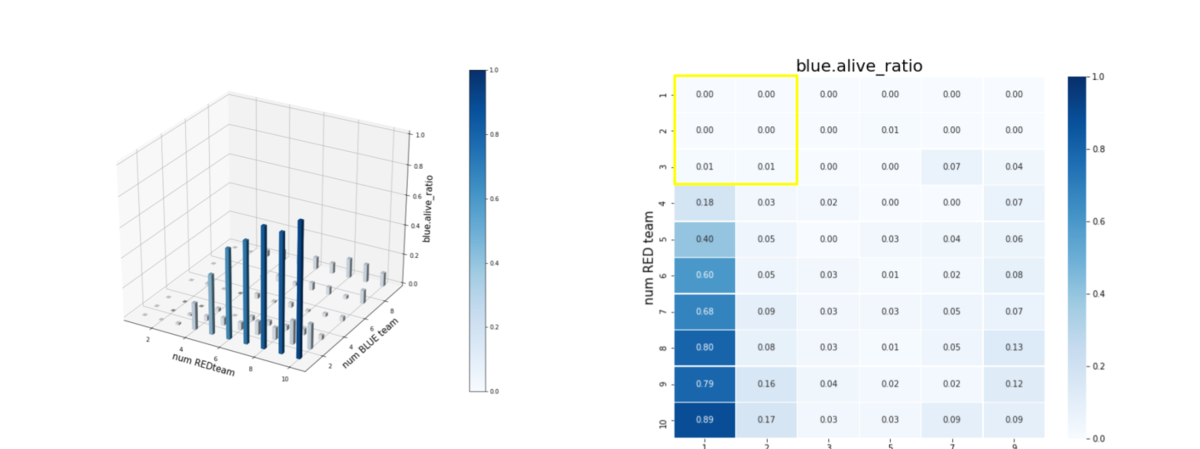
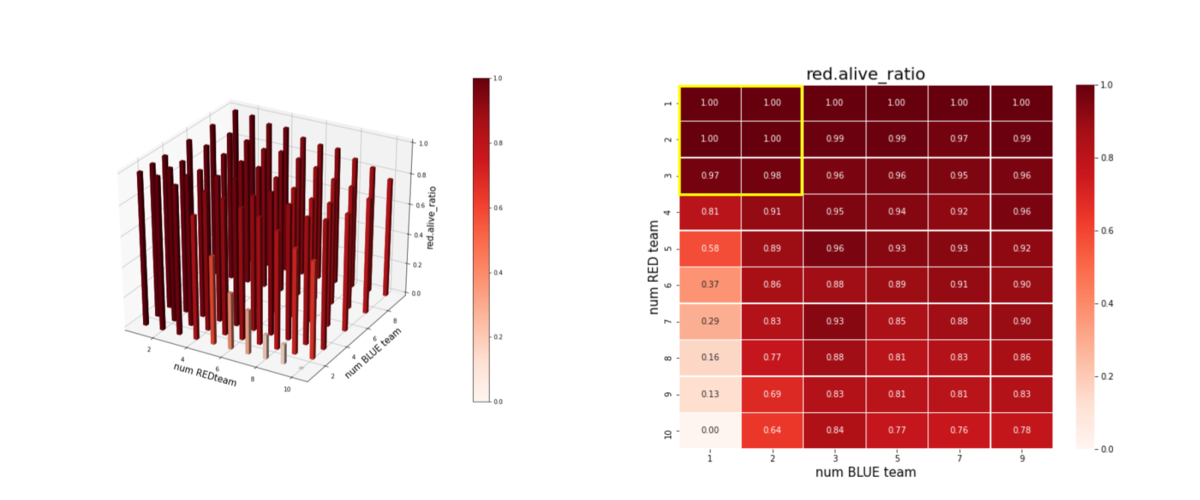
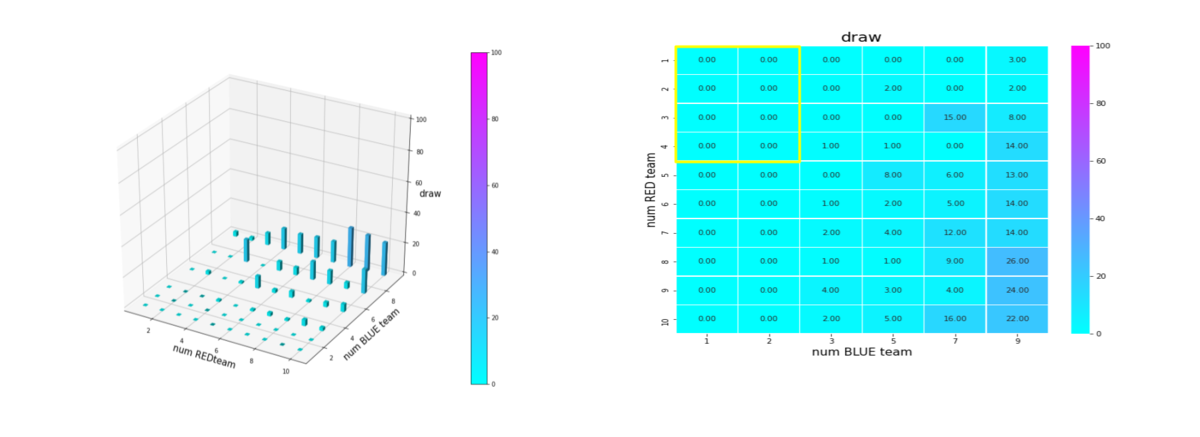
以上のことは、残存兵力ではなく、残存エージェント数からも読み取ることが出来ます。これを下図に示します。
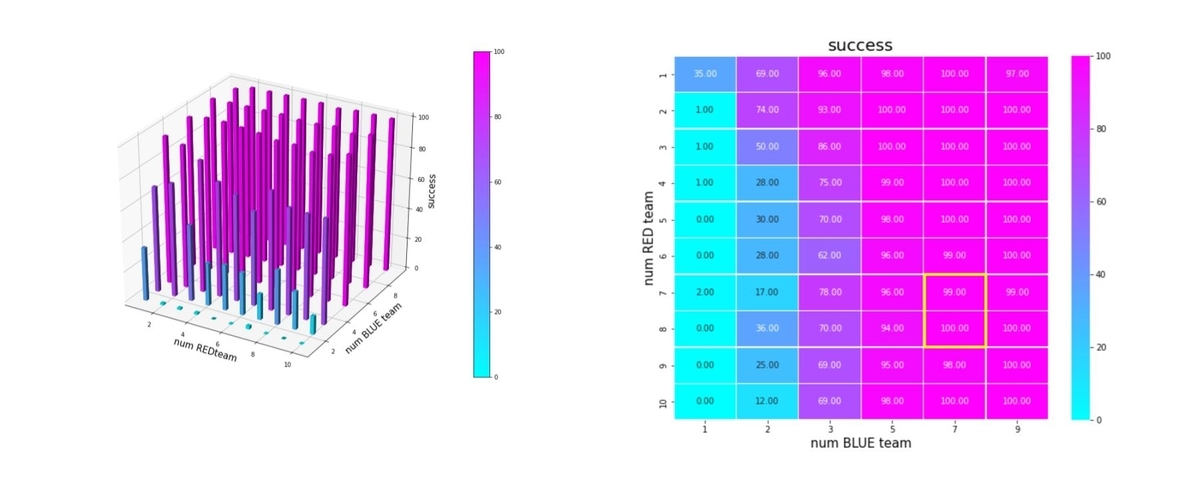
成功率を以下で定義します。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
これをバーグラフと heatmap にしたのが下図です。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するケースほど、成功率が低下しています。
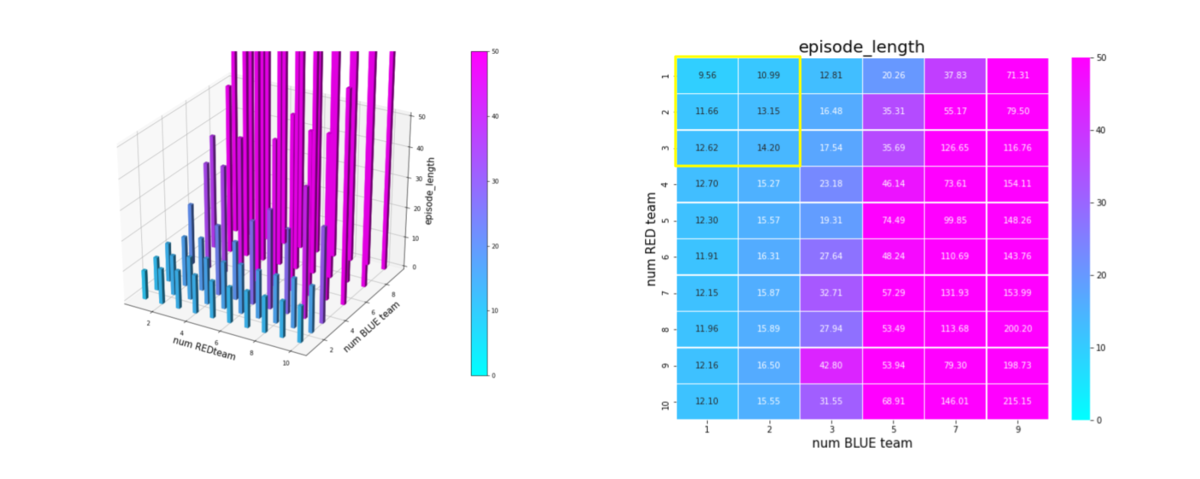
平均エピソード長は下図です。(その3)、(その4)のように少数群で訓練した場合と違って、成功率が低下するようなシナリオでも、エピソード長が極端に長くなっていません。これは、このようなシナリオでは、エージェントが右往左往して成功率が低下するのではなく、生成した戦術が悪くて失敗していることになります。この辺りは、今後の改良ポイントだと思っています。
生成された戦術
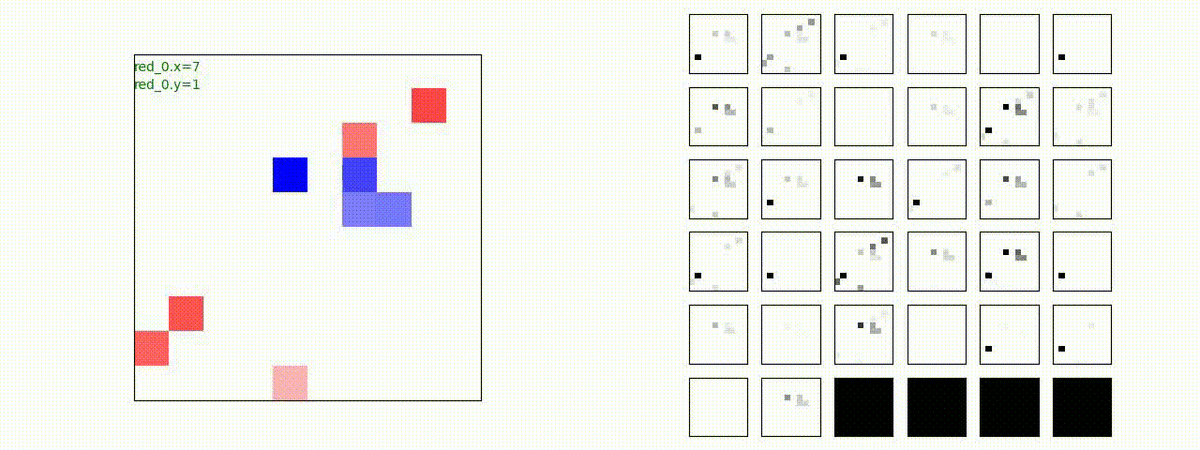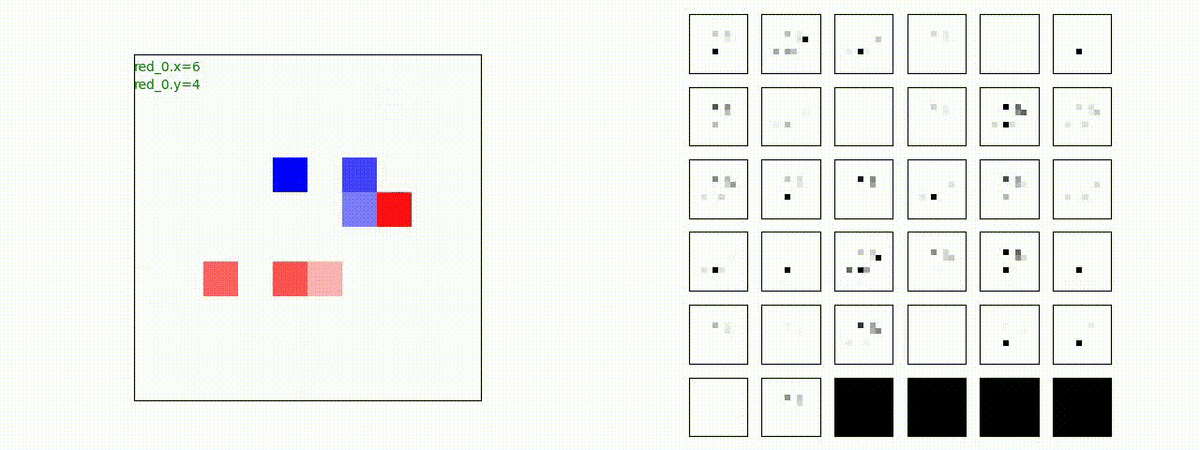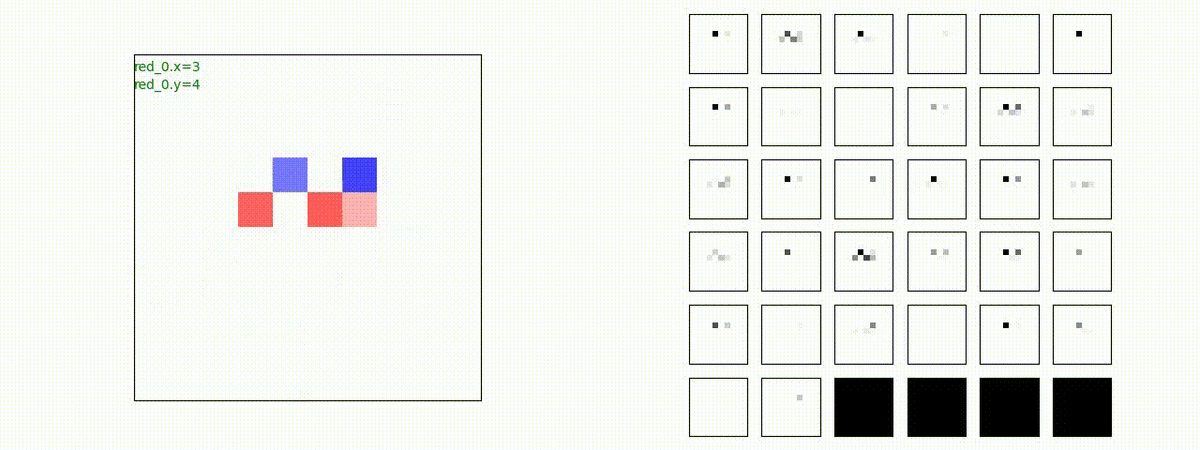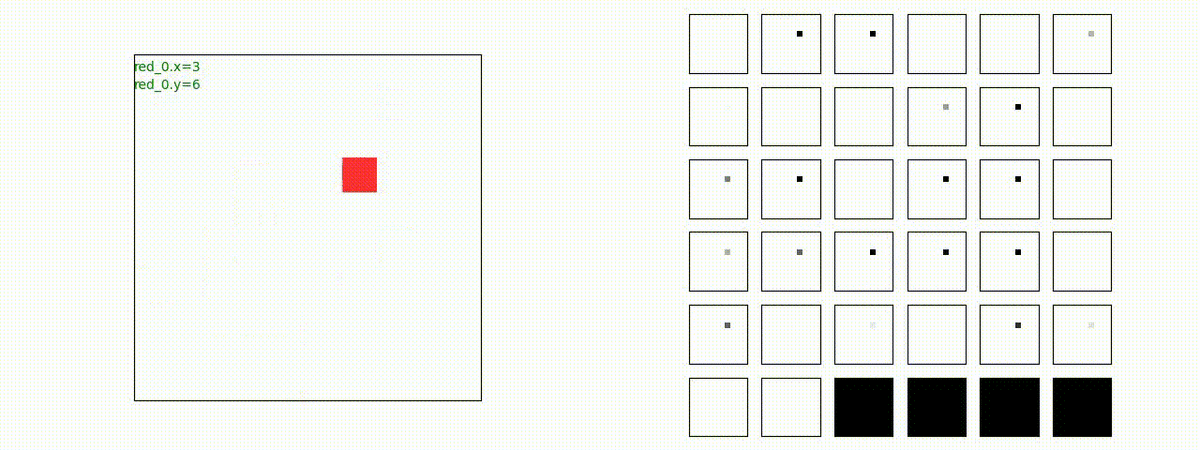
はじめに、学習時に含まれる群数での戦闘で生成された戦術の例を示します。見方はこれまでと同じで、左が交戦状況、右が残存兵力又は 1x1 Conv が入力マップを元に新たに生成し直した32枚のマップです。
Red team = 1 swarm vs Blue team = 1 swarm
最短経路で敵のいるグリッドに到達し、そこにとどまることを学習しています。
1x1 Conv が入力マップを元に新たに生成し直した32枚のマップは以下のようになります。
Red team = 2 swarms vs Blue team = 2 swarms
一つの大きな 'mass' となって、順に敵を撃破していく戦術が生成できています。
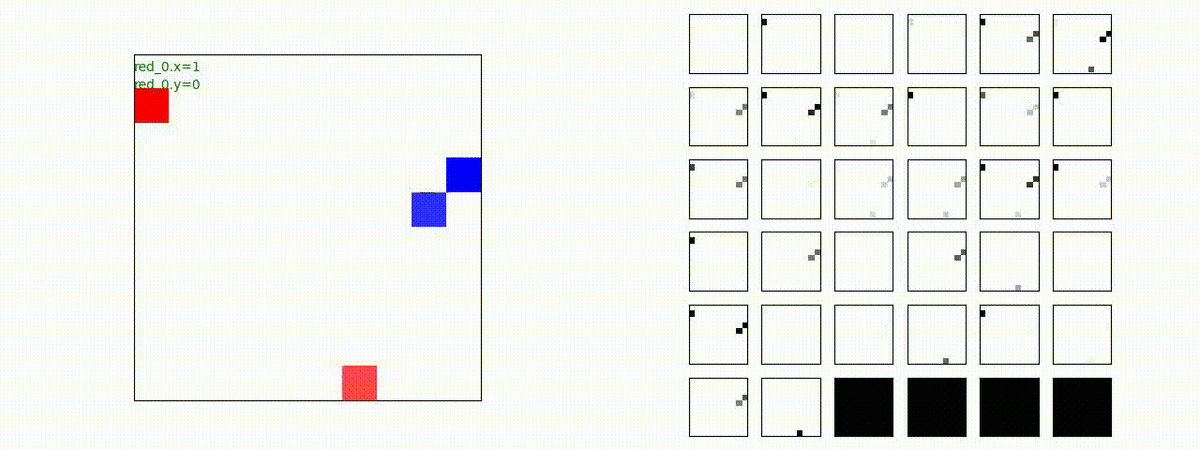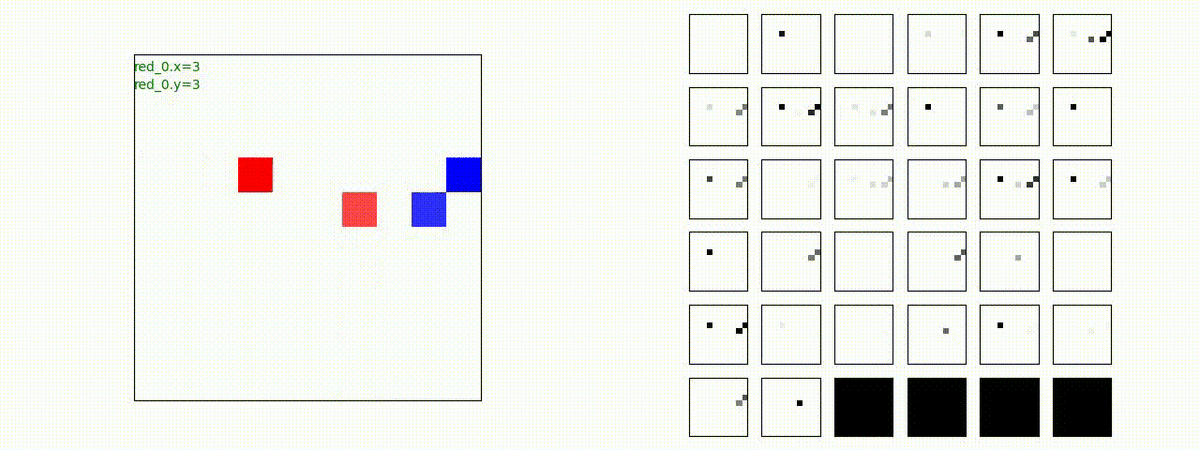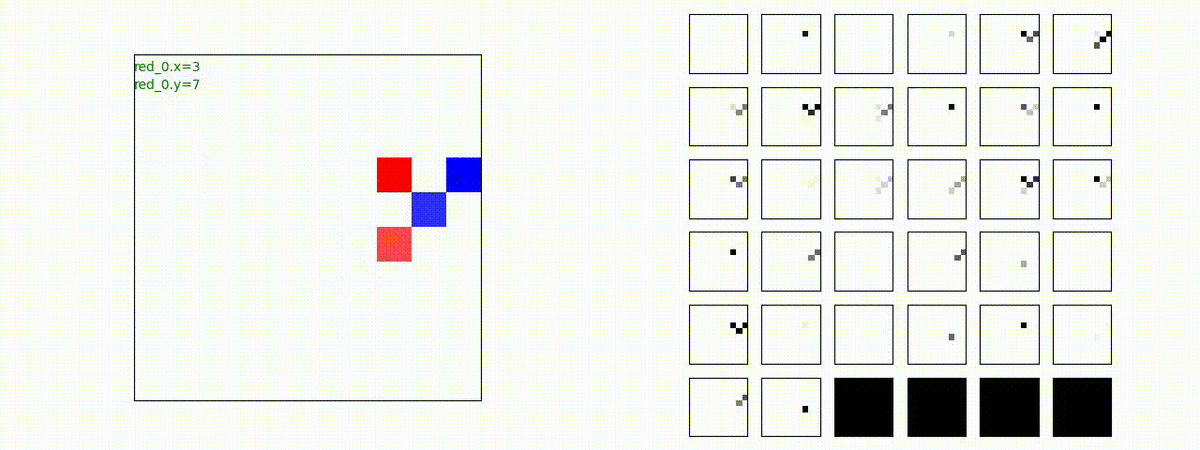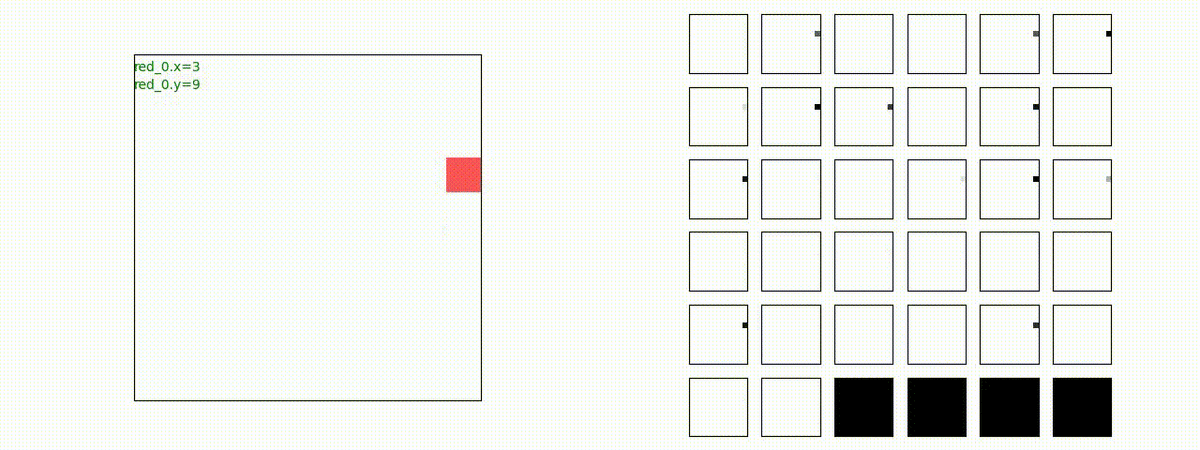
Red team = 3 swarms vs Blue team = 3 swarms
完全に一丸ではありませんが、敵よりも大きな 'mass' を構成して、敵を撃破していく戦術が生成できています。
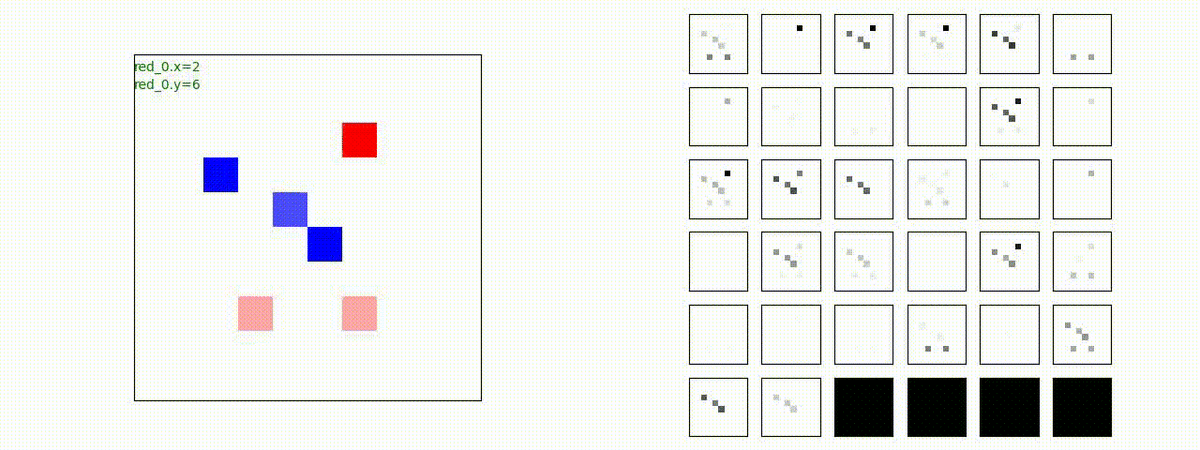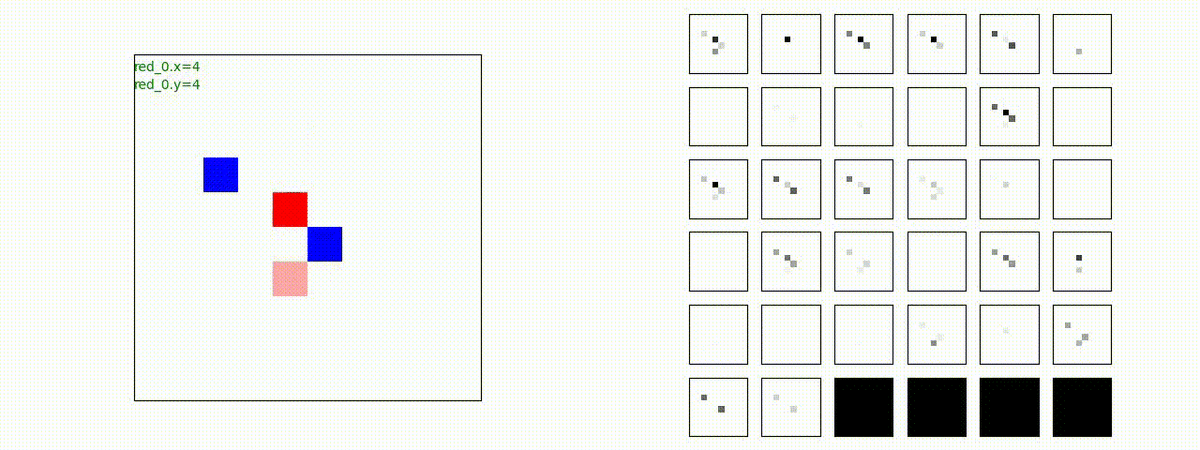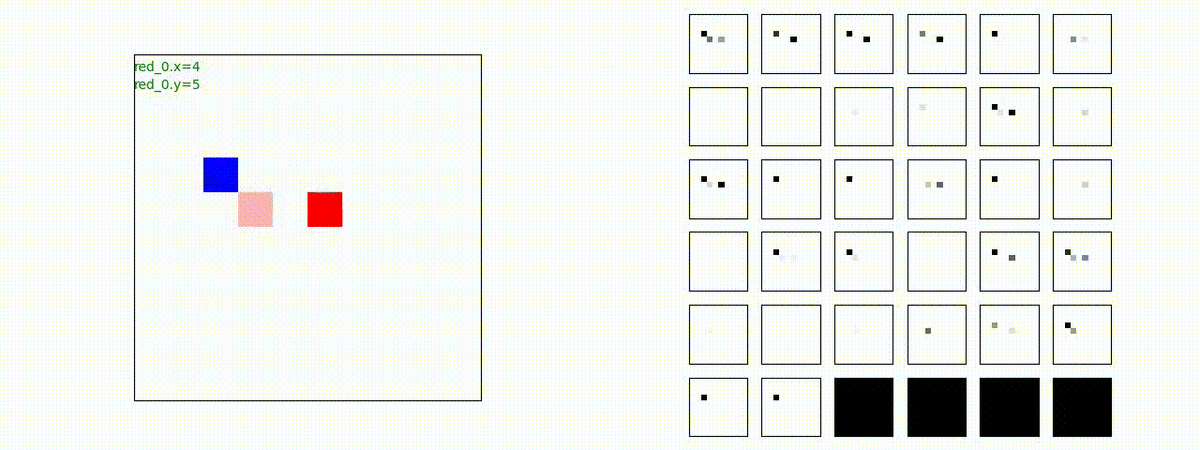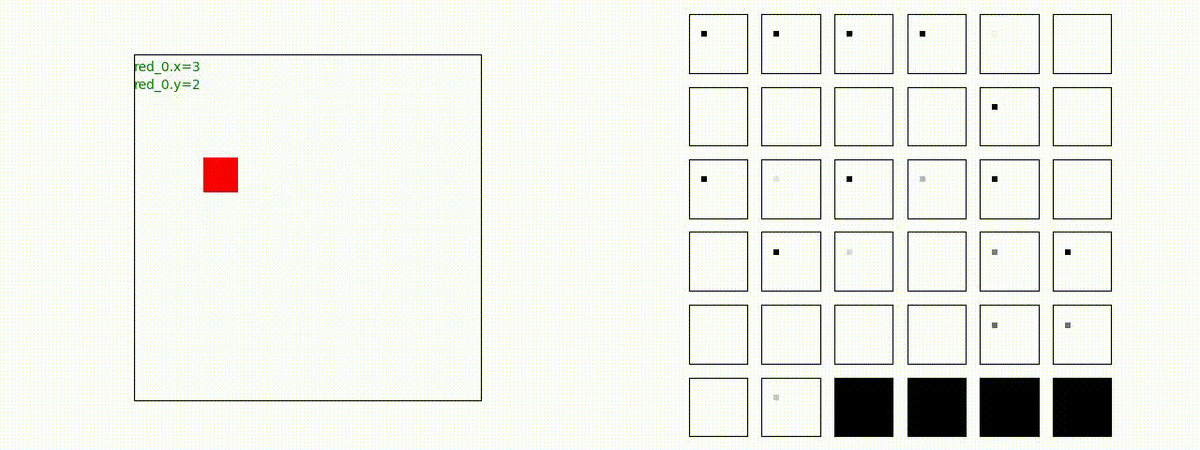
Red team = 5 swarms vs Blue team = 5 swarms
同様に、完全に一丸ではありませんが、敵よりも大きな 'mass' を構成して、敵を撃破していく戦術が生成できています。
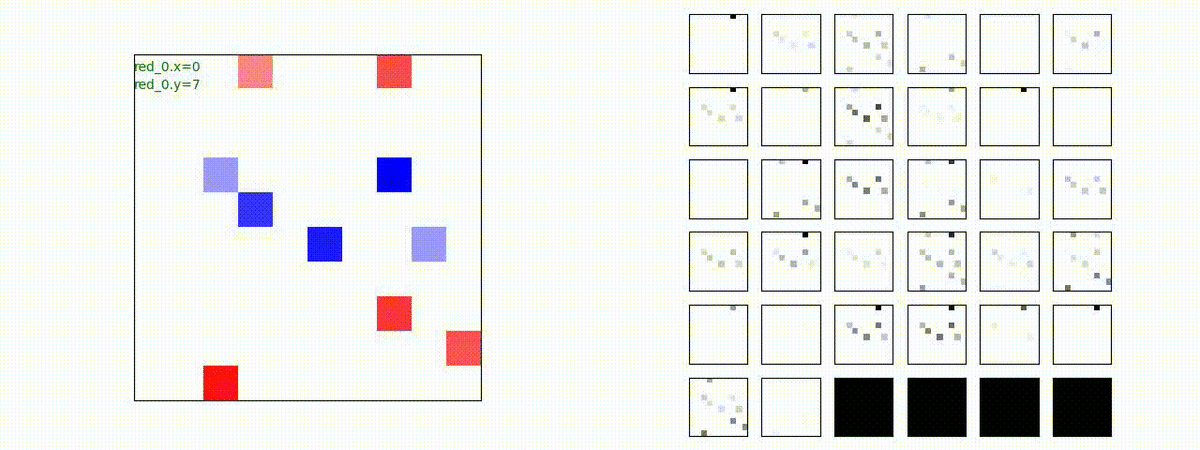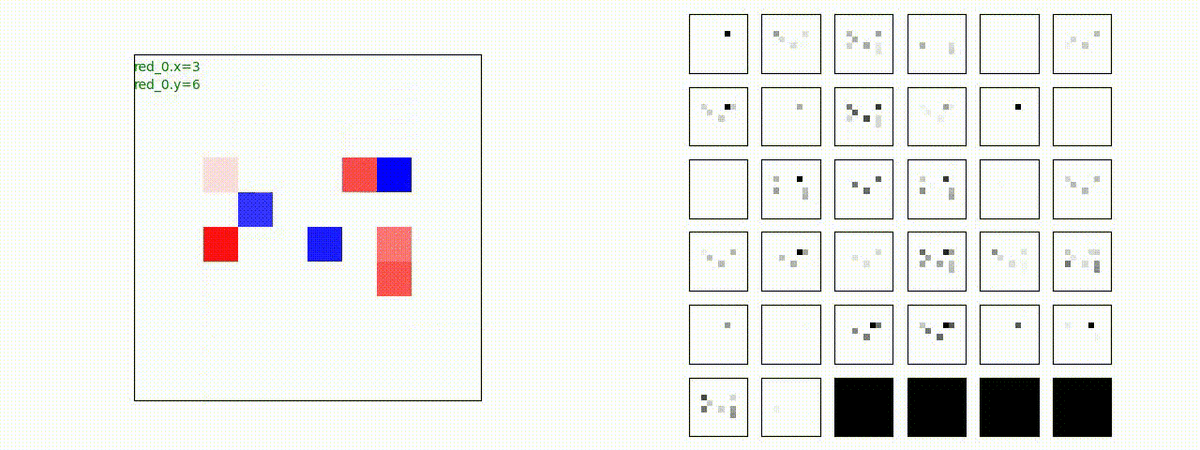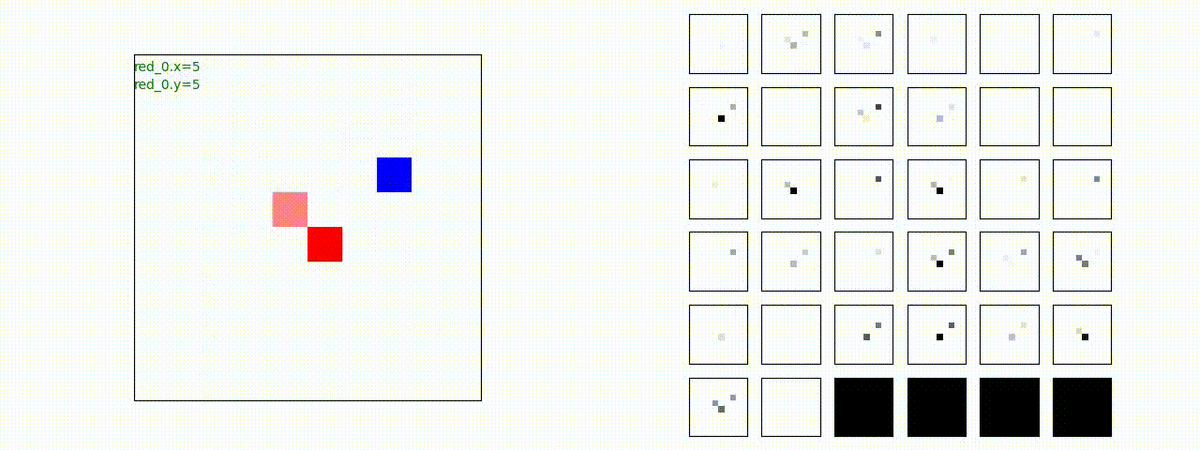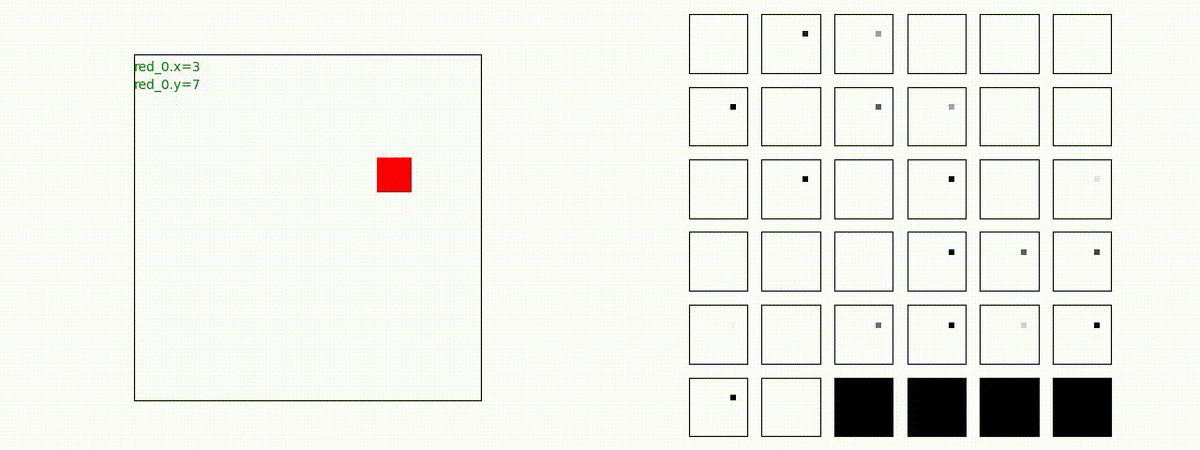
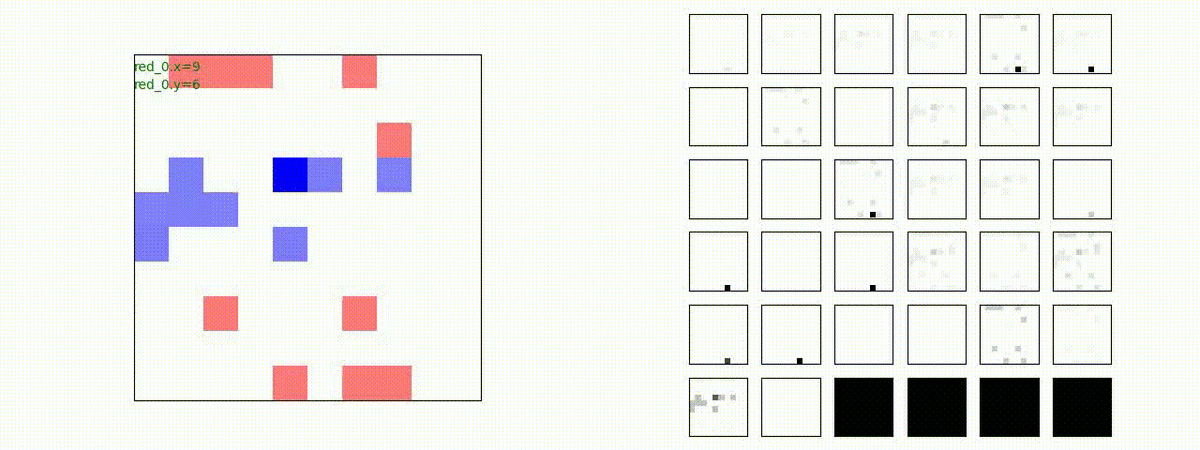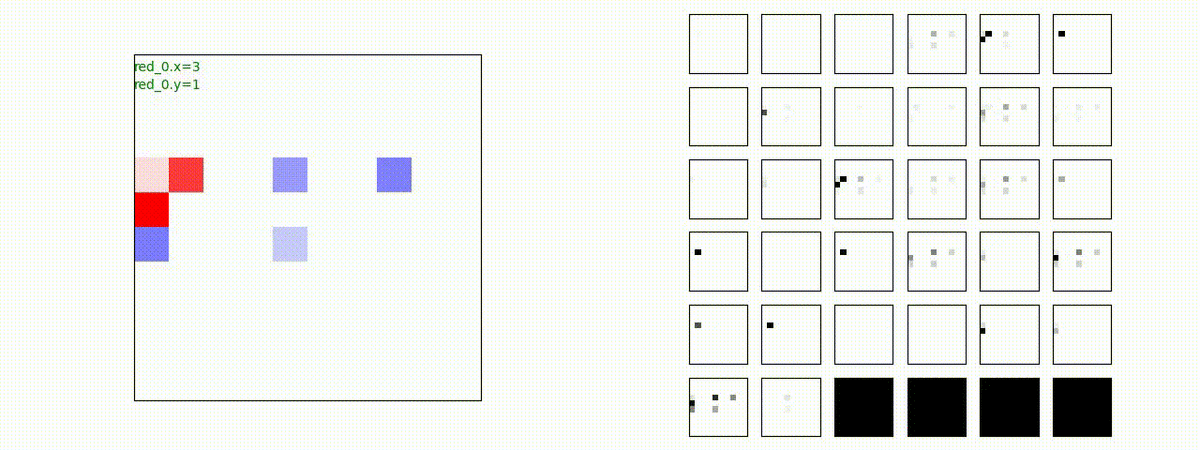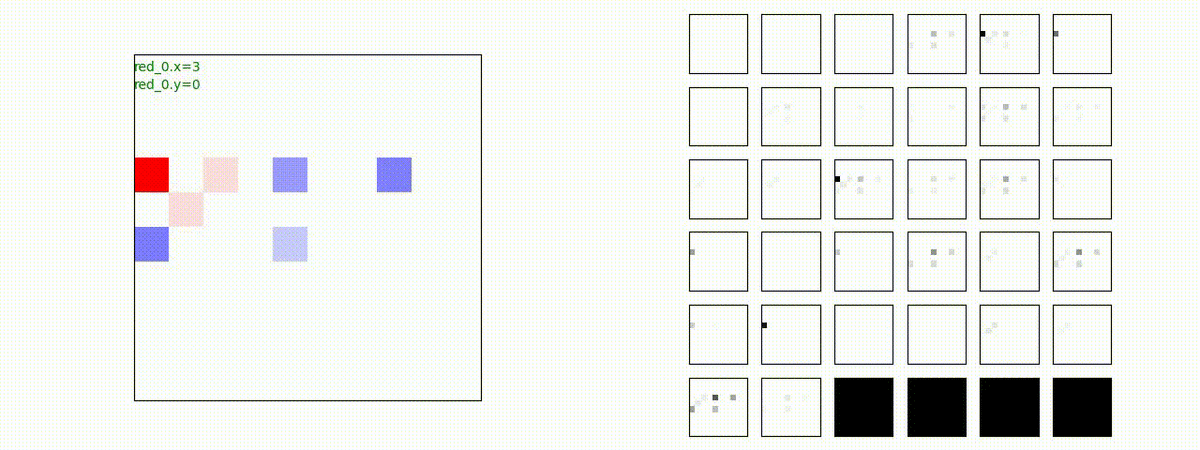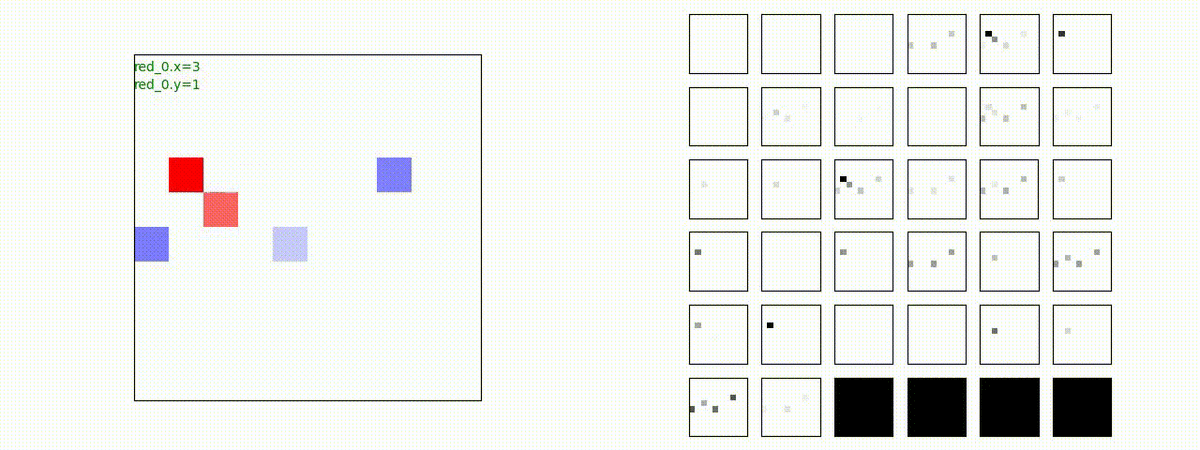
Red team = 8 swarms vs Blue team = 7 swarms
同様です。
汎化時の生成戦術例
トレーニング時よりも多いエージェント数(群数)のシナリオを使って、戦術を生成してみます。
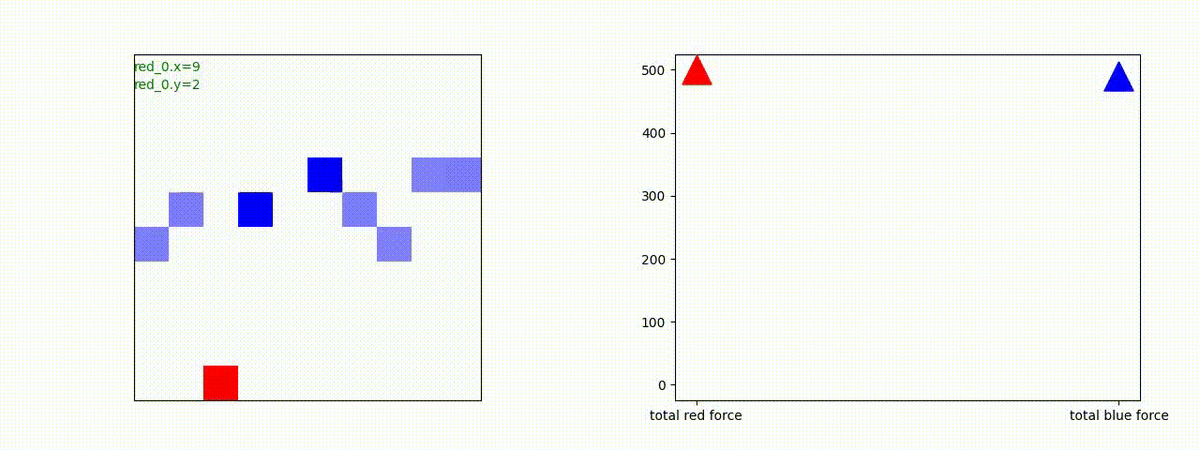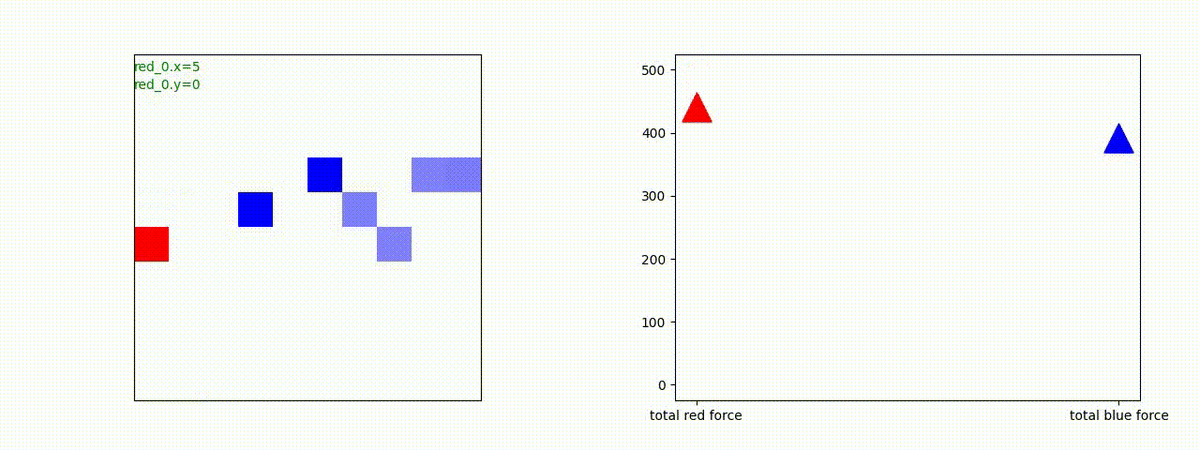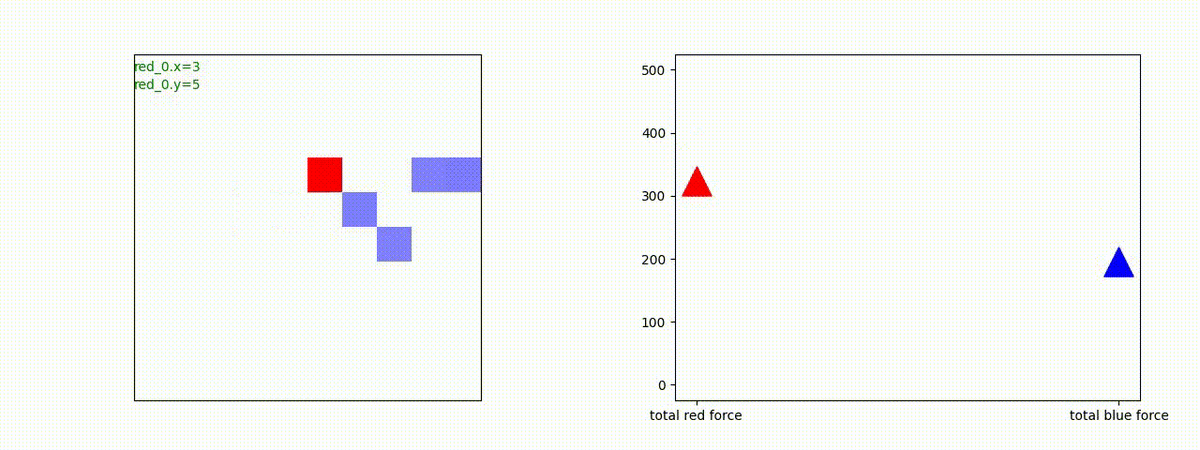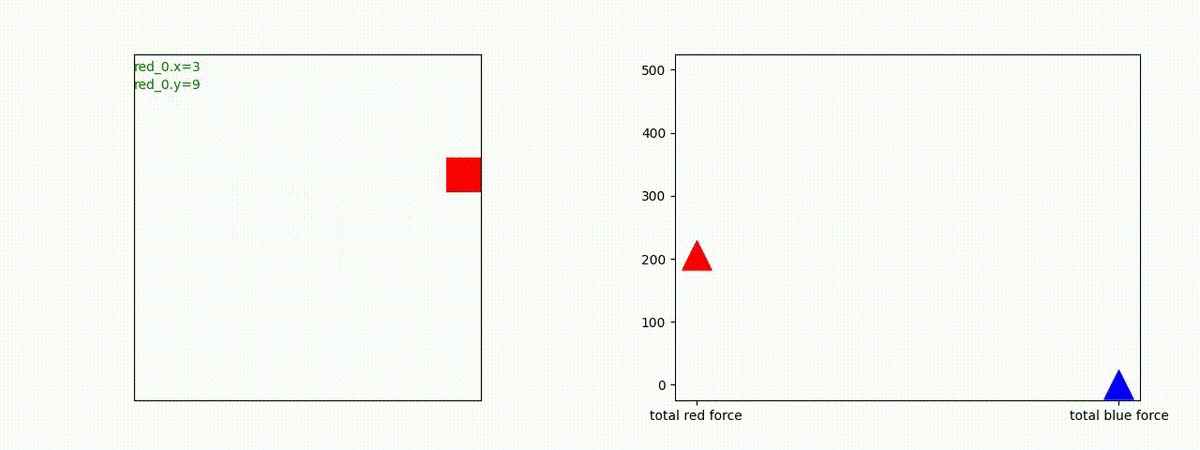
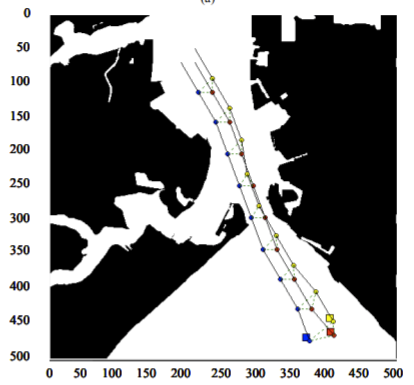
Red team = 10 swarms vs Blue team = 1 swarm
これは学習時よりも多い red team のエージェント数での戦闘シナリオです。群数が外挿方向に増えても、"mass" 重視の戦術が生成出来ています。
特にこのシナリオでは、Blue teamは巨大な兵力を持った1つの群となっていて、これを撃破するための Red team が採り得る唯一の戦術は、Red team のエージェントが1つの塊となってから初めて Blue team のエージェントがいるグリッドに進出することです。この戦術が生成されていることが判ります。
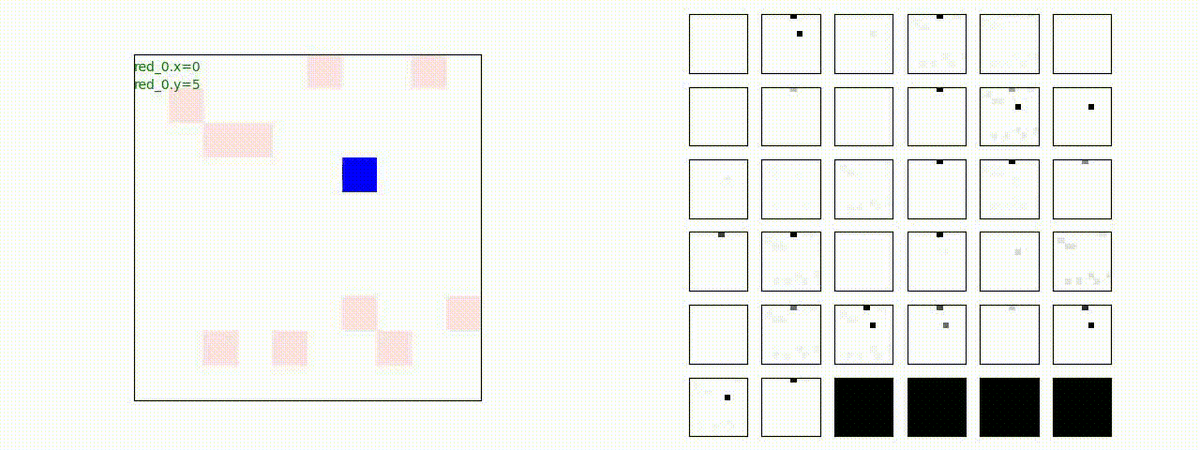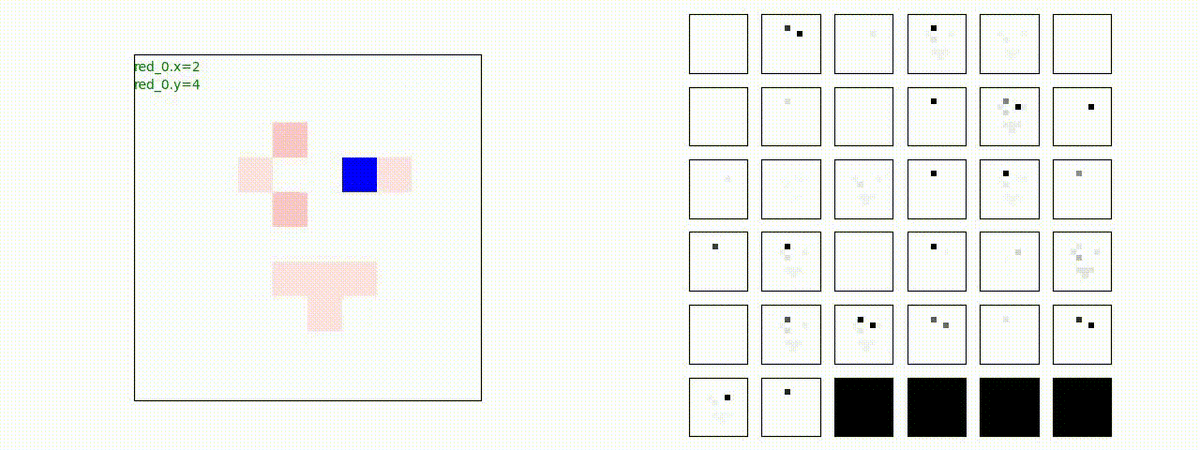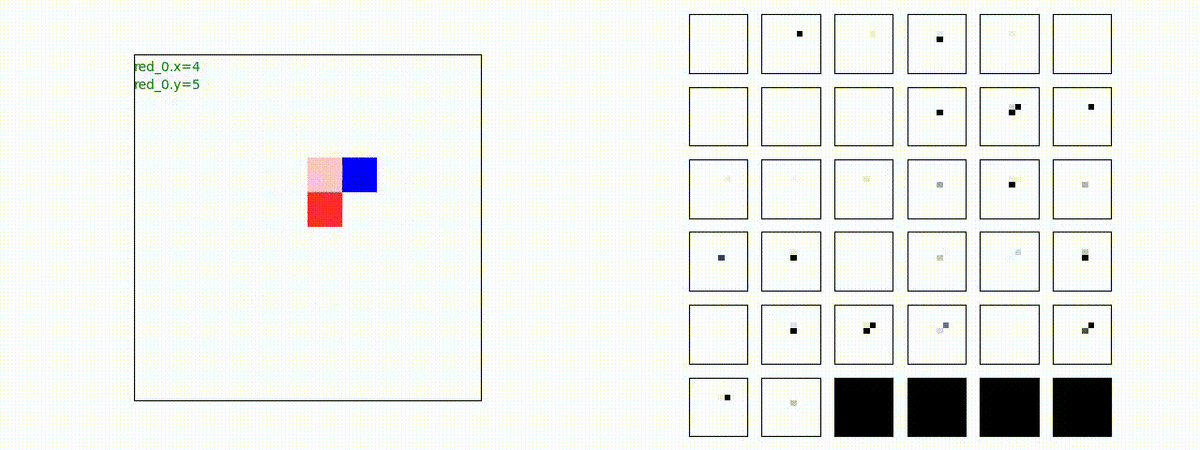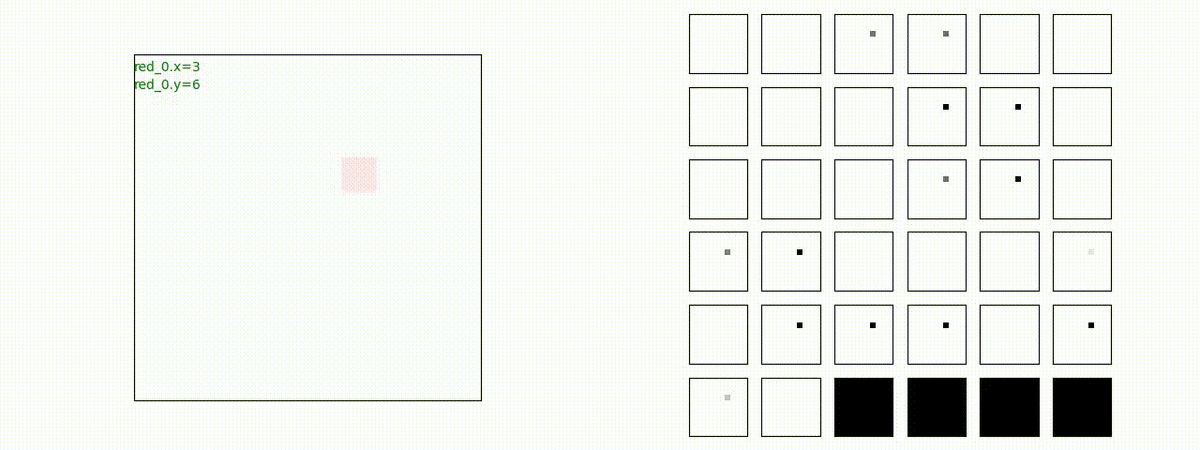
Red team = 1 swarm vs Blue team = 10 swarms
これは学習時よりも多い blue team のエージェント数での戦闘シナリオです。巨大な兵力で、弱小な敵を順に撃破していく必要があります。群数が外挿方向に増えても、敵を順に撃破していく戦術が生成できているのが判ります。
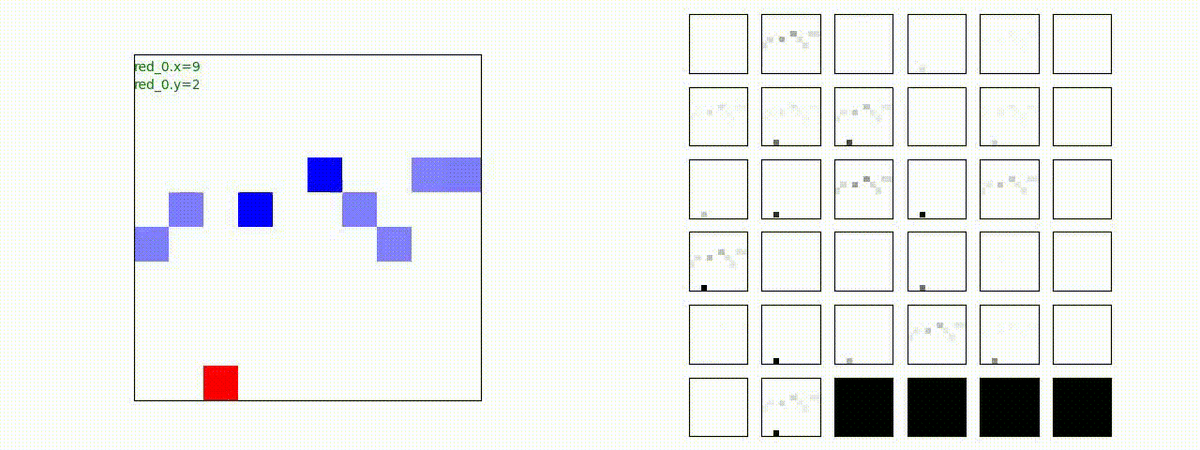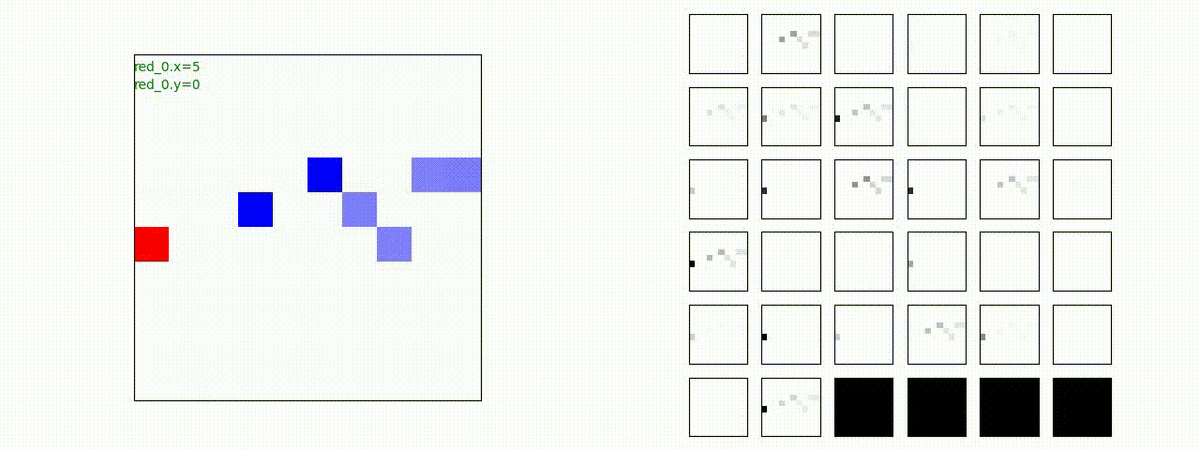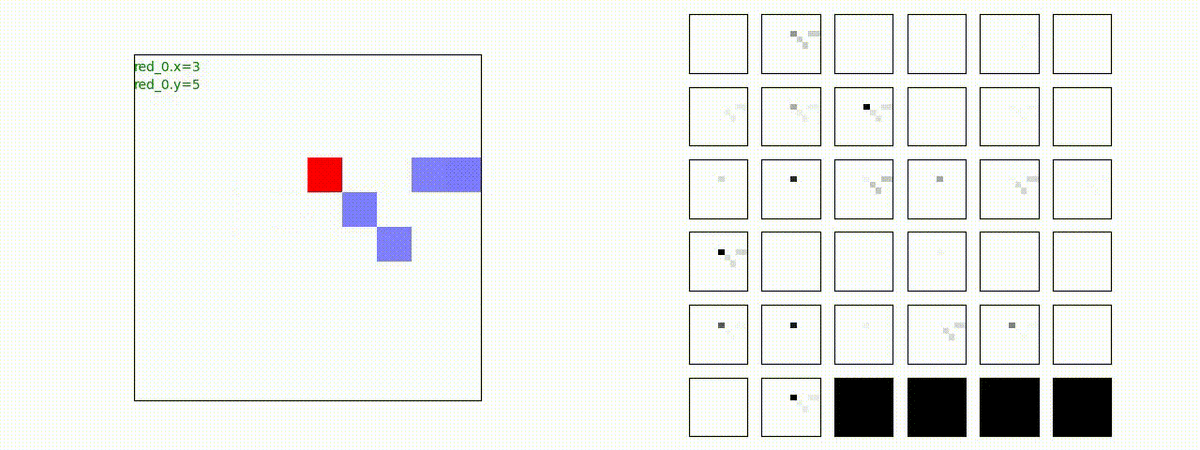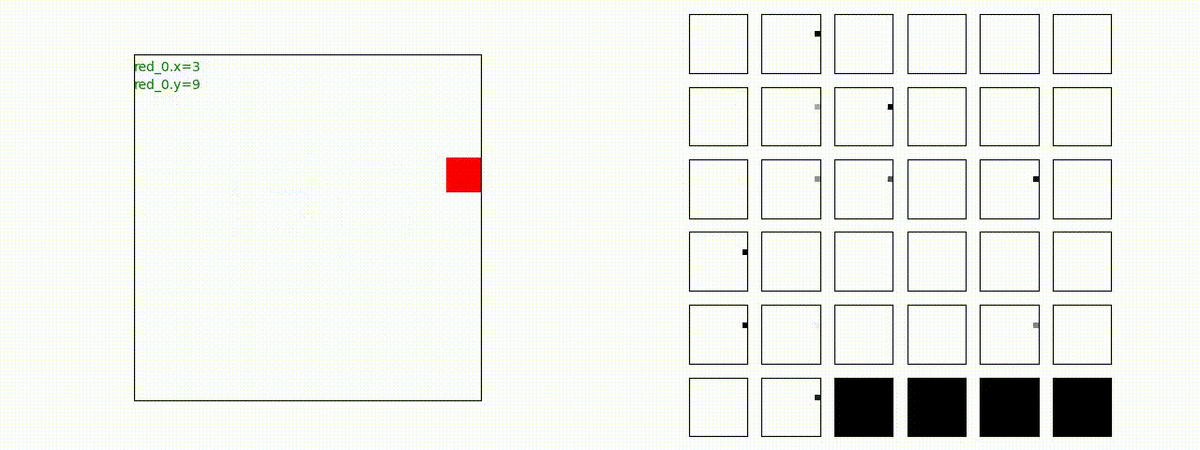
Red team = 10 swarms vs Blue team = 10 swarms
これは、彼我ともに学習時よりも多いエージェント数での戦闘シナリオです。群が完全に一丸となった "mass" 重視の戦術の生成とまでは行っていませんが、敵よりも巨大な 'mass' を構成して、敵を撃破していく戦術が生成できているのが判ります。
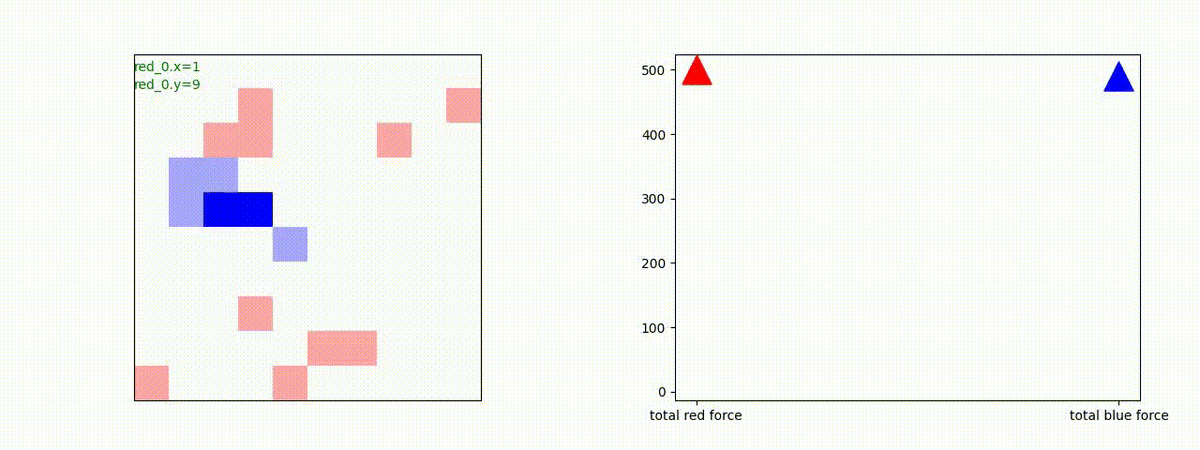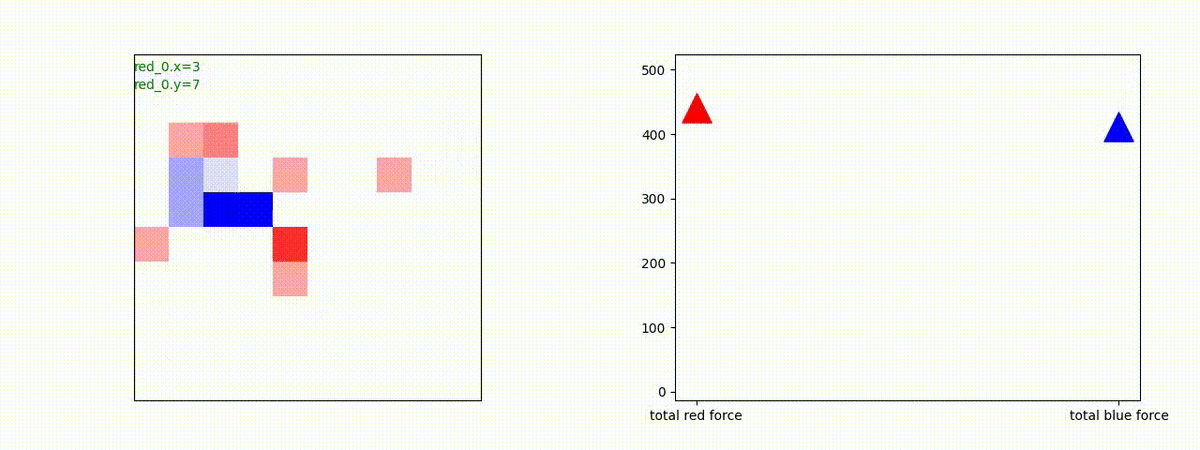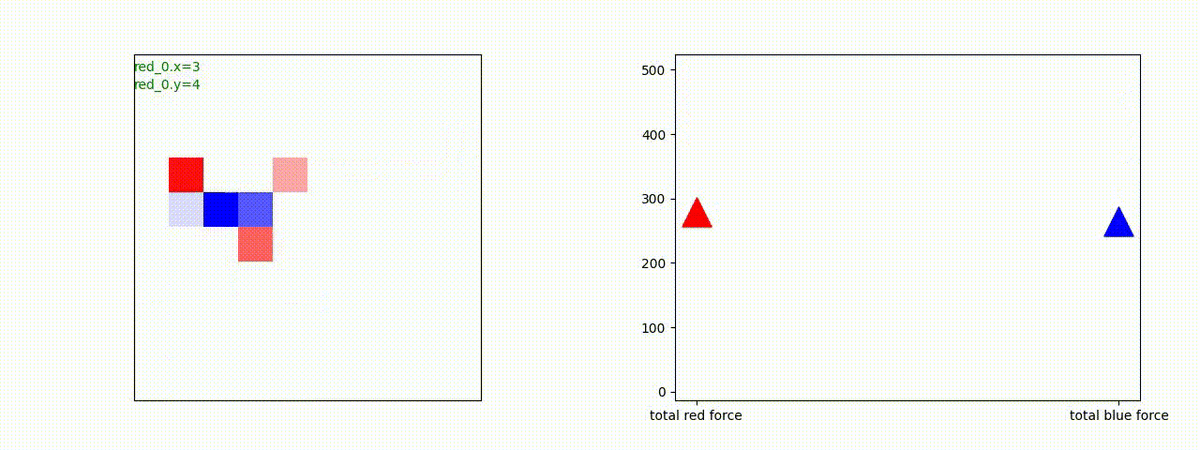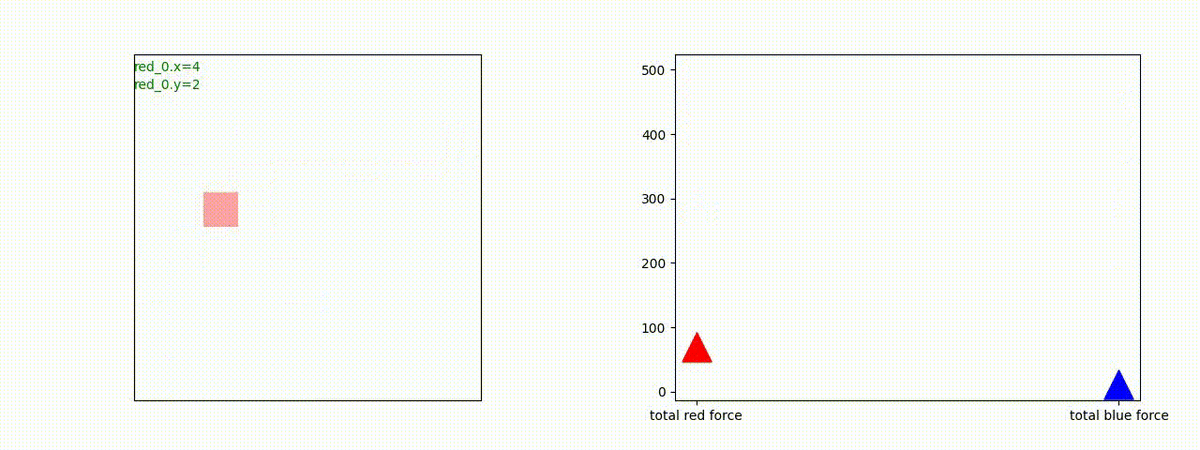
将来研究
今回トレーニングしたエージェントは、全体としての性能バランスは、(その3)でトレーニングした少数群戦闘エキスパートや(その4)でトレーニングした多数群戦闘エキスパートよりも優れています。
しかしながら、特に、少ないエージェント(群)で構成された Blue team に、多数のエージェント(群)で構成された Red team で当たるようなシナリオになるほど、性能が劣化し学習が不十分になっていることが判りました。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘することほど、学習が困難なようです。ここは、少ないエージェント(群)で構成された Blue team に対する戦闘は(その3)でトレーニングした少数群戦闘エキスパートに任せた方がよさそうです。
そこで、今回学習したエージェントを使って、転移学習により少数群戦闘エキスパート(Expert 1)と多数群戦闘エキスパート(Expert 2)をトレーニングすることが考えられます。
全体アーキテクチャは、下図を考えました。ここで、Expert 1 と Expert 2 の重みの初期値を今回トレーニングしたエージェントの重みとします。また、selector net 1 は適当なアーキテクチャを持ったニューラルネットで、重みはランダムに初期化します。
※ 将来研究として、(その4)では先にエキスパートを個別にトレーニングし、それらをフリーズさせて、後からセレクタをトレーニングする方法を考えてみましたが、今回のはその逆です。工業製品的には(その4)のやり方が良いと思います。今回の案は純粋に私の好奇心です。このセットアップで、自動で、少数群戦闘エキスパートと多数群戦闘エキスパートとに「分化」してくれるのか興味があります。たぶん、何らかの工夫が必要です。これは、ひと段落したらやってみたいと思います。
まとめ
- Red team の初期エージェント数(群数)を [1, 8]、Blue team の初期エージェント数(群数)を [1, 7] として、ネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、完璧ではありませんが、"mass" を構成して戦う戦術を学習でき、上手く戦況をハンドリングできている(ほとんどいつも Blue team を殲滅できる)ことが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を外挿方向に増やしても(つまり、戦力の小さな多数群にしても)、戦闘性能は劣化しませんでした。
実際の戦闘では、シナリオによって、"mass" と ”Economy of Force” のバランスを変えた戦術が欲しいことがあります。このため、次回記事では、本手法で "mass" と ”Economy of Force” のバランスを変えた戦術を生成できるのか試してみます。
マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その4):多数群 vs 多数群で訓練する
- GitHub Code
- 実施内容
- 実行環境
- シミュレーション条件
- トレーニング履歴
- 性能評価
- 生成された戦術
- ロバスト性(汎化能力)
- 生成された戦術例
- 少数群vs少数群で訓練した結果との比較、及び将来の発展性
- まとめ
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
(その3)とは逆方向に検討を行います。すなわち、
- はじめに、Red teamの初期エージェント数(群数)を [7, 8]、Blue teamの初期エージェント数(群数)を [6 ,7] として、多数群 vs 多数群の設定で共有ネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、各チームのエージェント数(群数)を増減して戦闘性能がどう変化するのか評価します。
- (その3)の「少数群 vs 少数群」で訓練した結果と比較し、夫々のトレーニング形態の特徴を分析します。併せて、これらを元に、将来の発展性について考えます。
実行環境
- (その3)と同じ
PPOハイパーパラメータ
- (その3)と同じ
シミュレーション条件
- (その3)と同じ
トレーニング履歴
縦軸は平均エピソード報酬、横軸が更新ステップです。
グラフの途中で色が変わり、一部グラフが重なっているのは、前実験と同じく GCP のPreemptive vm が最大24時間で強制シャットダウンされるため、シャットダウン後、保存したチェックポイントから継続学習を行っているためです。
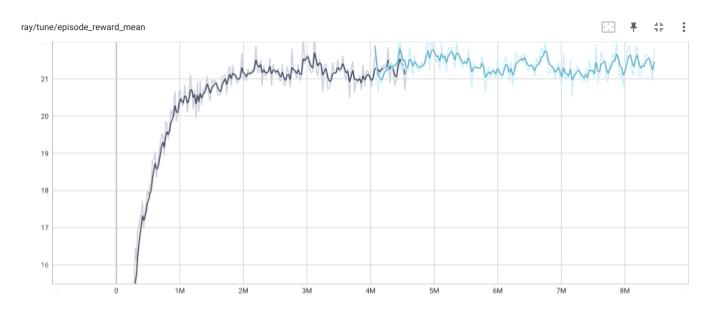
以下のトレーニング中の平均エピソード長の遷移を見ると、未だ収束していない感じがするので、もう少しトレーニングを継続したほうが良いと思われます。(趣味の範囲でやっているので、お金と時間をかけないように48時間で打ち切りました)。
トレーニング後半のエピソード長分布の履歴です。
チーム報酬も分布は「少数群 vs 少数群」の時とは異なり、単峰性になりました。
トレーニング時の評価結果
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。途中の段差は、GCPのpreemptiveの継続に依るものですので、無視してください。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [7, 8] で乱択しているので、学習が進んだ時の平均残存数=5 ~ 6 は、1~ 2 個のエージェントが戦闘で消耗することを意味します。
残存兵力(Force)の評価履歴は下記となりました。Blue team の残存兵力は0に近くなっていて、Red team の各エージェントは、上手く戦える戦術を生成し実行していることが分かります。ただ、「少数群 vs 少数群」でトレーニングした時の様に、Blue team の残存兵力を完全に0にはできていないので、もう少しトレーニングを続けた方がよさそうです。
Blue team の残存兵力を0にできたエピソードを success、逆に Red team の残存兵力が0になってしまったエピソードを fail、どちらの兵力も0とはならなかったエピソードを draw と定義して、これらを100回のエピソードから算出したのが下図です。学習が進むと、success=100%、つまり、Blue team の残存兵力を0に近づけられることが判ります。
下図は、エピソードの長さから学習の進捗状況を見たものです。(その3)の検討よりも、エージェント数が多くなったので、学習が進展した後の平均エピソード長は少し長くなっています。
性能評価
下表は、学習後に、チームの性能を100回のシミュレーションを行って、定量的に確認したものです。ここで、
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
です。red team の残存エージェント数は74~80%と割と多いのですが、残存兵力は25%程度になっています。もし、red team の各エージェントが、完全に一丸となって戦うことを学んでいれば、少なくとも「少数群 vs 少数群」の時と同程度の30%以上のred team残存兵力になるはずですので、完全に一丸となって戦っているとまでは言えないようです。(時間の都合で、Blue agent 数=7の場合だけを計算しています)。
この点に注意しながら、生成された戦術を見てみます。動画の見方は、(その3)と同様です。
生成された戦術
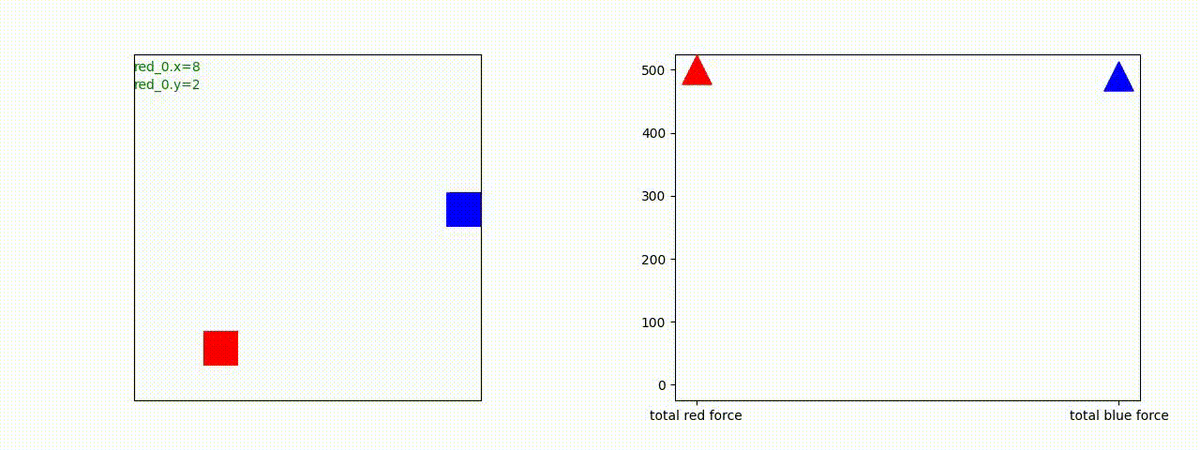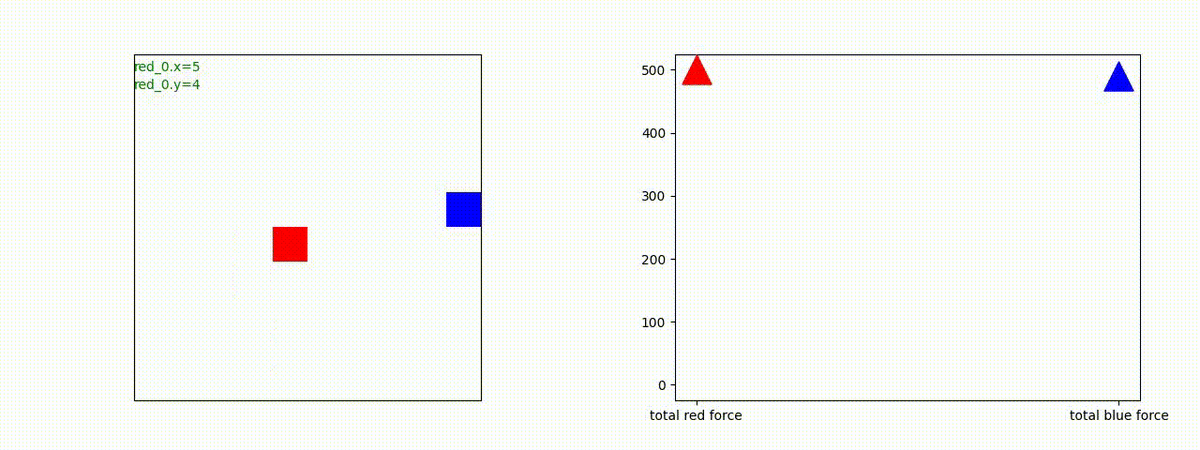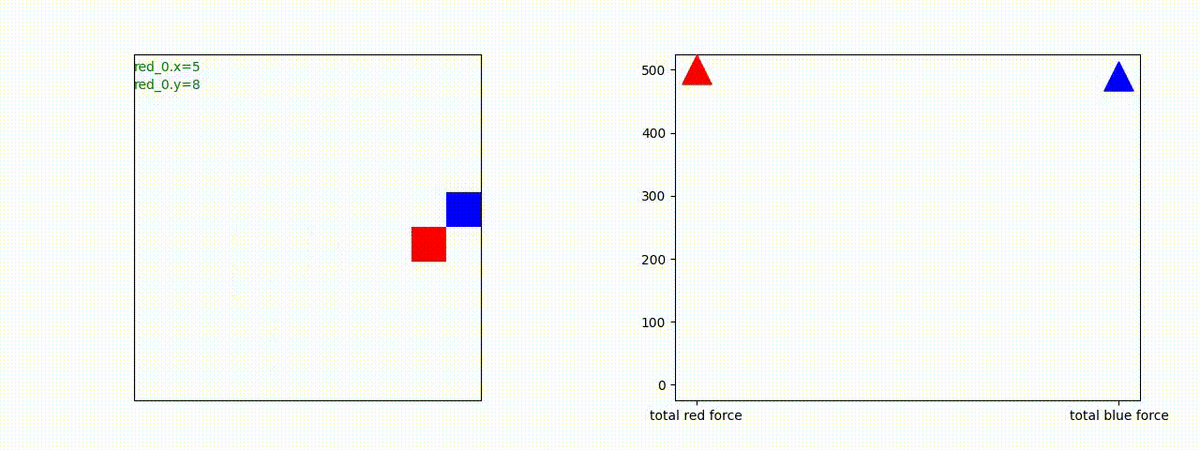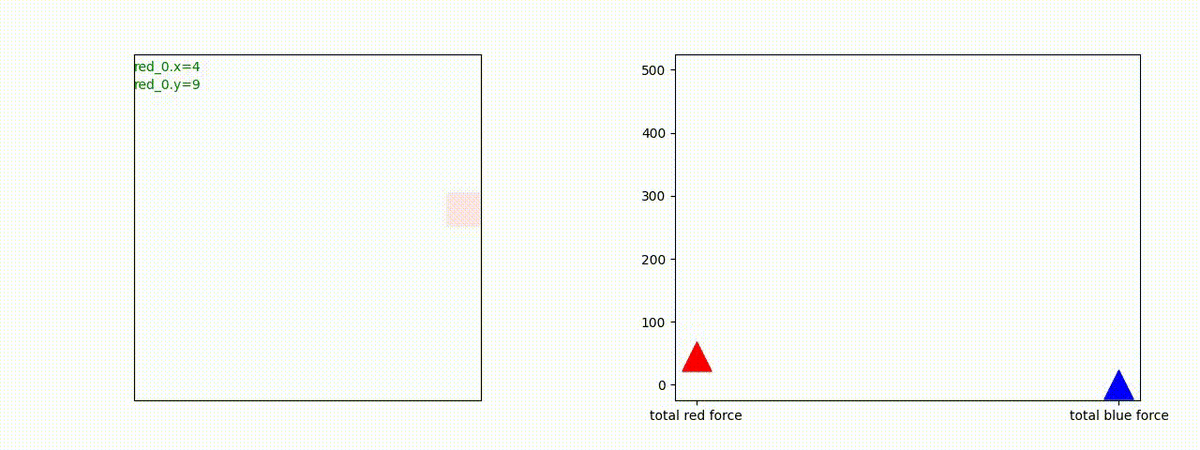
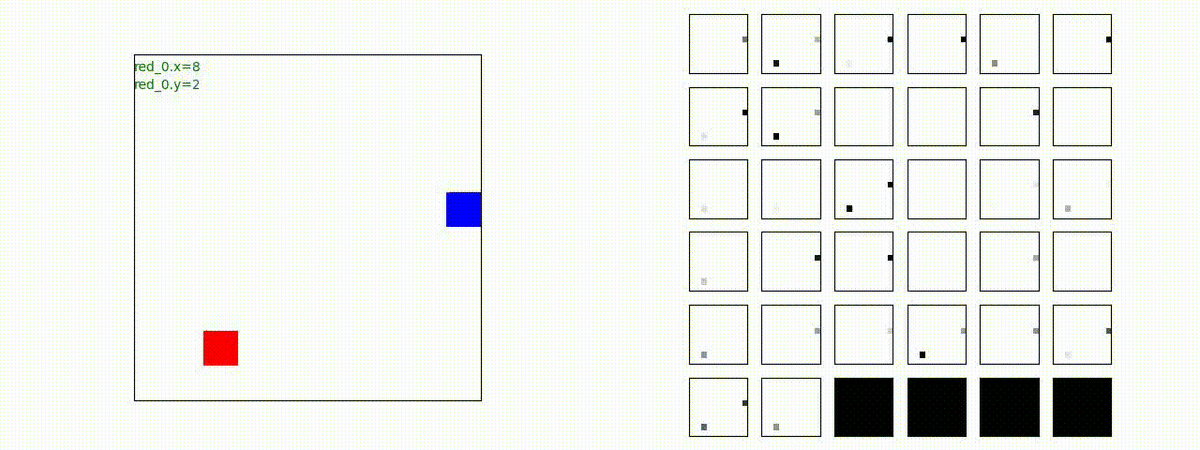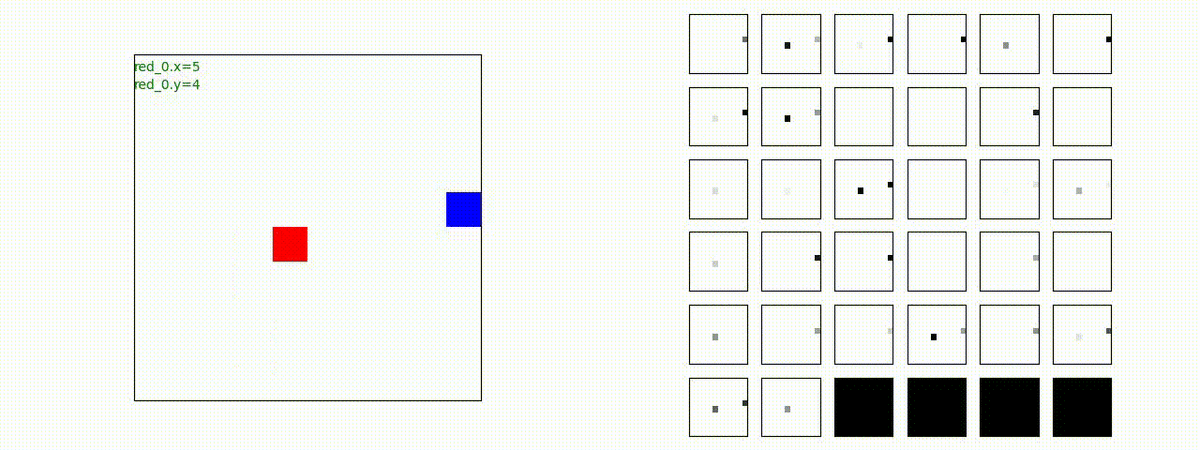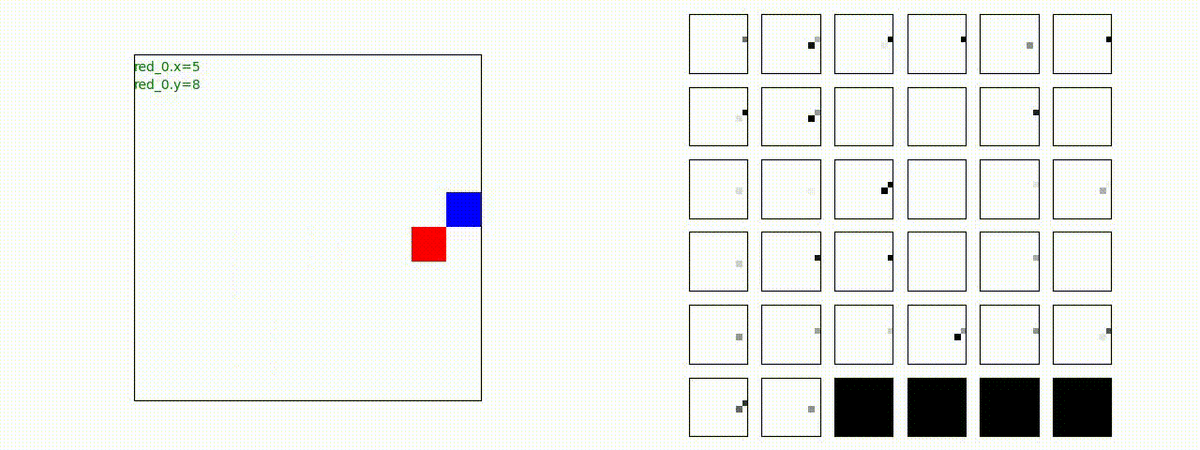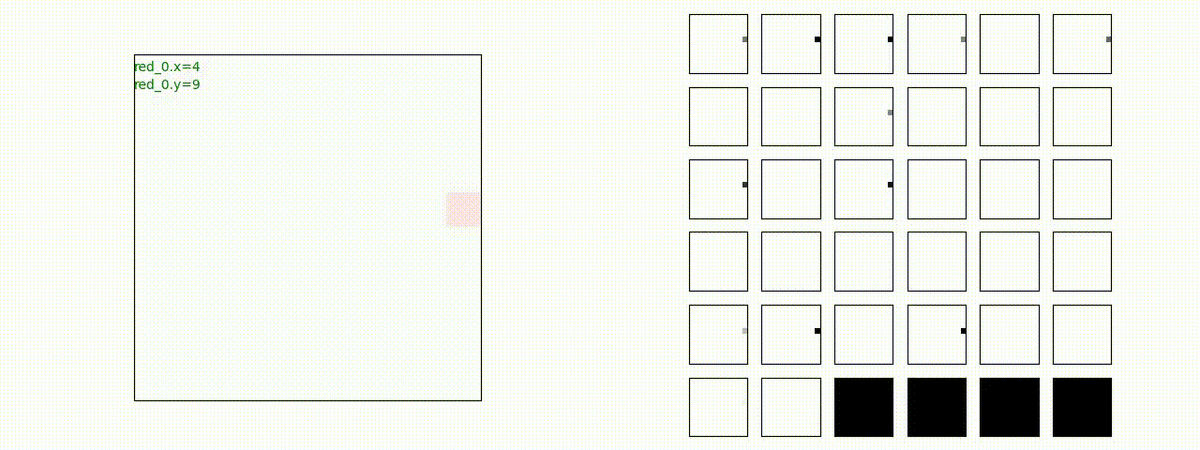
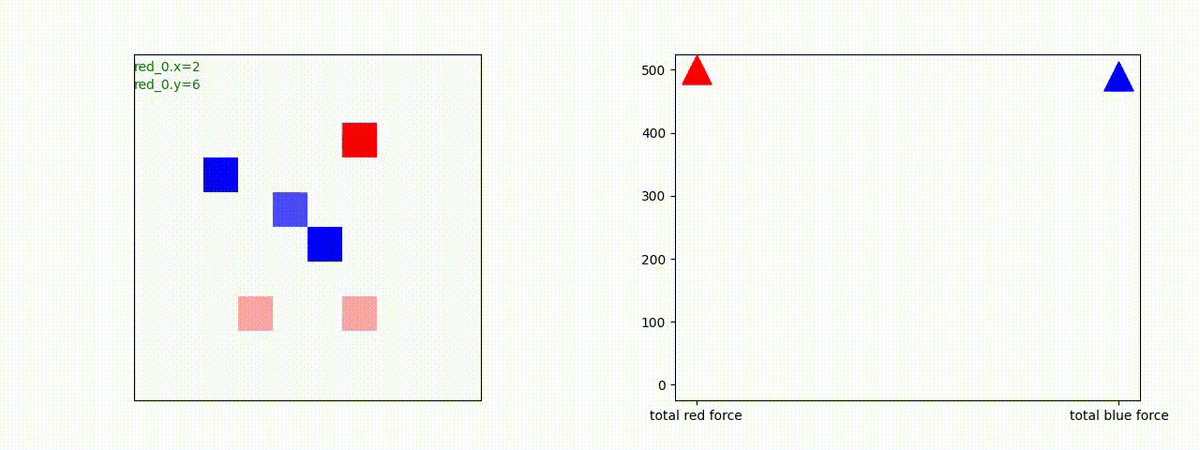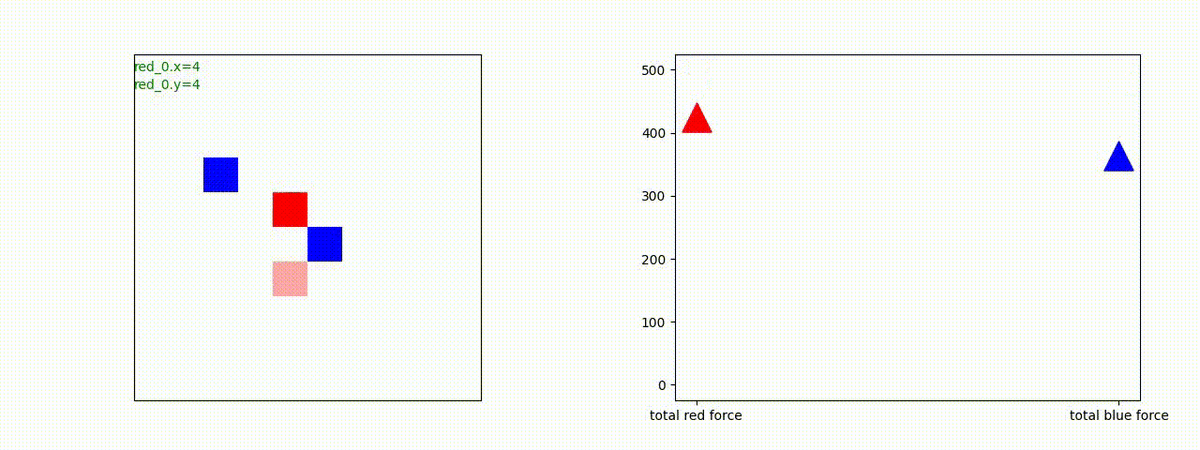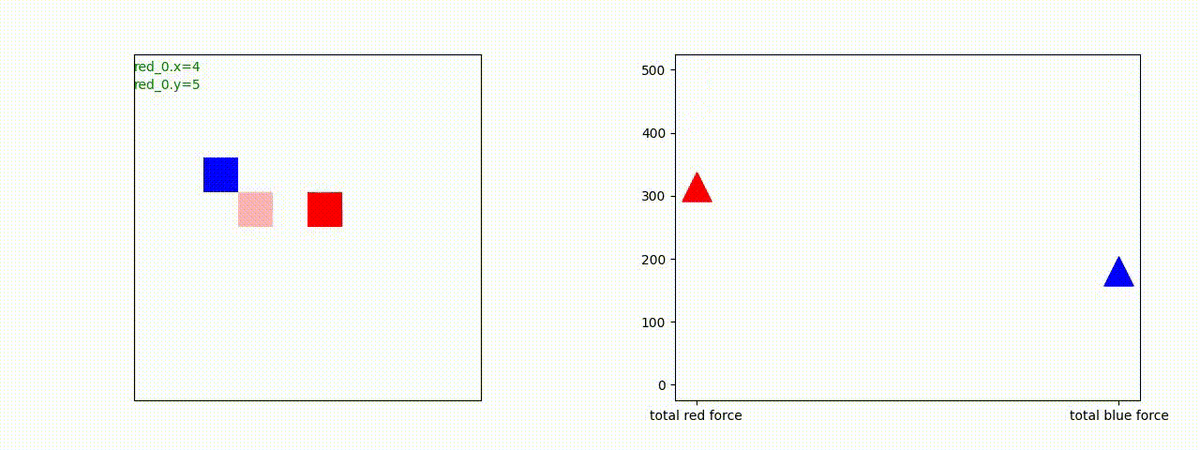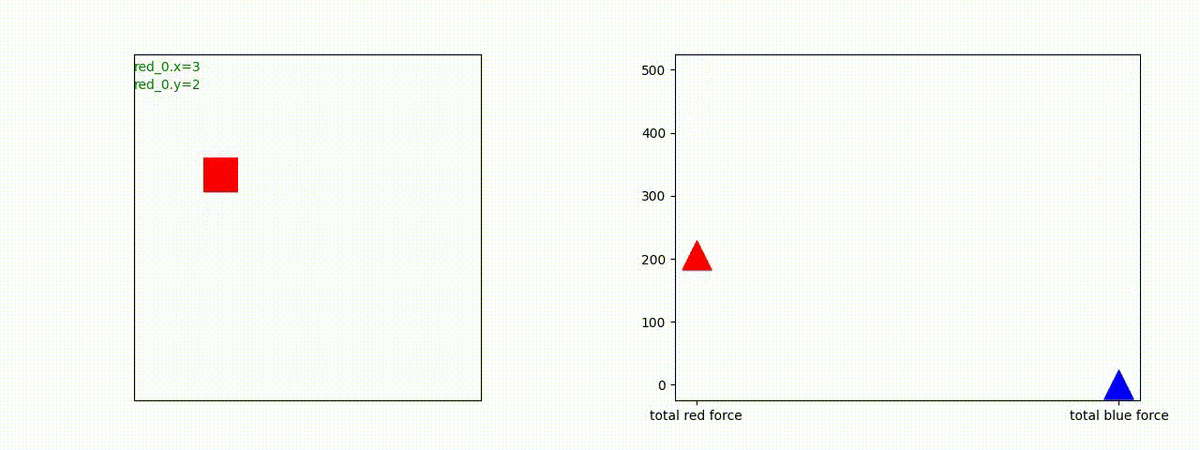
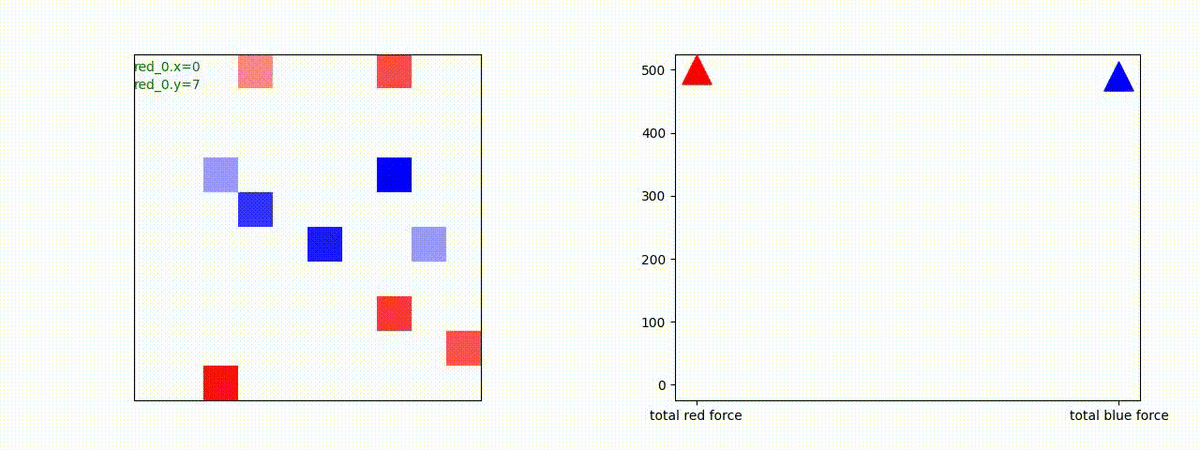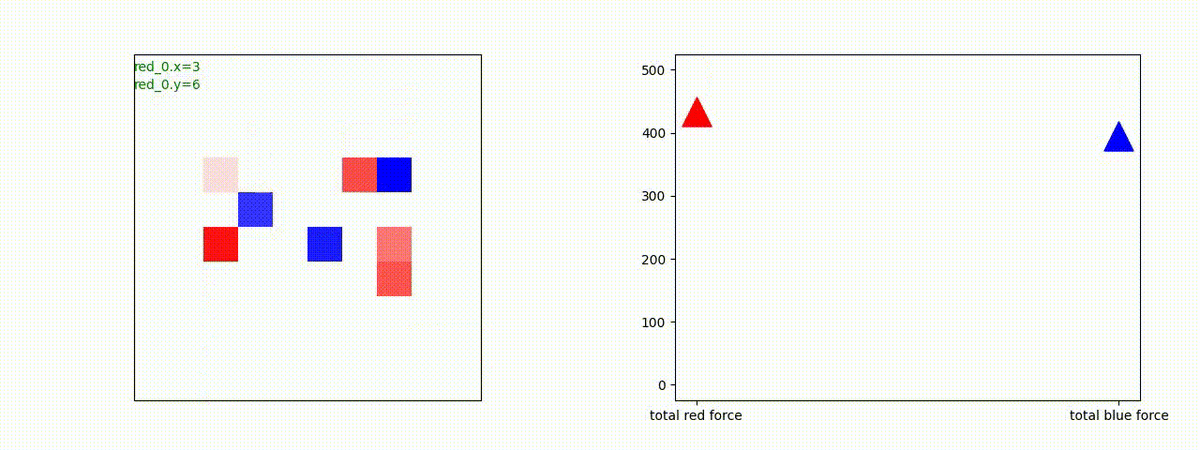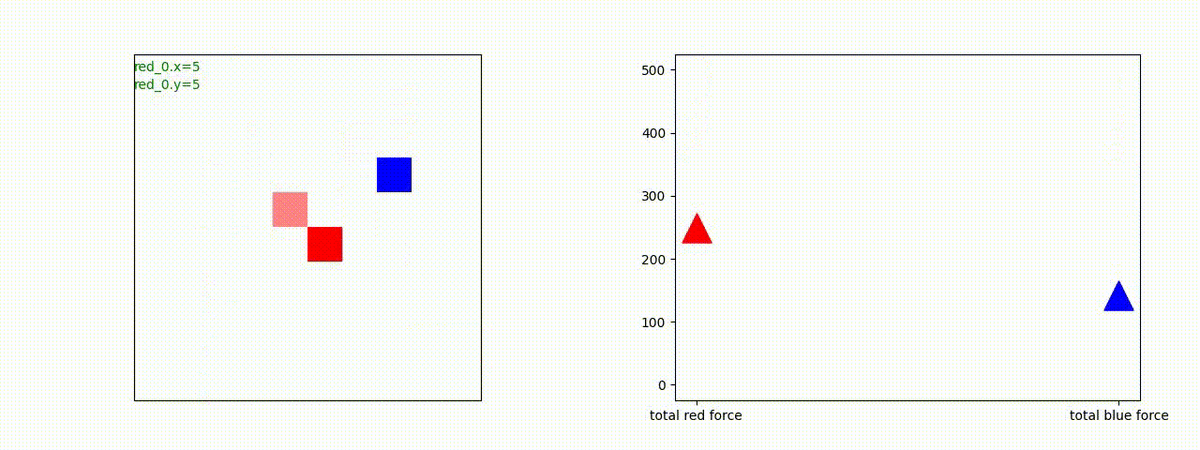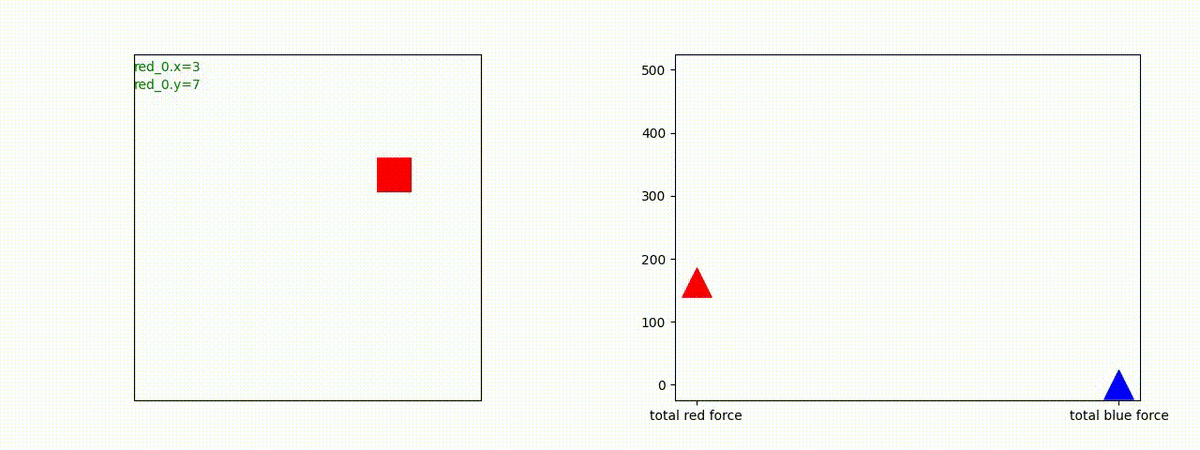
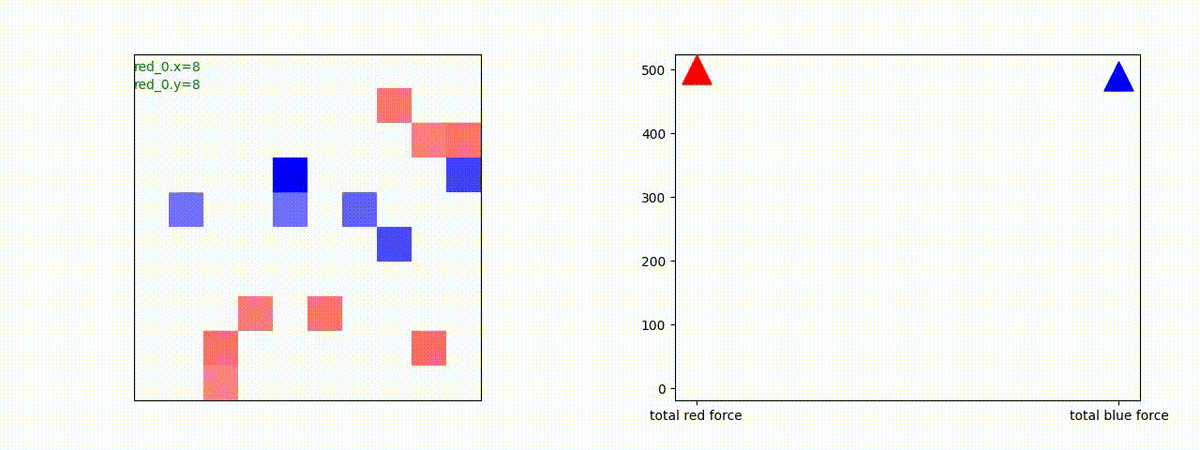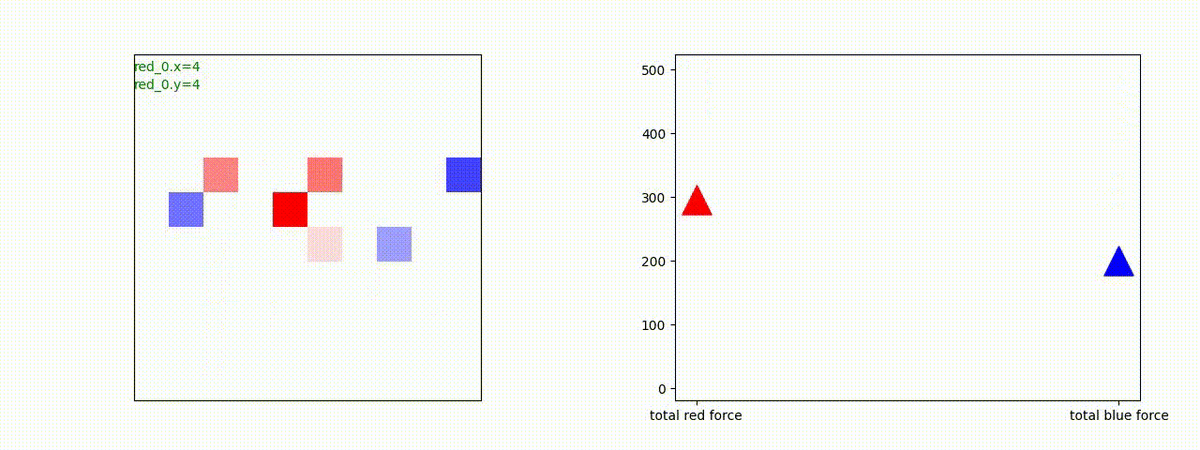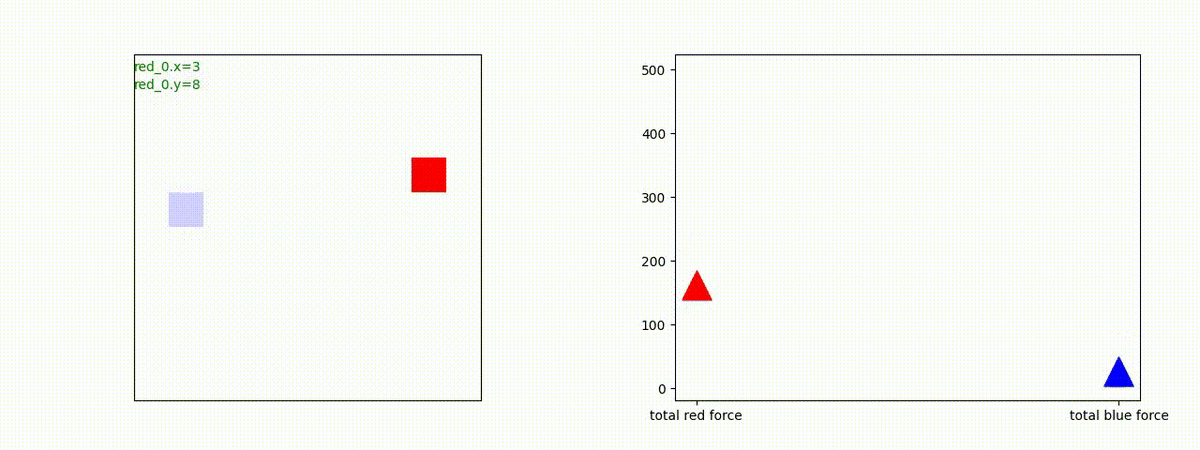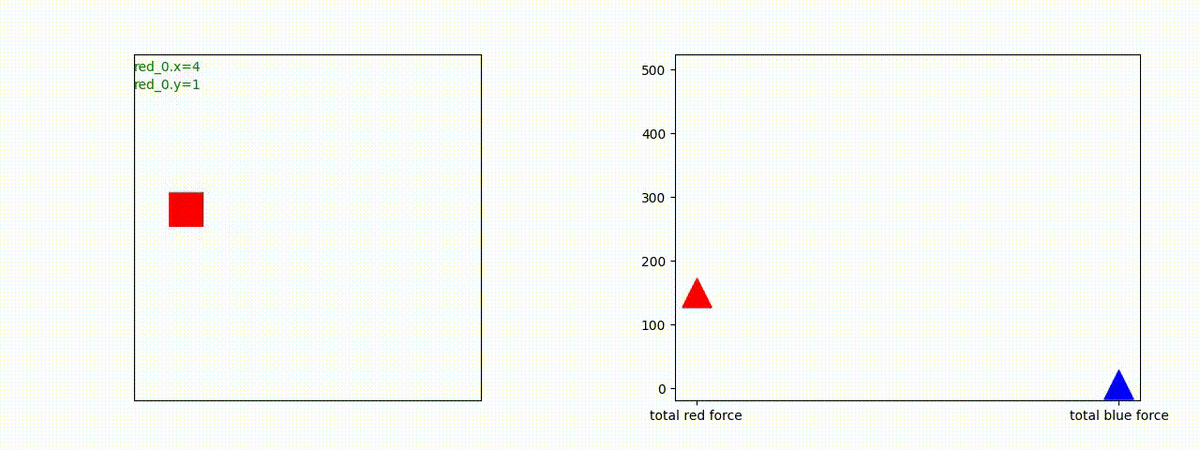
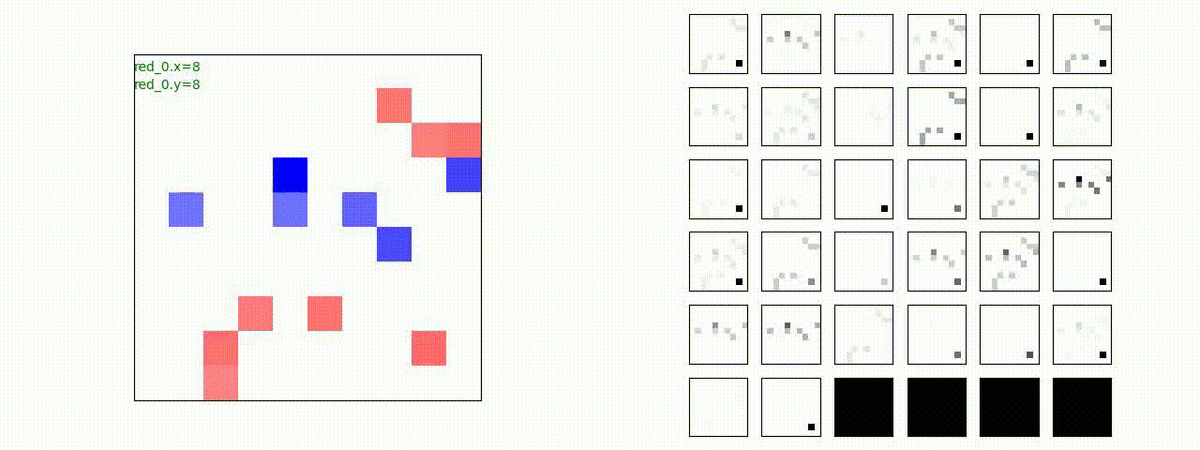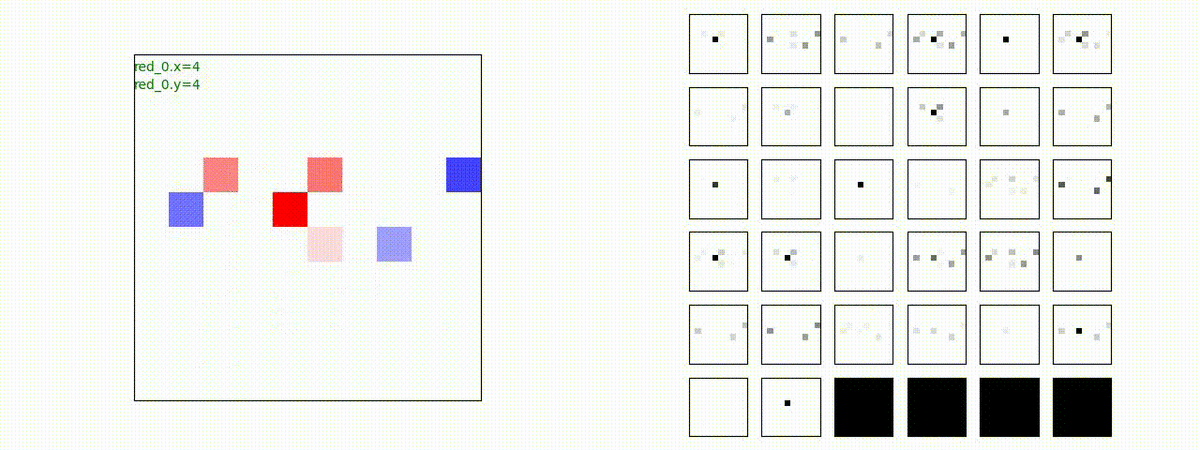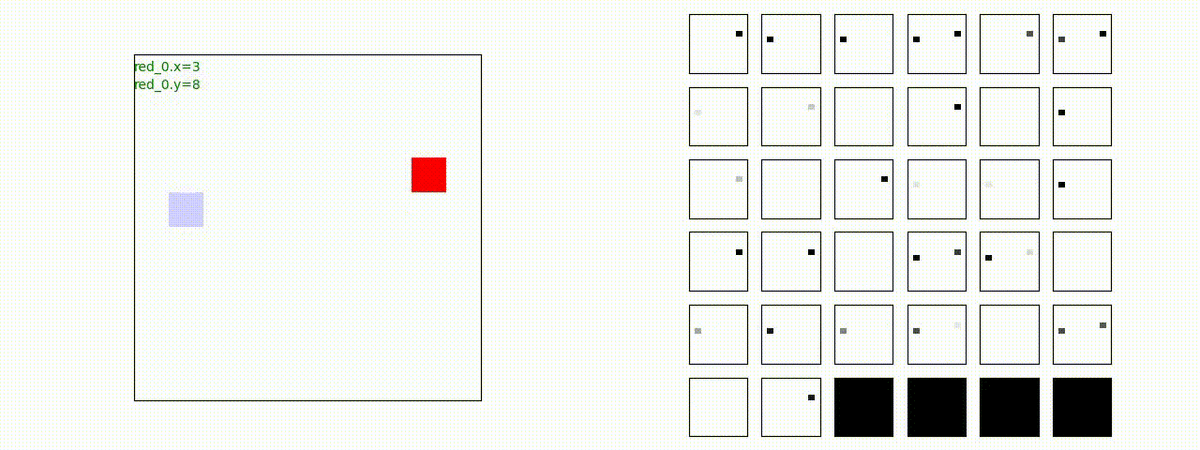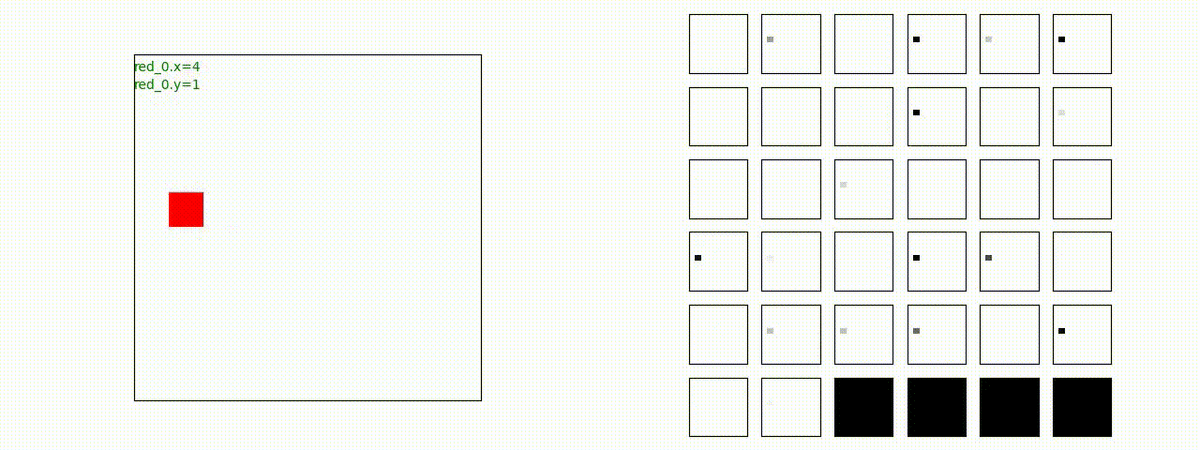
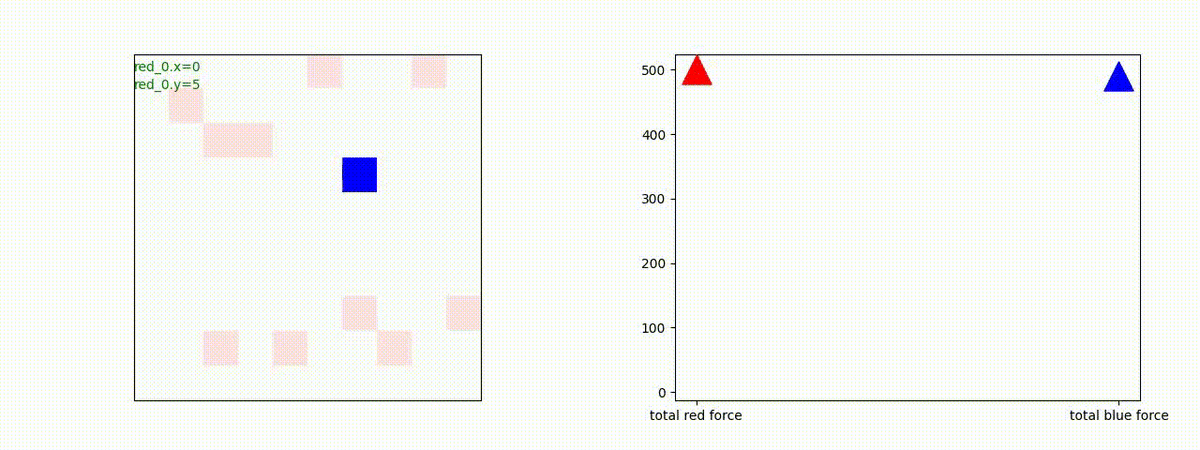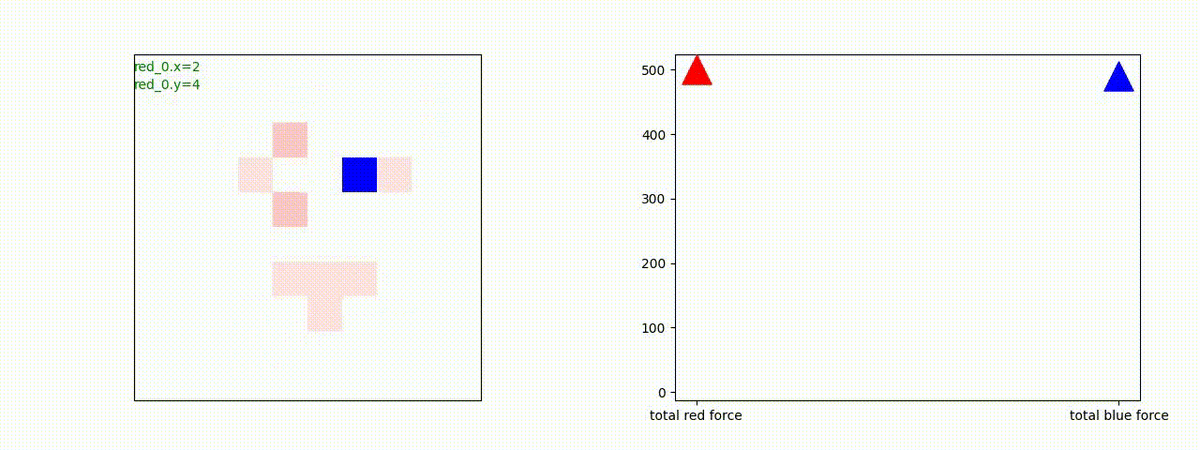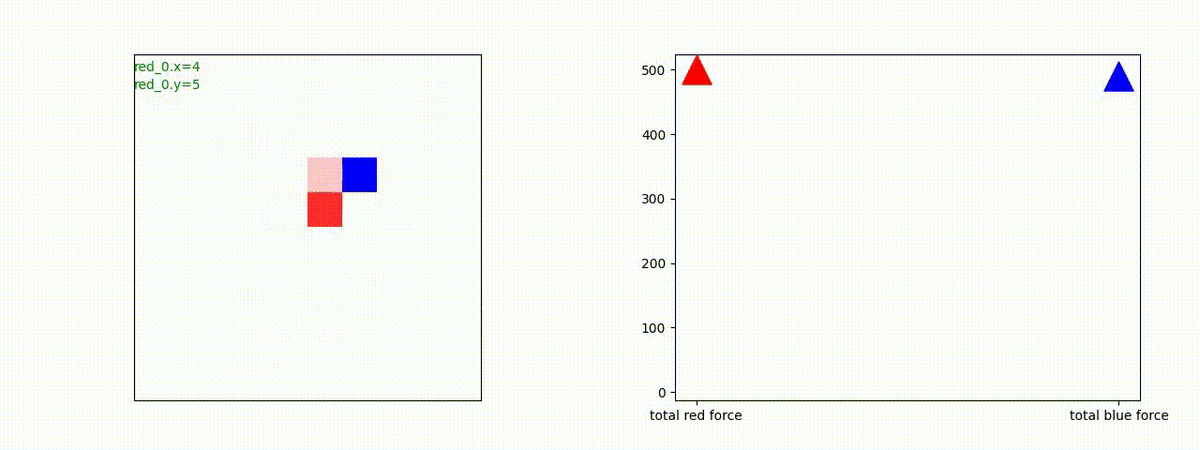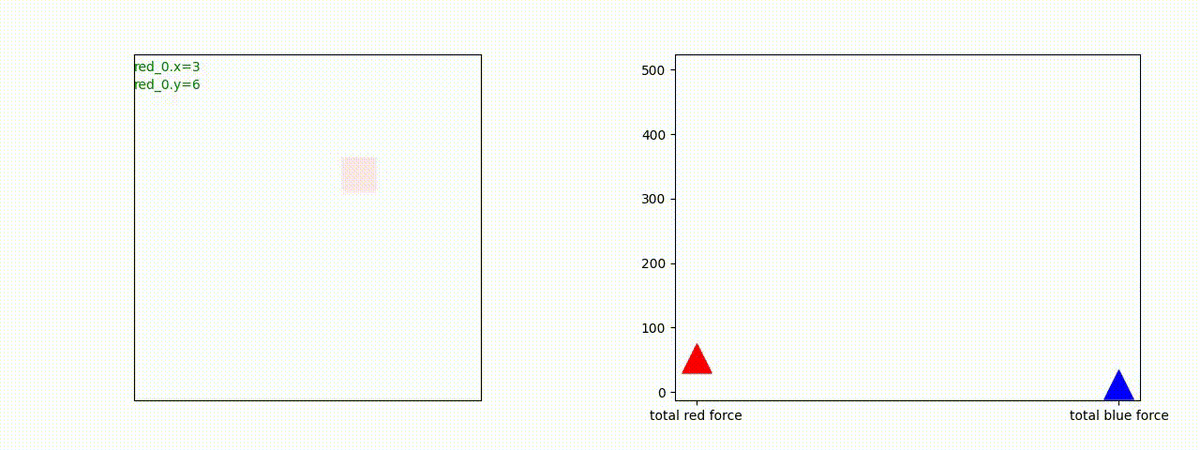
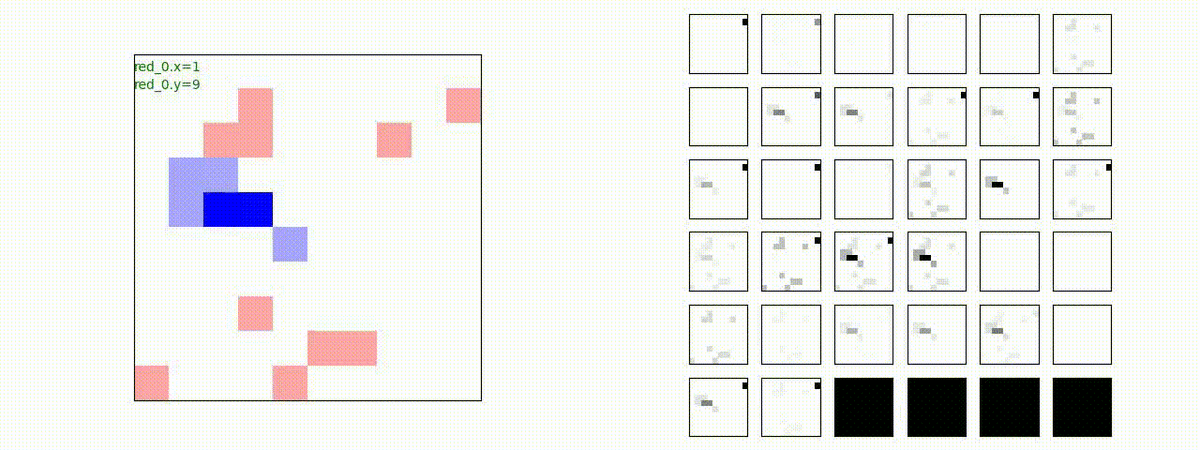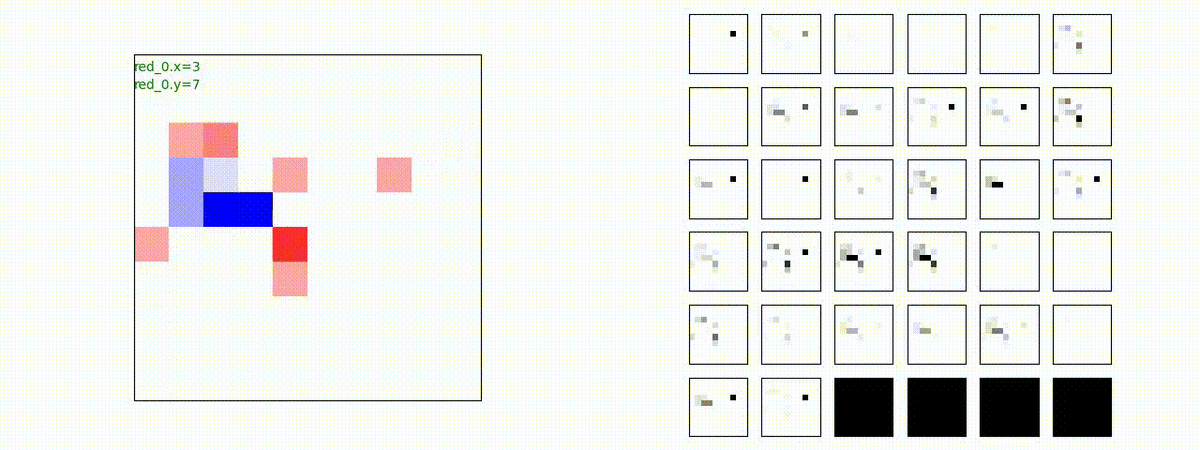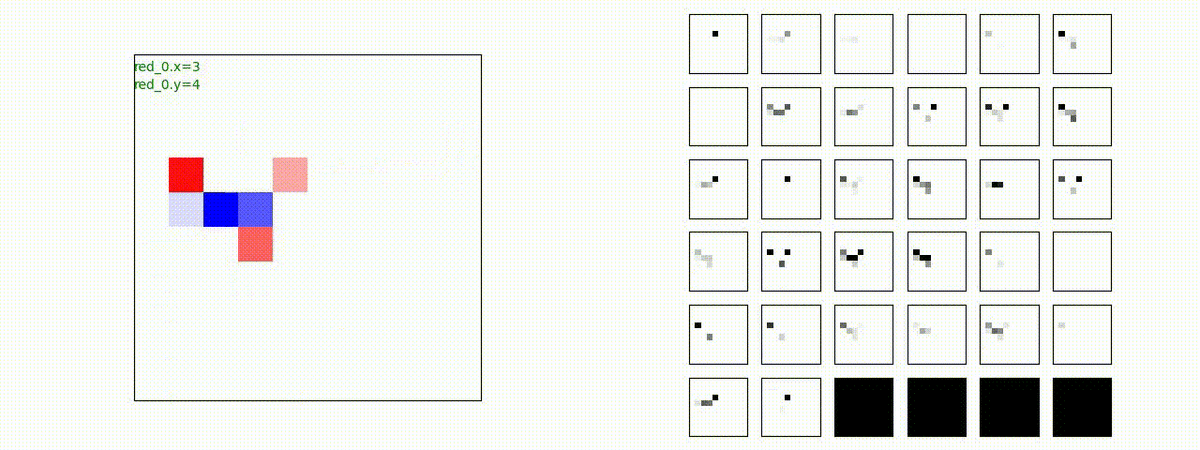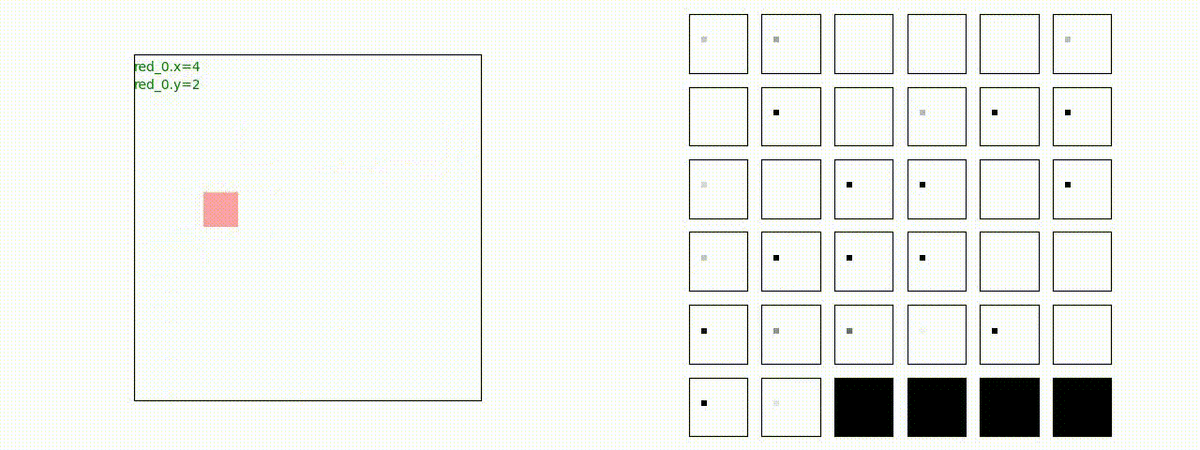
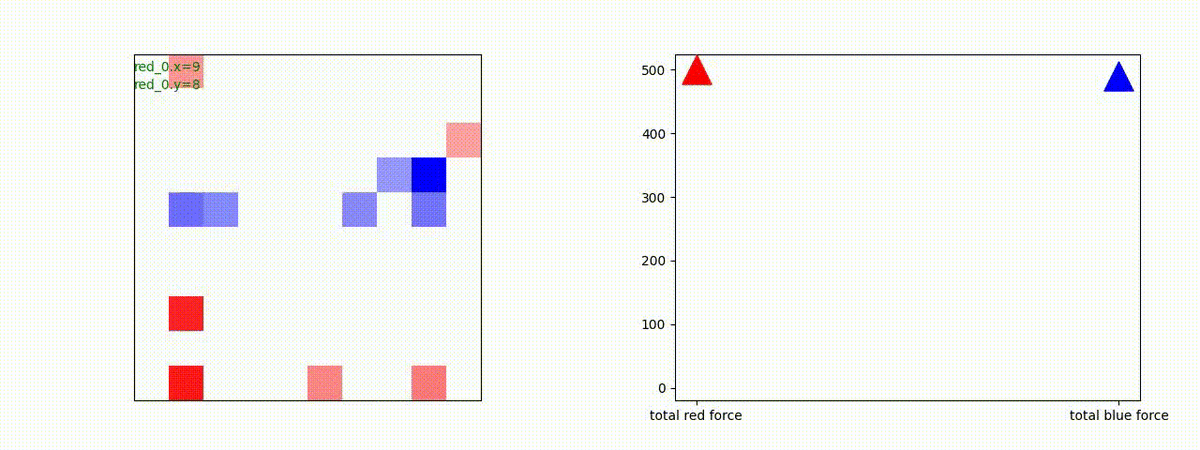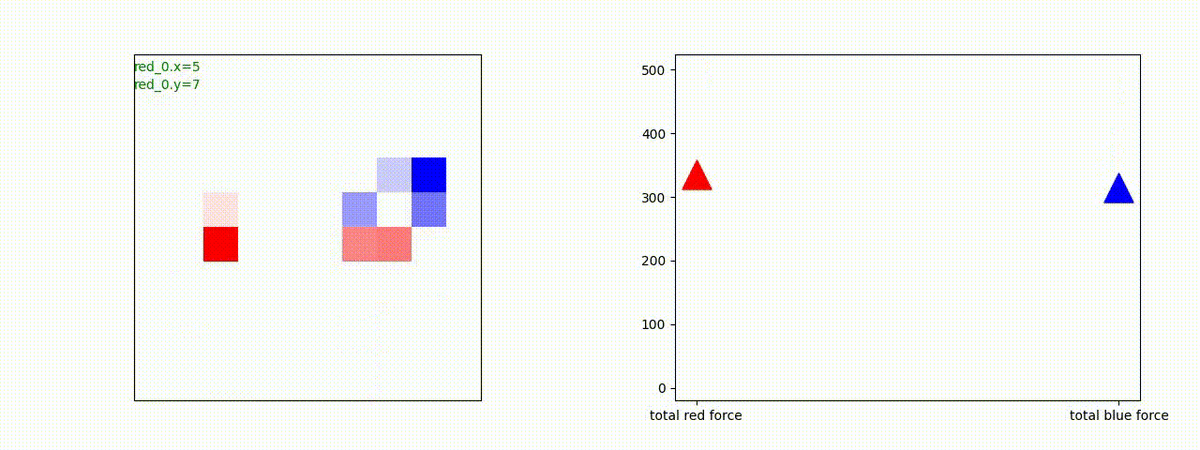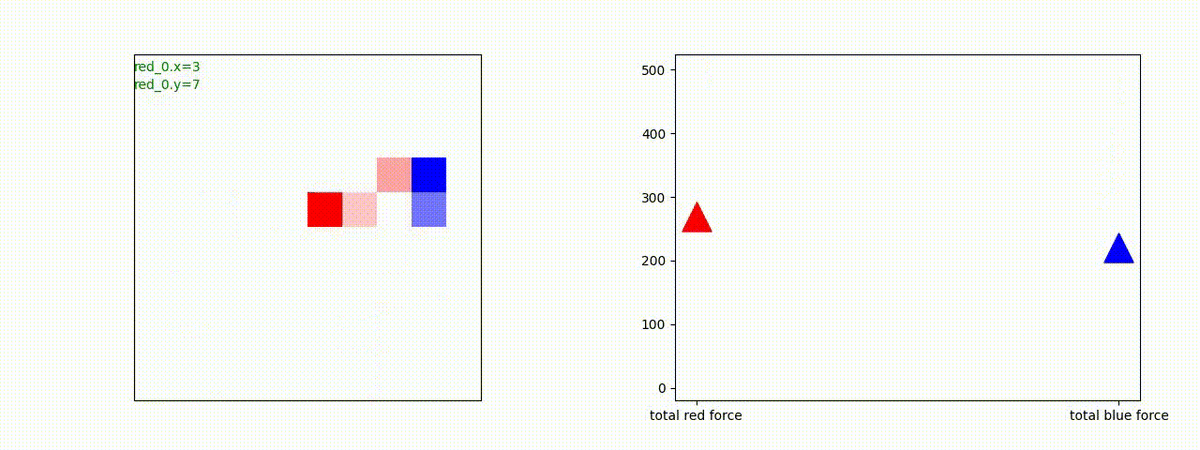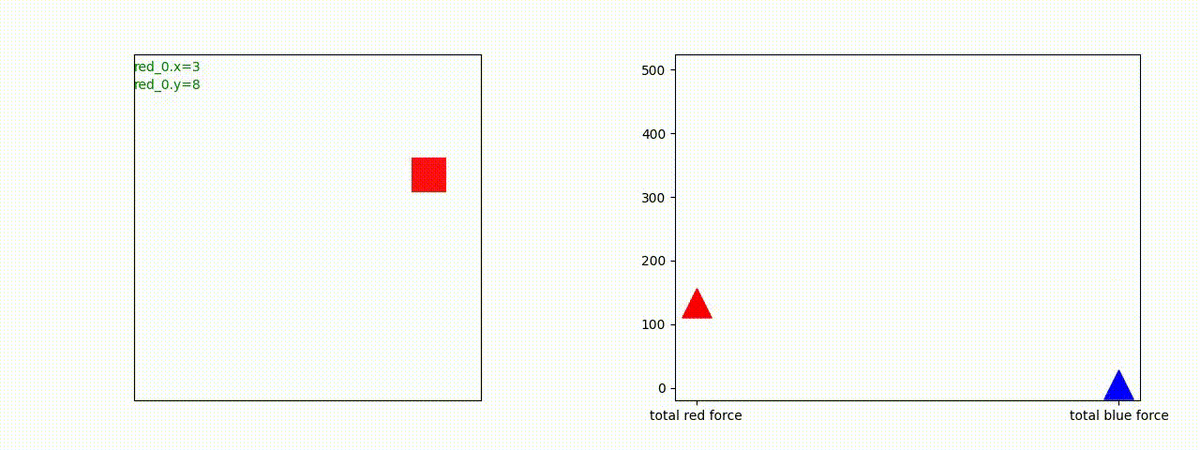
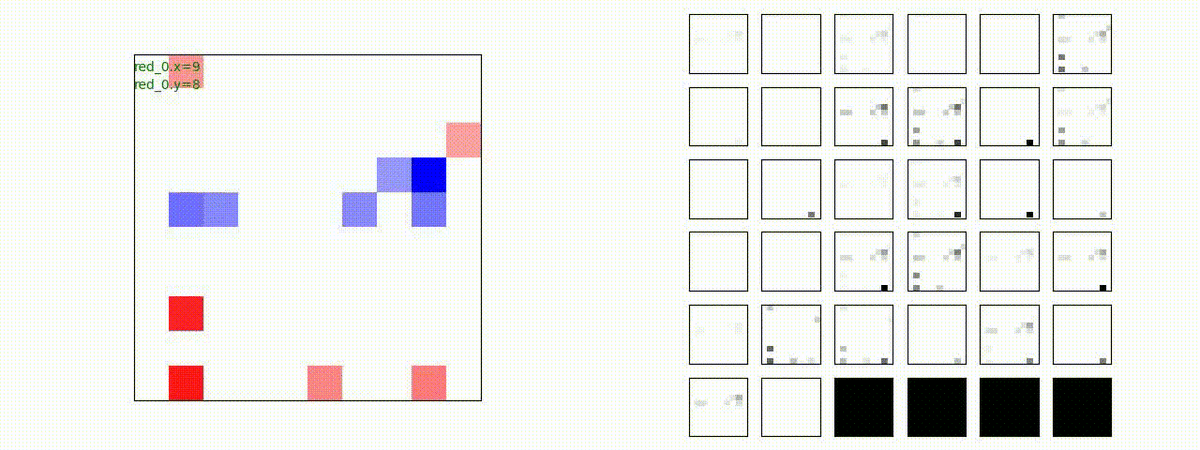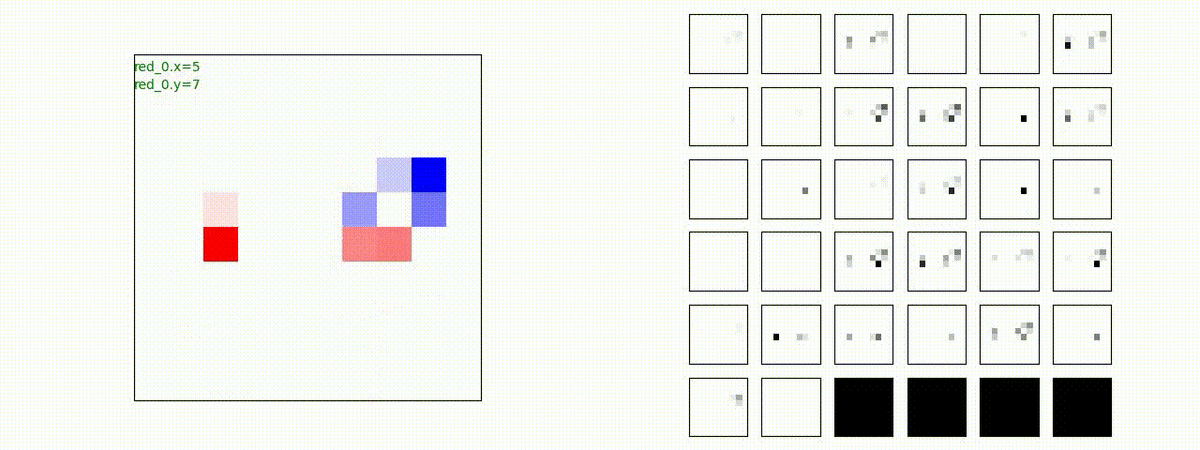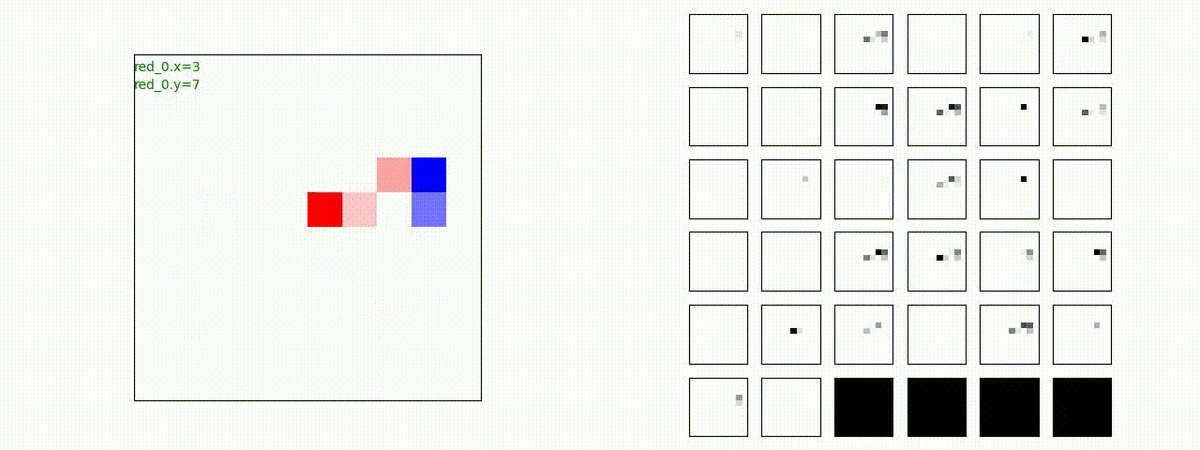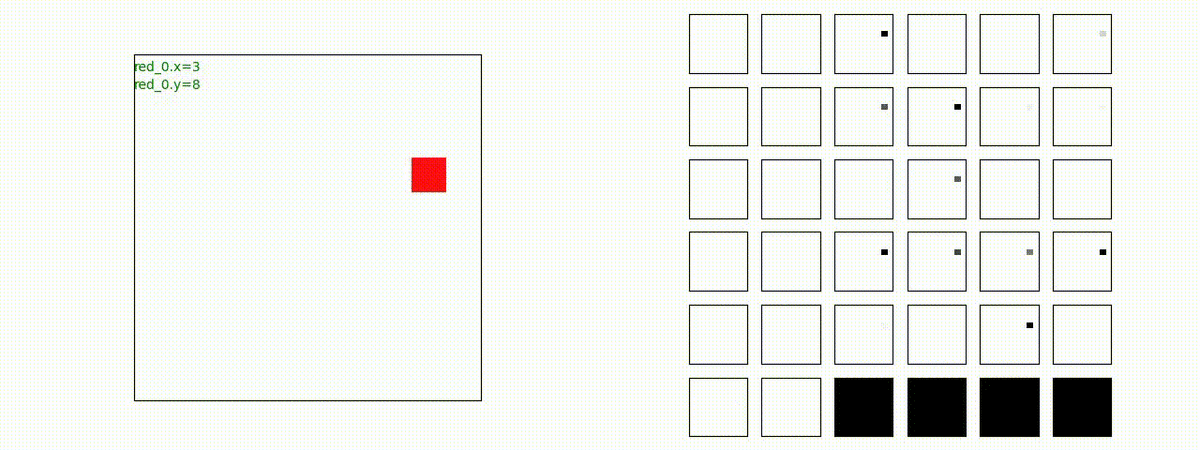
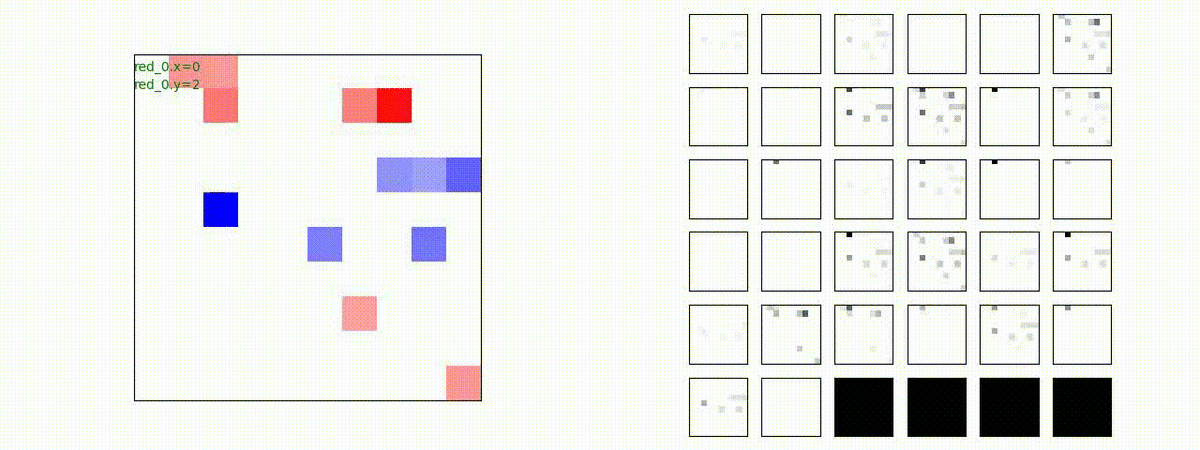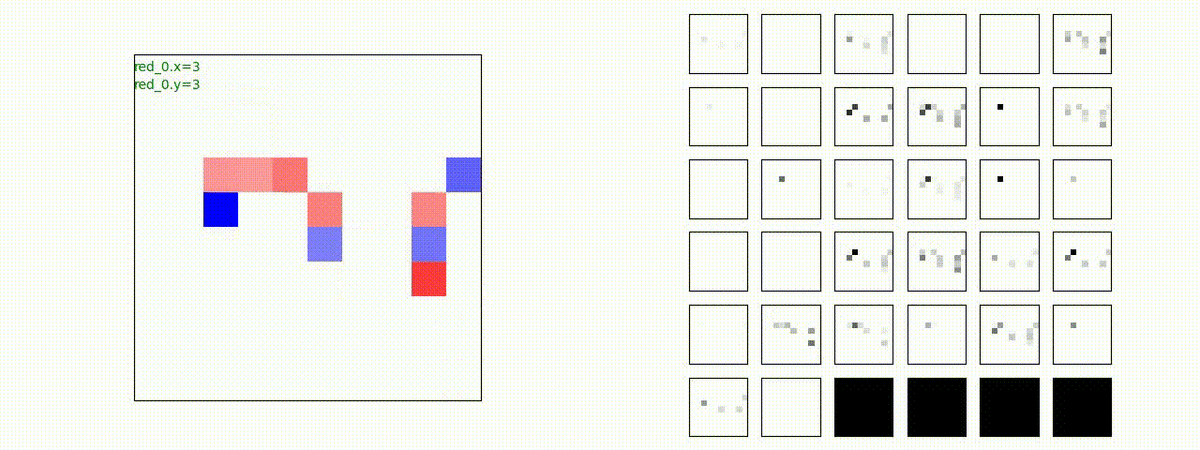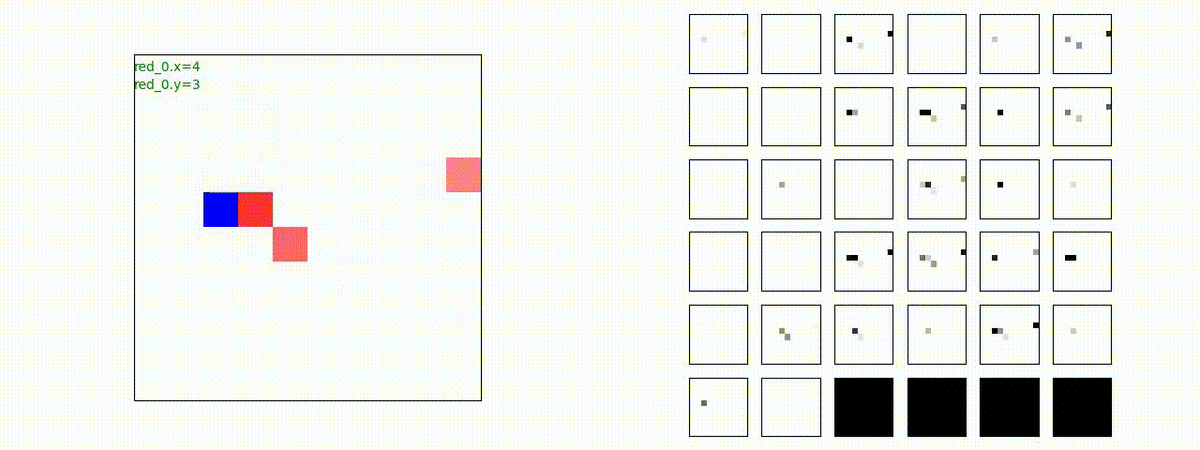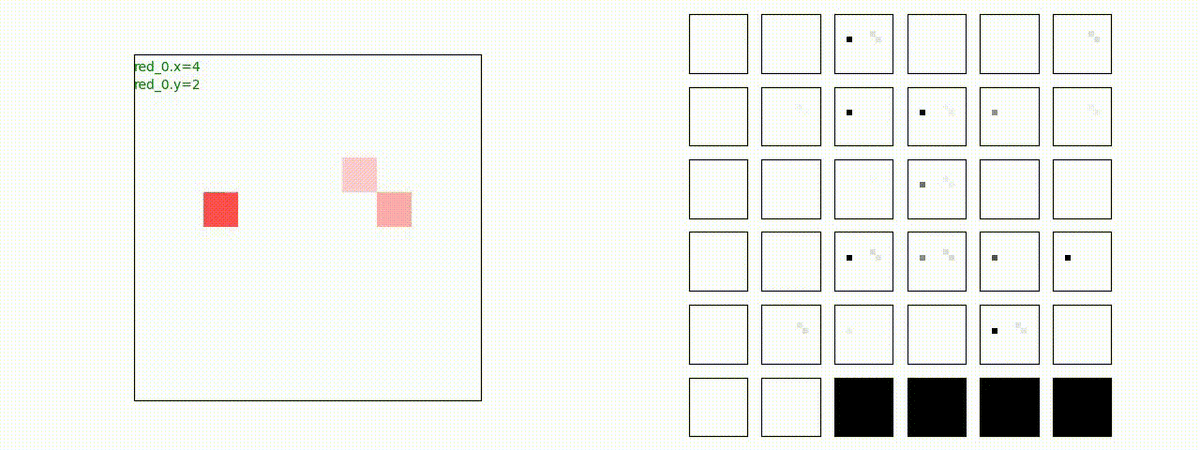
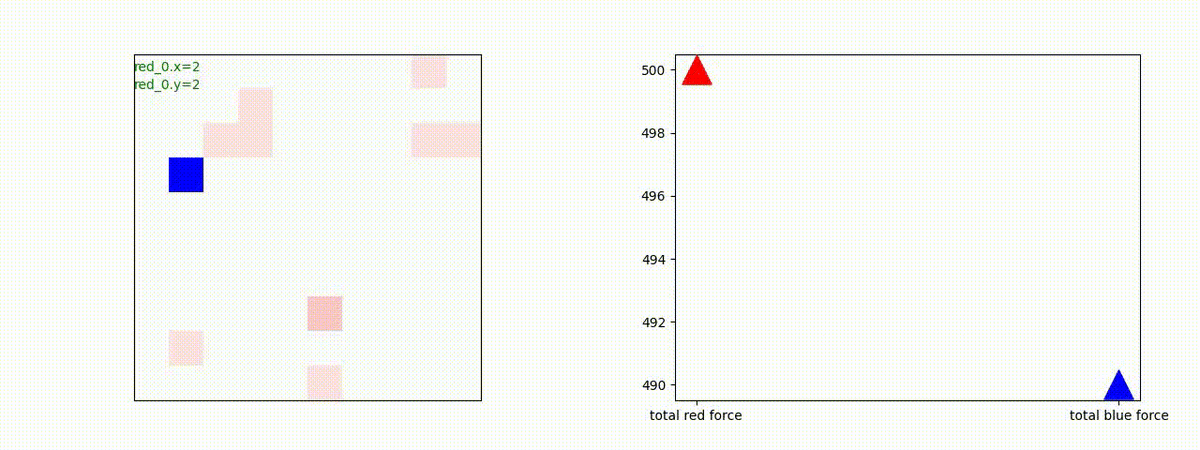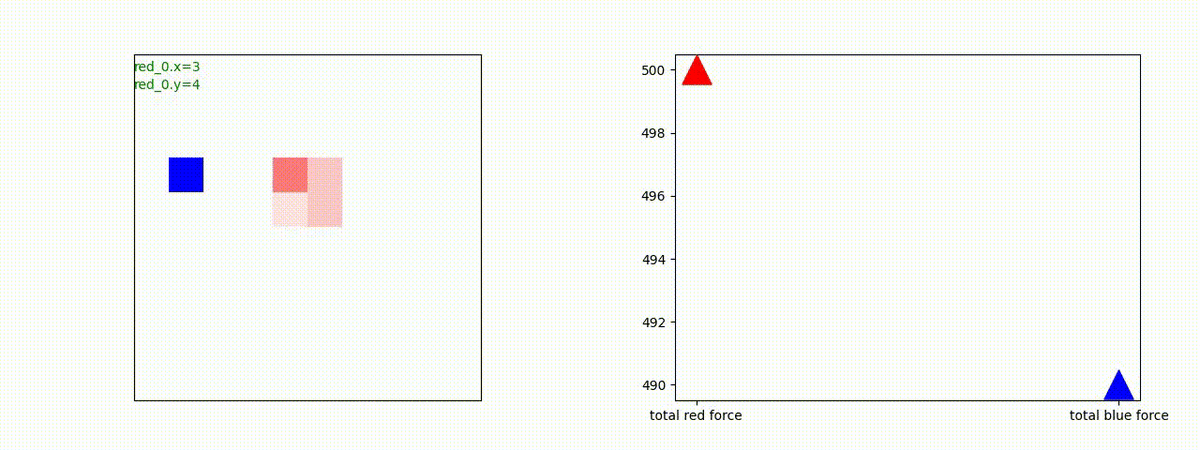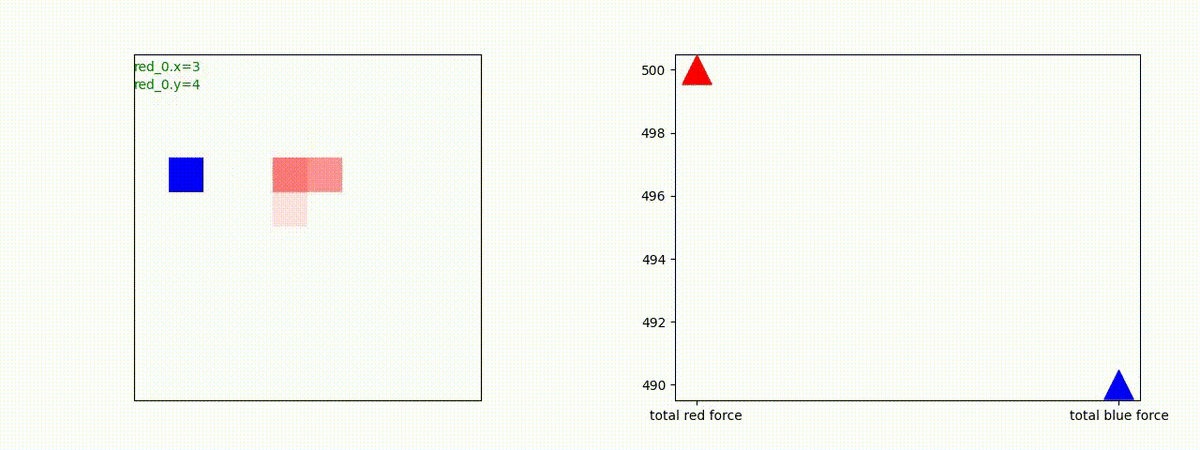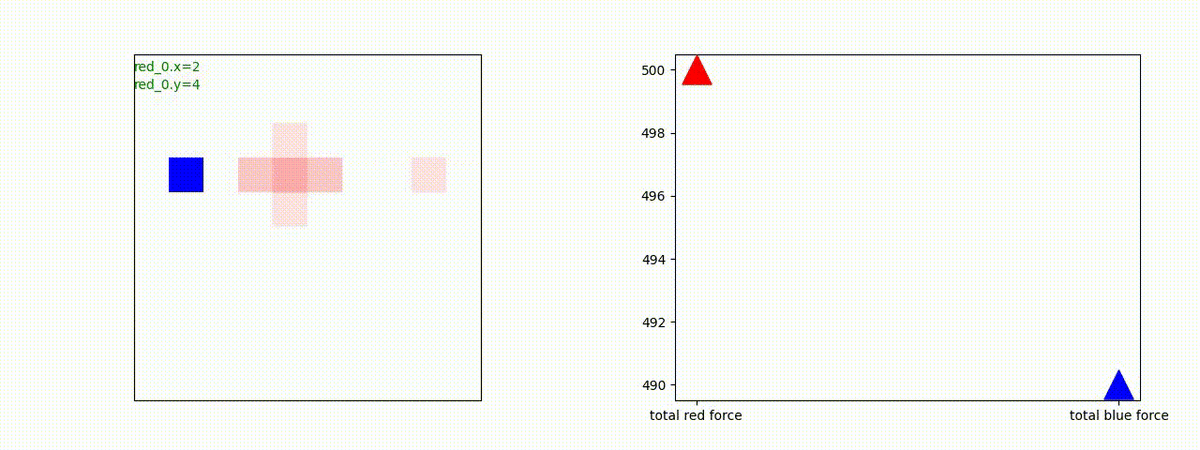
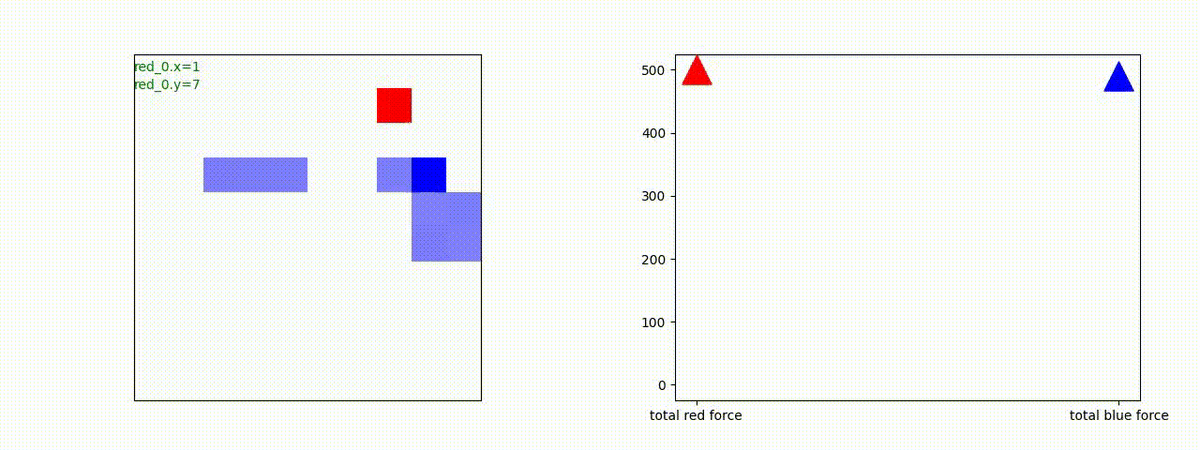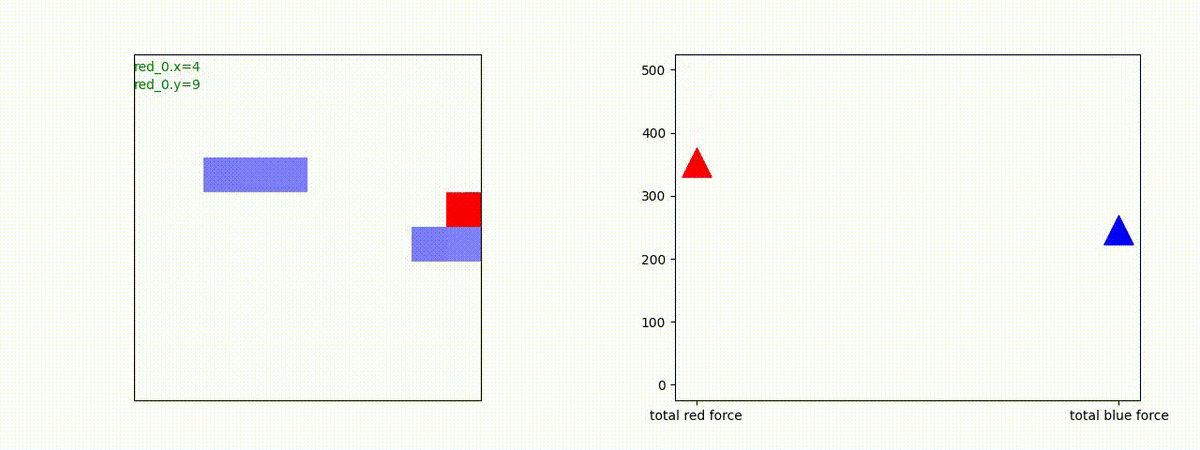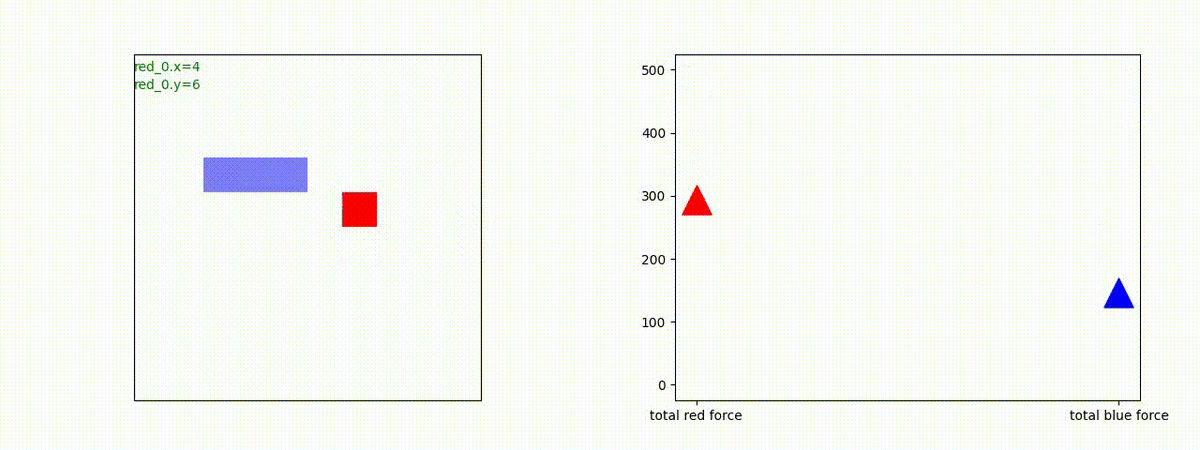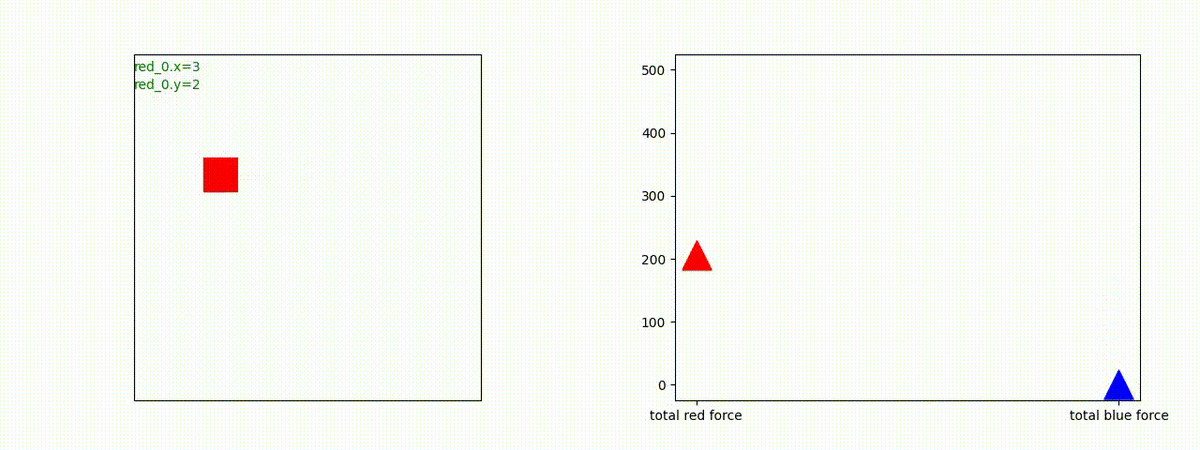
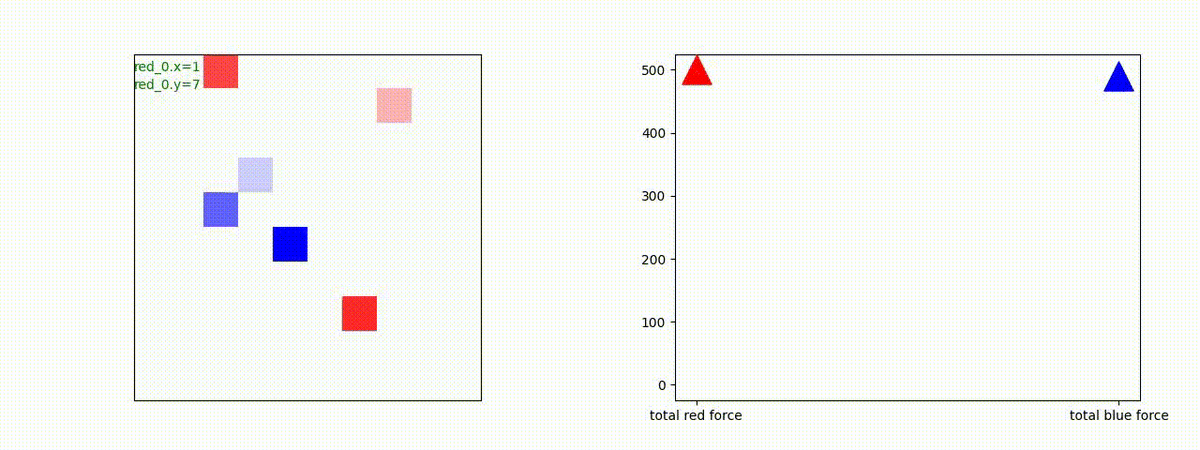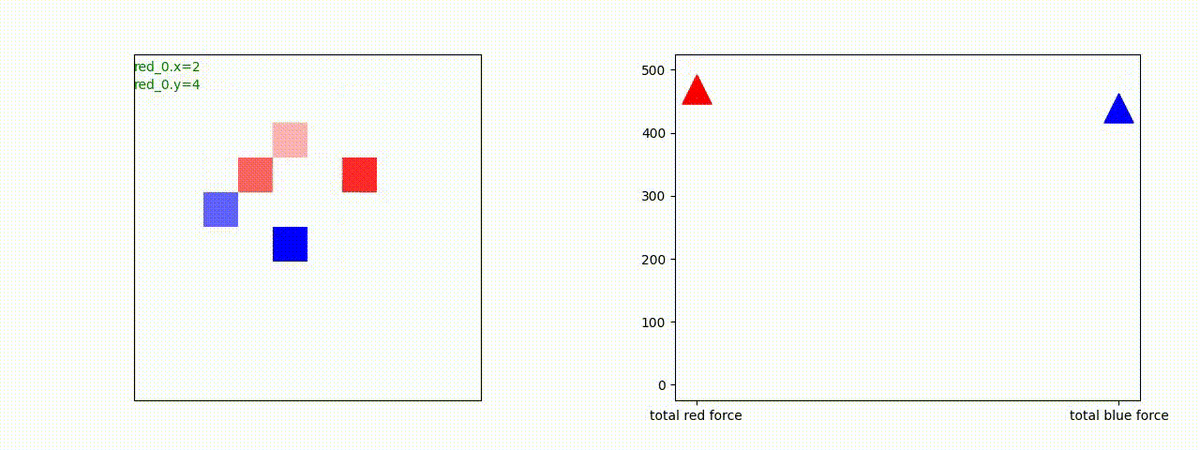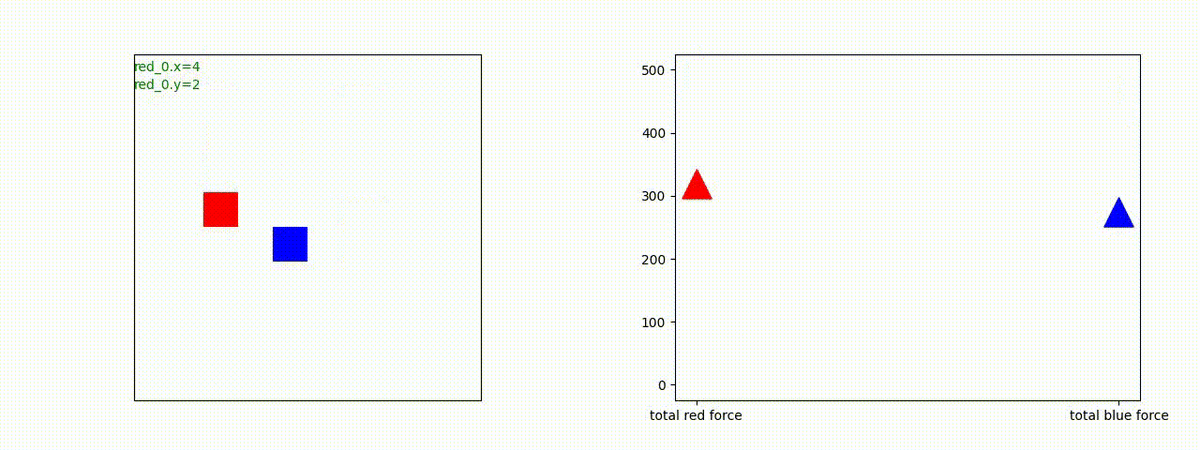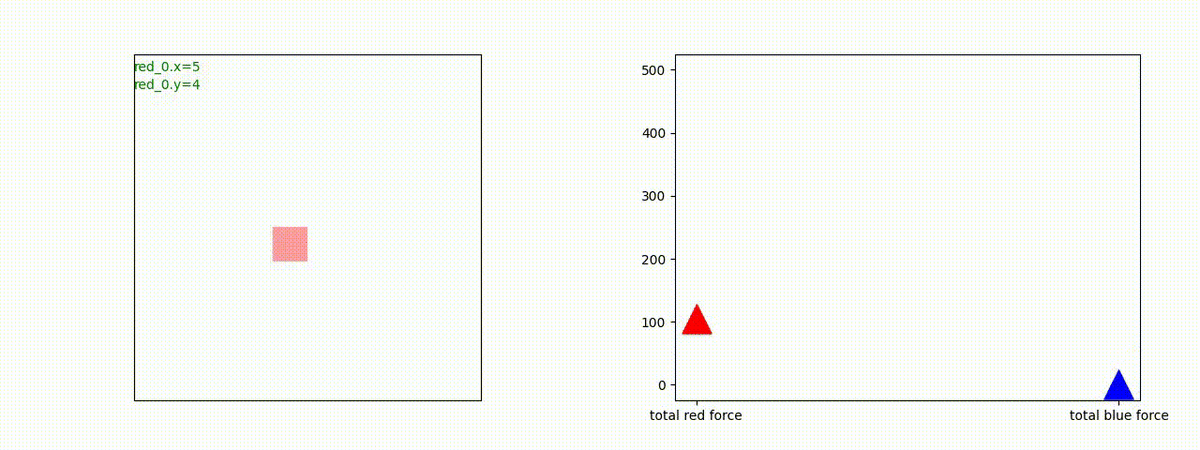
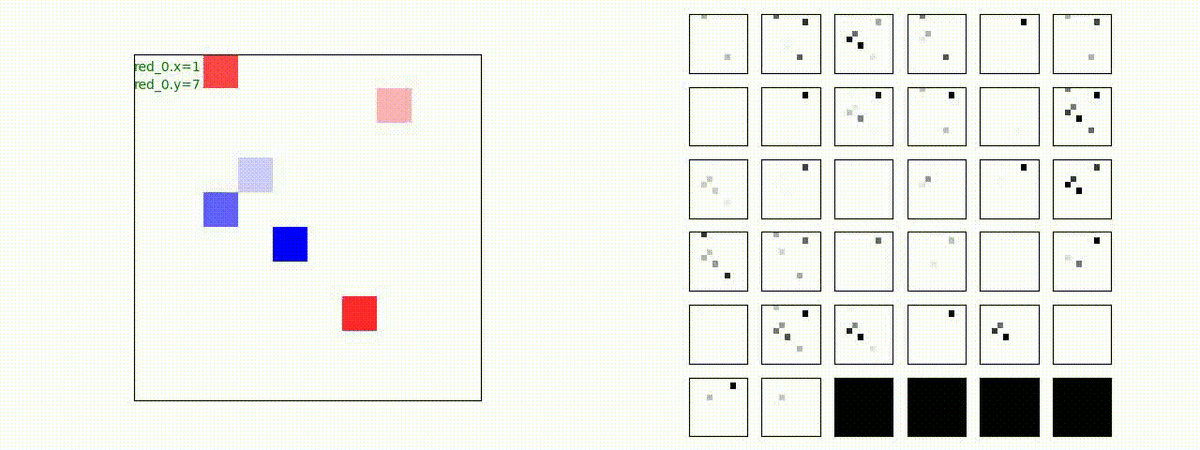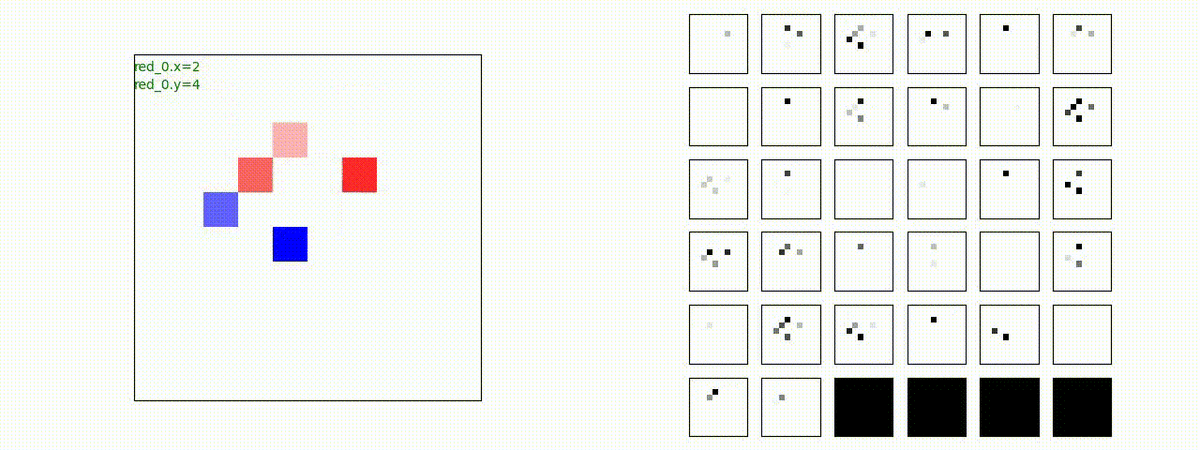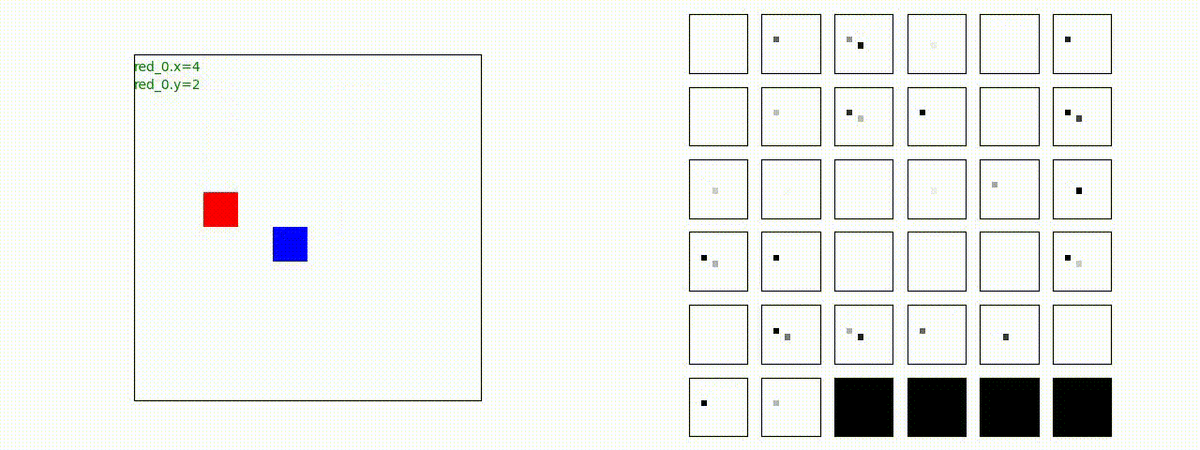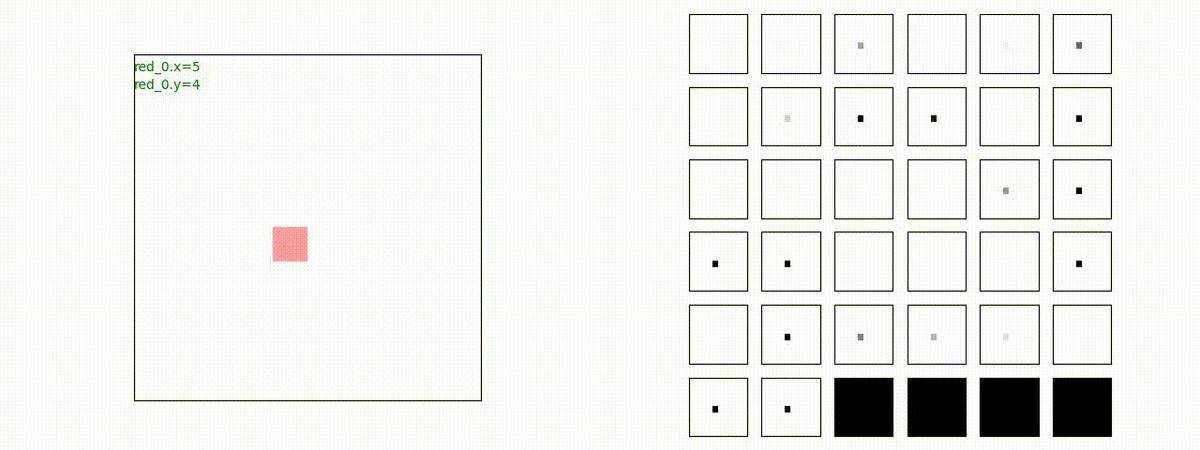
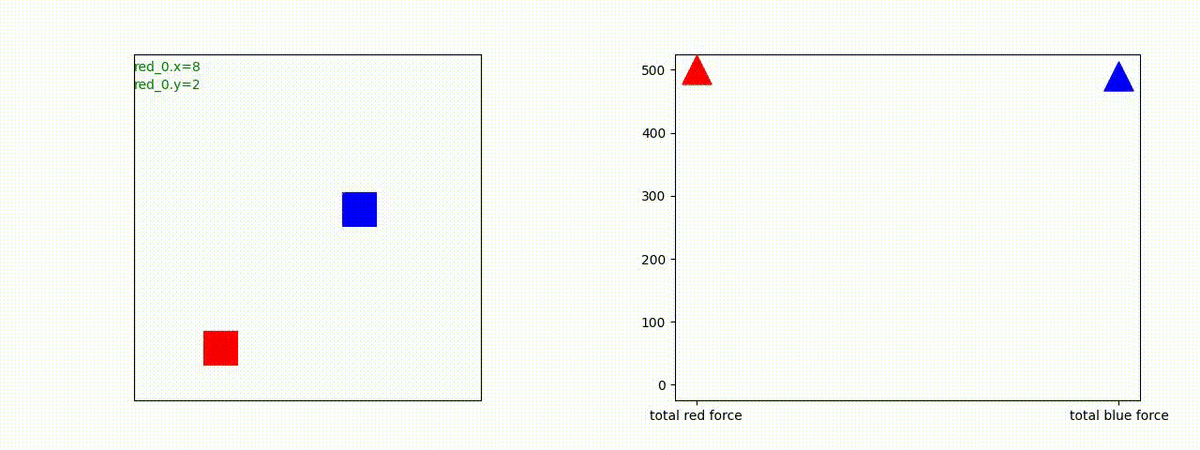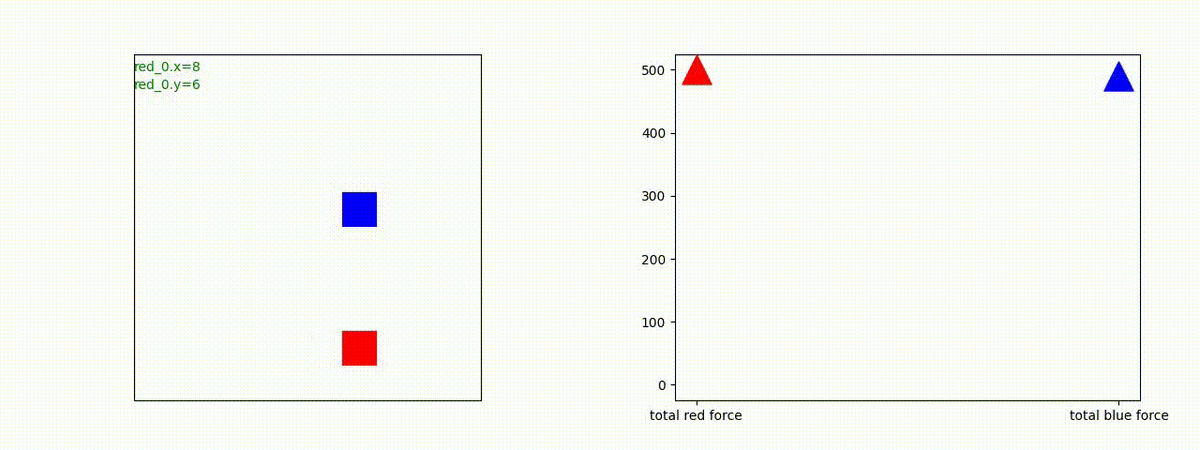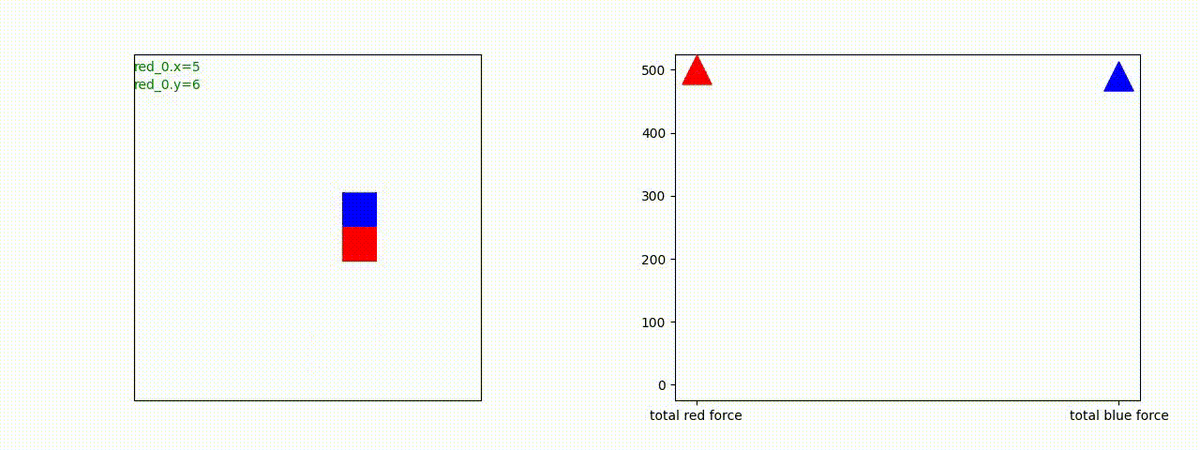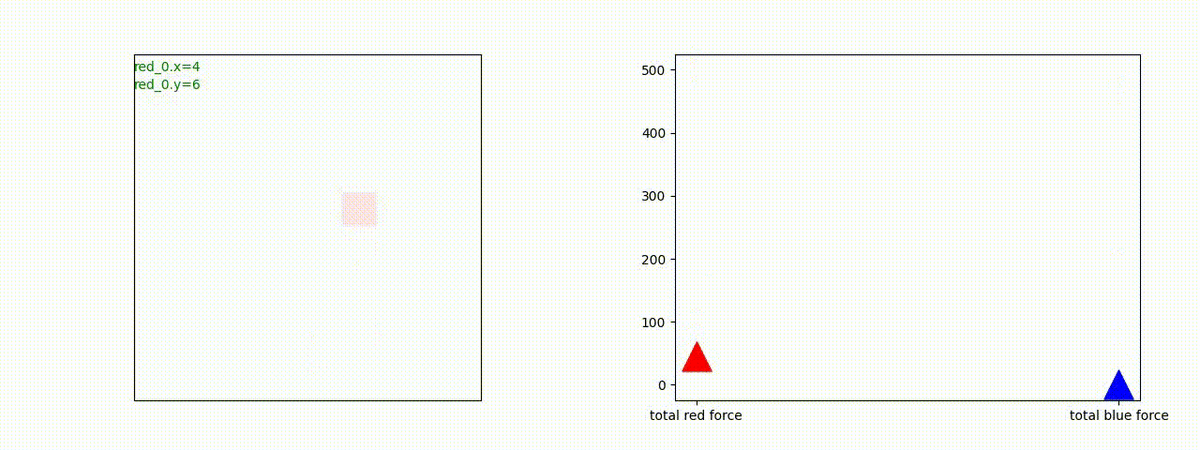
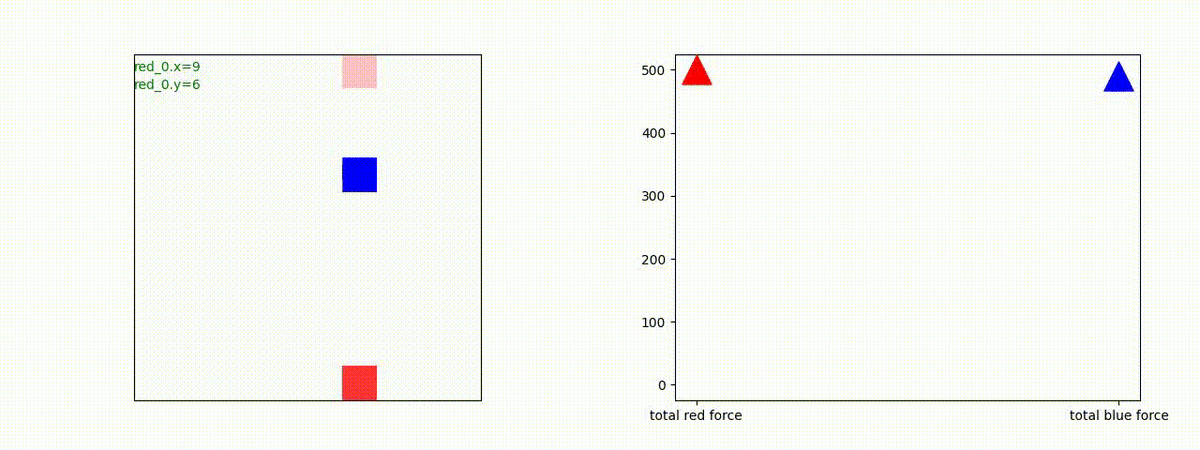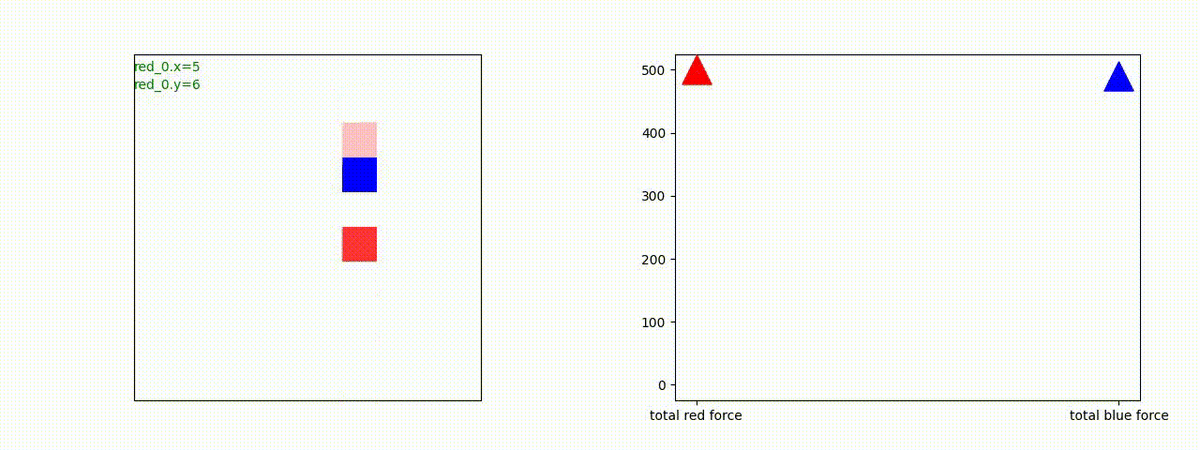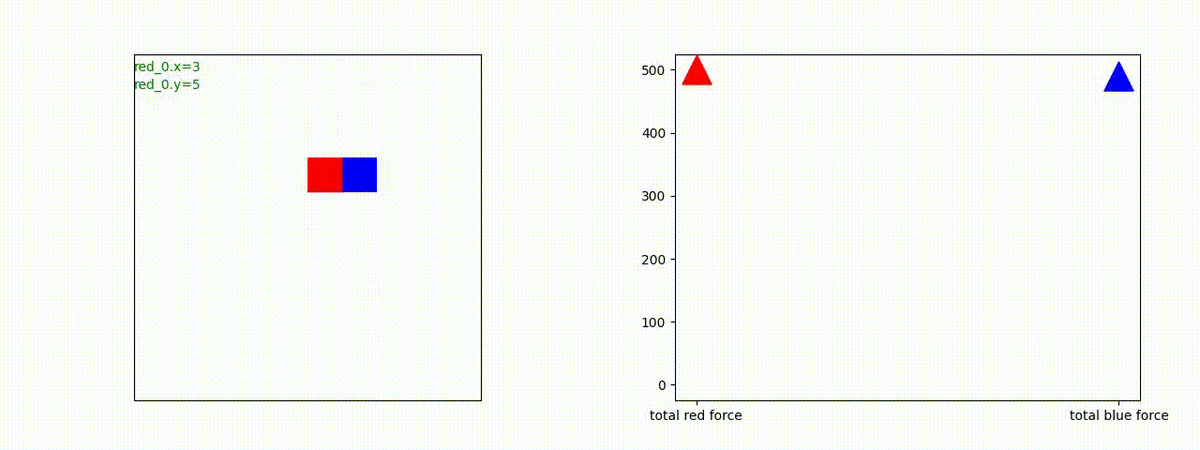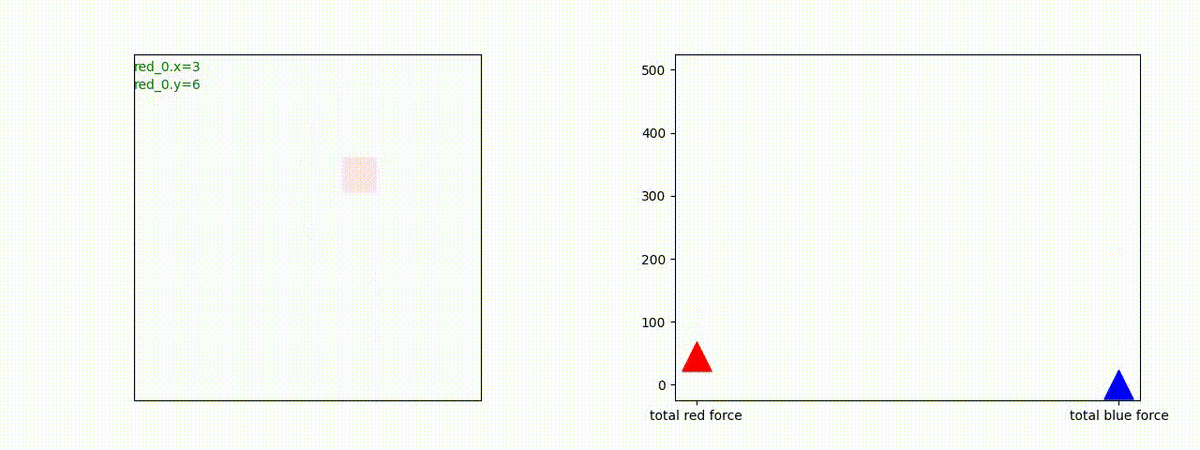
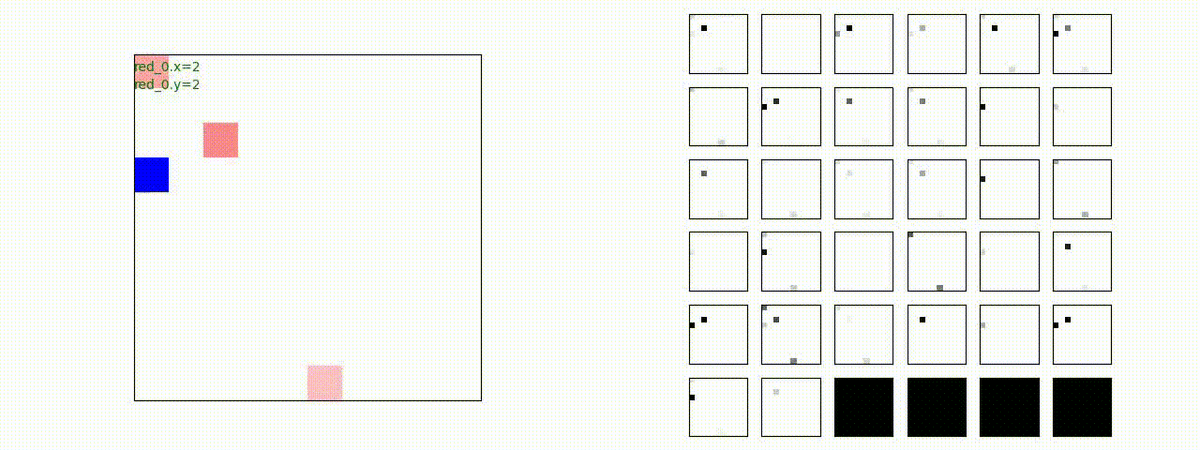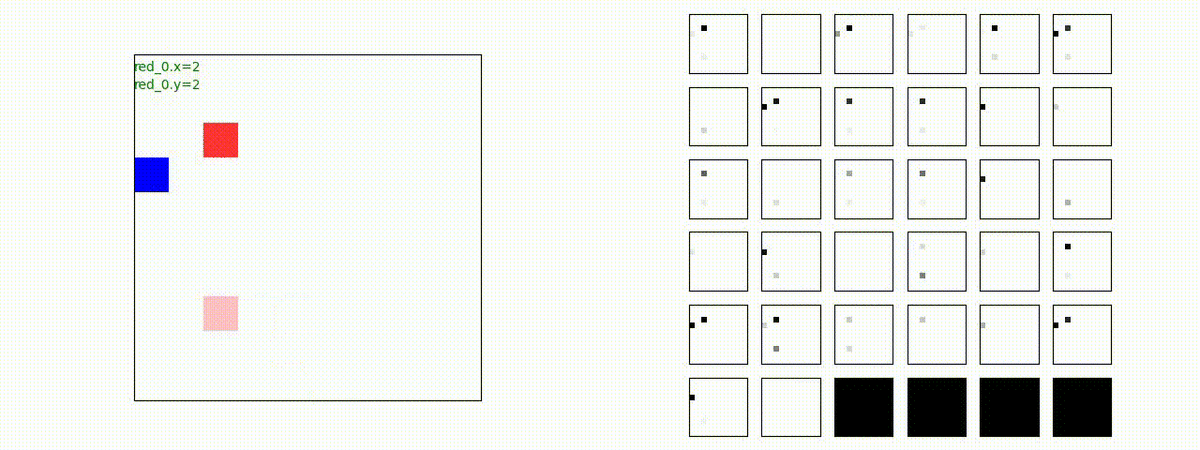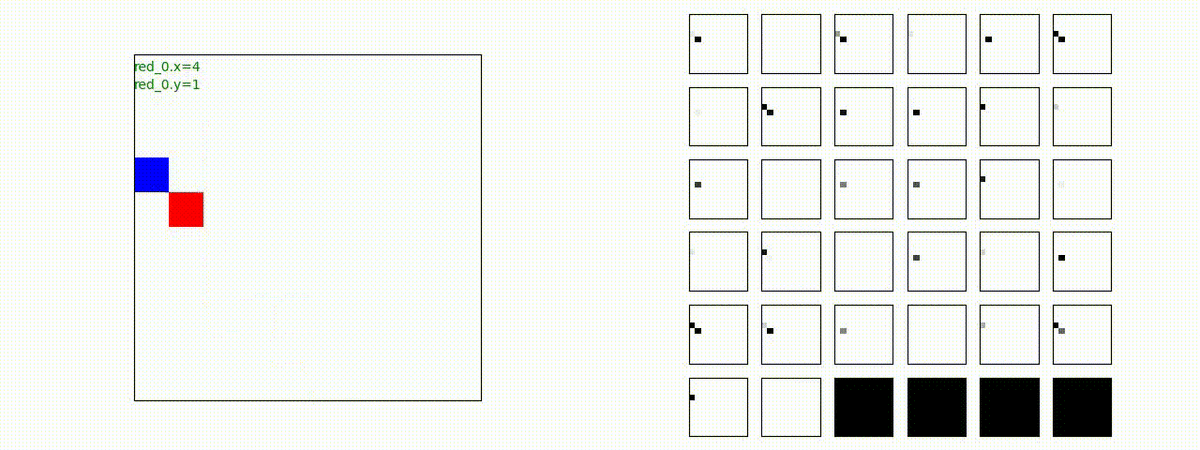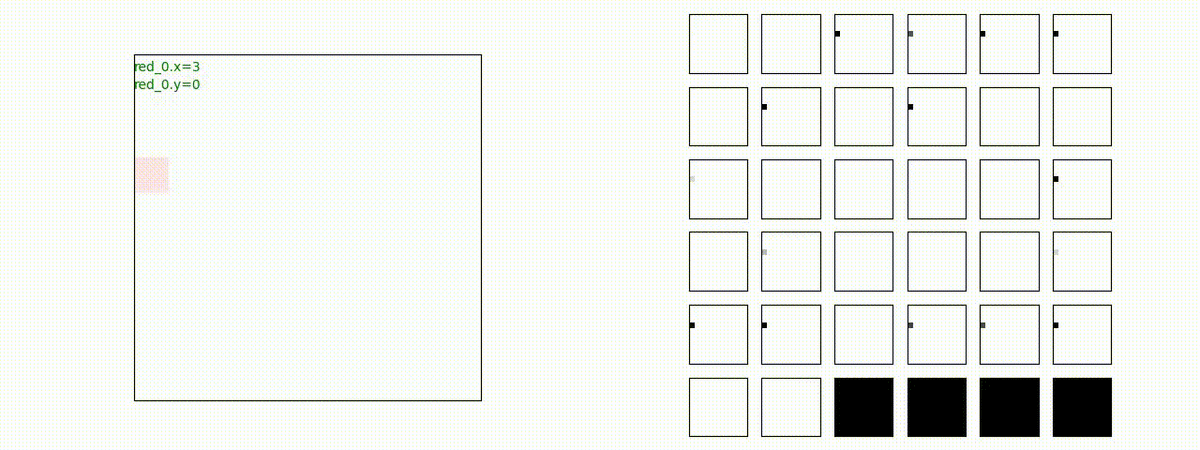
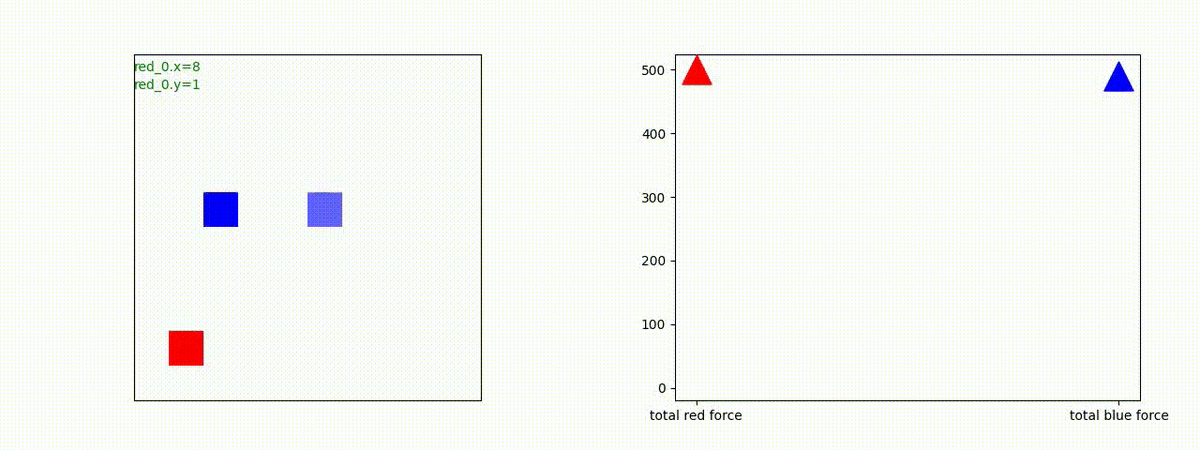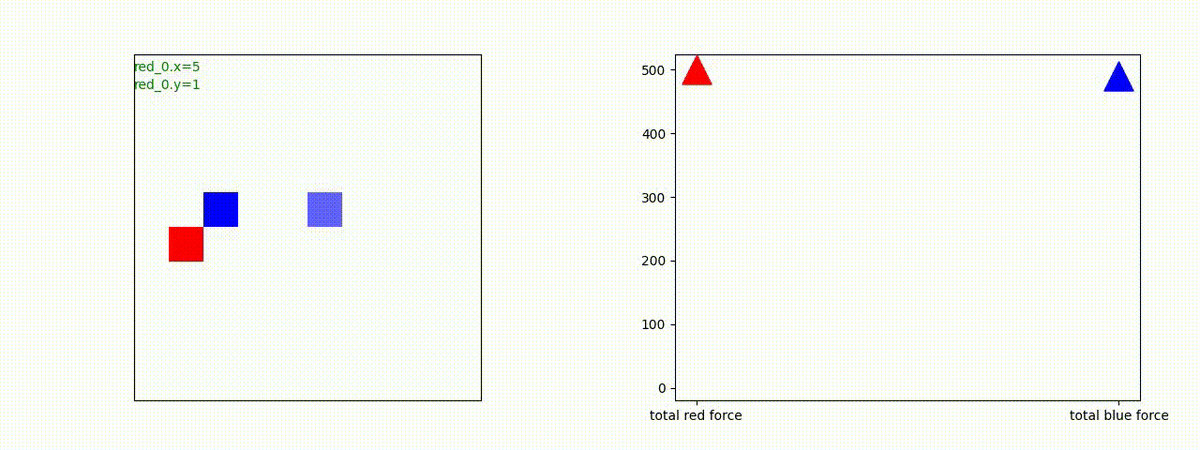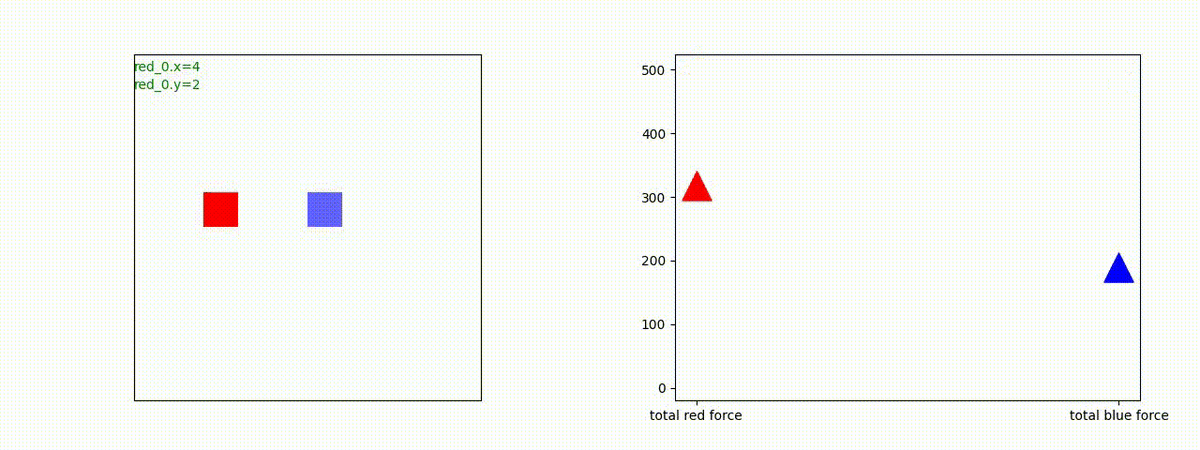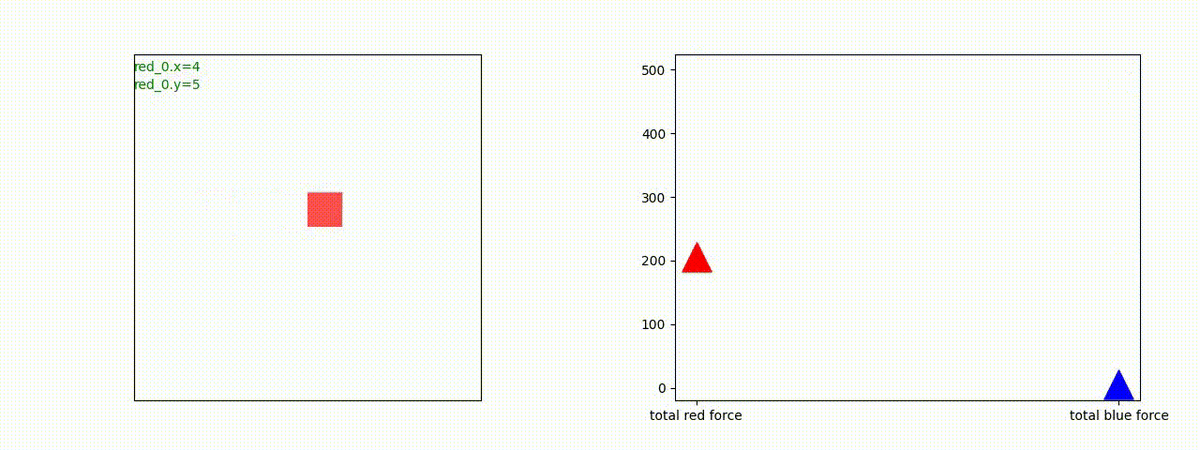
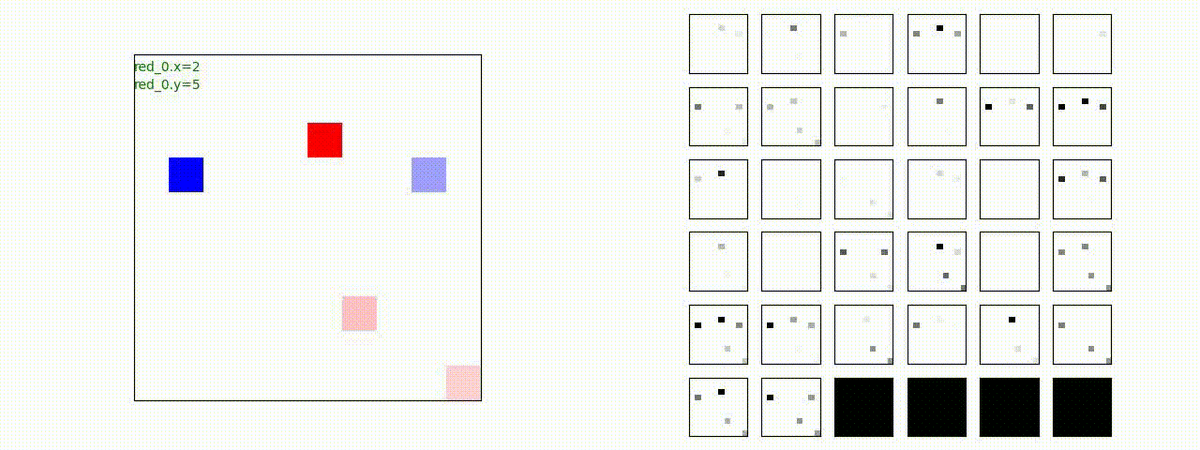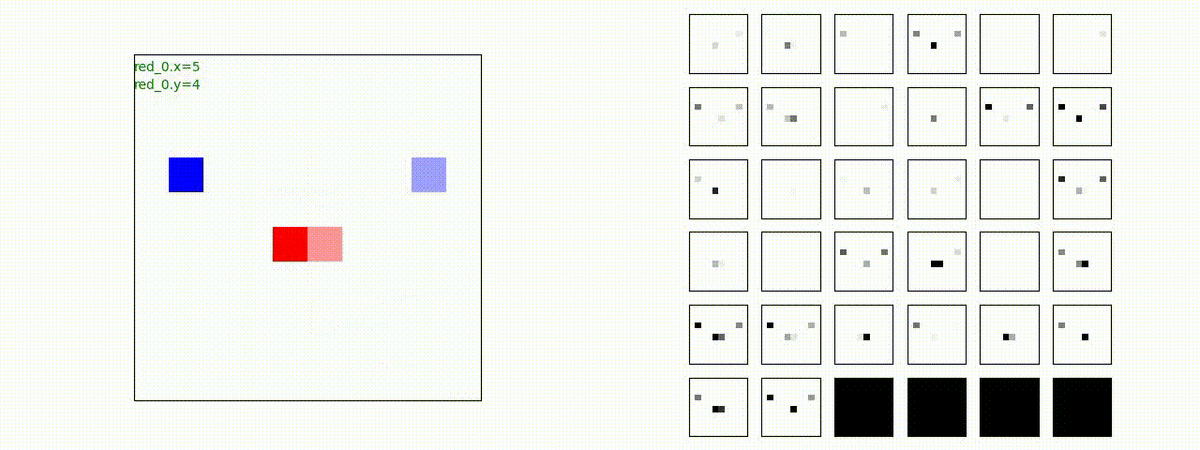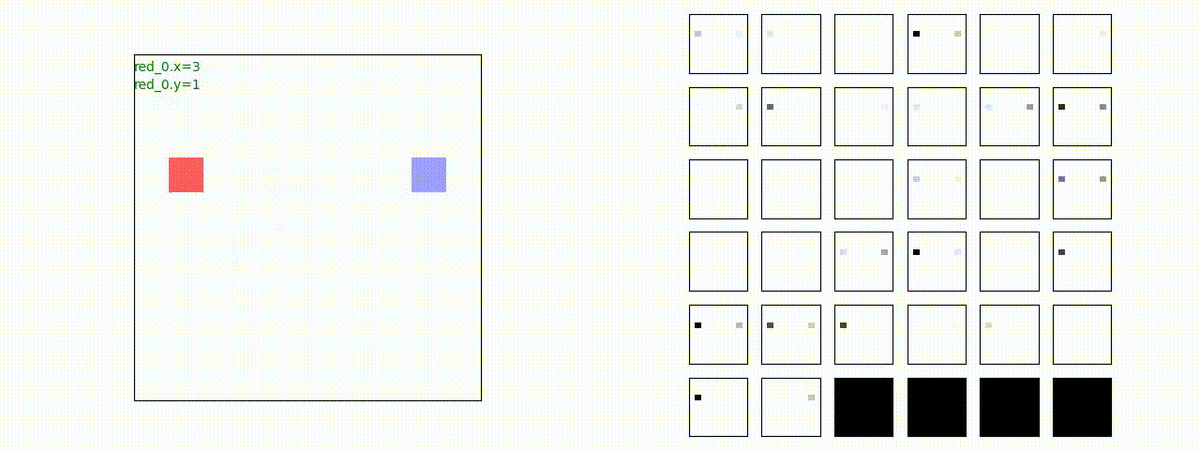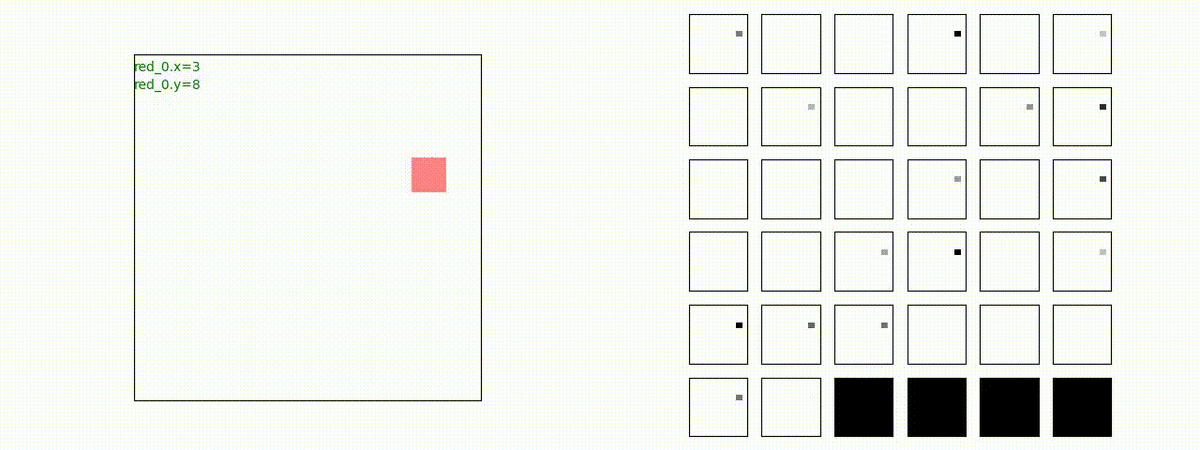
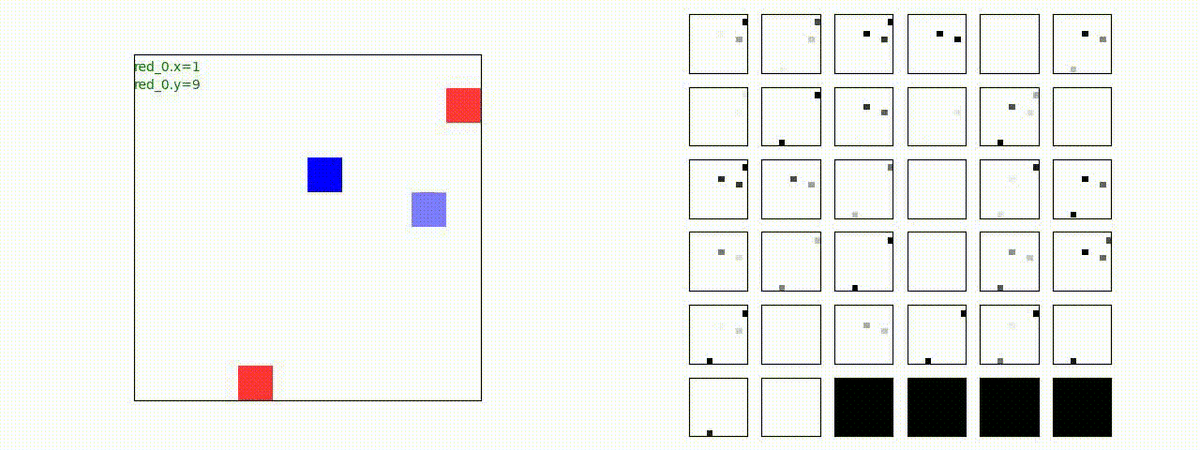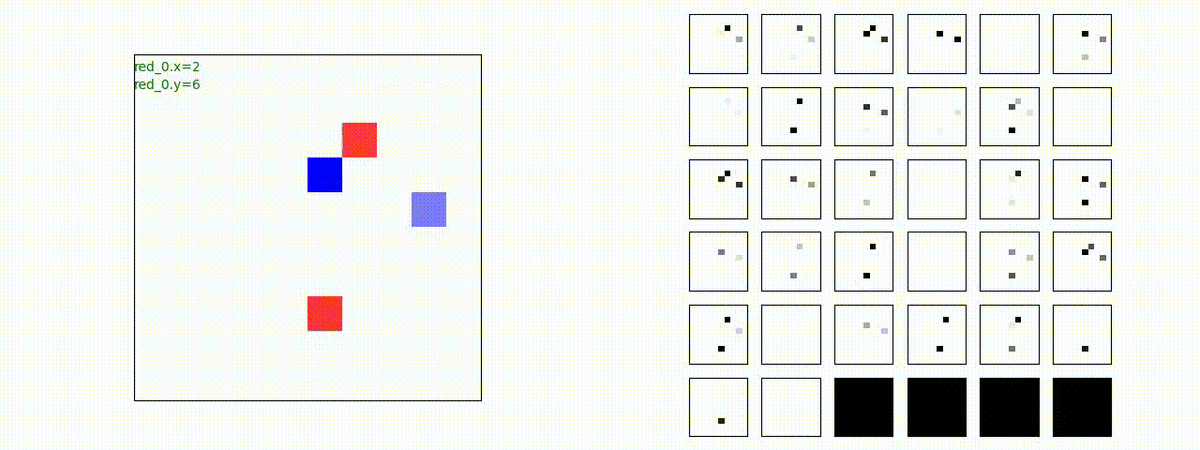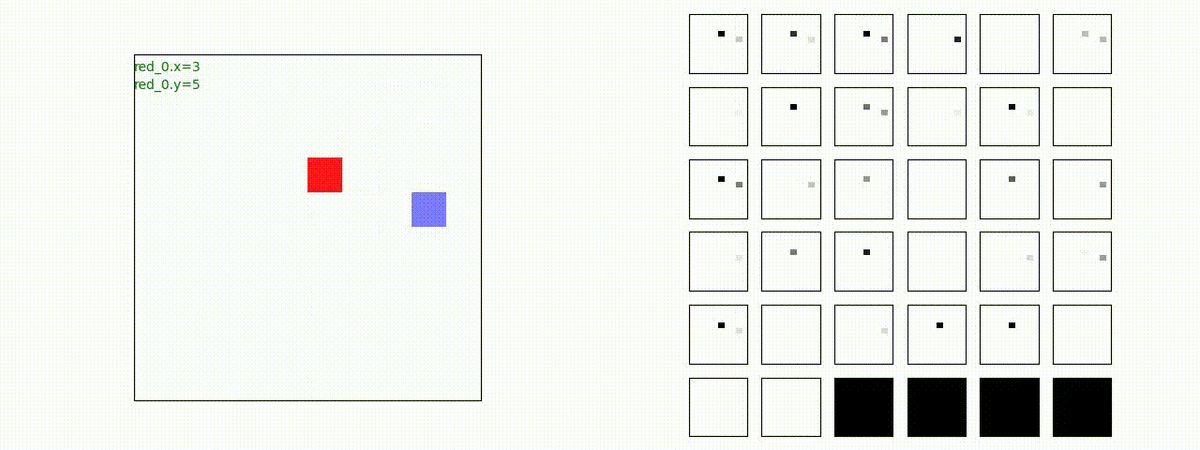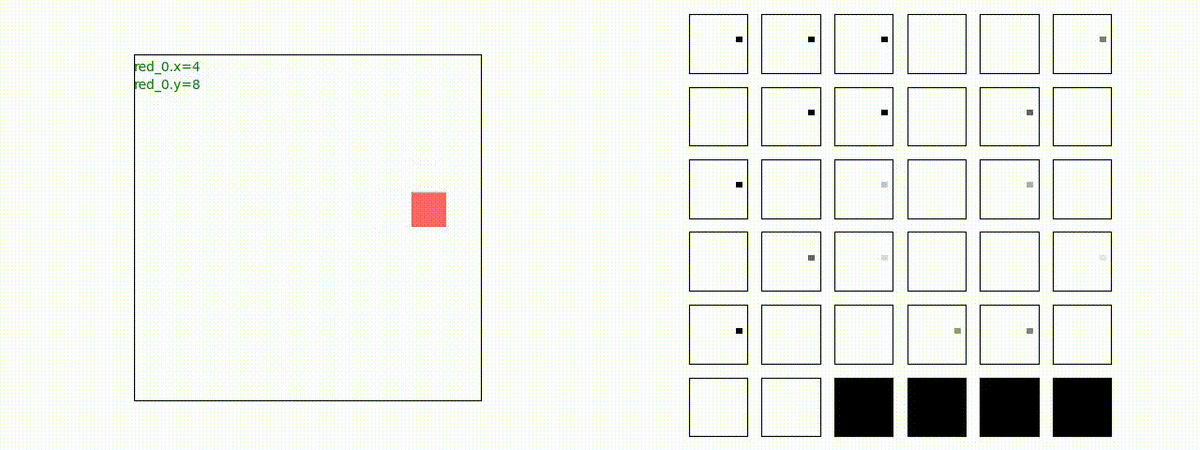
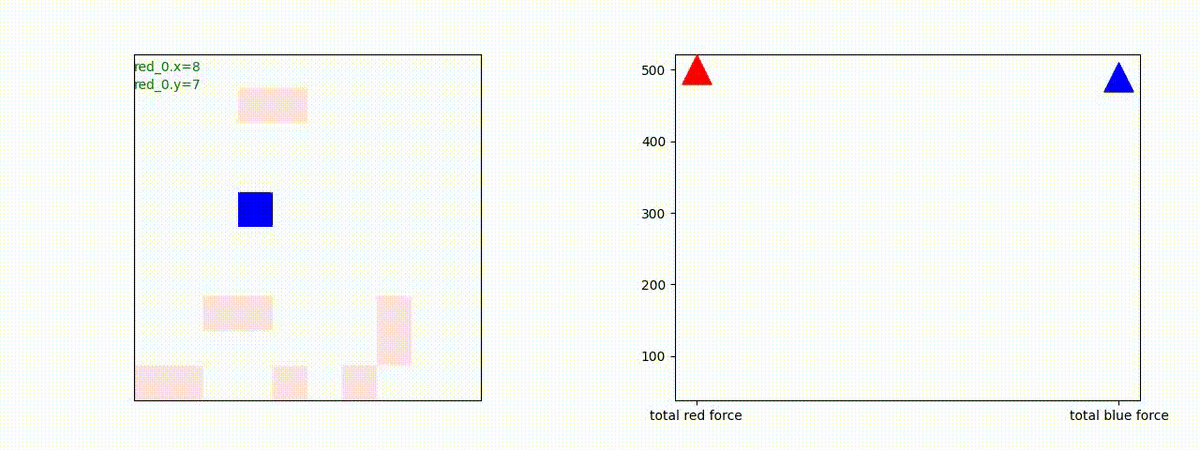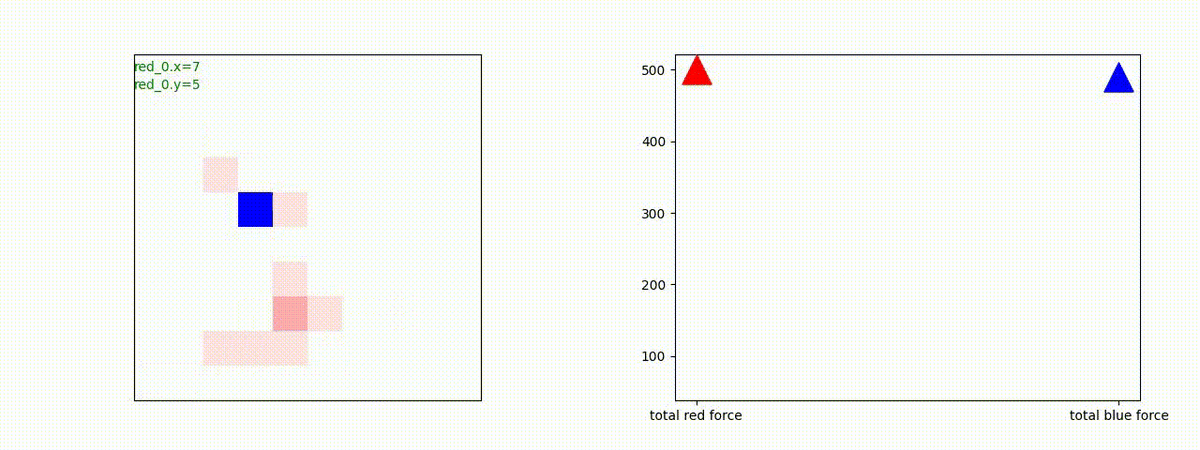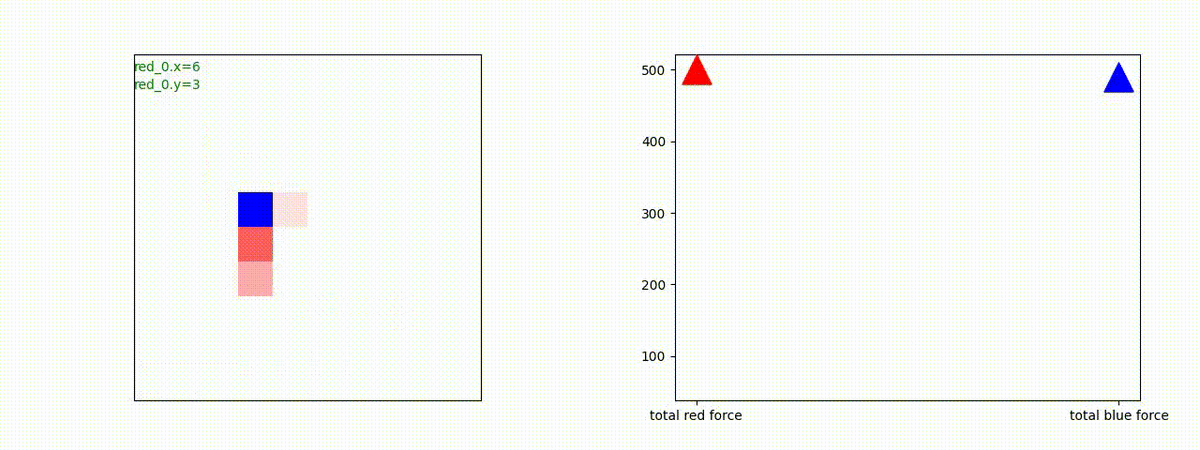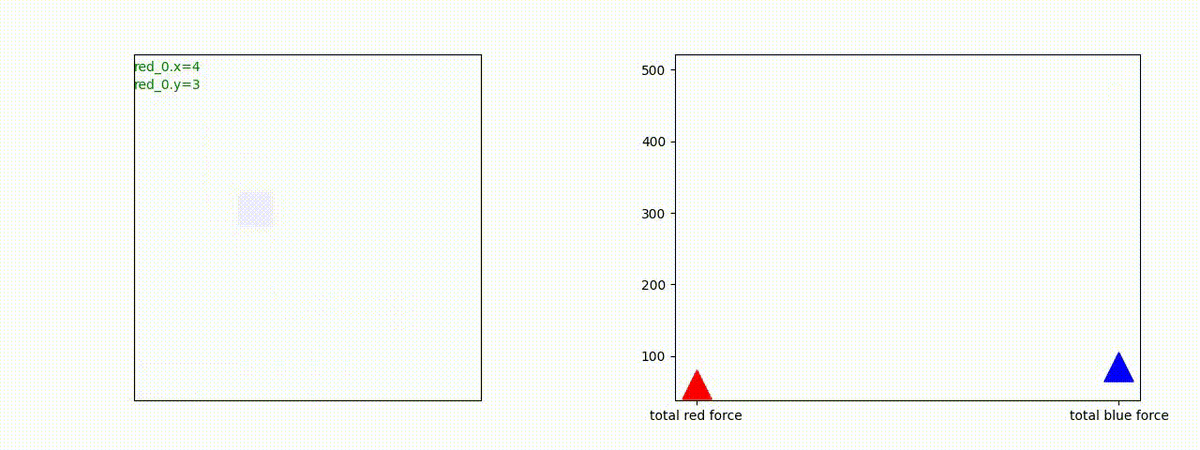
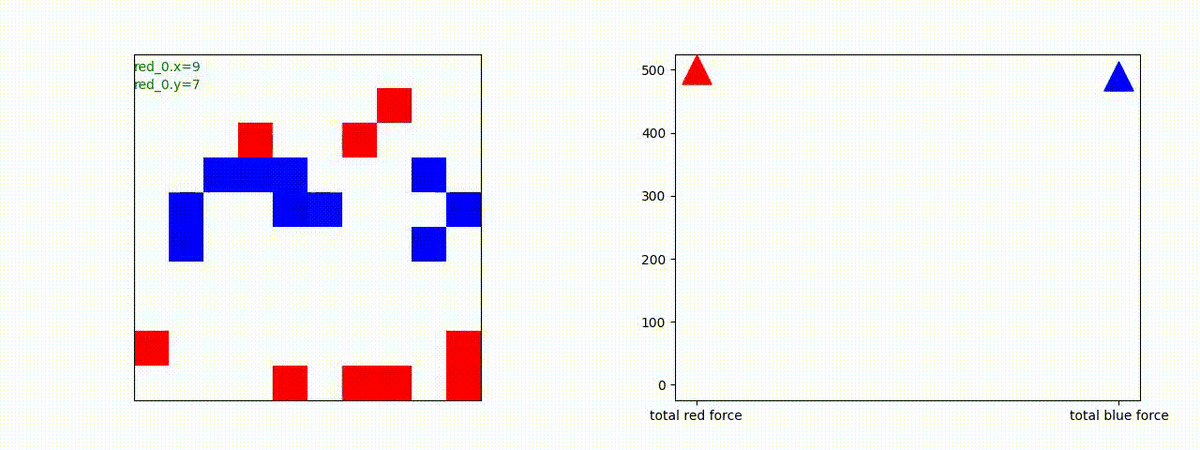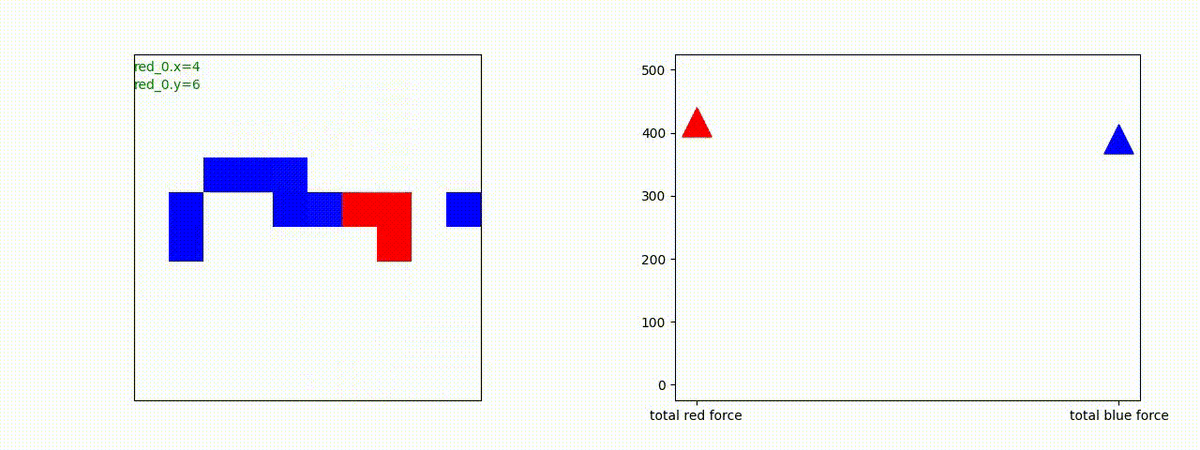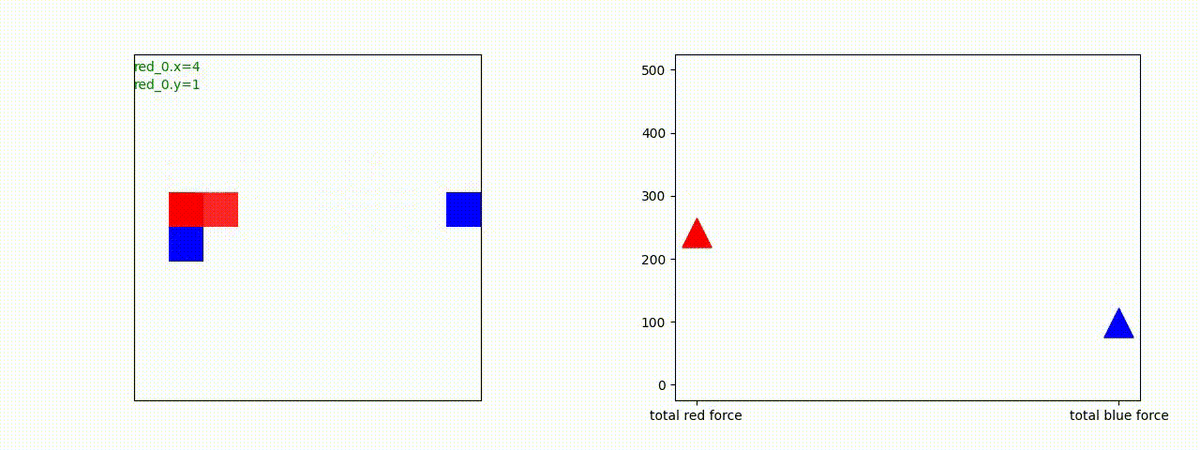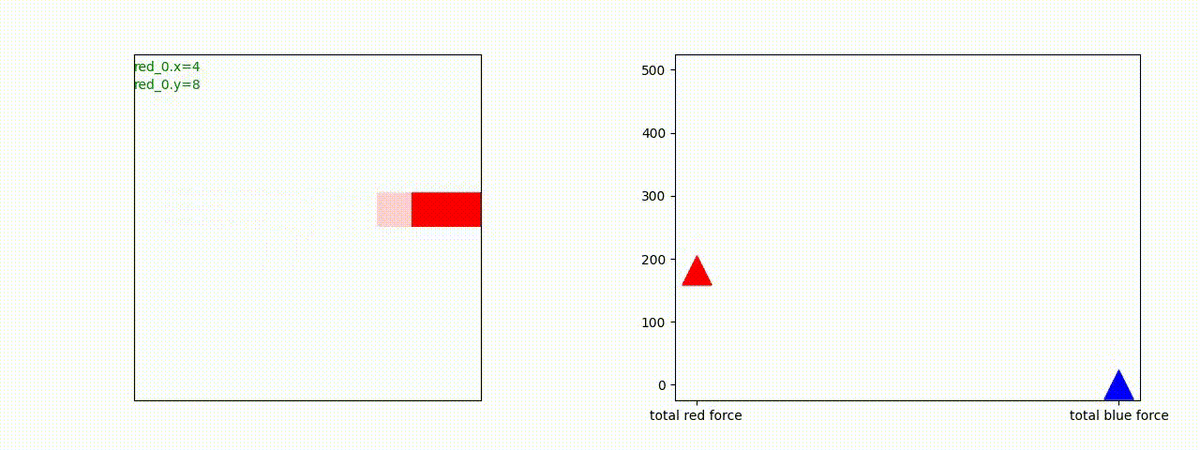
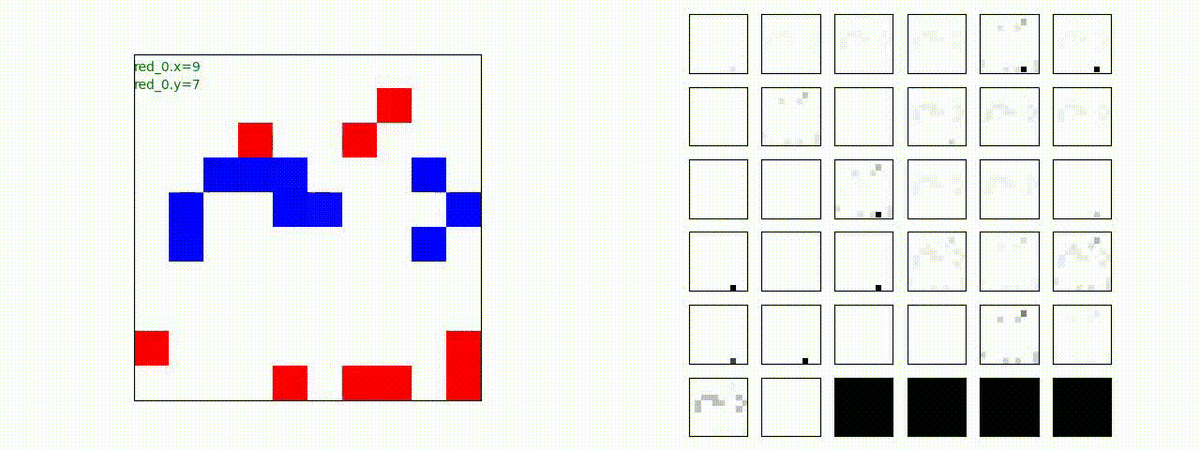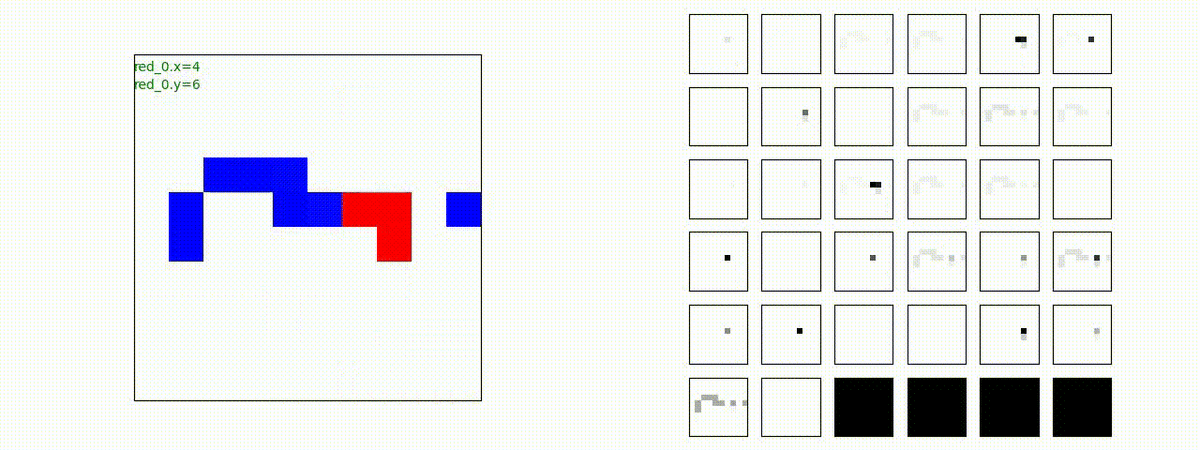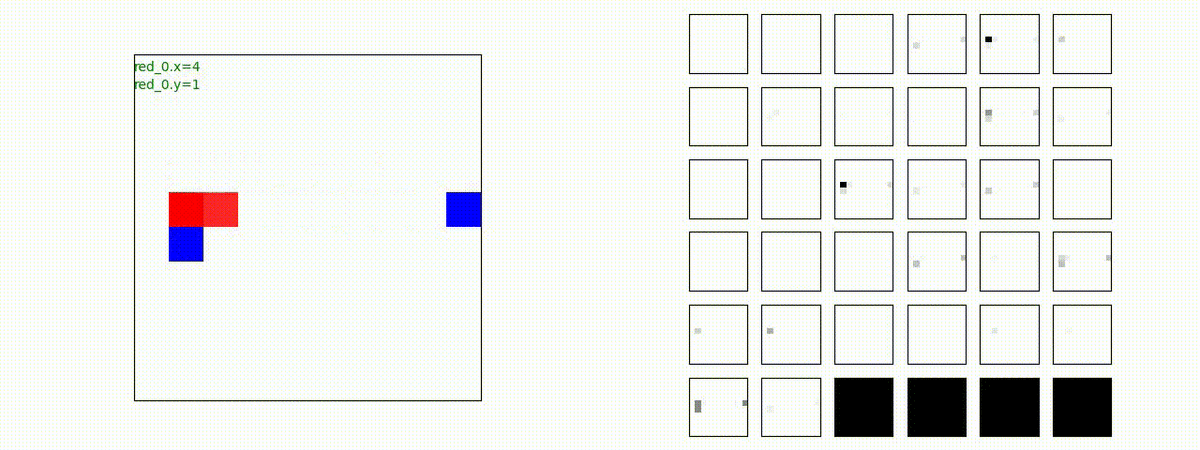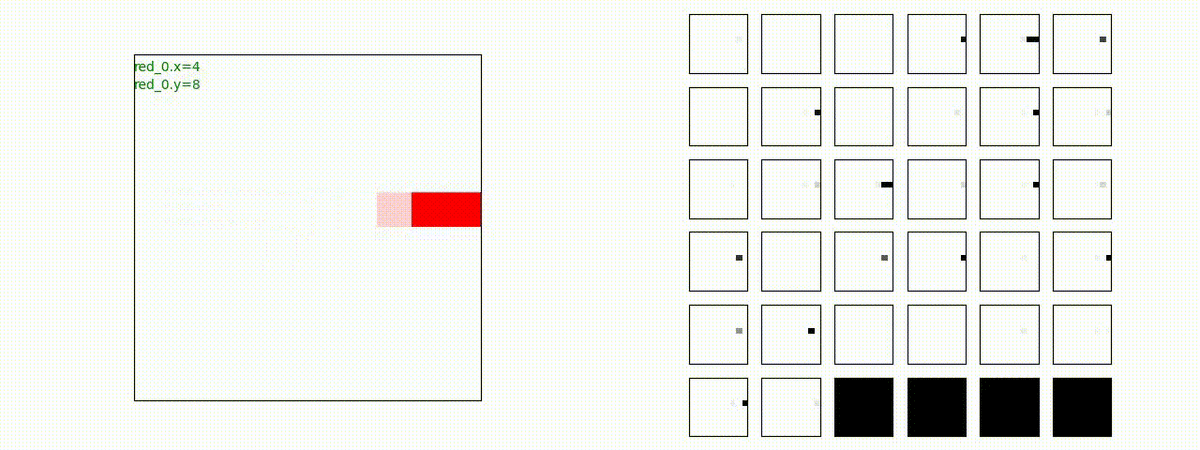
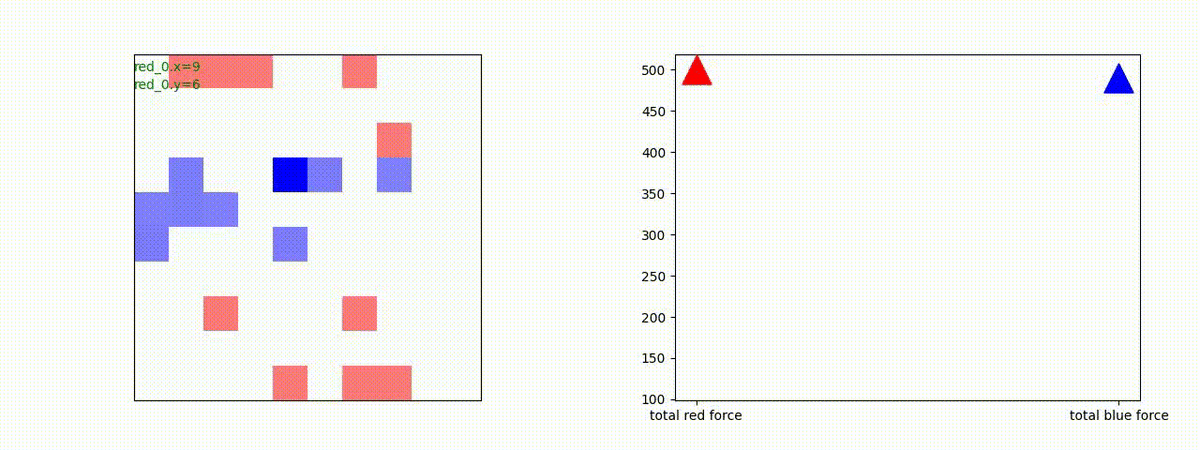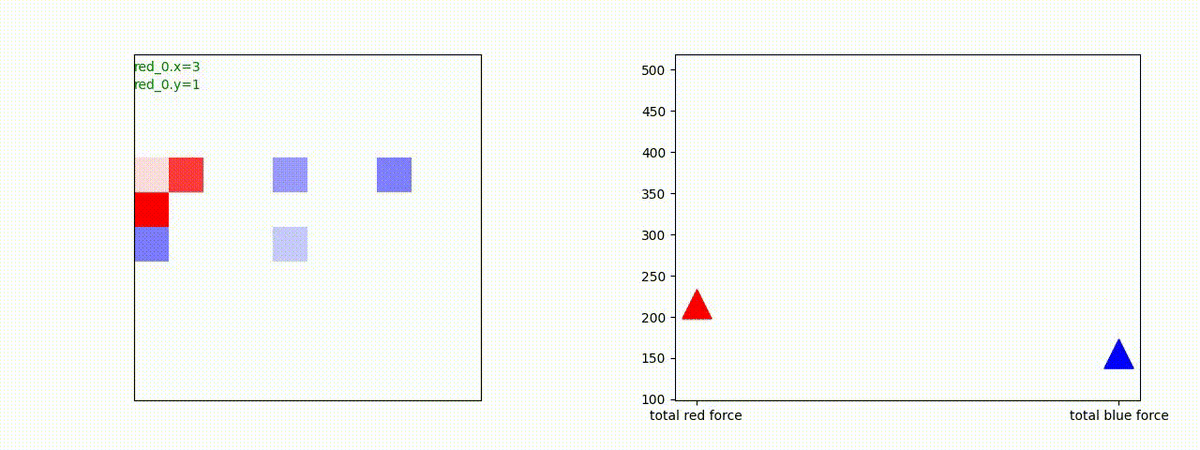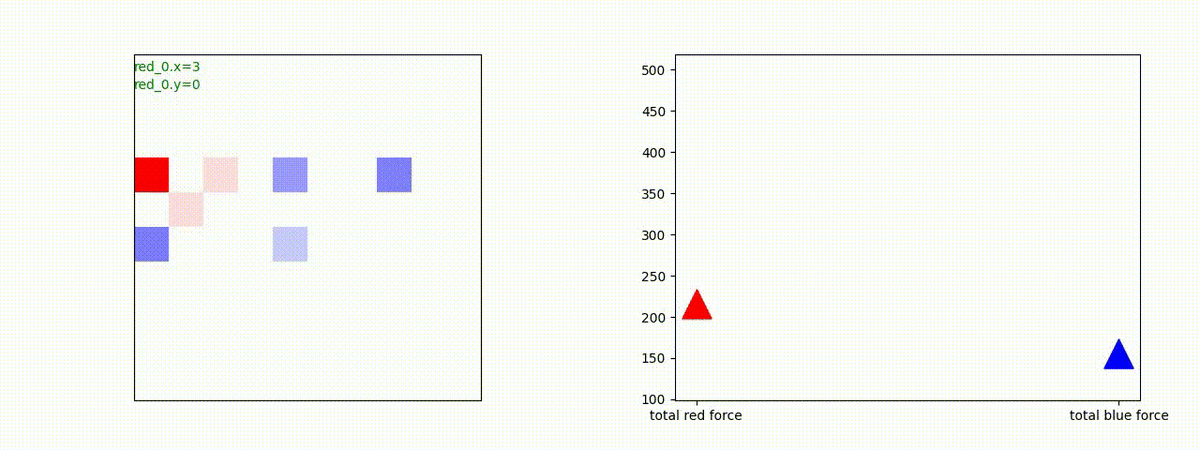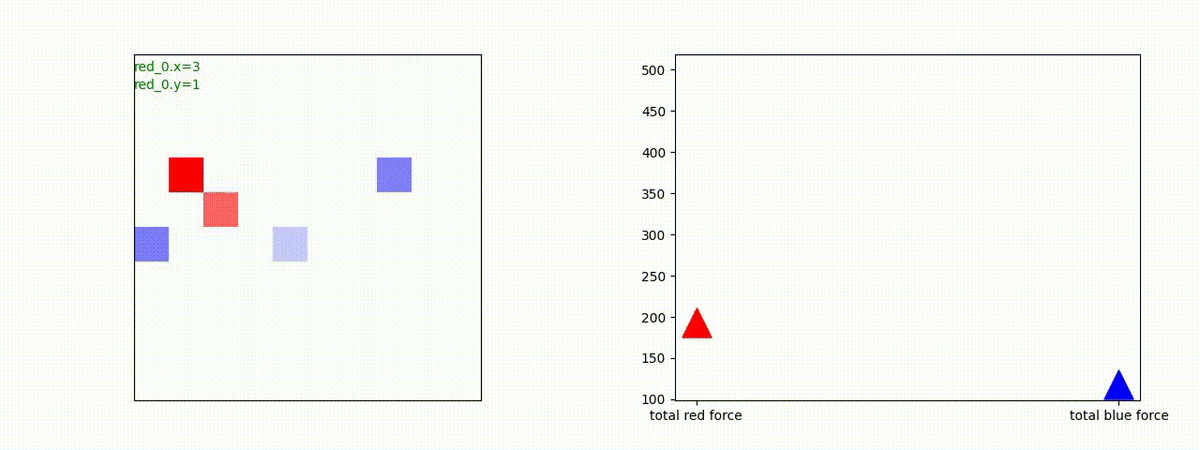
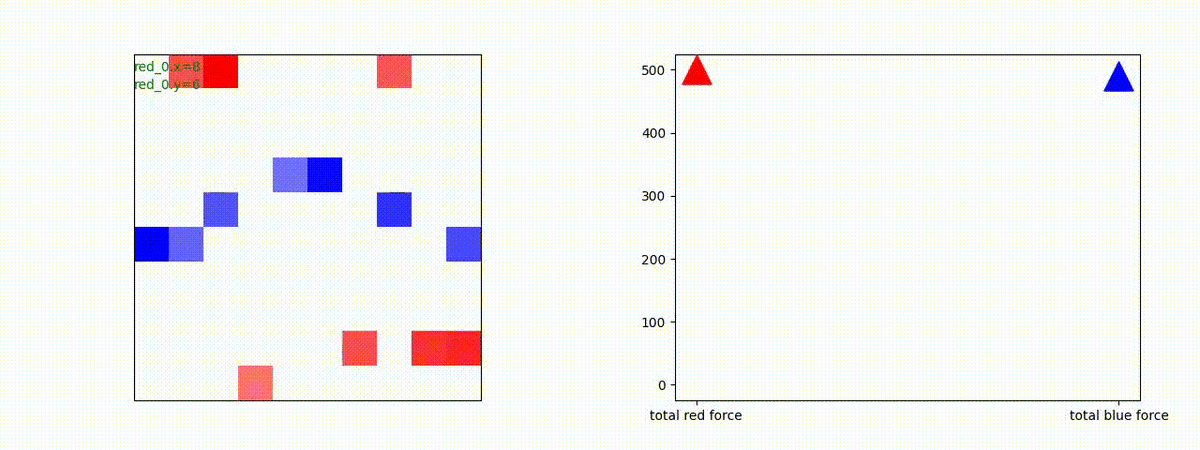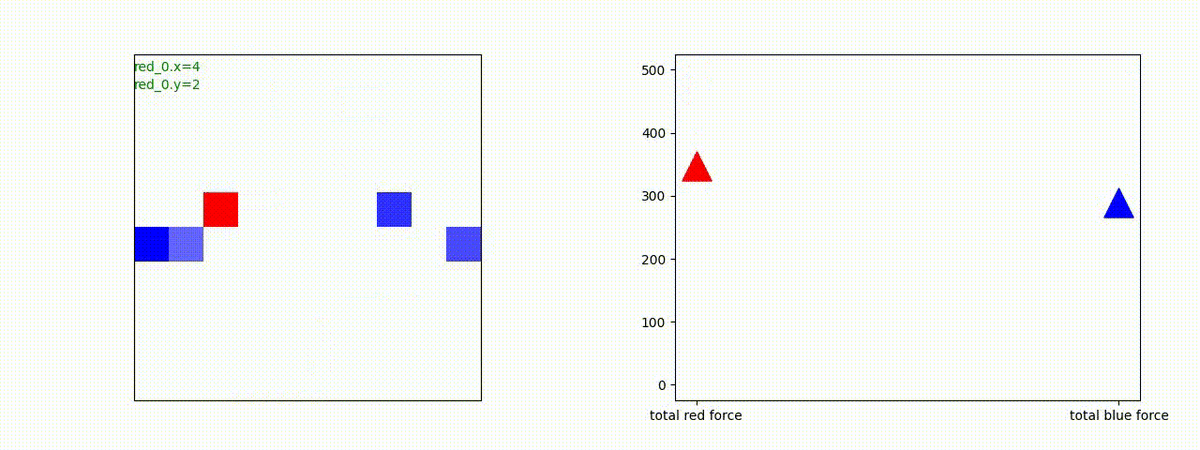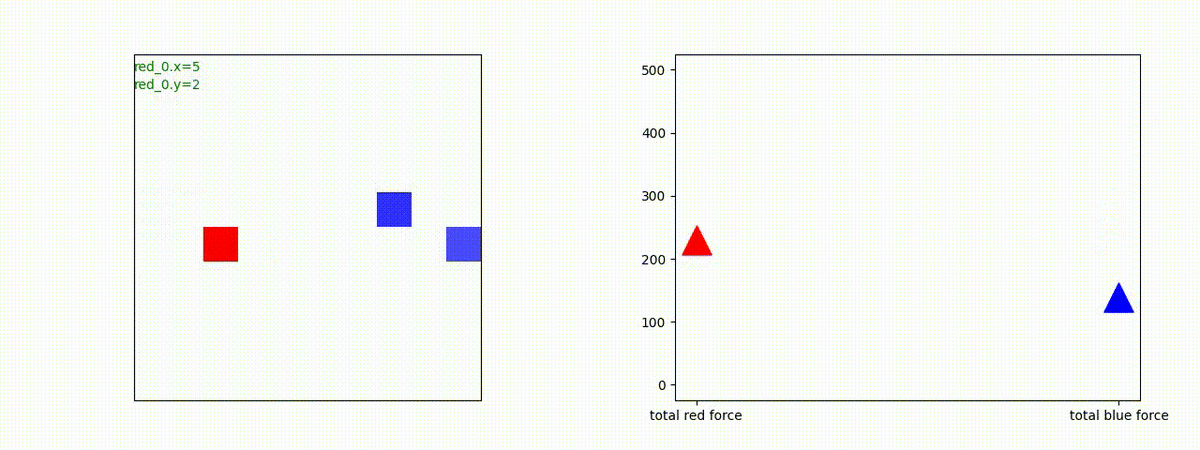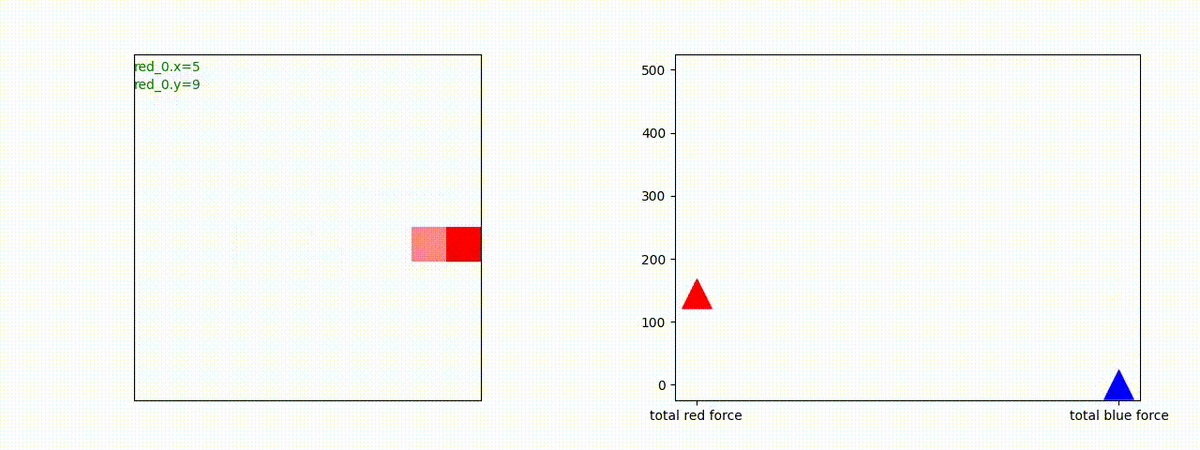
下図(左)は、戦闘状況を示します。赤い正方形が Red team のエージェント(群)、青い正方形が Blue team のエージェント(群)を示します。画面左上の座標値は、red team の0番目のエージェント( "red_0" と呼称)の位置を示します。また、色の濃さが戦闘力(Force)の大きさを表し、色が濃いほど大きな戦闘力であることを示します。したがって、戦闘が進むに連れ、戦闘力は消耗して色が薄くなってゆきます。また、同一グリッドに Red team と Blue team が混在する場合は、チームの戦闘力の差を表していますので、色が薄いほど拮抗した戦闘がそのグリッドで行われていることになります。戦闘が進んだ時に色が濃くなるのは、それだけその色のチームの戦闘力が相対的に優位になったことを表しています。
下図(右)の赤、青三角は、夫々 Red team, Blue team の残存戦闘力(群の構成メンバー数)を示します。
Red teamの各エージェントは、勝率 100% ですが、完全に一つの塊となって 'mass' 重視の戦闘をする訳ではありませんでした。ここは、もう少しトレーニングを継続すると改善するのかもしれません。(やっていないので分かりません)。
Red team = 8 swarms vs Blue team = 7 swarms
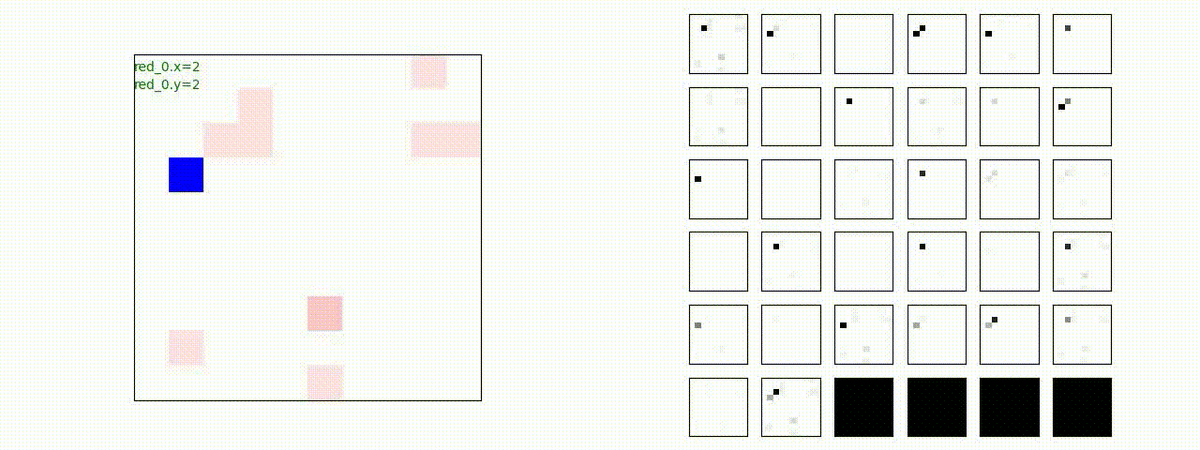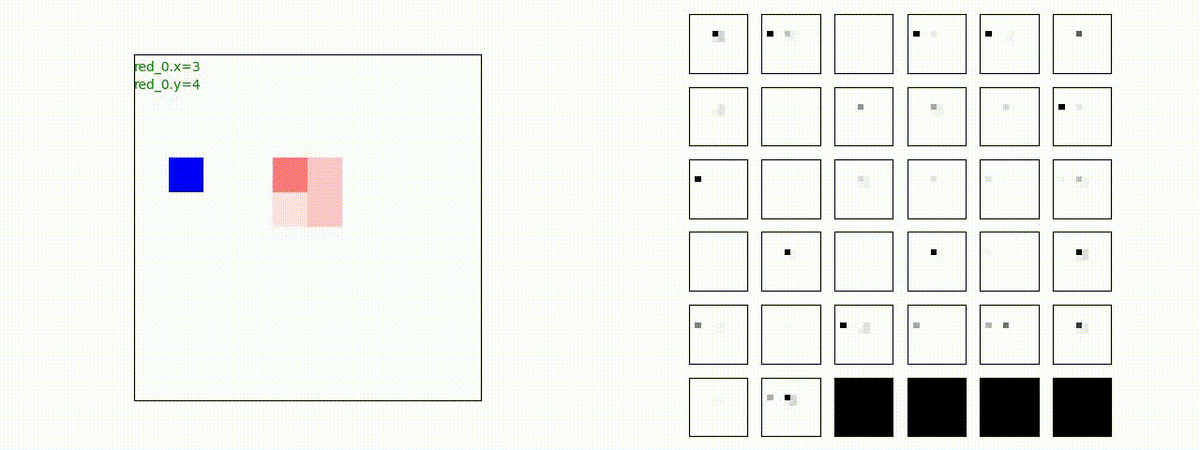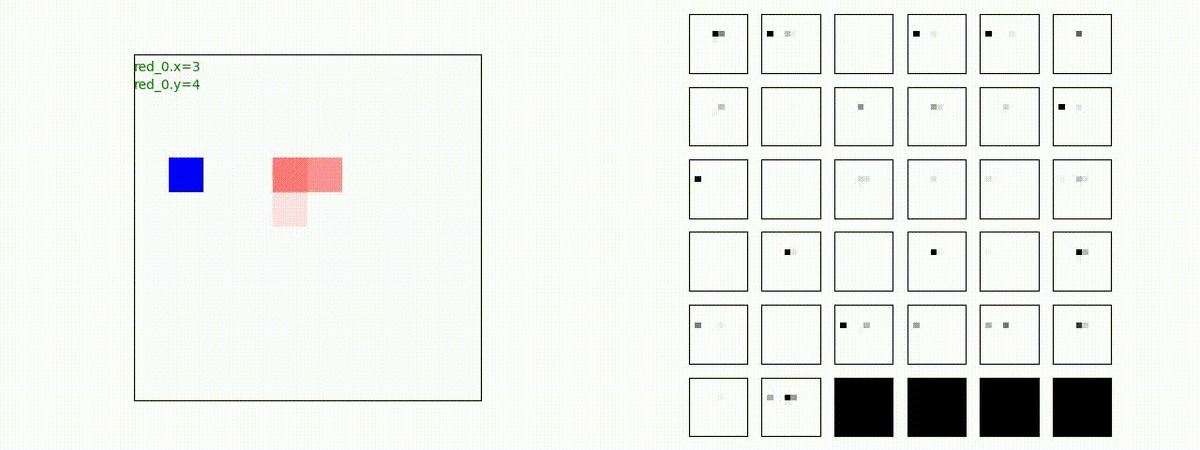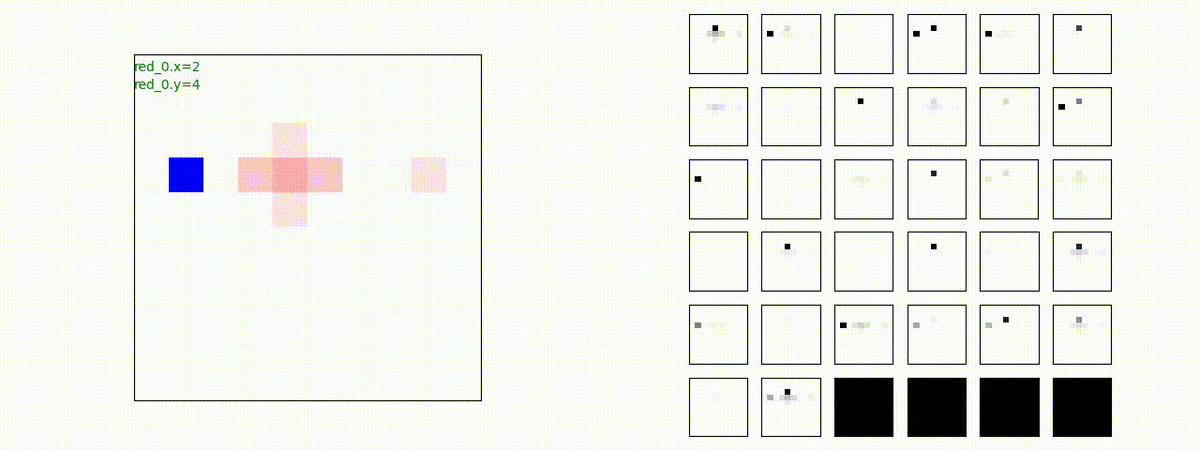
下図(左)も(その3)と同様に、各エージェントが、認知系(DenseNet)に入力するために 1x1 Conv を使って新たに生成した32枚のマップを示しています。どういったマップを生成しているのか把握するのは結構大変そうなのでやりませんでした。
別の例を示します。やはり、完全に一つの塊となって 'mass' 重視の戦闘をする訳ではありません。他の例も調べたのですが、同様の結果でした。
ロバスト性(汎化能力)
ここでは、エージェント数を Red team = [1, 10], Blue team = [1, 9] の範囲で振ってみて、トレーニング時には全く未経験の戦況にどこまで対応できるのか測って見ました。(トレーニング時のエージェント数は Red team = [7, 8], Blue team = [6, 7] です)。
初期エージェント数が Red team = [1, 6], Blue team = [1, 5] のようなケースでは、初期マップはトレーニング時に見たことが無いような、エージェントが少ない疎なマップになります。
しかしながらこれと類似したエージェント数のマップは、戦闘が進んで、初期兵力が消耗すると現れてくるはずです。もちろん兵力(Force)が異なるのでマップとして同じわけではありませんが、多少のロバスト性(汎化能力)は期待できるのではないかと当初は考えました。(結果は、そうはなりませんでした)。
一方、初期エージェント数が Red team = [9, 19], Blue team = [8, 9] のケースでは、初期マップがトレーニング時よりも密になりますが、「少数群 vs 少数群」の時の経験から、これくらいの違いであればロバスト性(汎化能力)が期待できます。
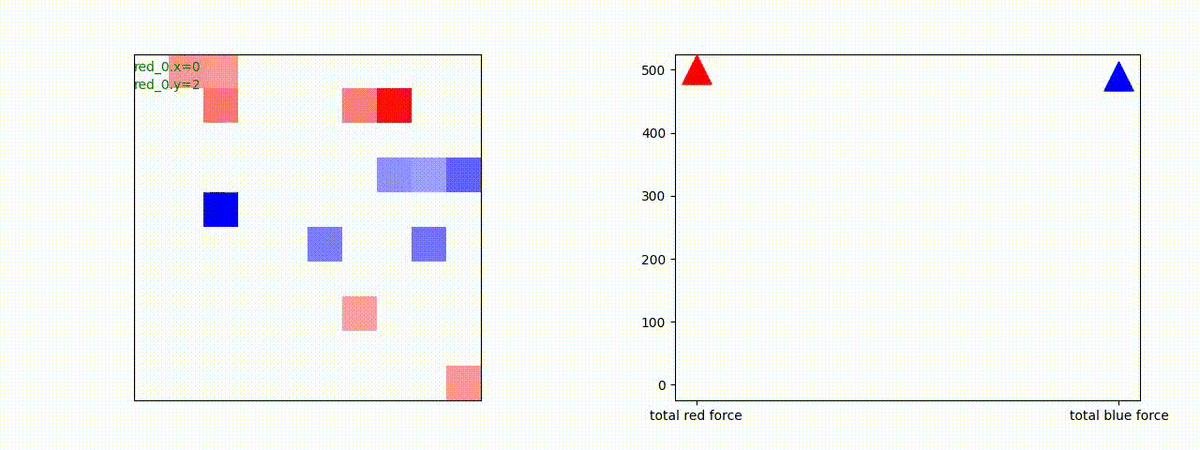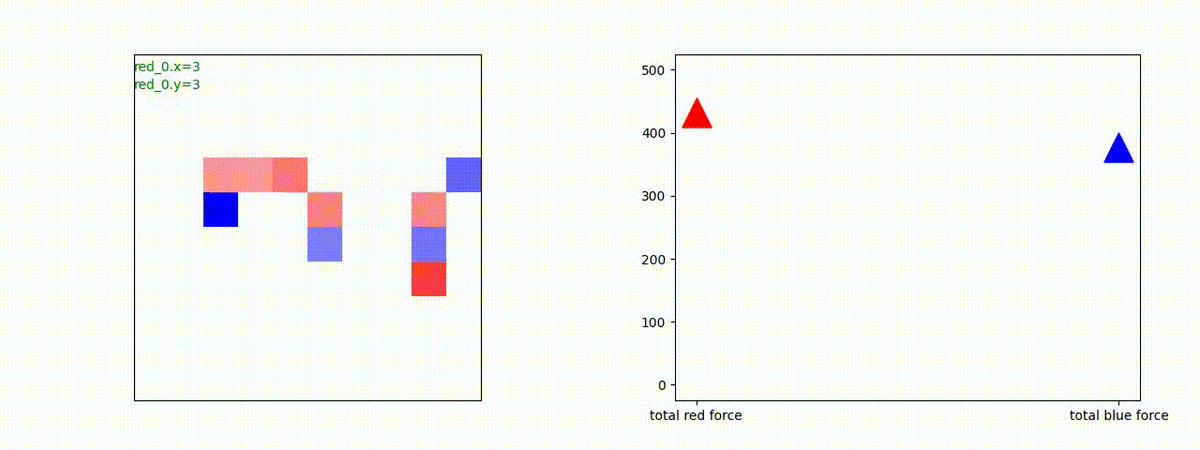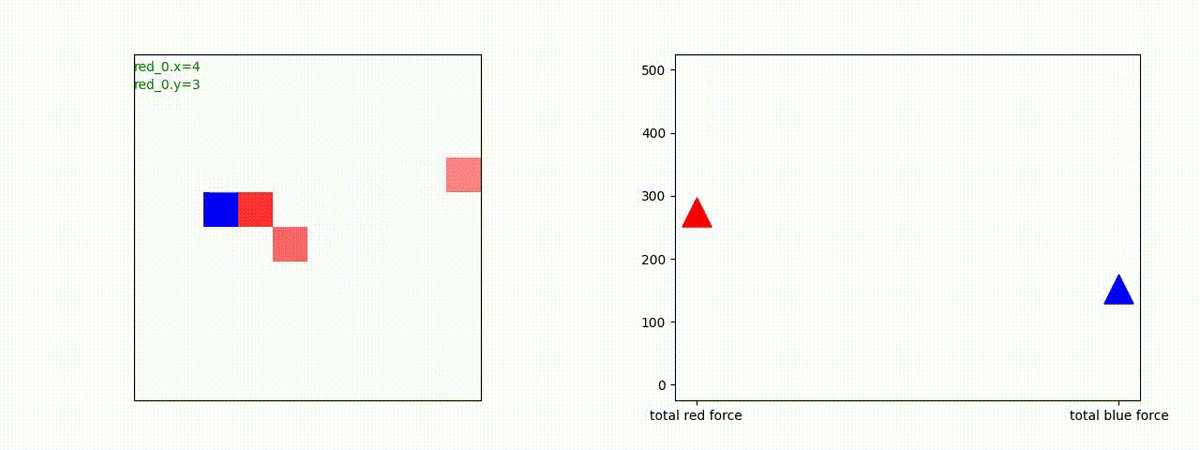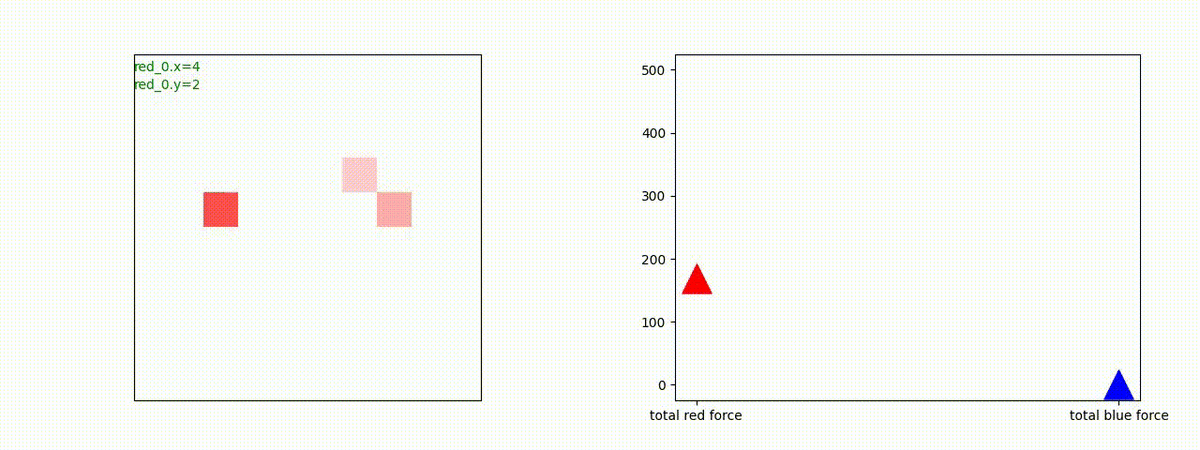
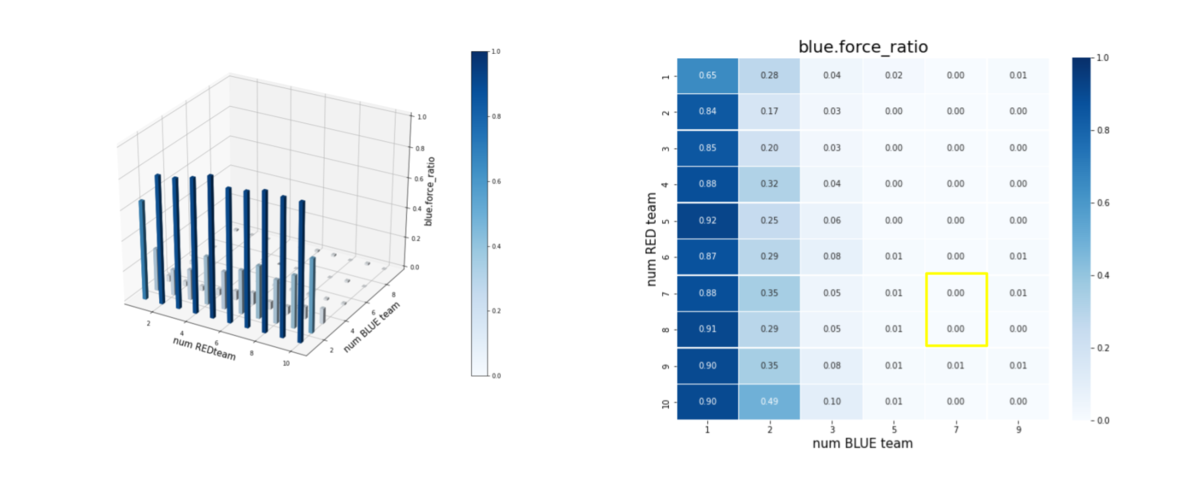
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。
num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸 blue_force_ratioは、
blue_force_ratio = Blue team残存兵力/Blue team初期兵力
を表します。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。トレーニング時のエージェント数は、red_team = [7, 8], blue team = [6. 7] ですが、Blue_team = {1,2,3,5,7,9} でやっているので、図のような長方形の黄枠になっています。いずれにせよ、黄色から外れるほど、トレーニング時に見たことがない戦闘環境になります。
これから、以下を読み取ることが出来ます。
- Blue teamのエージェント数が、トレーニング時の1/2である3程度までは、そこそこ上手く戦える。
- Blue teamのエージェント数が、トレーニング時の1/2以下である1や2になるとうまく戦えない。
- Blue team, Red team のエージェント数が多少増えても、問題なく対処できる。
この時の red teamの残存兵力は下図になります。red_force_ratio は以下で定義しています。
red_force_ratio = Red team残存兵力/Red team初期兵力
Blue teamのエージェント数が少ない場合、red teamの残存兵力も大きくなっています。したがって、このトレーニング方法では、強大な兵力の群に、小分けの群で戦う汎化能力は十分ではないことが分かります。
以上のことは、残存兵力ではなく、残存エージェント数(群数)からも読み取ることが出来ます。blue_alive_ratio は以下で定義しています。
blue_alive_ratio = Blue team残存エージェント数/Blue team初期エージェント数
= Blue team残存群数/Blue team初期群数
Red team については、下図になります。red_alive_ratio は以下で定義しました。
red_alive_ratio = Red team残存エージェント数/Red team初期エージェント数
= Red team残存群数/Red team初期群数
上記をもう少し分析します。成功率、引き分け率を以下で定義することにします。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
draw = どちらの tem の残存兵力も0にならなかったエピソード数/全エピソード数
これらをバーグラフと heatmap にしたのが下図です。
Blue teamが少数の巨大な群になると成功率が急激に下がり、引き分け率が急激に増加します。失敗率が下がるのではなく、引き分け率が増加するので、Red team のエージェントは、「戦いもせずにウロウロしているだけ」、といった状態になります。
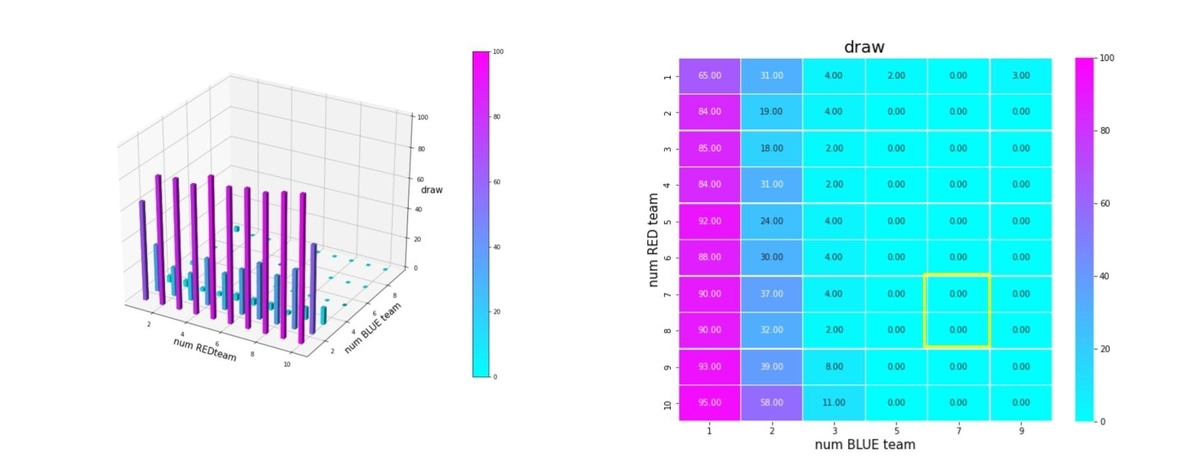
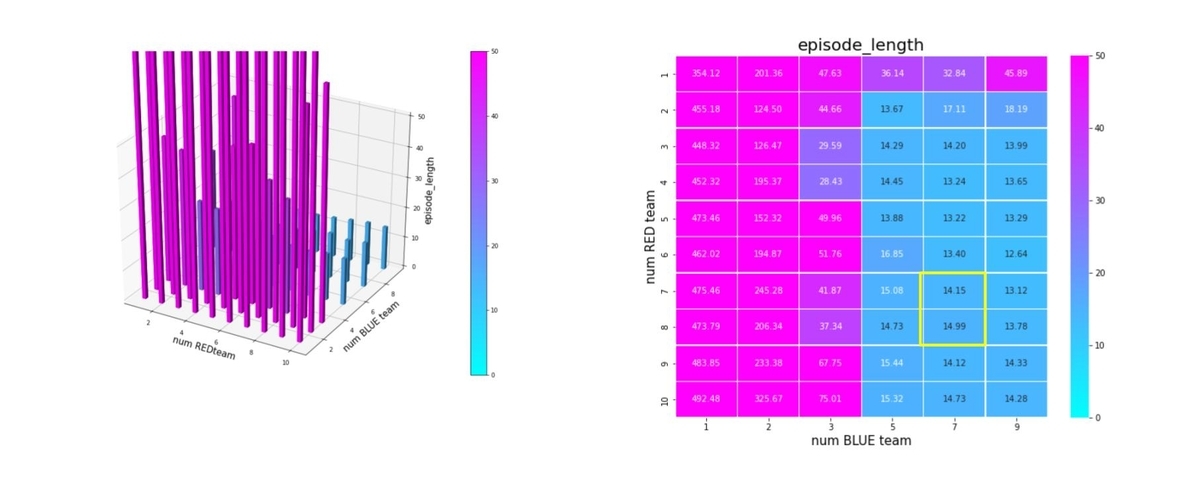
エピソード長で見てみます。戦場サイズが 10x10 なので、上手く戦っていれば平均10~20ぐらいのエピソード長で戦闘は終了するはずです。
Blue teamが少数の巨大な群になると、エピソード長は急激に長くなり、エージェントが戦おうとせずに右往左往しているのが分かります
生成された戦術例
Red team = 1 swarm vs Blue team = 1swarm
Blue team が少数群の初期状態の場合、やはり、red team は上手く戦えません。
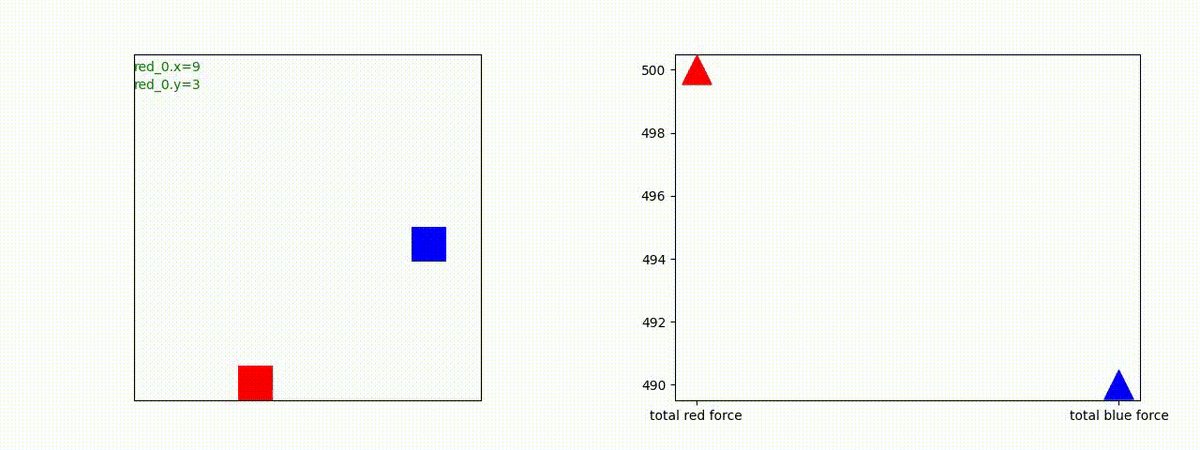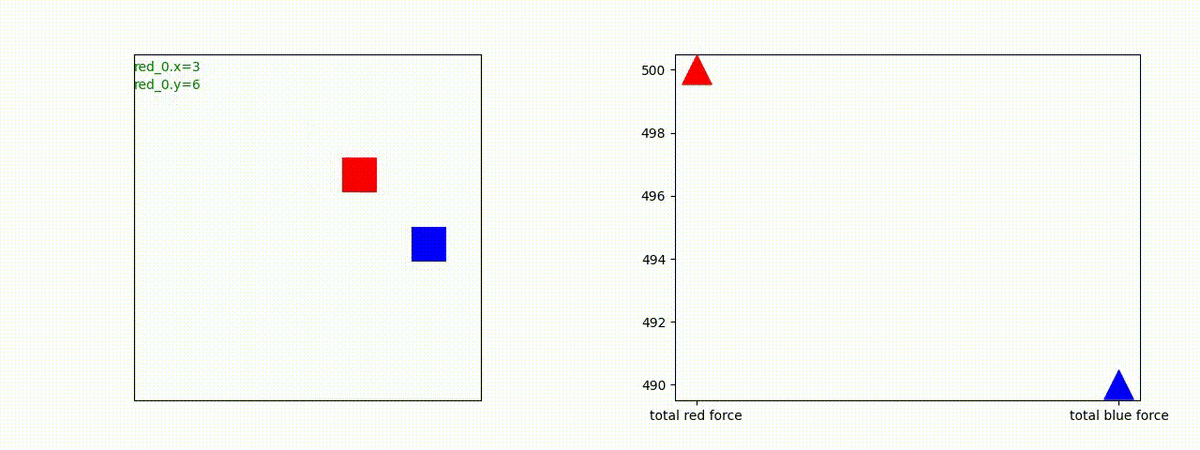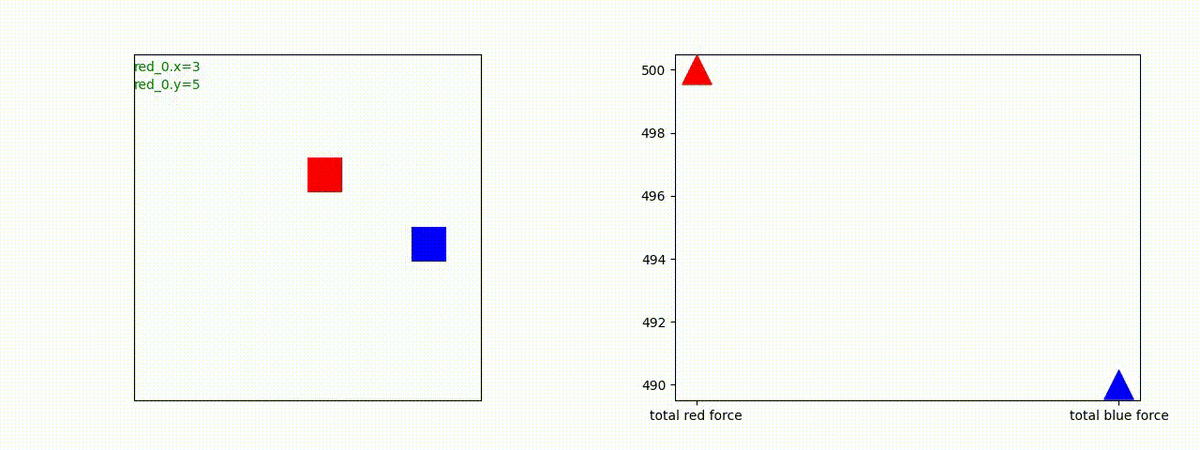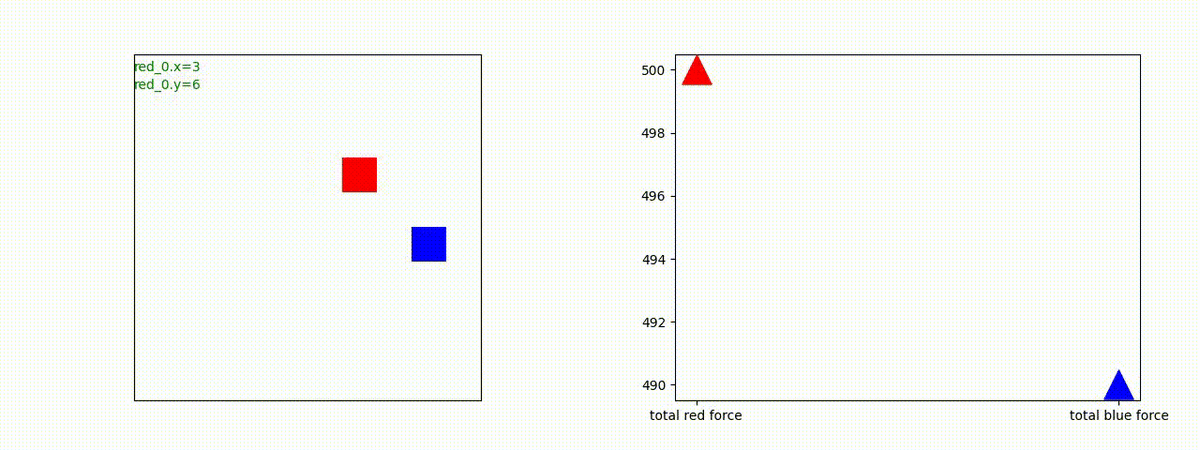
Red team = 10 swarms vs Blue team = 1 swarm
Red team = 1 swarm vs Blue team = 10 swarms
Blue team が多数群に分割されていれば、問題なく戦える戦術が生成されます。
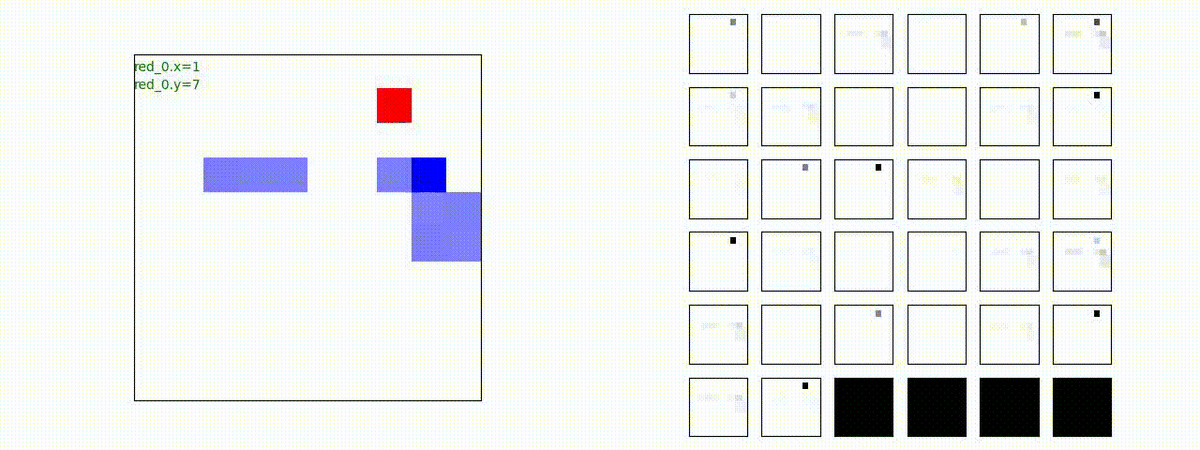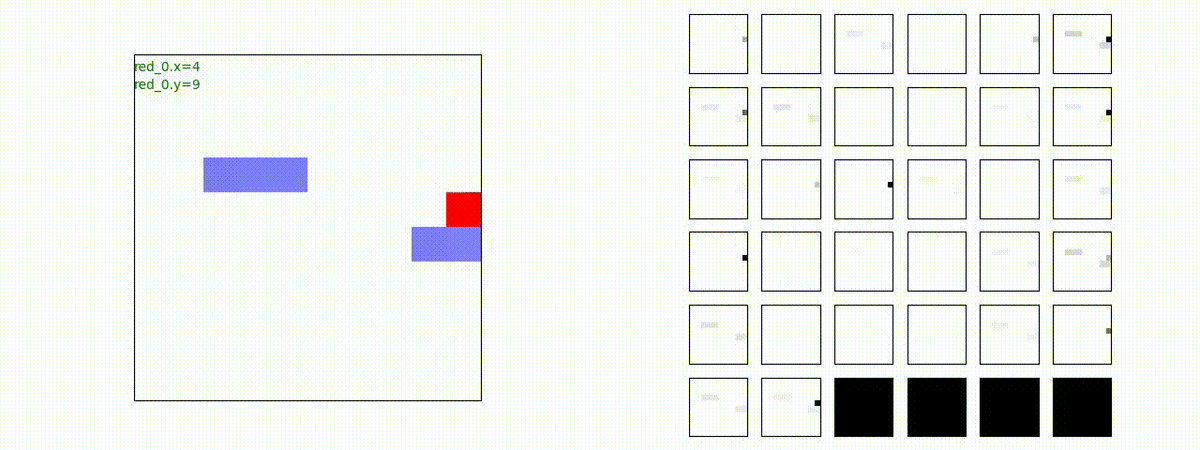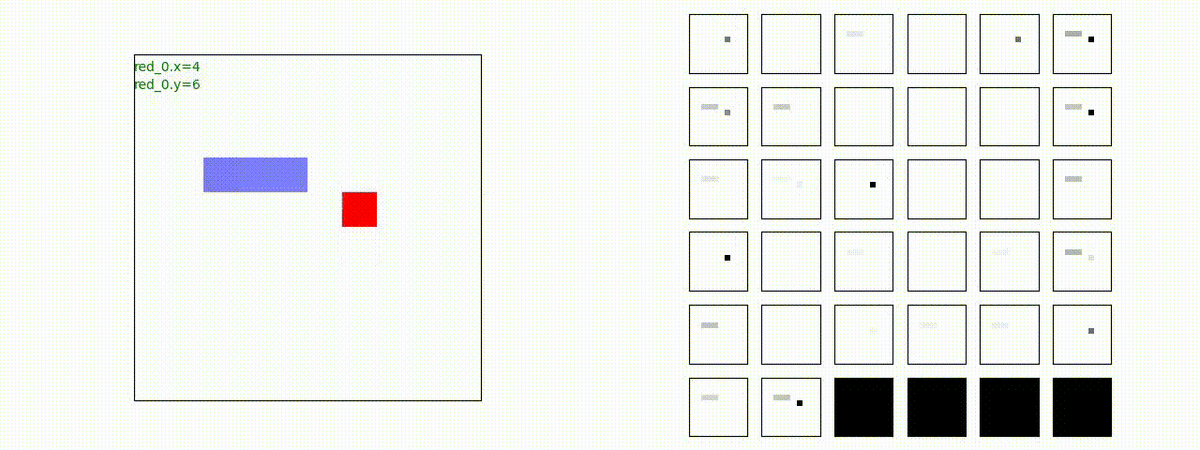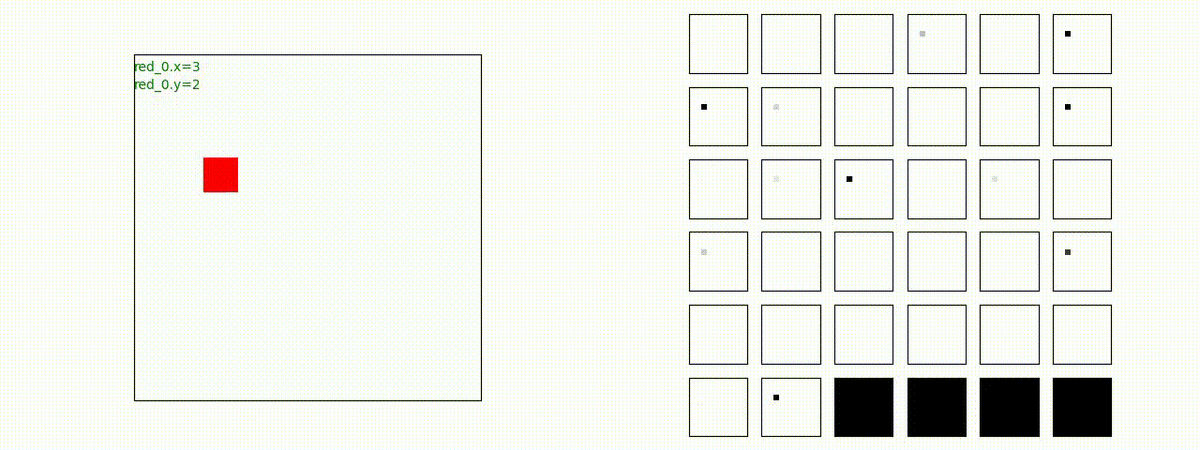
Red team = 3 swarms vs Blue team = 3 swarms
トレーニング条件の半分ぐらいの群数への外挿に対しては、問題なく戦える戦術が生成できます。
Red team = 5 swarms vs Blue team = 5 swarms
完全に一丸とまでは行っていませんが、うまく戦う戦術を生成したいます。
少数群vs少数群で訓練した結果との比較、及び将来の発展性
少数群vs少数群で訓練した結果と比較してみます。
Blue team の残存兵力で見ると、少数群vs少数群で訓練した Red teamに対しては下図でした。
一方、多数群vs多数群で訓練したRed teamの場合、Blue teamの残存兵力は下図でした。
これらから、敵を殲滅する平均的な汎化能力は、この範囲であれば、少数群 vs 少数群で訓練したteamのほうがやや優れていると言えます。これは、特に、強力な相手に、小分けになった多数の群で当たるには、
- 多数の群が一丸となって攻撃する、
- 多数の群のタイミングを合わせる、
必要があるのですが、彼我ともに多数群の初期条件だけでトレーニングした場合は、これが学習しきれないためと思われます。
ただ、少数群vs少数群で訓練したteamの方が平均的な汎化能力が優れていると言っても、あくまで比較の問題です。平均エピソード長を比較してみると、少数群 vs 少数群で訓練したRed teamに対しては、
多数群vs多数群で訓練したRed teamに対しては、
となっていますので、訓練時の環境から離れると右往左往するのは間違いありません。
纏めて言うと、トレーニング時の条件の倍や1/2倍程度のエージェント数までの外挿であれば対処できますが、それを超えた外挿になると厳しくなってくるようです。
結果を踏まえて発展性を考える
これらの結果から、以下のような方向への発展が考えられます。
少数群 vs 少数群で訓練したRed team のニューラルネットを「エキスパート1」、多数群 vs 多数群で訓練した Red team のニューラルネットを「エキスパート2」と呼ぶことにします。
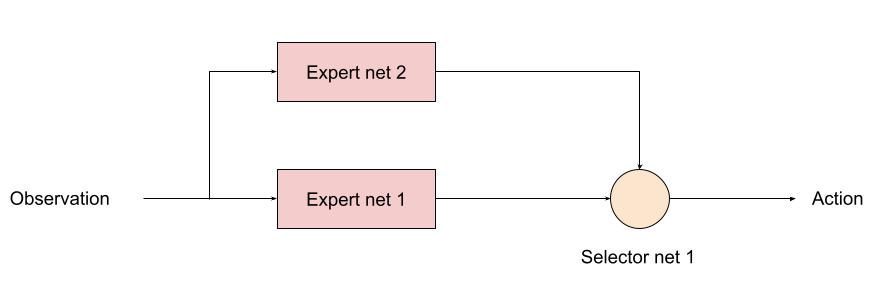
この時、下図のように、セレクタ・ニューラルネットを使って戦況に応じて、2つのエキスパートを切り替えて使う方法が考えられます。セレクタ・ニューラルネットの強化学習時には、既に学習させた2つのエキスパート・ニューラルネットは固定します(学習しないようにします)。
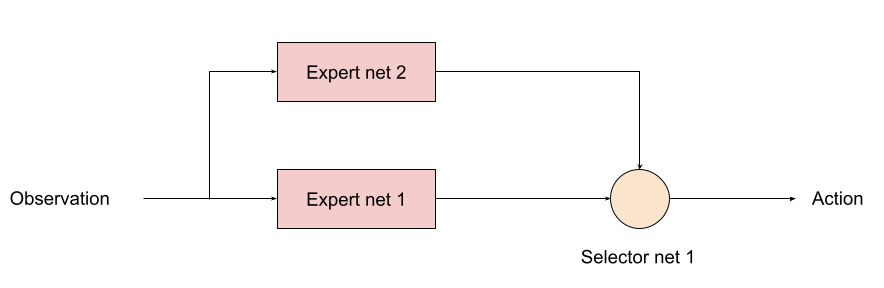
これを、もっと格好良く、まとめてやってしまう階層型強化学習(Hirerarchical reinforcement learning、下記に参考文献を示しました)という世界もあるのですが、本件ぐらいのアプリケーションであれば、セレクタ型で対応できる気がします。
[1609.05140] The Option-Critic Architecture
[1710.09767] Meta Learning Shared Hierarchies
[1703.01161] FeUdal Networks for Hierarchical Reinforcement Learning
[1811.11711] Neural probabilistic motor primitives for humanoid control
[1805.08296] Data-Efficient Hierarchical Reinforcement Learning
また、工業製品の観点から見ると、エキスパートが増えた場合に、セレクタ型であれば、もう一度学習をやり直すのではなく、下図に示す Subsumption architecture のように、既存の固定したネットワークに順次エキスパートとセレクタを追加していくことが出来るはずなので非常に便利だと思われます。(コーディングもずっと楽です)。
これについては、ひと段落したらやって見ようと思います。
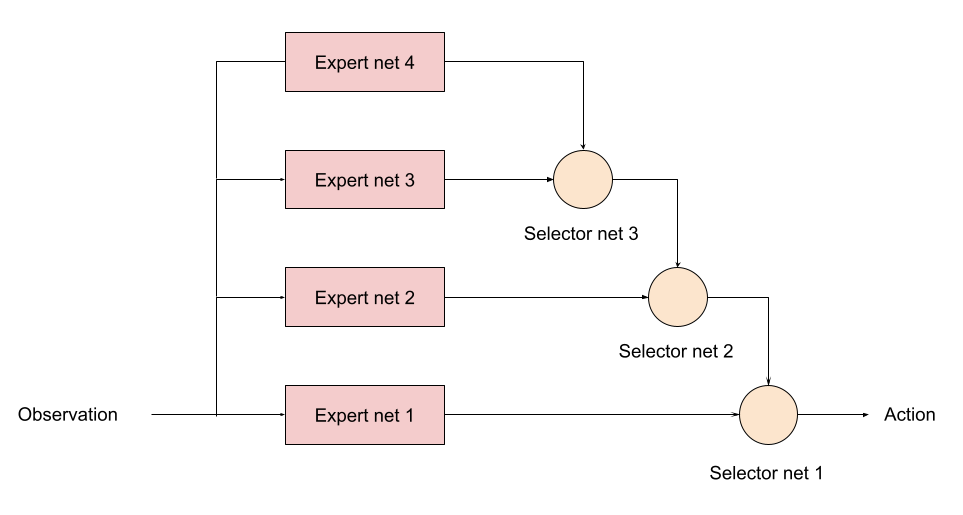
まとめ
- Red team の初期エージェント数(群数)を [7, 8]、Blue team の初期エージェント数(群数)を [6, 7] として、多数群 vs 多数群の設定でネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、完璧ではありませんが、"mass" を構成して戦う戦術を学習でき、上手く戦況をハンドリングできている(ほとんどいつも Blue team を殲滅できる)ことが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を外挿方向に減らして(つまり、戦力の大きな少数群にして)戦闘性能がどの程度劣化するのか見てみました。
- (その3)、(その4)の結果から、将来の研究の方向性として Subsumption architecture likeなアーキテクチャを提案しました。(提案だけで、未実施です)。
過去2回の実験は、少数群 vs 少数群、或いは多数群 vs 多数群といった比較的ダイナミックレンジが狭い群数でトレーニングしました。この結果、「少数群 vs 少数群」用エキスパート、或いは「多数群 vs 多数群」用エキスパートのようなマルチエージェント・システムがトレーニング出来ました。
では、Red team, Blue teamのトレーニングに使用する群の数のダイナミックレンジを増やした場合、性能はどうなるのでしょうか。これも興味があります。次回記事では、これを評価してみます。
マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その3):少数群 vs 少数群で訓練する
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
- はじめに、Red team の初期エージェント数(群数)を [1, 3]、Blue team の初期エージェント数(群数)を [1, 2] として、少数群 vs 少数群の設定でネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を増やして(つまり、戦力を小分けにして散開させて)戦闘性能がどの程度劣化するのか見てみます。
実行環境
- Google Cloud Platform (GCP) preemptive E2 12 vcpu で 24時間 x 2。DenseNet ベースの画像処理が結構大きいので、本当は gpu を使いたいのですが、preemptive では使わせてもらえないらしいので、cpu だけで頑張っています。
- 22 rollout workers(トレーニング対象となるRed teamエージェント数が最大3なので、多めに設定しました。この辺り、あまり根拠はないです。)
- CPU使用率 66% 程度だったので、もう少し少ない vcpu でいけると思いました。お金に余裕があれば、1 worker に 1 agent を割り当てると効率が良いはずです。
PPOハイパーパラメータ
- Learning rate: lr = 5e-5, Adam
- Discount factor: γ = 0.99
シミュレーション条件
各チームの初期エージェント数(群数):各エピソードの初めに、Red team のエージェント数(群数)を [1,3] から、Blue team のエージェント数(群数)を [1,2] から乱択します。
Initial Force(初期兵力):各エピソードの始めに、両チームともに、ランダムに Force をチームのエージェントに配分します。エージェントの Force の最小値は 50 とします。Red team の Initial Force の合計は 500、Blue team は 490 としました。したがって、Red team の最大エージェント数(群数)は 10、Blue team は 9 になります。また、エージェント数が増えるほど、ほぼ同じForceの群となっていきます。この辺りは、将来もう少し工夫したいと思っています。
Efficiency(武器性能):全エピソードで、両チームともに 0.6 で固定しました。この場合、1タイムステップにおける兵力の消耗が大きいので、'mass' の戦術を採るためには、敵がいるグリッドに一丸となって侵攻する「タイミング・コントロール」が非常に重要となります。私の経験では、タイミング・コントロールは、強化学習の苦手とするところなので、少しだけチャレンジングです。
兵力消滅判定条件:エージェントの force が消耗して、初期兵力の10% 以下になると、そのエージェントは消滅することとしました。Δtが小さい場合、Lanchester モデルの解は0に漸近します。このため、この仮定が無いと Force=0 にならないので、戦闘が永遠に続いてしまう場合がありますので注意が必要です。
エピソード終了条件:各エピソードにおいて、どちらかのチームのエージェントが全て消滅するか、シミュレーション・ステップが最大値(=100)に達した場合、そのエピソードは終了とします。
トレーニング履歴
以下のグラフの途中で色が変わっているのは、GCP の Preemptive vm が最大24時間でシャットダウンされてしまうので、シャットダウン後、継続学習を行っているためです。(お金が無いので、ケチっているだけです)。
下図で、縦軸はエピソード報酬、横軸が更新ステップです。安定して学習しているのが判ります。
下図は、平均エピソード長の履歴です。戦場サイズが 10x10 なので、平均エピソード長が12ぐらいになっていて、妥当ではないでしょうか。

下図は、学習後半のエピソード長の分布履歴です。
チーム報酬の分布は、双峰性になりました。これは、初期エージェント数により、得られる報酬が2通りあることを意味しています。ここは、もう少し解析すべきなのですが、先を急ぎたいので省略しました。
トレーニング時の評価結果
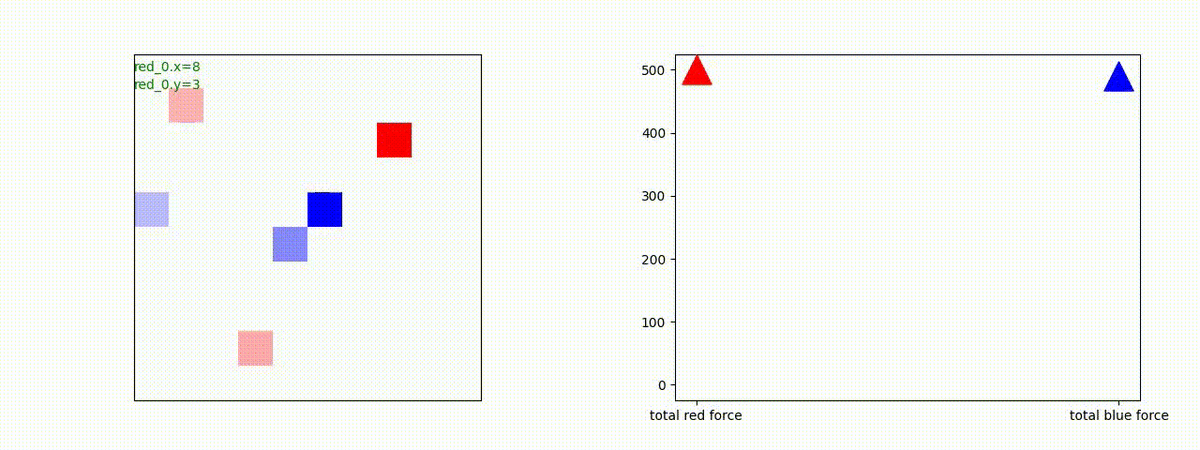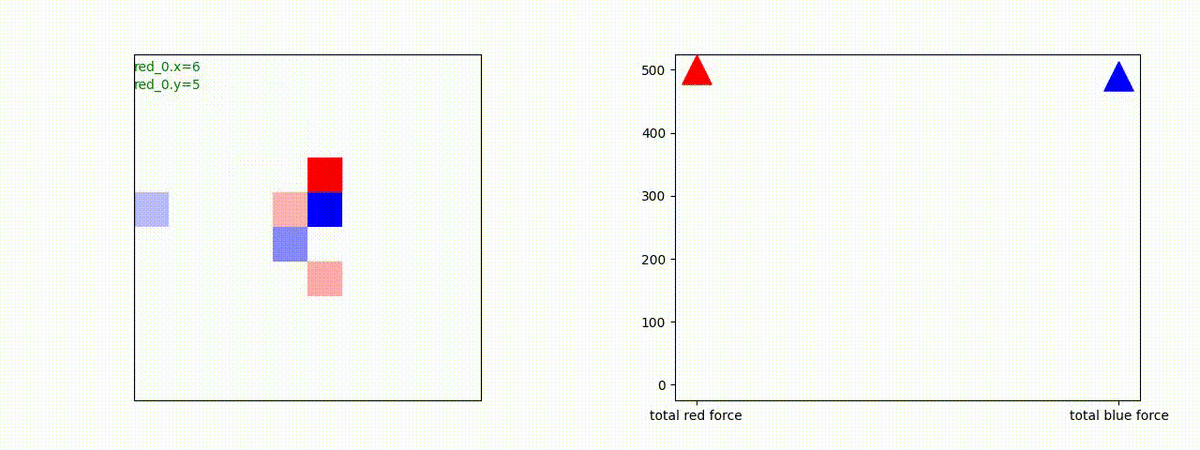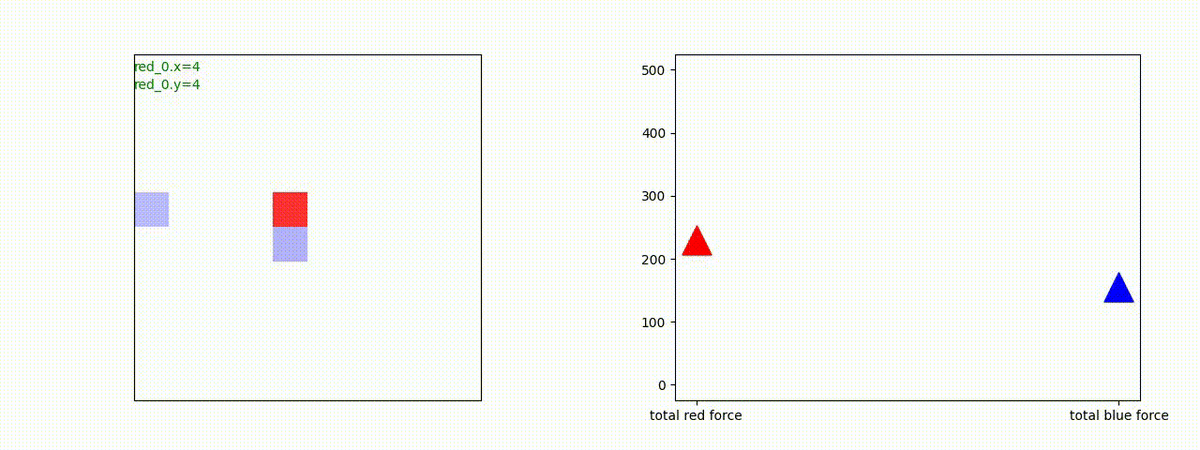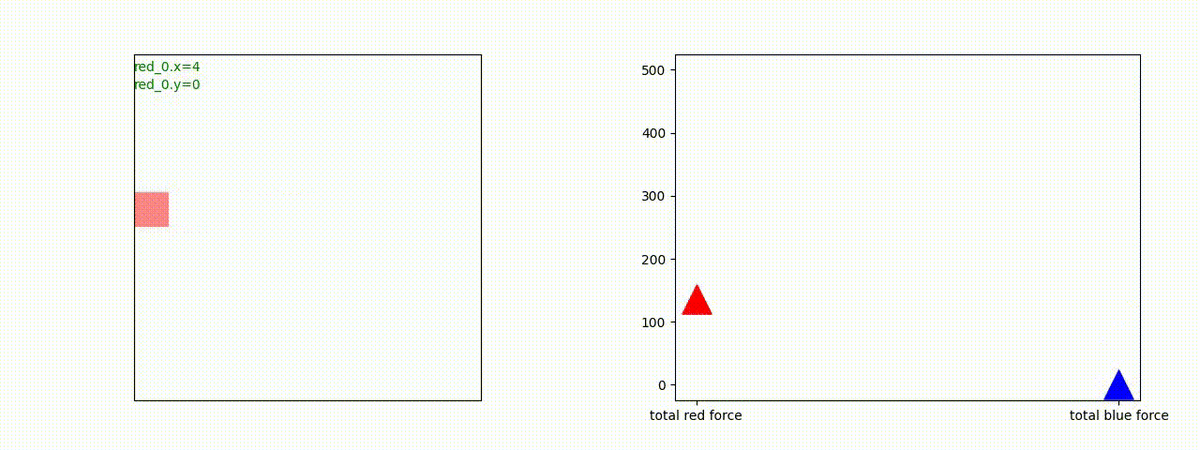
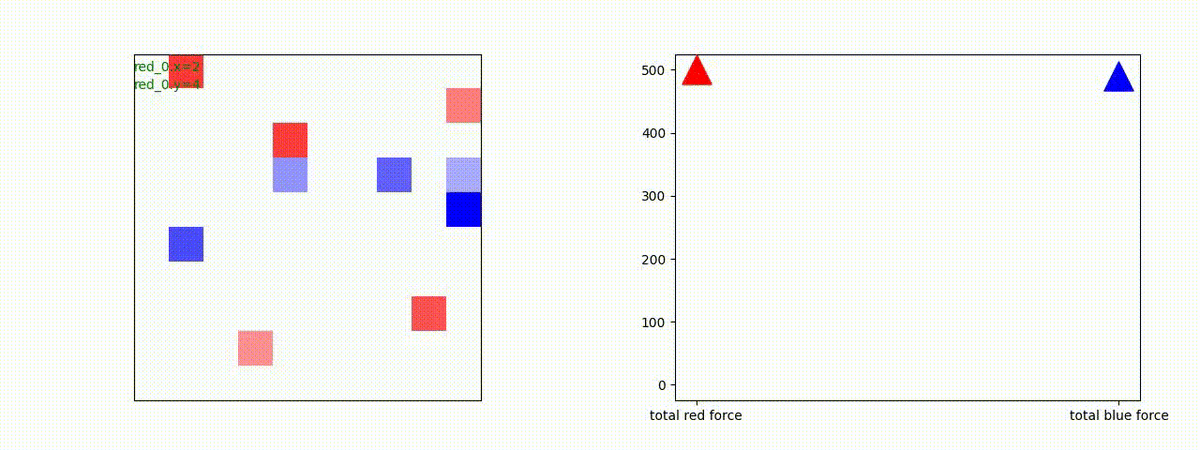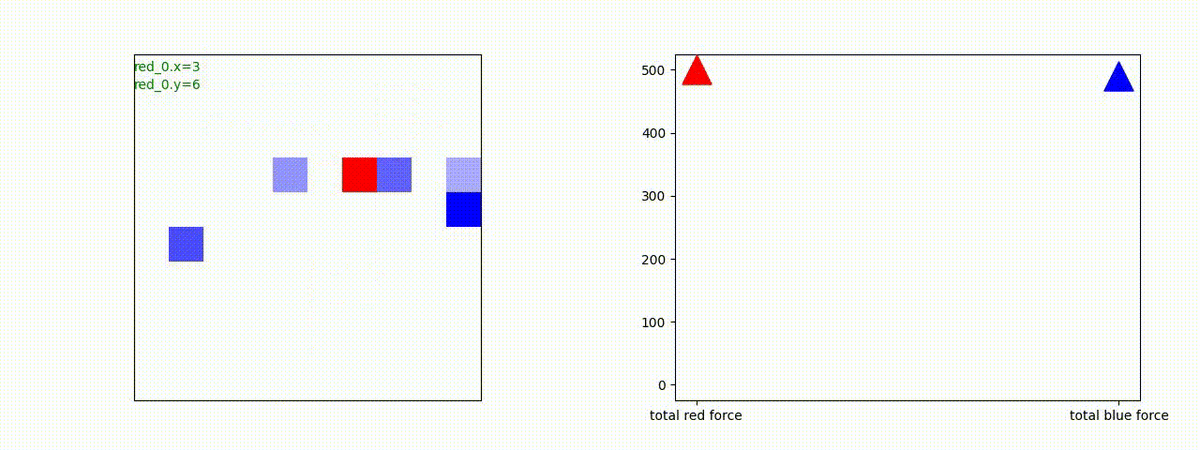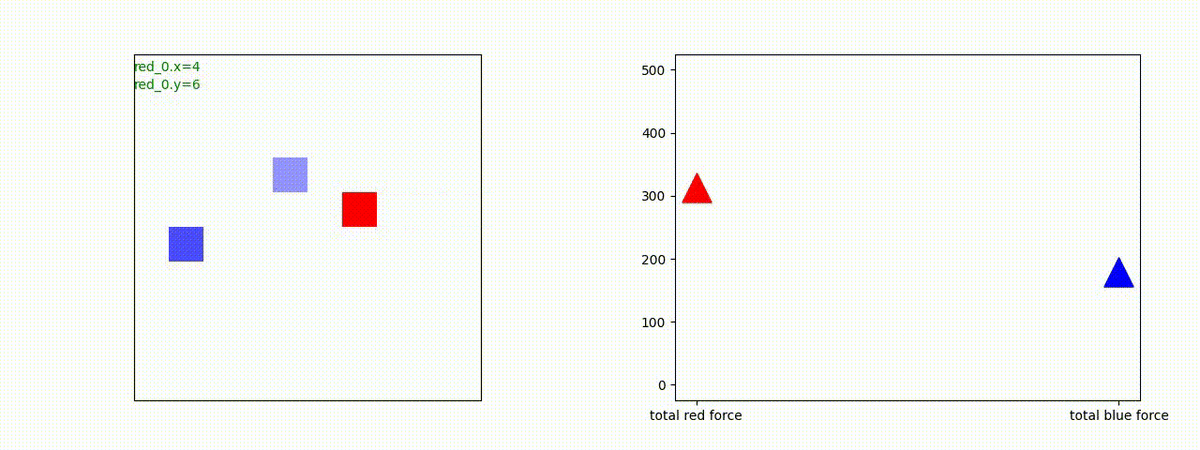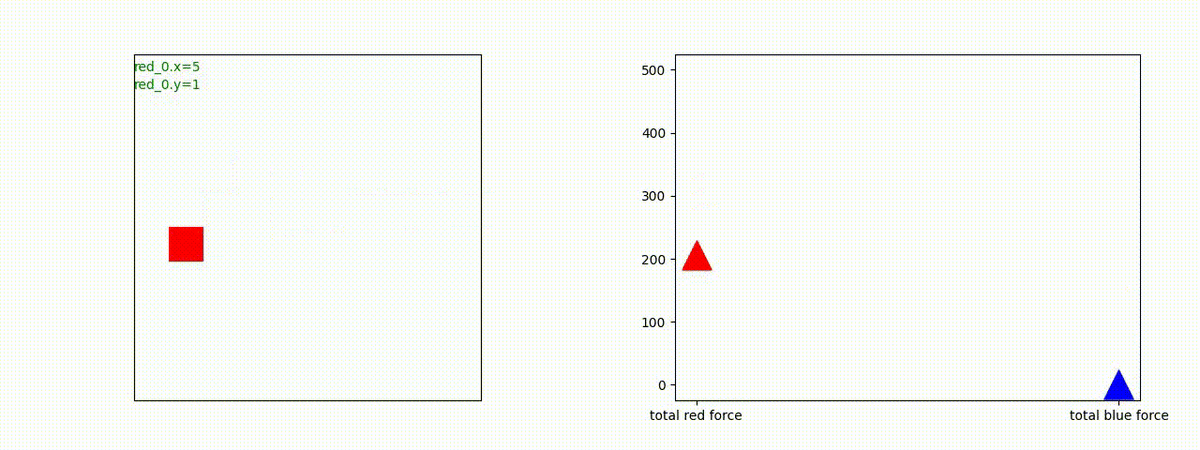
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [1, 3] で乱択しているので、学習が進んだ時の平均残存数=2 は、ほとんどの場合、全エージェントが残存していることを意味します。
これを平均残存兵力で見たのか下図です。Blue team の残存兵力はほぼ0になっています。Red team の残存兵力は 110 程度です。この最適解は、Red team が一丸となって、順に分割戦略で Blue team にあたった時の Lanchester model の残存兵力に近いものになっているはずです。エネルギー不足で、この計算は省略しました。いろいろ、省略が多くてゴメンナサイ。
Blue team の残存兵力を0にできたエピソードを success、逆に Red team の残存兵力が0になってしまったエピソードを fail、どちらの兵力も0とはならなかったエピソードを draw と定義して、これらを100回のエピソードから算出したのが下図です。学習が進むと、ほぼ確実に success=100%、つまり、Blue team の残存兵力を0にできることが判ります。
下図は、観点を変えて、エピソードの長さから学習の進捗状況を見たものです。戦域サイズが 10x10 で、エージェント数は少なく、1タイムステップでの兵力の消耗も大きいので、学習がちゃんと進んでいれば、ざっくり言って平均 10+α 回程度のタイムステップでエピソードが終われるはずです。実際、そのような結果となっています。一方、学習初期には、各エージェントは右往左往するので、最大エピソード長(=100)まで勝負がつきません。
性能評価
学習後のチームの性能を100回のシミュレーションを行って確認しました。
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
Blue team 初期エージェント数 = 1 の場合の結果は下表です。確実に、Blue team を撃破できる戦術を獲得していることが判ります。
BLUE Team Swarm 数 = 1
Blue team 初期エージェント数 = 2 の場合の結果は下表です。ここでも、確実に、Blue team を撃破できる戦術を獲得していることが判ります。また、Blue team が小分けになったことにより、Red team の残存兵力(red.force_ratio)が、上記 Table よりも大きくなっています。この残存兵力(red.force_ratio)が、0.33~0.36 とほぼ一定になっているので、Red team はエージェント数(群数)が多くても、"mass" を活かした戦術が生成できているのではないかと期待できます。
BLUE Team Swarm数 = 2
生成された戦術
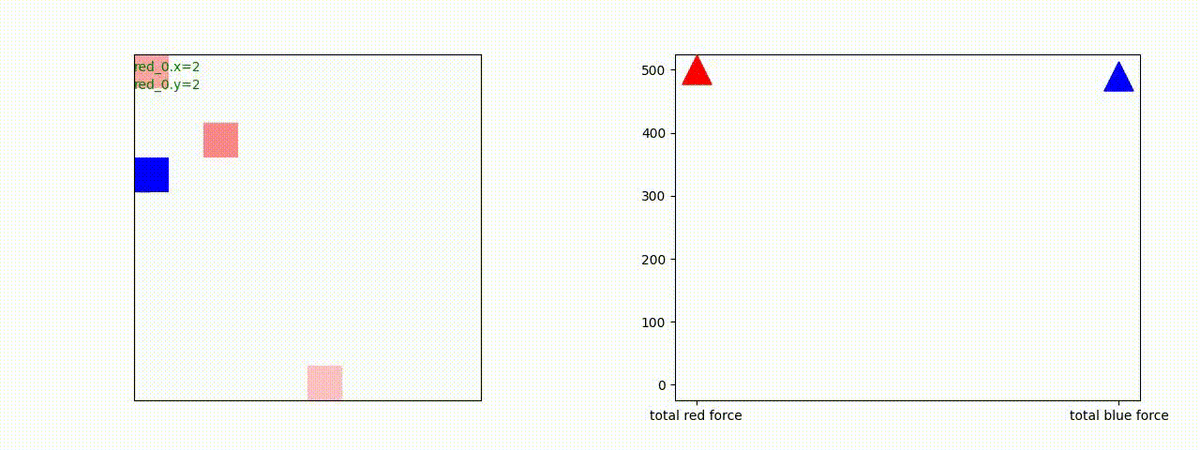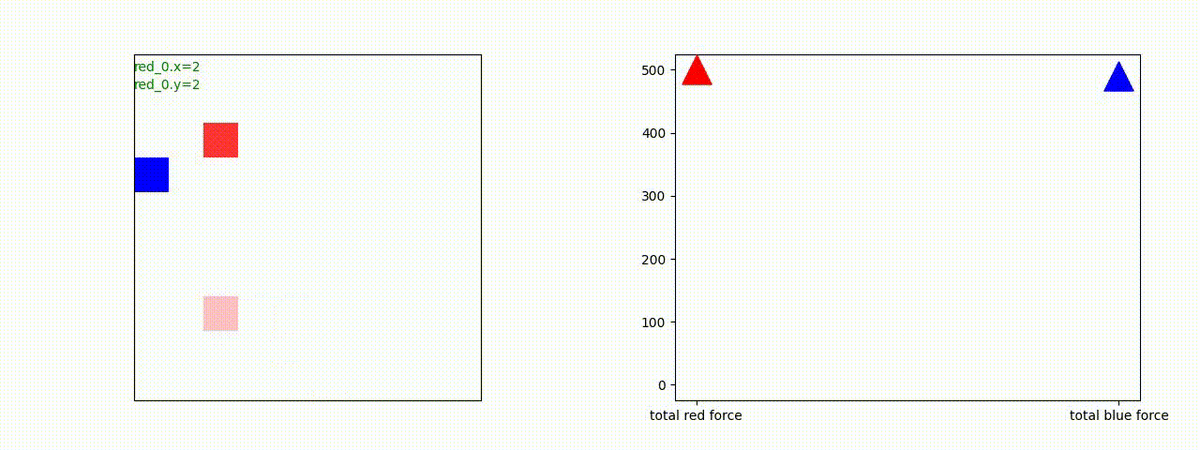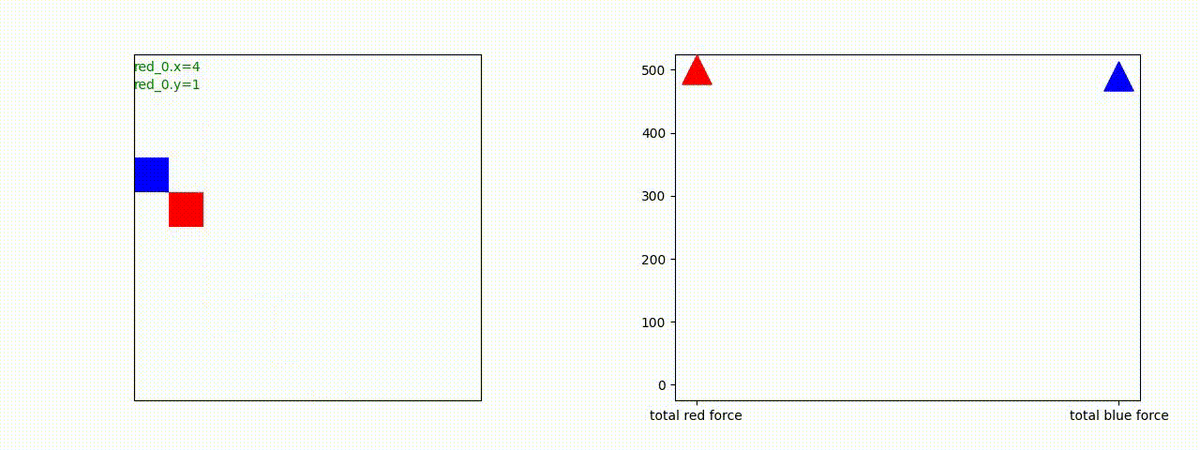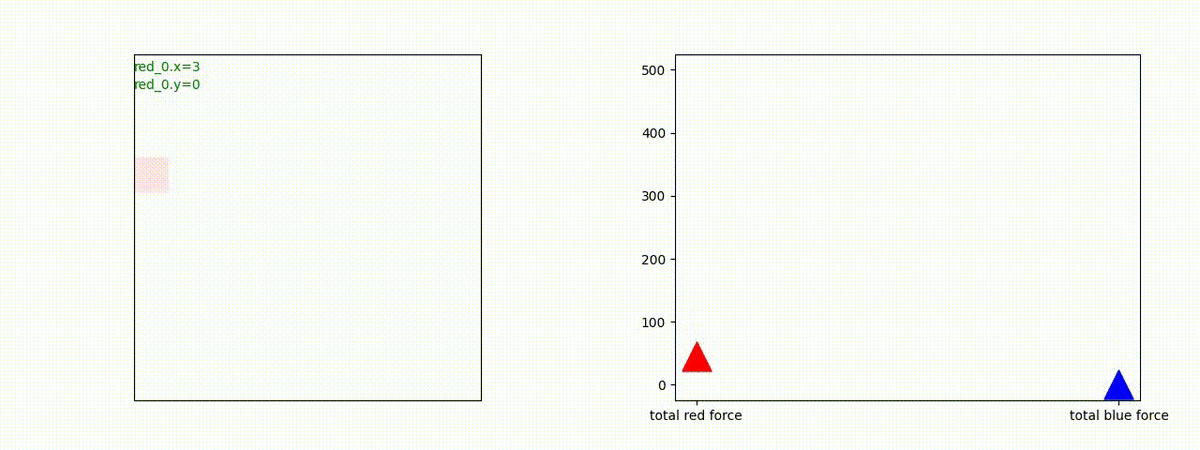
1 swarm vs 1 swarm
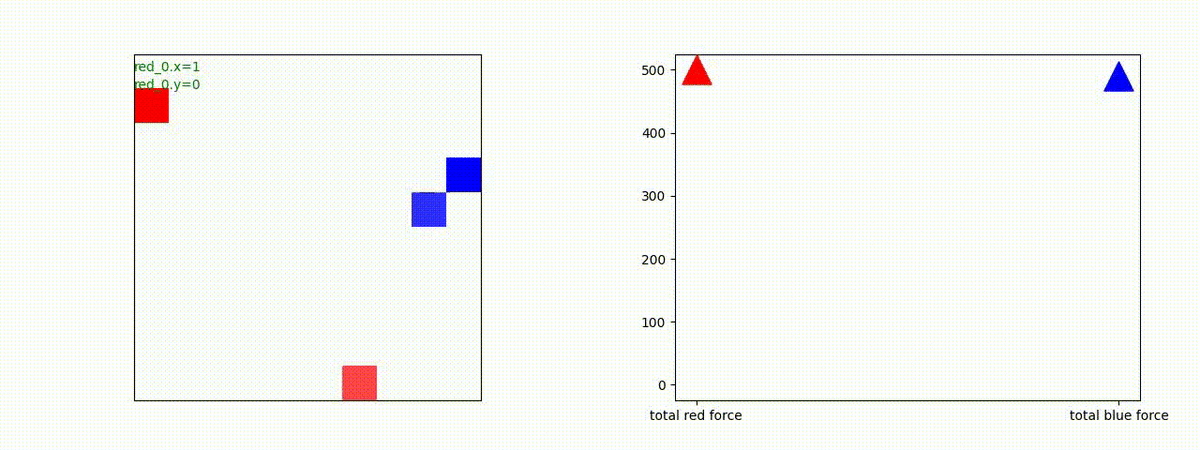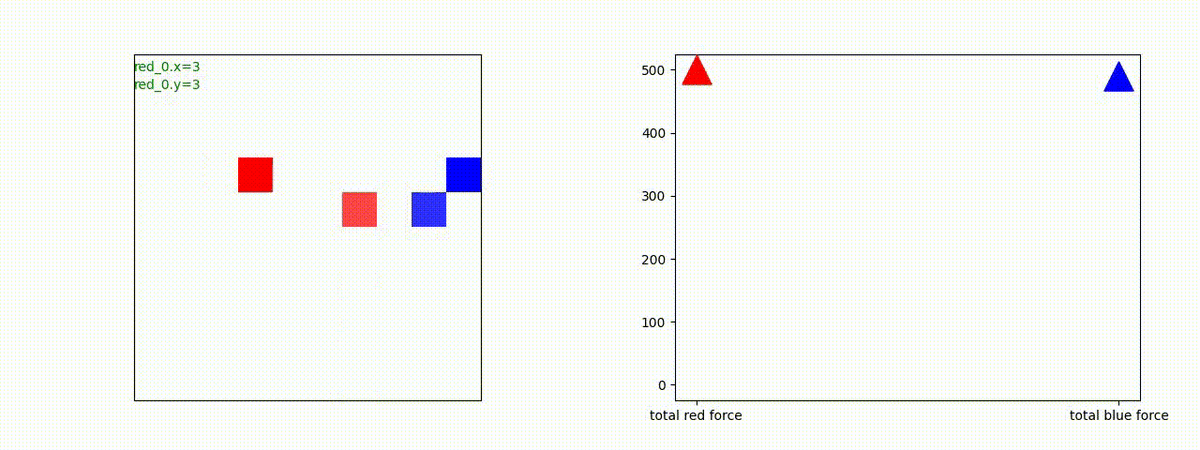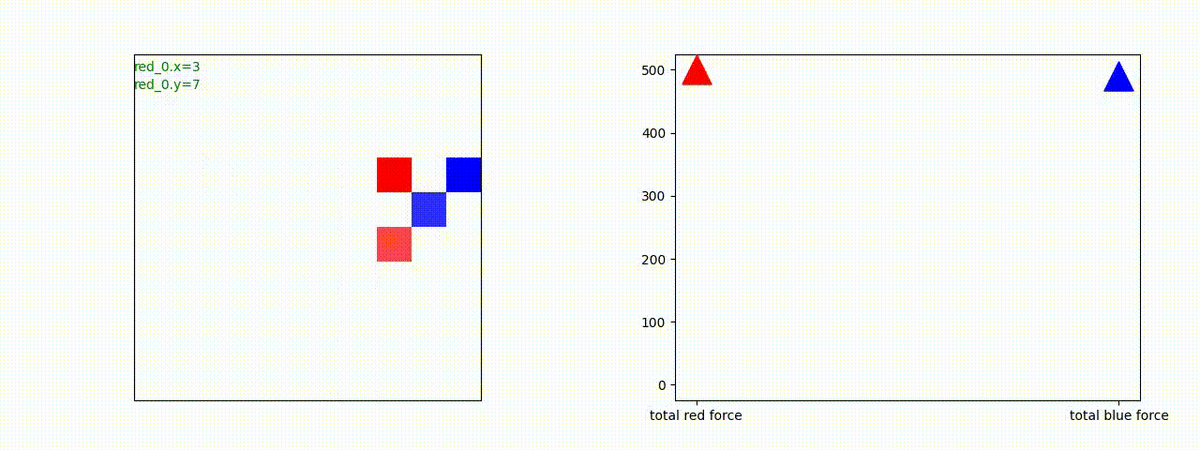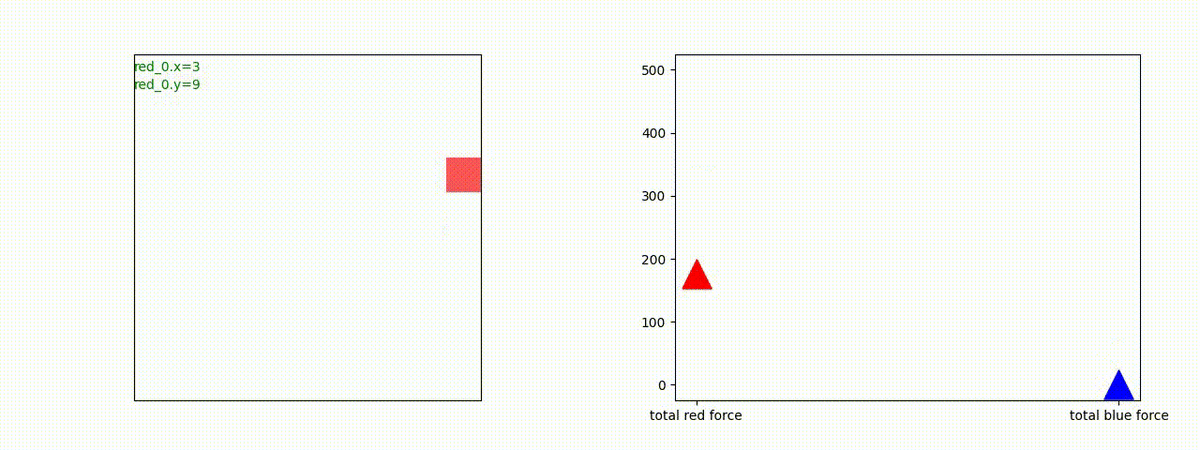
下図(左)は、戦闘状況を示します。赤い正方形が Red team のエージェント(群)、青い正方形が Blue team のエージェント(群)を示します。画面左上の座標値は、red team の0番目のエージェント( "red_0" と呼称)の位置を示します。また、色の濃さが戦闘力(Force)の大きさを表し、色が濃いほど大きな戦闘力であることを示します。したがって、戦闘が進むに連れ、戦闘力は消耗して色が薄くなってゆきます。また、同一グリッドに Red team と Blue team が混在する場合は、チームの戦闘力の差を表していますので、色が薄いほど拮抗した戦闘がそのグリッドで行われていることになります。戦闘が進んだ時に色が濃くなるのは、それだけその色のチームの戦闘力が相対的に優位になったことを表しています。
下図(右)の赤、青三角は、夫々 Red team, Blue team の残存戦闘力(群の構成メンバー数)を示します。
Red team のエージェントは、敵(Blue team のエージェント)の位置を認識し、そのマスへ最短経路で移動し、敵が消耗して殲滅するまで敵と同じマスにとどまる戦術を学習しています。
但し、ごく稀ですが、1タイムステップの遠回り経路をとることが有りました。
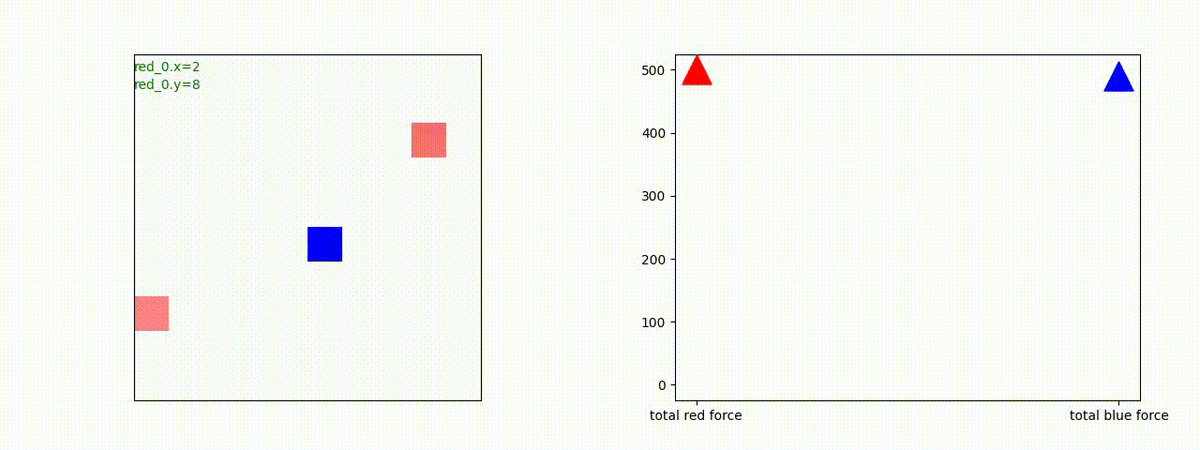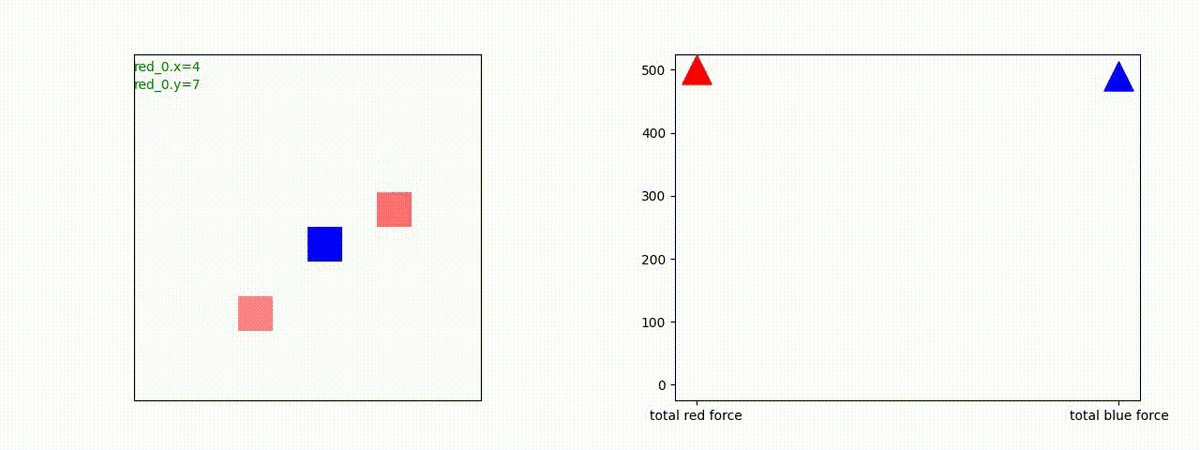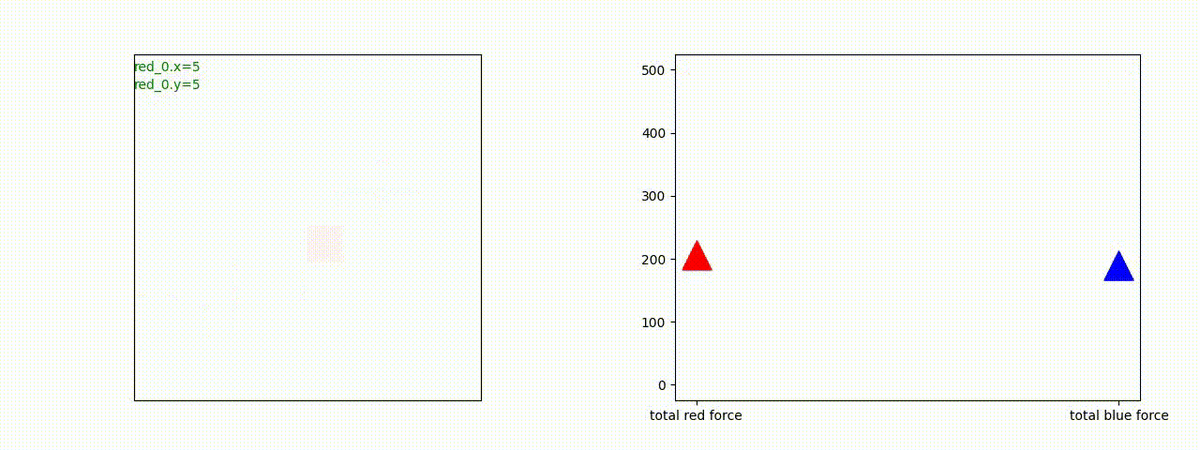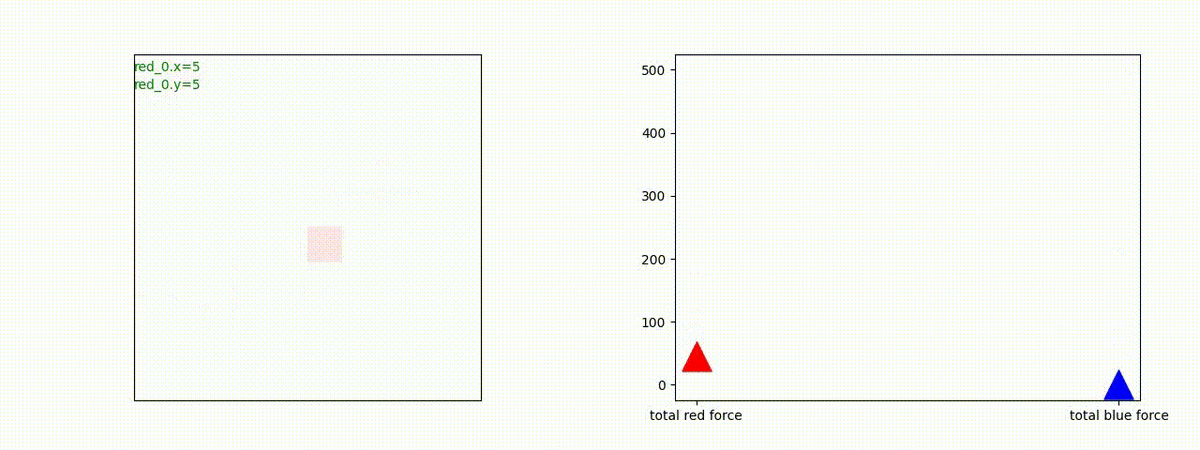
2 swarm vs 1 swarm
Red team のエージェントは、一丸となって巨大な Blue Team のエージェントに当たる必要があるシナリオです。
このシナリオでは、2通りの戦術が生成されました。
1つめの戦術は、まず2つの swarm が一体化して巨大な戦闘力を有する1つの swarm になった後、初めて Blue team の swarm に攻撃を加える戦術です。
2つ目の戦術は、2手に分かれている Red team の swarm が、別々の方向から同じタイミングで Blue team の swarm に同時攻撃をかける戦術です。実際の戦闘では、このような挟撃戦術は、より効果があると思うのですが、Lanchester モデルは挟撃の効果をモデル化していないため、学習したエージェントが常にこの戦法をとるとは限りません。この辺りは、強化学習の問題ではなく、モデル化の問題です。
どのような戦況配置の時に、どちらの戦術をとることになるのか知りたかったので、いくつかケースを比較してみたのですが、私には判りませんでした。この分野は、XAI として熱心に研究されていますので、今後に期待しています。
3 swarm vs 1 swarm
再録になりますが、今回使っているアーキテクチャは下図になっています。
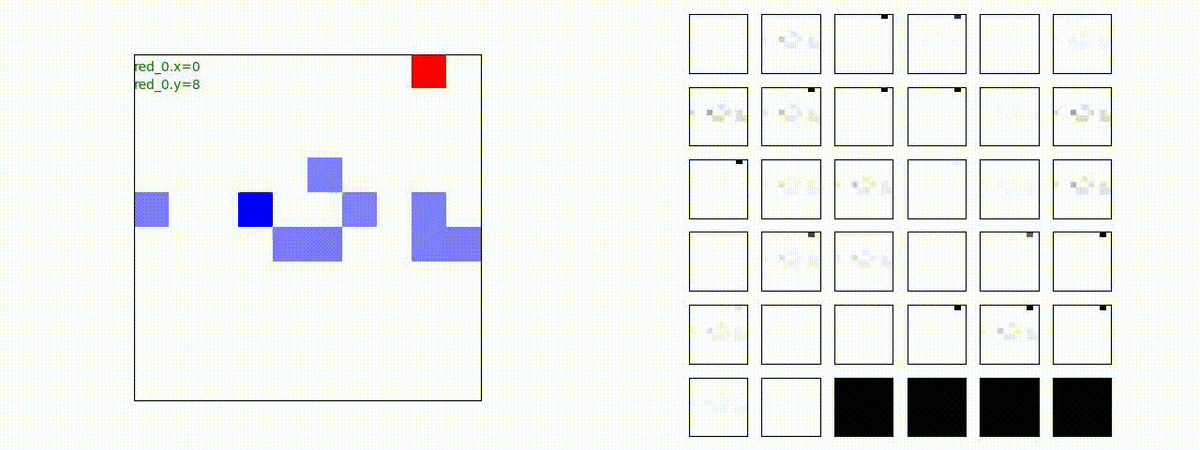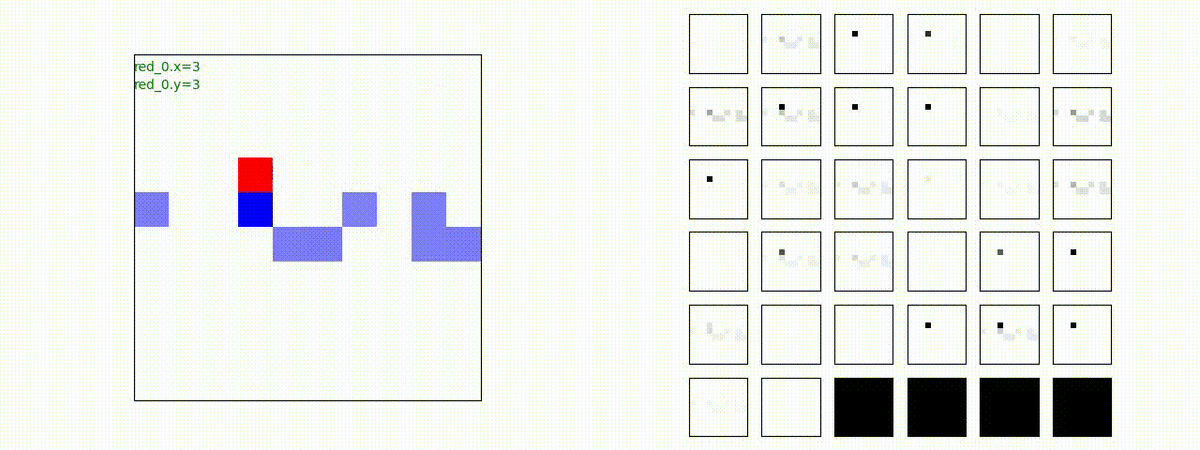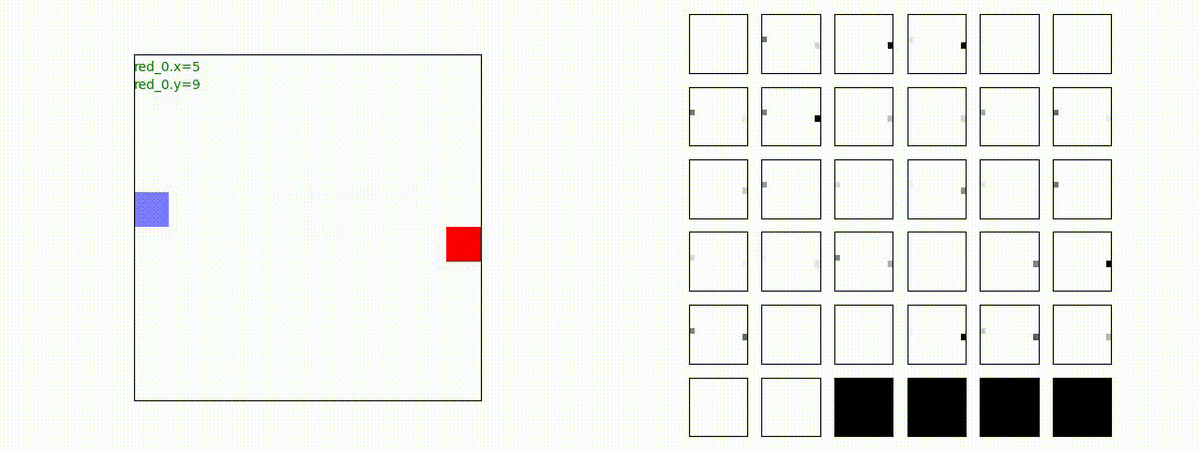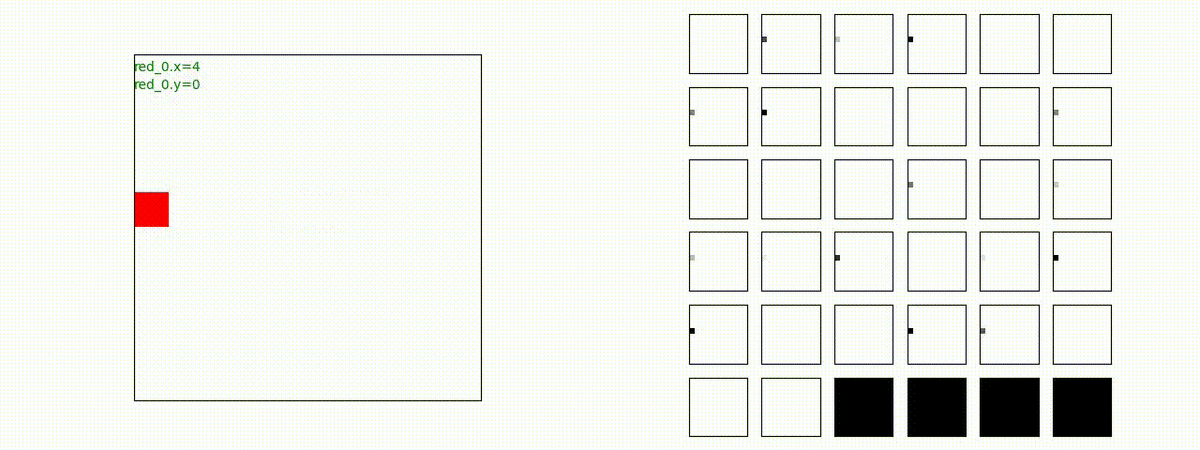
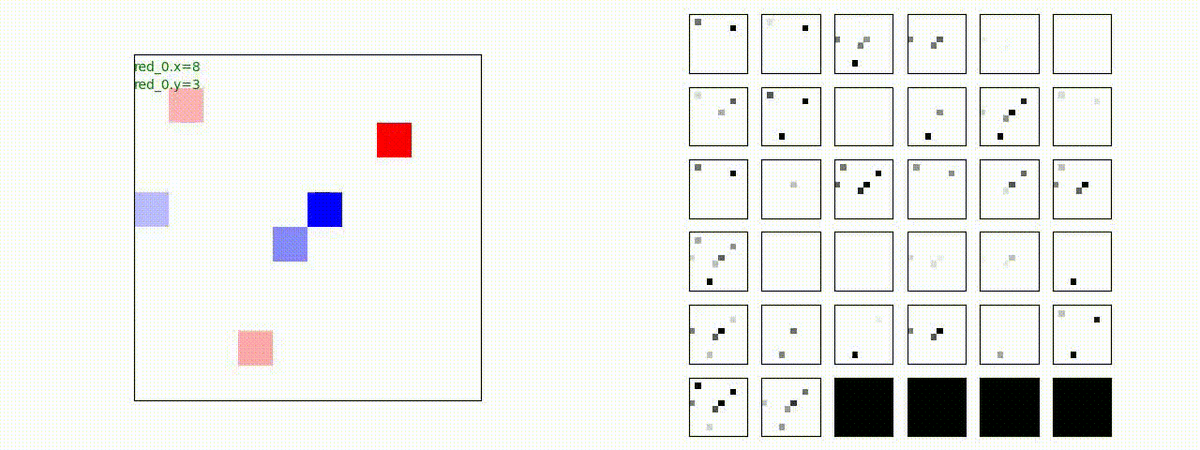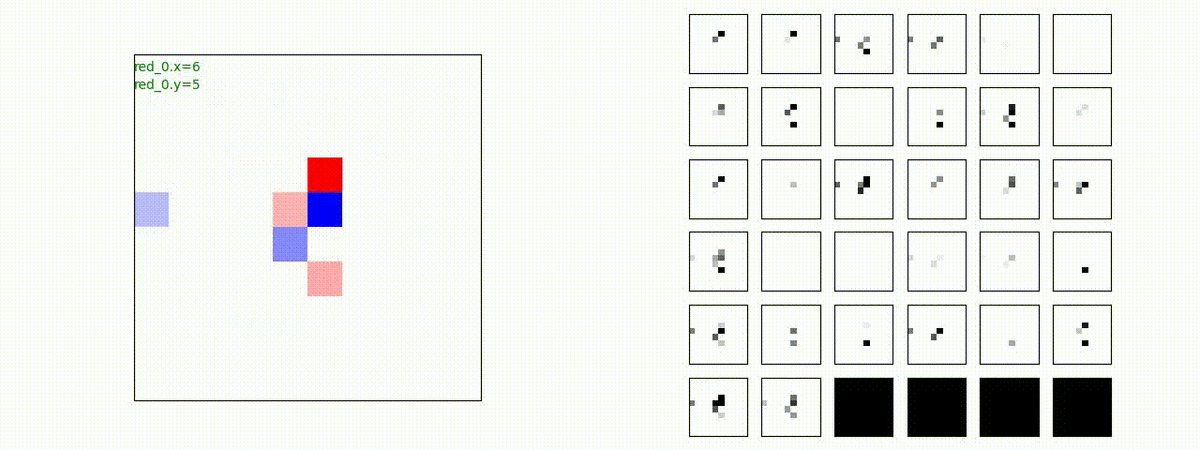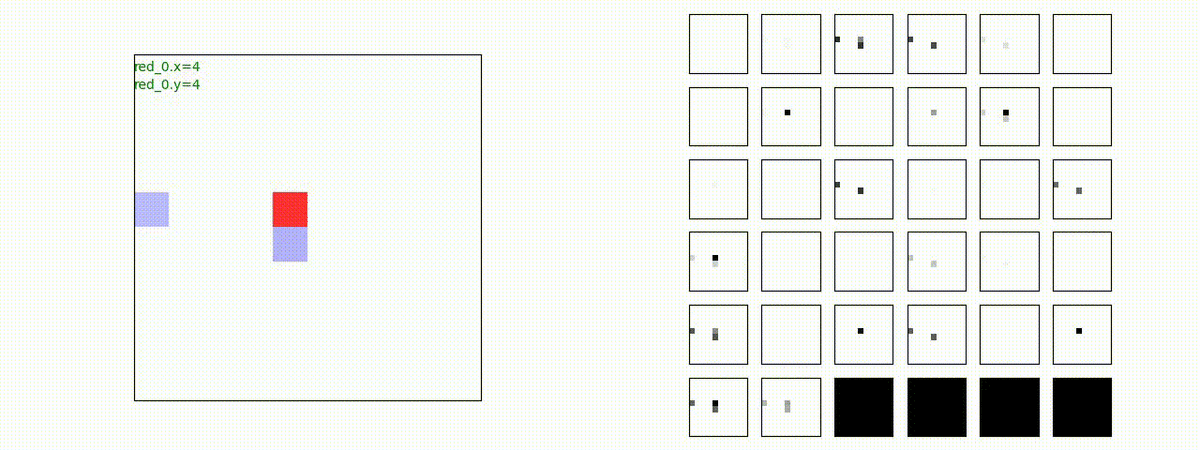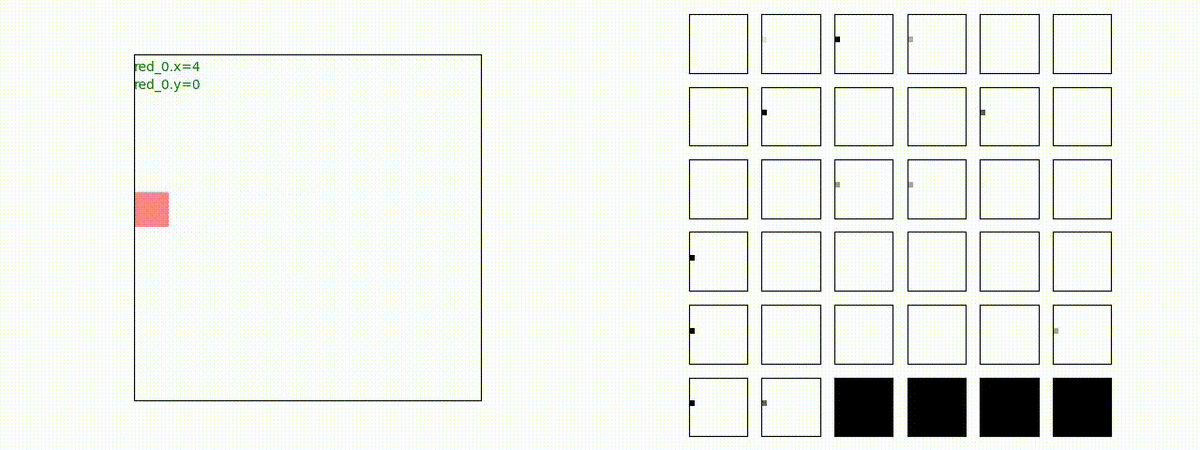
このアーキテクチャでは、各エージェントは、入力された6枚のマップ (10x10x6) から、1x1 Conv を使って、以降の認知系(DenseNet)に入力するマップ (10x10x32) を合計で 32 枚生成しています。どのようなマップが生成されるのかは、大変興味があるところだったので、エージェント 'red_0' の生成したマップを可視化してみました。(これらのマップは、当然、エージェント毎に異なります)。
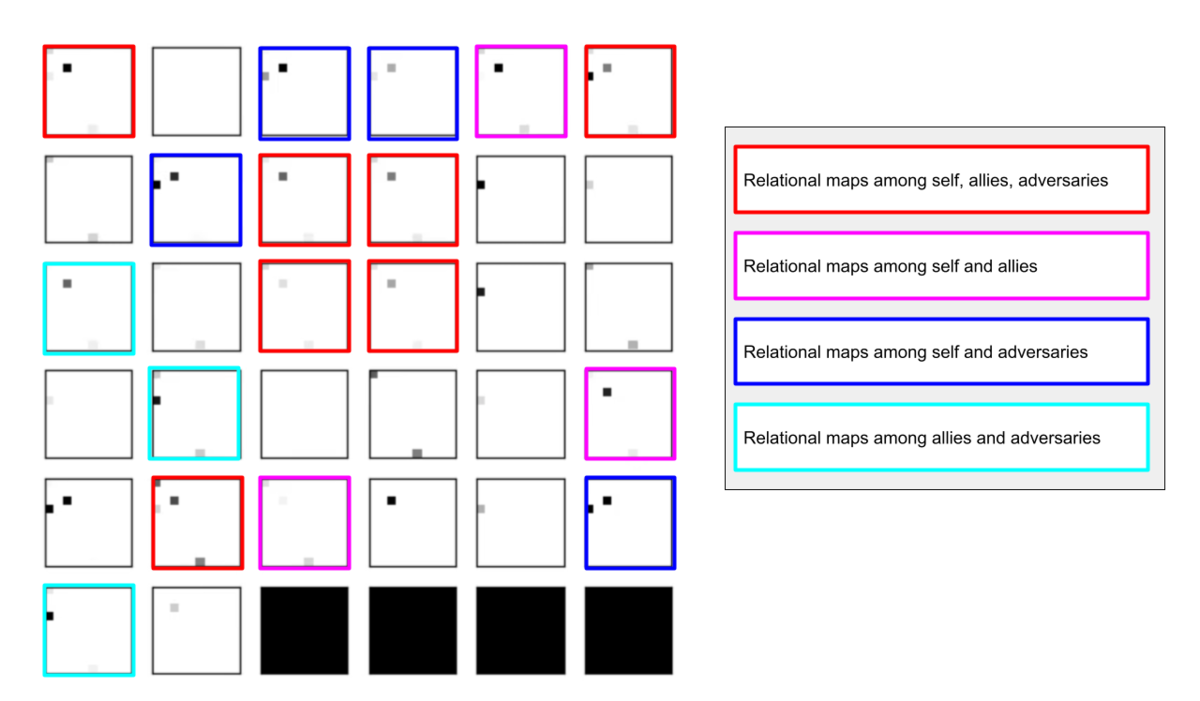
上図から、入力されたマップから、Shared 1x1 Conv が新たに以下のマップを作成して、DenseNet にハンドオーバーしていることが判ります。
- Red team, Blue team全体の配置や兵力を表していると思われる複数のマップ
- 自分('red_0')と、他の red team エージェントの位置や兵力を表していると思われる複数のマップ
- 自分('red_0')と Blue team のエージェントの位置や兵力を表していると思われる複数のマップ
- 他のred teamエージェントとBlue team のエージェントの位置や兵力を表していると思われる複数のマップ
これらのマップは、いずれも戦術を生成する上で意味があるマップとなっているように思えます。人間でも似たようなマップを作るのではないでしょうか。各 map はテンソル(数値アレイ)で与えられているので、定量的に解析しようと思えば解析できます。例えば、どのエージェントと組むのが良さそうなのかとか、どのblue teamを攻撃するのが良さそうなのかを表すようなマップが見つかるのかもしれません。ただ、この解析は相当時間がかかりそうだったので省略しました(ゴメンナサイ)。
※ 1 x 1 conv 以外の層の出力も、同じようにして可視化してみたのですが、グリッドサイズが変わっている上に、チャネル数が増えているので、これを解析するのも諦めました。もう少し、XAIが進歩したら、面白い結果が出せるのかもしれません。
以下では、参考のために、エージェント 'red_0' の 1x1 Conv の出力である生成した新たなマップも示します。(エージェント数が増えてくると、眺めている分には楽しいのですが、目がちらちらしてしまい、マップの把握が出来なくなりました)。
また、例えば 「1 swarm vs 2 swarm」は、前が red team数、後ろが blue team 数を表します。つまり、「1 red team エージェント(群)vs 2 blue teamエージェント(群)」を意味します。
下記の動画から、red team が複数のエージェント(群)で構成されているようなシナリオでは、red teamは、'mass' を構成して blue team にあたる戦術を生成していることが判ります。
1 swarm vs 2 swarms
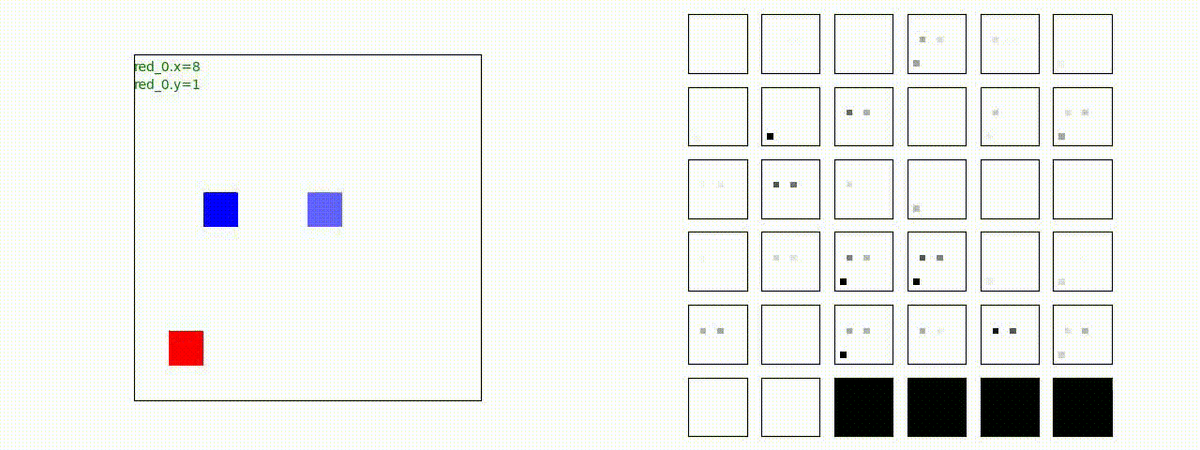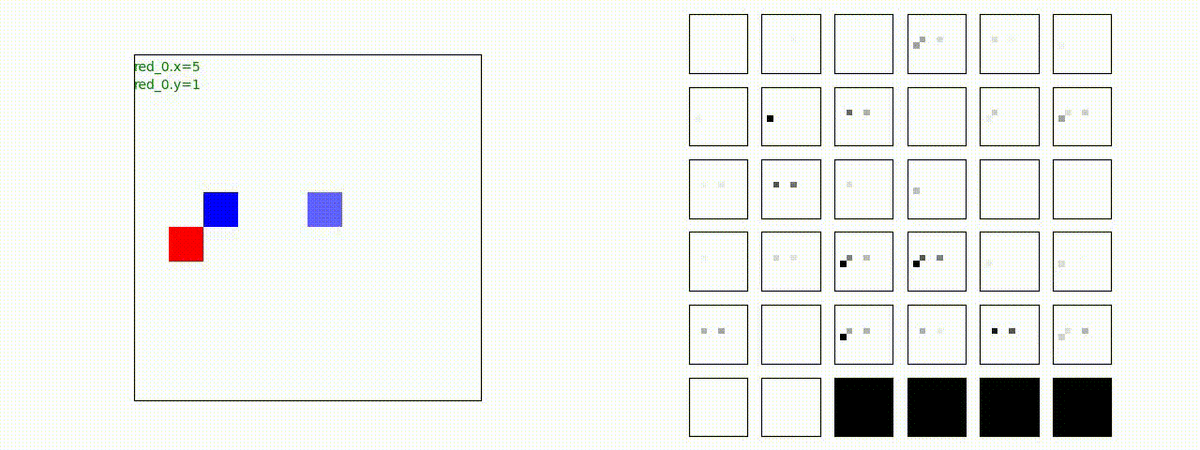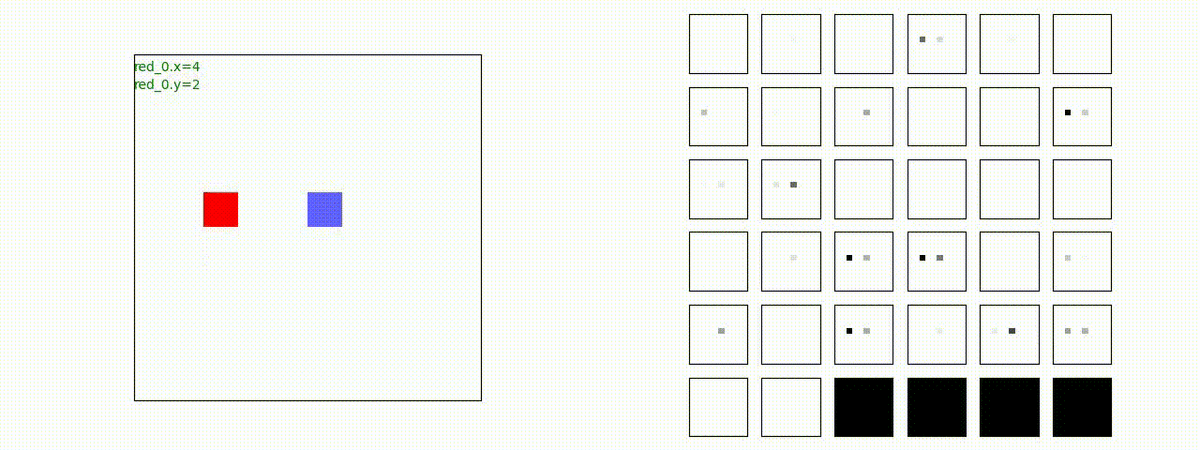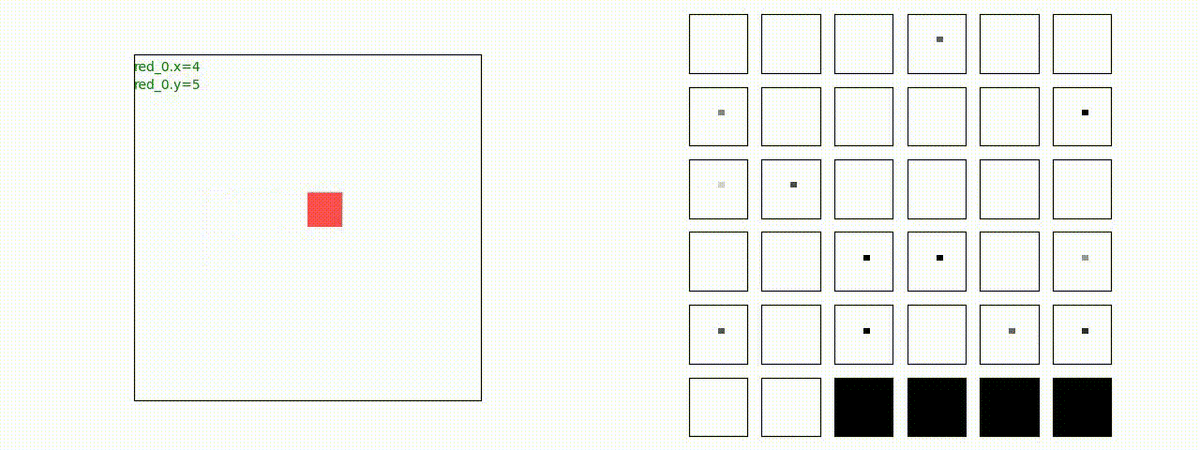
2 swarms vs 2 swarms
red team の各エージェント(群)は、'mass' を構成してから blue team にあたる戦術を獲得しています。
Shared 1 x1 Convが生成するマップは、更に複雑になり、見ている分には楽しいのですが、私には手が終えません。
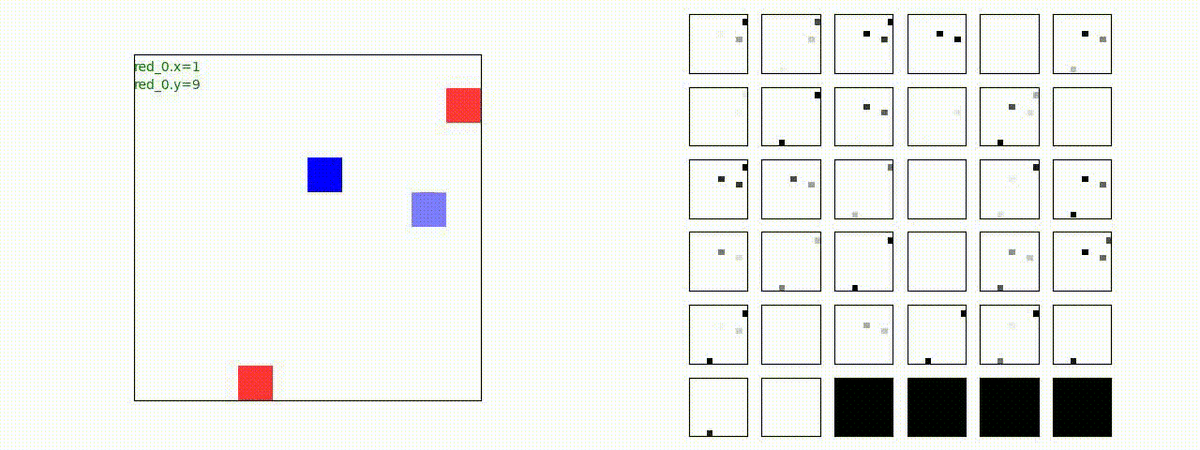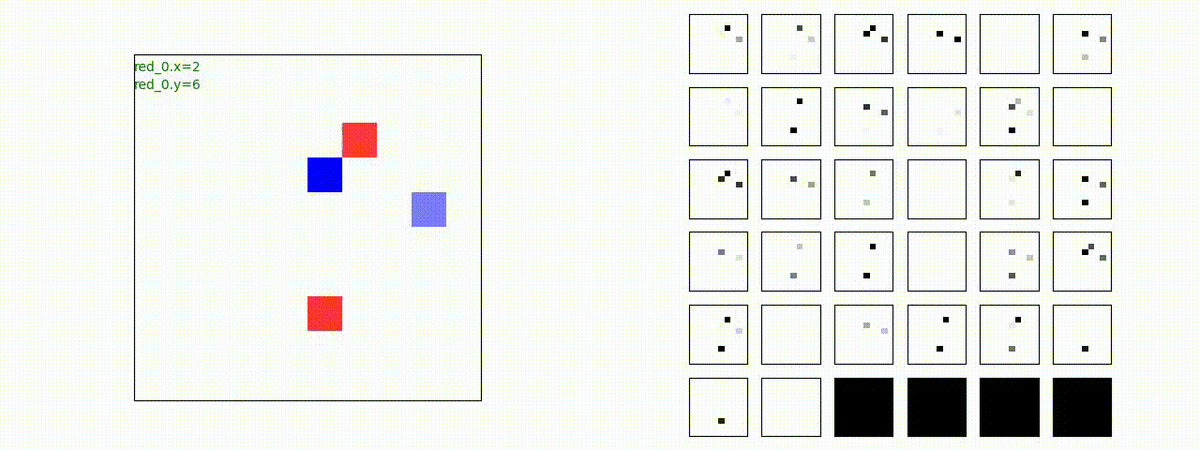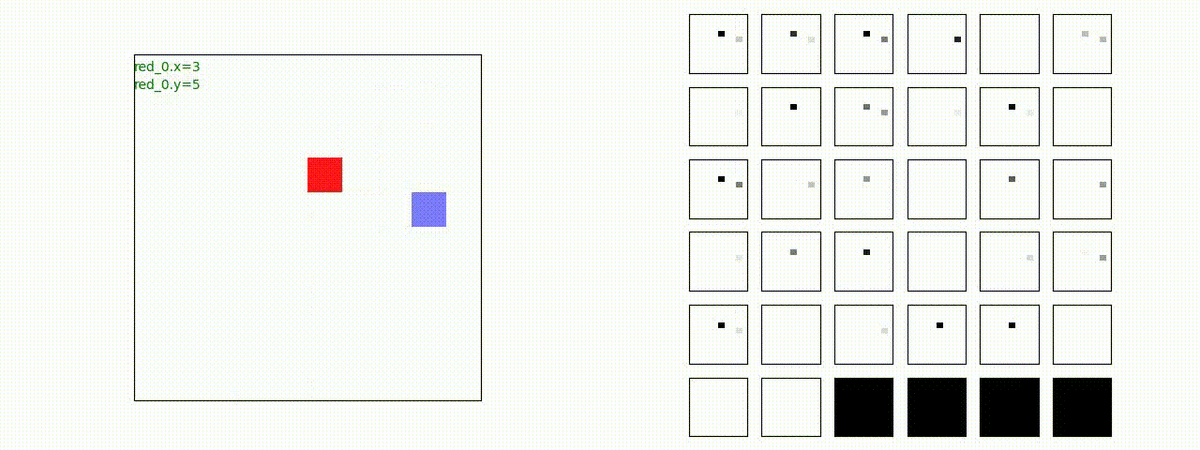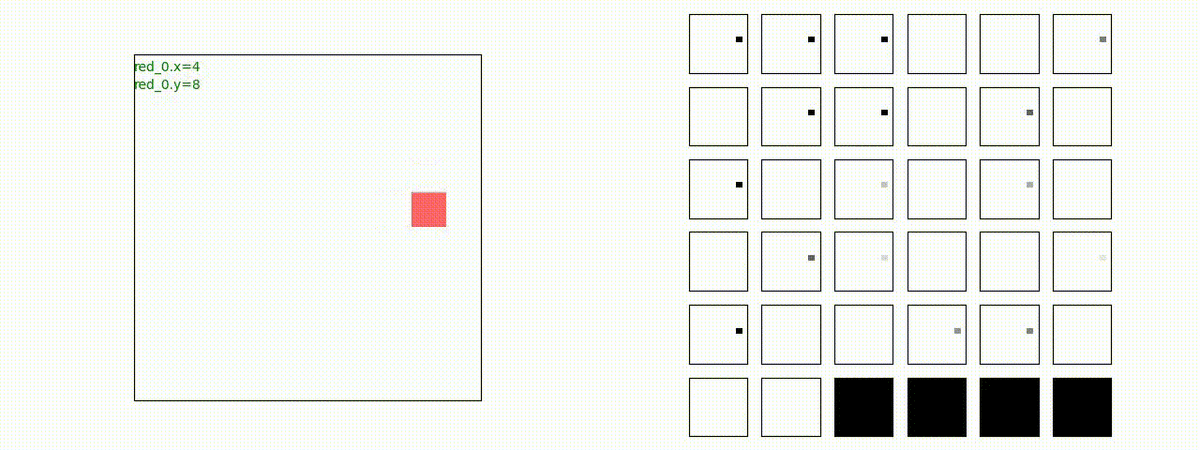
3 swarms vs 2 swarms
red team の各エージェント(群)は、'mass' を構成してから blue team にあたる戦術を獲得しています。
ロバスト性(汎化能力)
戦況をマップで表し、マルチエージェントの枠組みを使うメリットの一つは、登場エージェント数を任意に増減できることです。もちろん、学習時に経験していないエージェント数に対しては、見たことが無いマップが入力されることになるので、性能は劣化するはずです。
ここでは、エージェント数を Red team = [1, 10], Blue team = [1, 9] として、トレーニング時には全く未経験の戦況にどこまで対応できるのか測って見ました。(トレーニング時のエージェント数は Red team = [1,3], Blue team = [1,2] です)。
この場合、トレーニング時には見たことがないような、沢山のグリッドにエージェントが存在するきらびやかなマップがいきなり提示されることになるので、人間だったら、結構戸惑う状況だと思います。それでも、「敵の戦闘力以上の戦闘力になるように、味方エージェントと協調して一丸となって戦う」という "mass" のコンセプトをきちんと学習し理解できていれば、最適とまでは行かなくても一定の戦闘は出来る可能性があります。
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。この見せ方は、とても難しく何通りかやってみて、バーグラフとヒートマップに落ち着きました。(ヒートマップは、拡大してみてください)。
num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸 blue_force_ratioは、
blue_force_ratio = Blue team残存兵力/Blue team初期兵力
を表します。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。したがって、黄色から外れるほど、トレーニング時に見たことがない戦闘環境になります。
同様の解析を Red team の兵力に対して行ったのが下図です。red_force_ratio は以下で定義しています。
red_force_ratio = Red team残存兵力/Red team初期兵力
兵力(Force)の代わりに、残存エージェント数をグラフ化したのが下図です。blue_alive_ratio は以下で定義しています。
blue_alive_ratio = Blue team残存エージェント数/Blue team初期エージェント数
= Blue team残存群数/Blue team初期群数
Red team については、下図になります。red_alive_ratio は以下で定義しました。
red_alive_ratio = Red team残存エージェント数/Red team初期エージェント数
= Red team残存群数/Red team初期群数
以上から、以下を読み取ることができます。
- Brue team のエージェント数 = 1 の時、つまり、Blue team が巨大な兵力を持った1つの群だけで構成されている場合、Red team のエージェント数がトレーニング時よりも増えると、Blue team の残存兵力は急激に大きくなる。この時の、Red team の残存兵力は僅かである。したがって、Red team は、外挿に耐えうるほどは "mass" 重視の戦術を学習しきれていない。
- Brue team、Red team のエージェント数が増えるほど、(外挿方向なので、当然ですが)、Brue team の残存兵力は増える。この時の Red team には、かなりの兵力が残存している。したがって、エージェント数が増えるほど、未知の環境に右往左往してしまい上手く戦いきれていない。
上記をもう少し分析します。成功率、引き分け率を以下で定義することにします。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
draw = どちらの tem の残存兵力も0にならなかったエピソード数/全エピソード数
これらをバーグラフと heatmap にしたのが下図です。
Brue team のエージェント数 = 1 の場合、Red team が小分けになるほど急速に成功率が減少します。
一方、Brue team, Red_team のエージェント数がともに増えた場合、draw になる割合が増えていきます。これは、上手く戦えずエージェントが未知の環境で右往左往していることを裏付けています。
これをエピソード長で見てみます。戦場サイズが 10x10 なので、上手く戦っていれば平均10~20ぐらいのエピソード長で戦闘は終了するはずです。
エピソード長は、Brue team のエージェント数 = 1 の場合、Red_team 数が増えても長くなっていません。やはり、強大な敵に小分けの戦闘力で当たる場合、mass 戦略を発揮しにくくなっているのが判ります。
一方、Brue team, Red_team のエージェント数がともに増えた場合、エピソード長は増大し、エージェントが未知の環境で右往左往していることが判ります。
生成された戦術例(汎化性能)
実際に、どういった戦闘状況になるのか、いくつか生成例を下記に示します。図の見方は、先の動画と同じです。
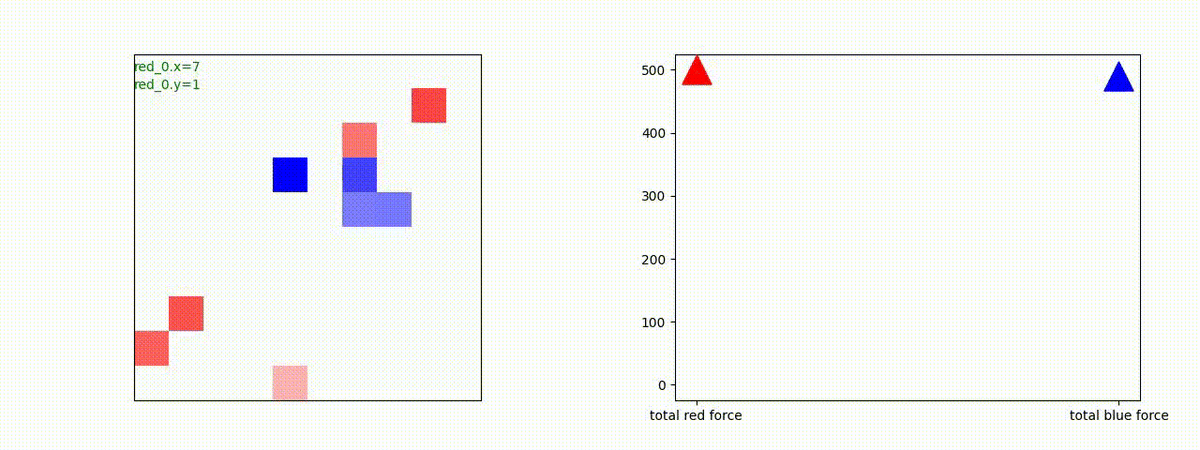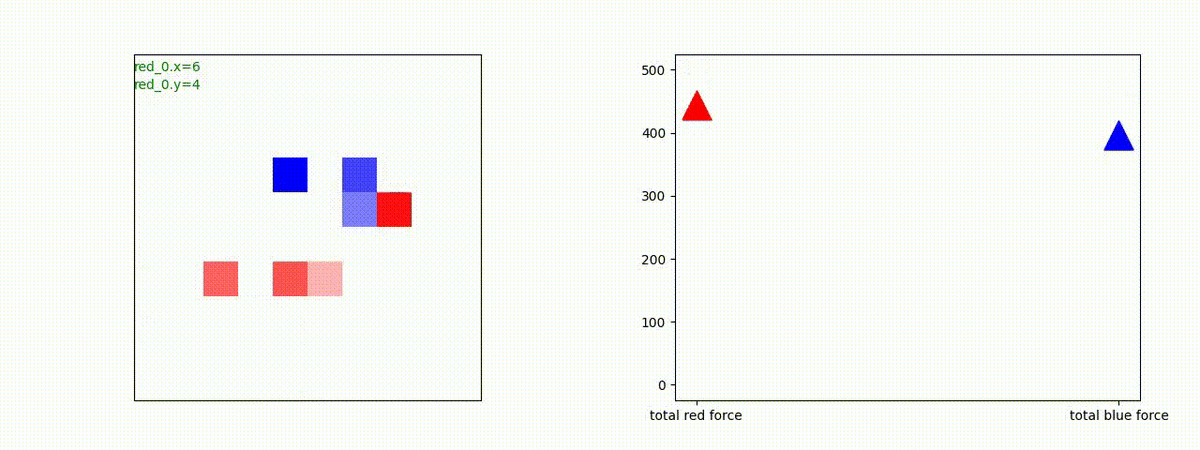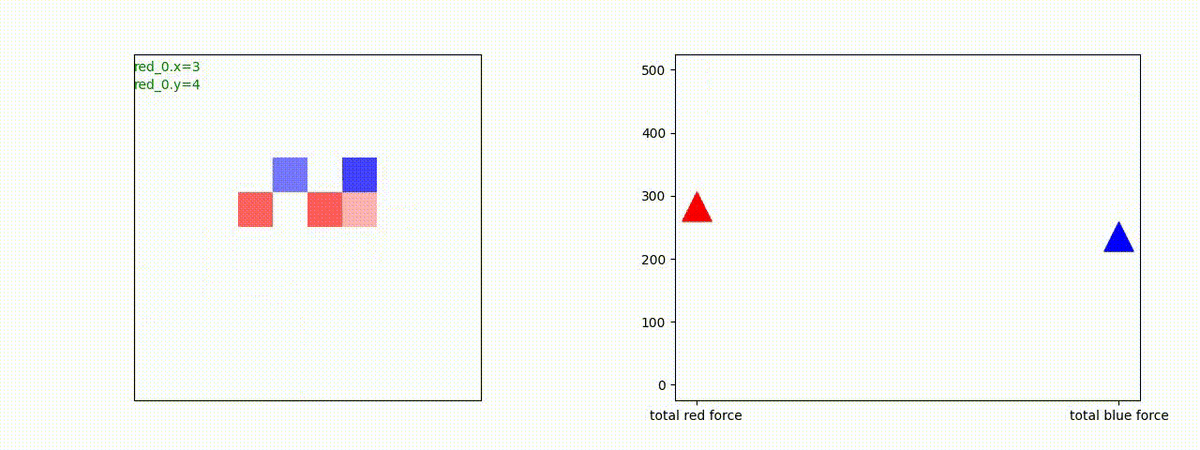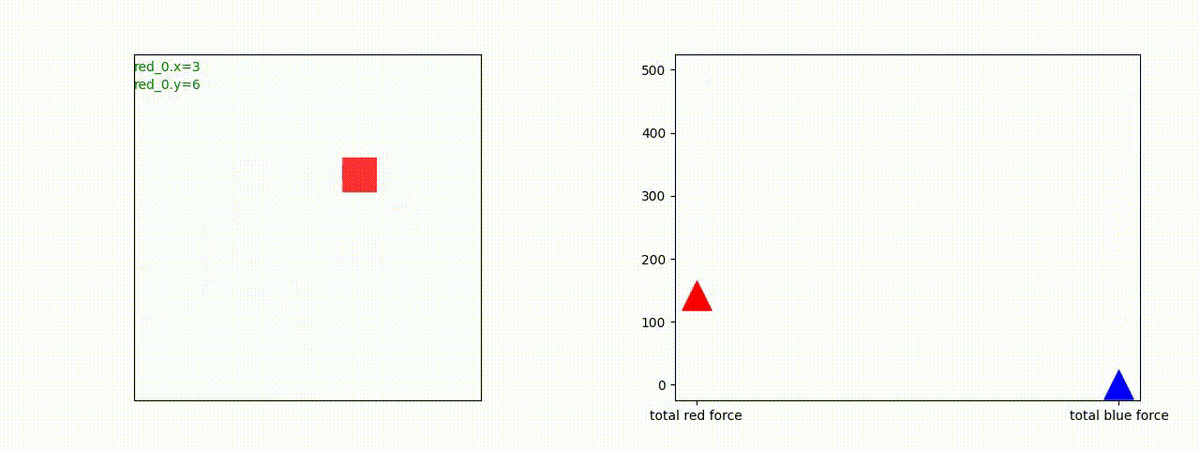
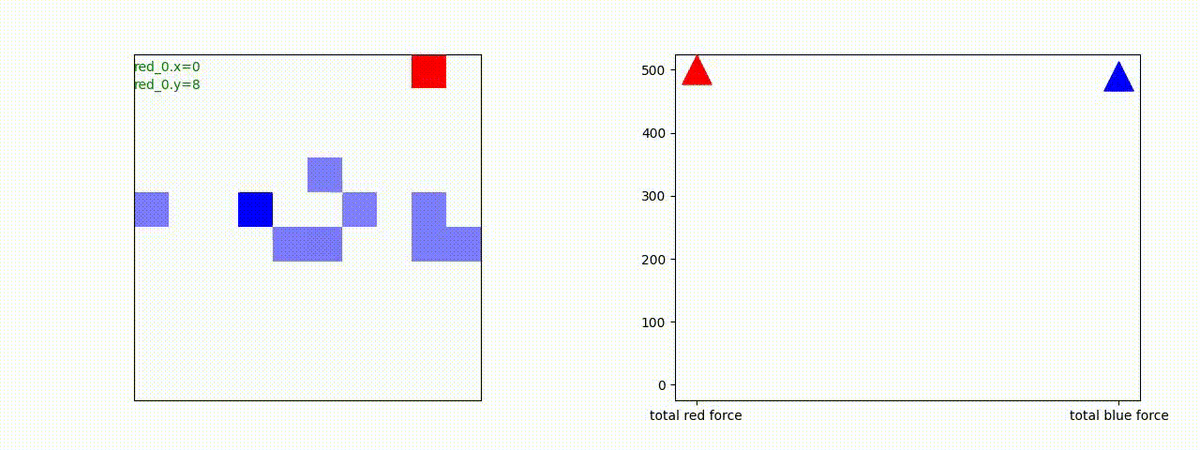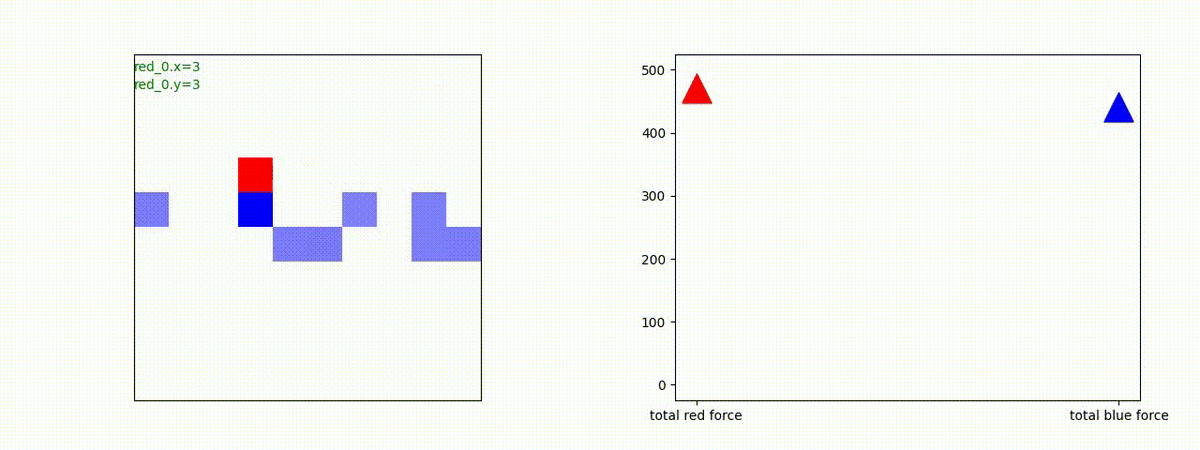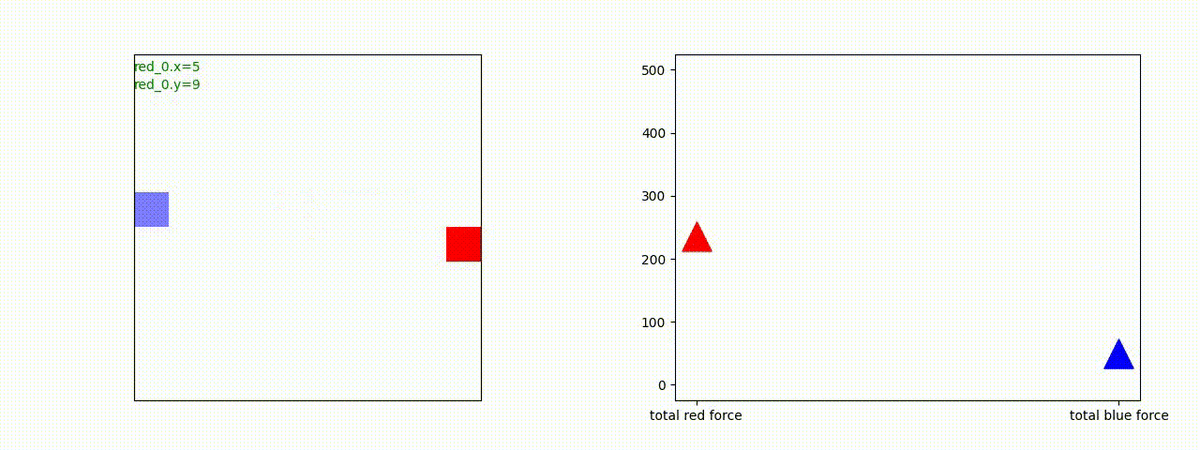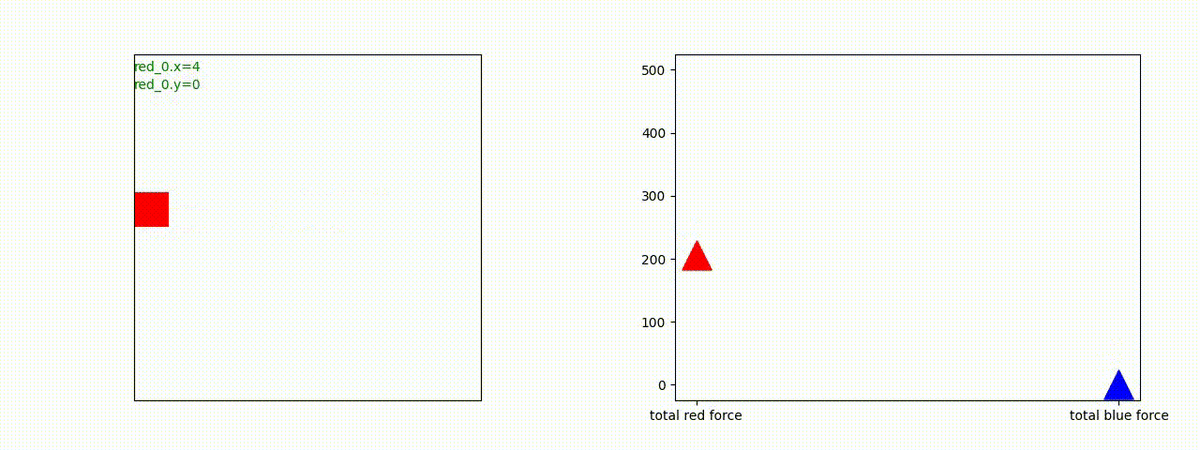
Red_team=10 swarms vs Blue_team=1 swarm
戦域に小分けになって散開した Red teamが、1つの巨大な戦闘力を有する Blue team と戦うシナリオです。Red team の各エージェントは、mass を重視した大きな戦闘力となるよう自律的に集合して来るのですが、後一歩タイミングを揃えることがでないために、わずかの差で Blue team に撃破されます。他のケースも、いくつか調べたのですが、同様の傾向が見られました。
やはり、強化学習はタイミングのコントロールは、あまり得意ではないようです。
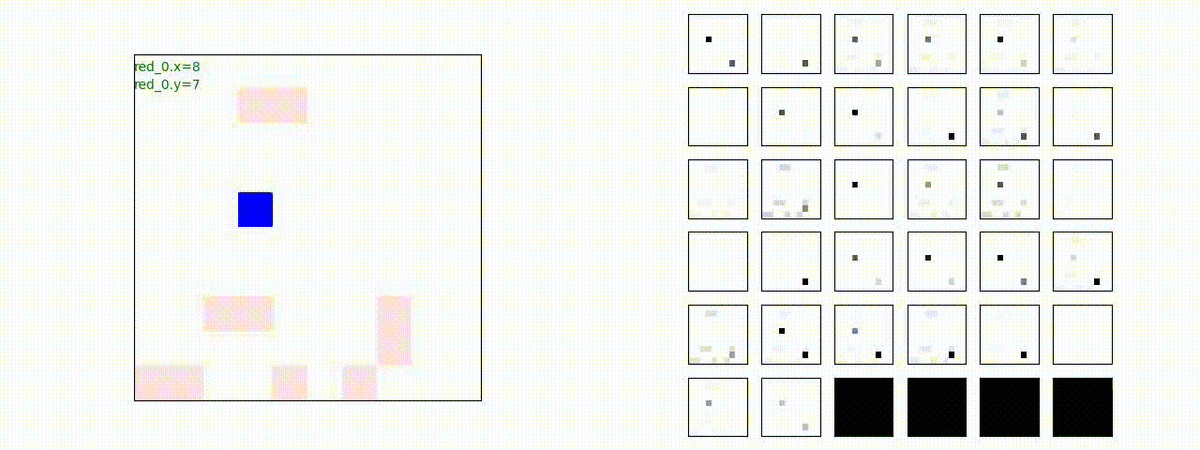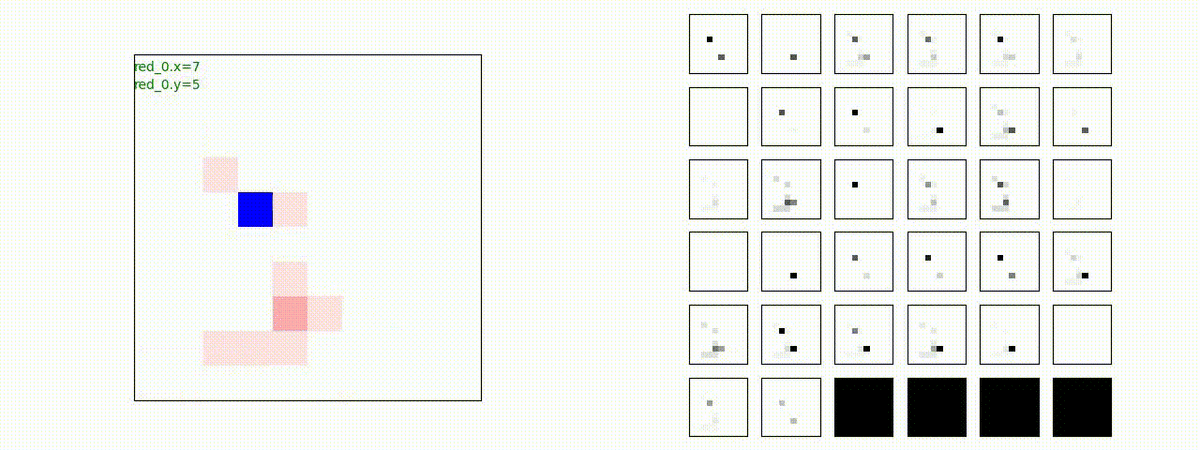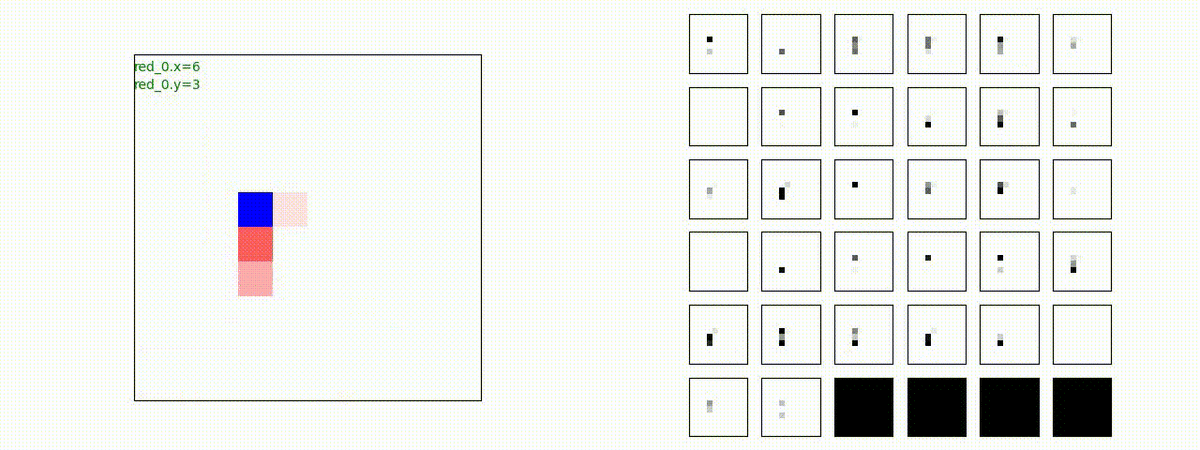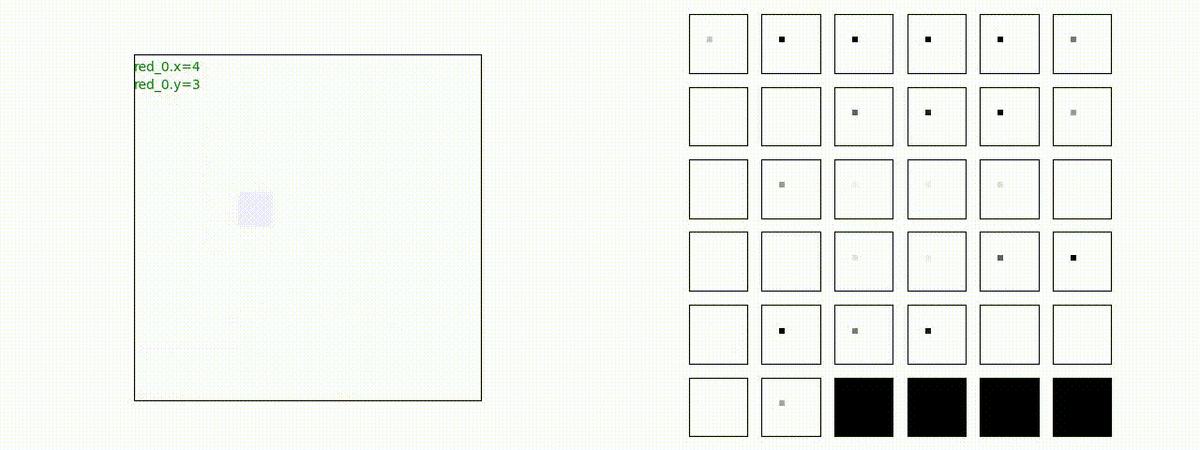
Red_team=10 swarms vs Blue_team=10 swarms
以下は、Red team が上手く戦い、Blue team を壊滅させた「レア」ケースです。
多くの場合、上手くは行かず、Red team のエージェントは、時間切れになるまで右往左往します。途中までは、上手く戦っているのに、途中から右往左往してしまいます。この段階で、Red team の戦闘力は、Blue team よりも高く、Red team = 2, Blue team=4 という戦闘様相になっているので戦えないことはないと思うのですが・・・。ここは、もう少し分析すると改善点がでてくる気がします。
Red team=1 swarm vs Blue tem=10 swarms
小分けになった Blue team を強大な Red team の swarm が順番に撃破していくケースで、「敵を撃破する」というコンセプトは、きちんと学習できていることを確認しました。
上記の両極端な例以外の戦闘様相における生成された戦術の例を以下に示しておきます。
Red team = 3 swarms vs Blue team = 3 swarms
これくらいの外挿は全く問題ありませんでした。
Red team = 5 swarms vs Blue team = 5 swarms
これくらいの戦闘様相までは、red teamのエージェントは、一つの "mass" となって戦うことができます。
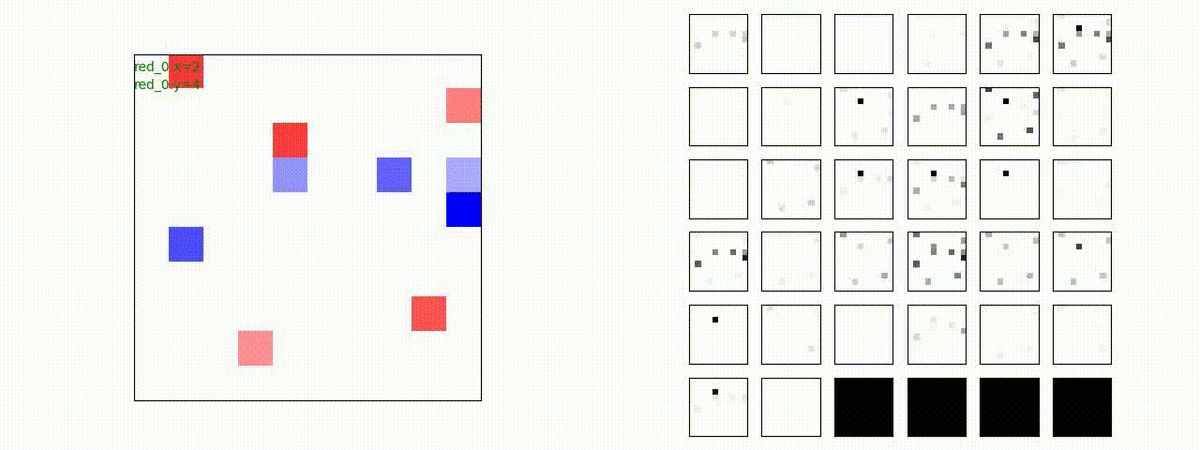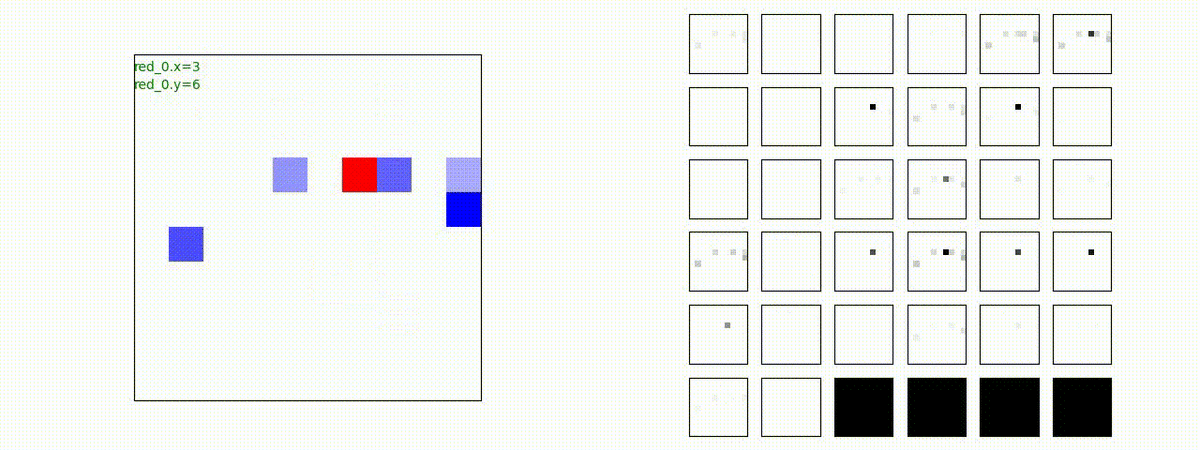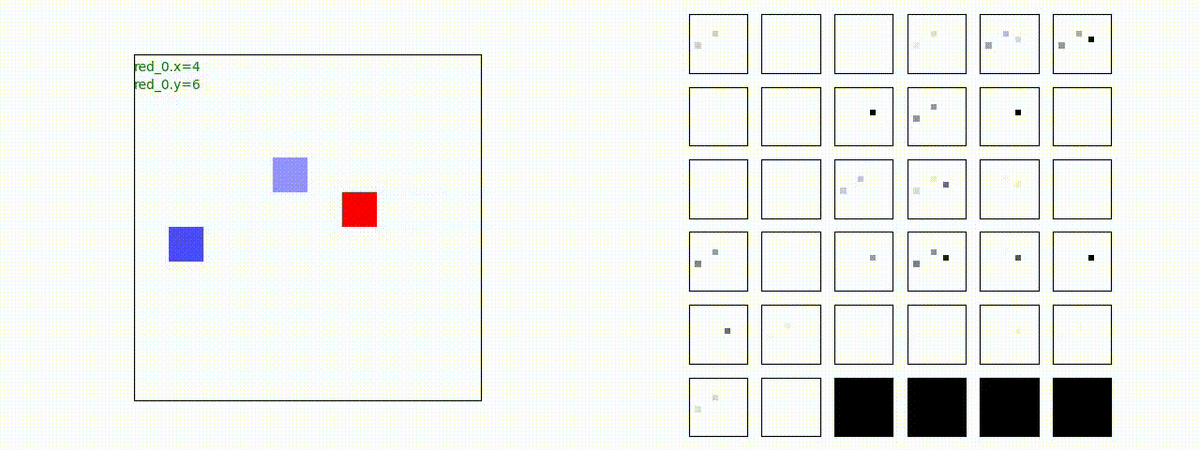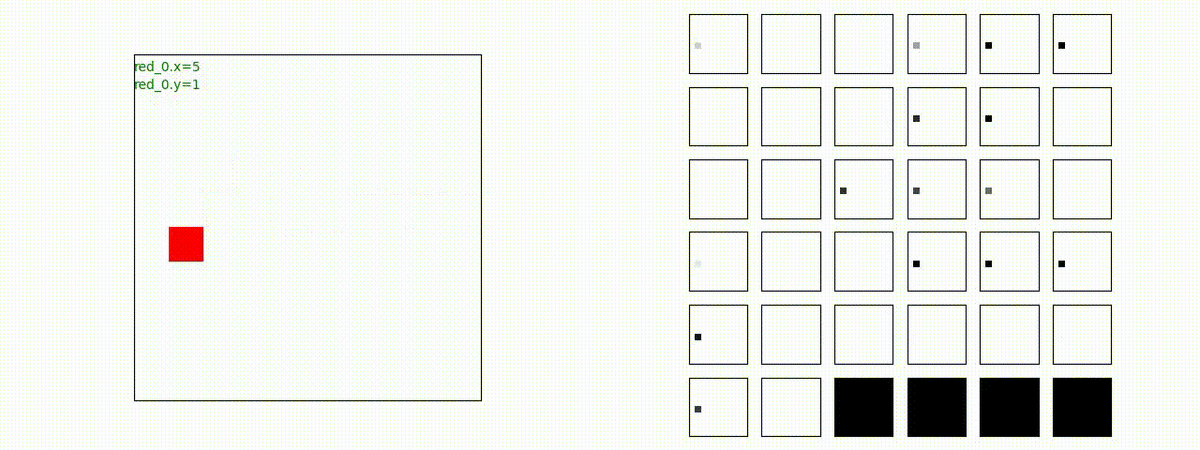
Red team = 8 swarms vs Blue team = 7 swarms
一つの mass とまでは行きませんが、上手く戦うことができます。初期マップで Red team が 7 エージェントになっていますが、これは同一マスに2エージェントが居るためです。
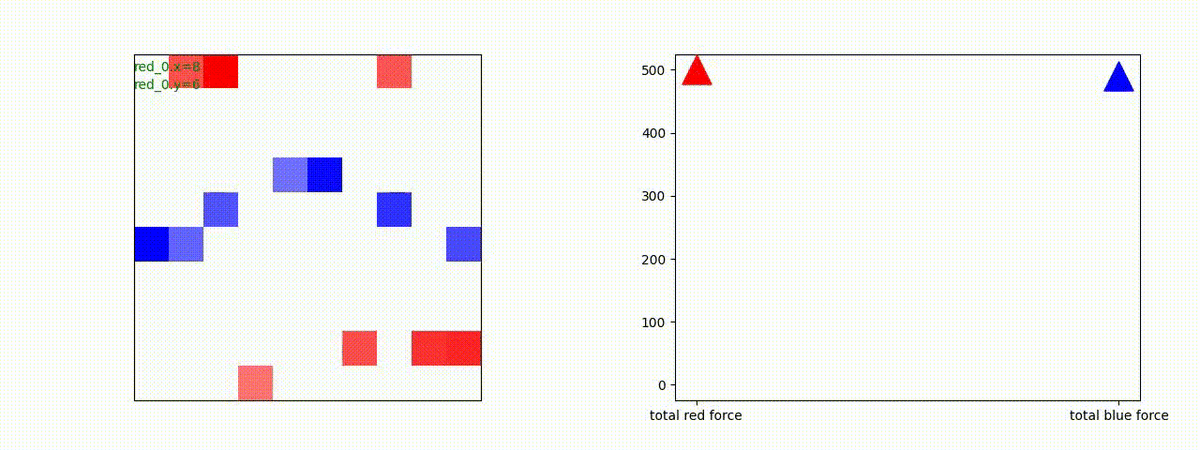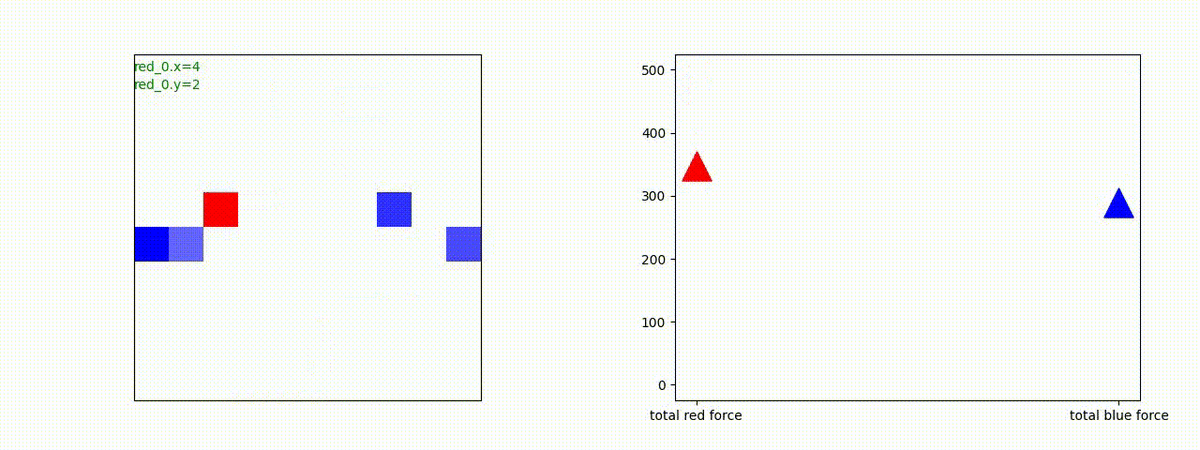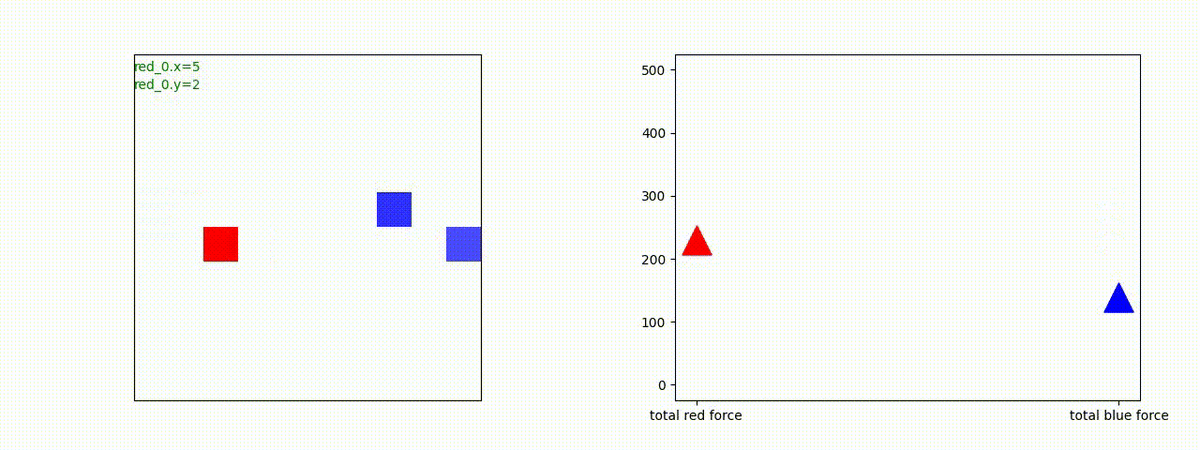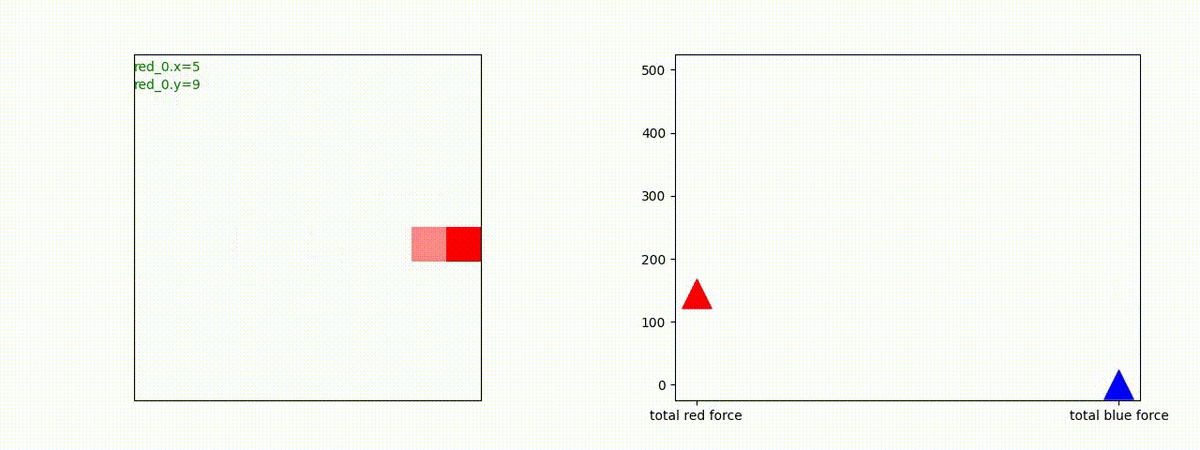
まとめ
- Red team の初期エージェント数(群数)を [1, 3]、Blue team の初期エージェント数(群数)を [1, 2] として、少数群 vs 少数群の設定でネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、"mass"を構成して戦う戦術を学習できていることが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を増やして(つまり、戦力を小分けにして散開させて)戦闘性能がどの程度劣化するのか見てみました。
- Red teamのエージェントは、彼我のエージェント数がトレーニング時の2倍強程度までの外挿であれば、問題なく "mass" を活かした戦術で戦うことができました。
- 「10 read team swarm vs 1 blue team swarm」のように、巨大な兵力の Blue team に対し、小分けされる方向に外挿された状況では、Red team のエージェントは、タイミングコントロールが後一歩及ばないため、”mass"を活かした戦術で戦うことができなくなりました。
- 「10 read team swarm vs 10 blue team swarm」のように、彼我のエージェント数がトレーニング時よりも遥かに増えると、Red team のエージェントは右往左往し始め、上手く戦うことができませんでした。
次回記事では、今回とは逆に、Red team, Blue team のトレーニングを多数群 vs 多数群で行い、少ないエージェント数に対するロバスト性(汎化能力)を図ってみたいと思います。
マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その2):まずはシンプルな問題を設定する
- Keyword
- GitHub Code
- 最初の一歩として、シンプルな問題を設定する
- 各エージェントの観測量(Observation)
- 各エージェントの報酬設計(マルチエージェント強化学習では、これが難しい)
- 各エージェントのアーキテクチャ
- まとめ
Keyword
Swarm, Company, Platoon, Autonomous, Mass, Consolidation of force, Economy of force, Multi-agent, Reinforcement learning, Lanchester combat model, DenseNet, ResNet, PPO
群、小隊、中隊
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
最初の一歩として、シンプルな問題を設定する
いきなり複雑な問題にあたる前に、まずはシンプルな問題設定で解いてみて、解決の見通しについて感触を得てみようと思います。このため、以下の仮定を置いて問題をシンプルにしました。なお、海兵隊の研究と同様に、我が Red team、彼が Blue team としています。
- 戦域は、10x10のグリッドとする。(少し小さいですが、海兵隊の研究も同サイズで実施していました)。
- Red team, Blue team の戦闘効率(Efficiency)は同じとする。また、戦闘における確率的要素はないものとします。したがって、兵力(Force、軍の構成メンバー数)のみが勝敗に影響することになります。
- 学習が上手くいけば必ず Red team が勝利できるよう、以下の兵力関係を仮定する(学習が上手く行くいったことが確認できるようにするための仮定です):
Red team の兵力の合計 > Blue teamの兵力の合計
- Blue team は静止しているものとします。
- 各エージェントの観測は、部分観測ではなく、マップ全体とします。(部分観測マルコフ過程になることを避けるための仮定です)。
- マップの情報は100%正確で、ノイズは無いものとします。
- 環境は均一で、障害物などは無いものとします。
- 全エージェントは、同一のニューラルネット・アーキテクチャと重みを共有するものとします。それでも、各エージェントに与えるマップ情報が異なる(自群位置が異なる)ので、エージェントは異なった行動を示すことになります。さらに、今回は、自身の特徴量(ForceとEfficiency)もマップでそれぞれ与えているため、仮に同じ位置に複数のエージェントが位置しても、エージェント毎に異なる振る舞いをすることになります。つまり、エージェントは、構造的には互いに均質(Homogeneous)ですが、性格的には異質(Heterogeneous)なものとなります。
その他:
- 1回のタイムステップでの経過時間は1とする。つまり、Lanchester model の Δt=1 です。(この場合、微分方程式では近似できません)。
- シミュレーションの最大ステップ数=100。最大ステップに達した段階で勝負がついていなければ、戦闘結果はドローで打ち切ります。
各エージェントの観測量(Observation)
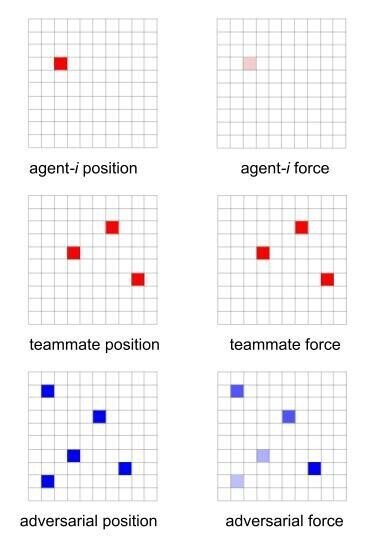
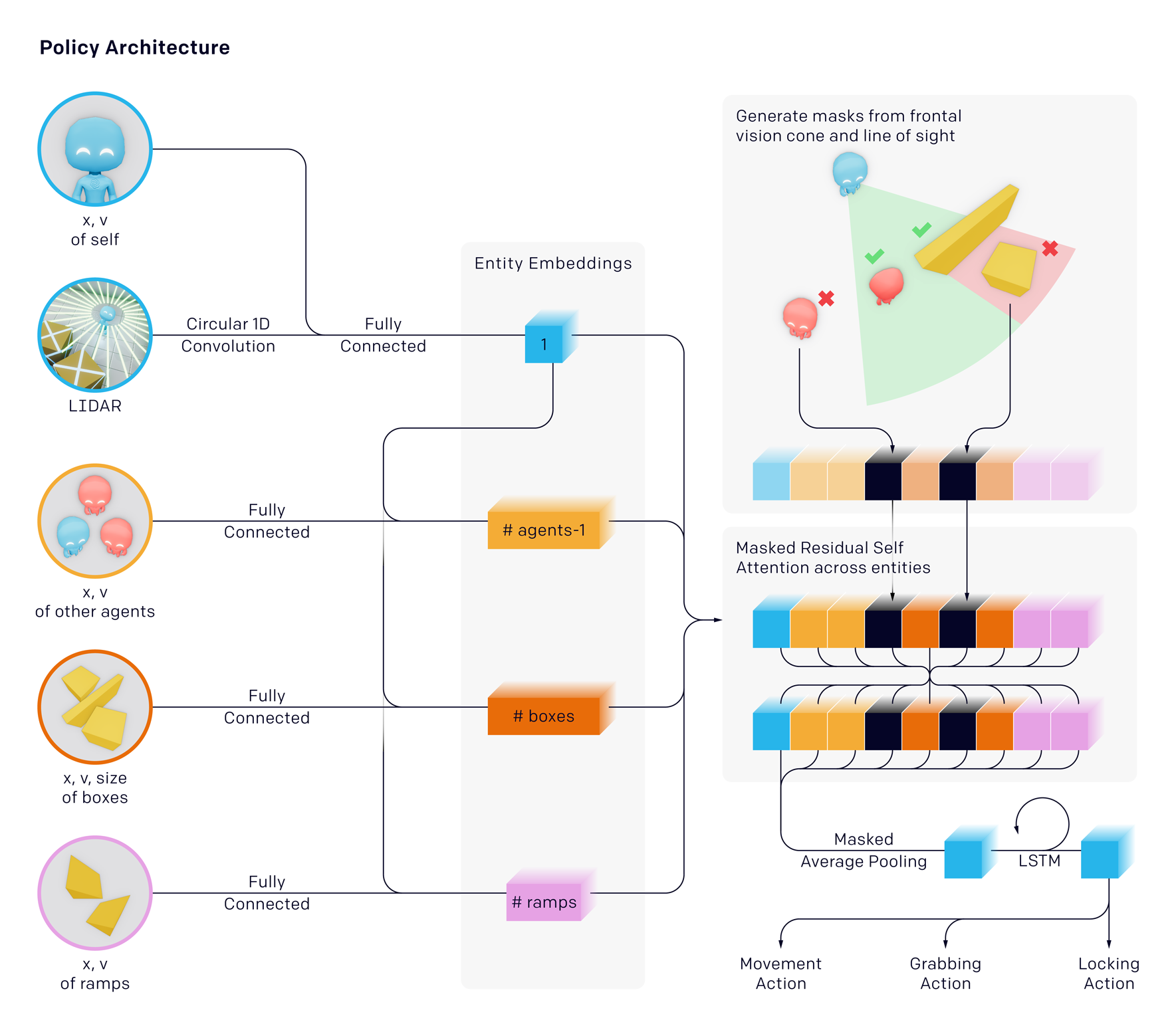
各エージェントのObservationは、シンプルに以下の6マップとします。
- 自群位置、自群兵力(Force)
- 友群位置、友群兵力(Force)
- 敵群位置、敵群兵力(Force)
彼我の群の戦闘効率はすべて同じなので、戦闘効率のマップは不要と考え省略します。障害物などは何もない環境なので、環境マップも不要と考え省略します。
従って、各タイム・ステップでエージェントに与えられる情報は下図の6チャンネルとなります。位置のマップについては、同一マスに複数エージェントがいる場合、以下の式で [0,1] の範囲になるように正規化しました:
position map =
そのマスにいるエージェントの数 / 現在のエージェント総数
同様に、兵力(Force)も、[0, 1] の範囲になるように正規化しました:
force map =
そのマスにいるエージェントのforce合計 / 全エージェントの初期兵力(Force)
これは、コードで書くと以下となります。Observationは、エージェント毎に辞書として定義しています。
def get_observation_5(env):
observation = {}
for i in range(env.num_red):
if env.red.alive[i]:
my_matrix = np.zeros((env.grid_size, env.grid_size))
teammate_matrix = np.zeros((env.grid_size, env.grid_size))
adversarial_matrix = np.zeros((env.grid_size, env.grid_size))
my_matrix_pos = np.zeros((env.grid_size, env.grid_size))
teammate_matrix_pos = np.zeros((env.grid_size, env.grid_size))
adversarial_matrix_pos = np.zeros((env.grid_size, env.grid_size))
# my position & force map
my_matrix_pos[env.red.pos[i][0], env.red.pos[i][1]] += 1
my_matrix[env.red.pos[i][0], env.red.pos[i][1]] += env.red.force[i]
# teammate position & force map
teammate_id = [j for j in range(env.num_red) if j != i]
for j in teammate_id:
if env.red.alive[j]:
teammate_matrix_pos[env.red.pos[j][0], env.red.pos[j][1]] += 1
teammate_matrix[env.red.pos[j][0], env.red.pos[j][1]] += env.red.force[j]
# Don't care because env.red.force[j]=0 if not env.red.alive[j]
# adversarial position & force map
for j in range(env.num_blue):
if env.blue.alive[j]:
adversarial_matrix_pos[env.blue.pos[j][0], env.blue.pos[j][1]] += 1
adversarial_matrix[env.blue.pos[j][0], env.blue.pos[j][1]] += env.blue.force[j]
# Don't care because env.blue.force[j]=0 if not env.blue.alive[j]
# stack the maps
my_matrix_pos = np.expand_dims(my_matrix_pos, axis=2)
my_matrix = np.expand_dims(my_matrix, axis=2)
teammate_matrix_pos = np.expand_dims(teammate_matrix_pos, axis=2)
teammate_matrix = np.expand_dims(teammate_matrix, axis=2)
adversarial_matrix_pos = np.expand_dims(adversarial_matrix_pos, axis=2)
adversarial_matrix = np.expand_dims(adversarial_matrix, axis=2)
# normalize the maps
my_matrix = my_matrix / env.max_force
teammate_matrix = teammate_matrix / env.max_force
adversarial_matrix = adversarial_matrix / env.max_force
# Normalize teammate_matrix_pos & adversarial_matrix_pos by current number of agents
teammate_matrix_pos = teammate_matrix_pos / np.sum(env.red.alive)
adversarial_matrix_pos = adversarial_matrix_pos / np.sum(env.blue.alive)
obs = np.concatenate([my_matrix_pos, my_matrix,
teammate_matrix_pos, teammate_matrix,
adversarial_matrix_pos, adversarial_matrix], axis=-1)
observation['red_' + str(i)] = obs.astype(np.float32)
return observation
各エージェントの報酬設計(マルチエージェント強化学習では、これが難しい)
マルチエージェント強化学習で難しいのは、エージェントに与える報酬設計です。
例えば、red team は (490, 20) という兵力を有する2エージェント(2群)で構成され、Blue team は 500 の兵力を有する1エージェントで構成されている初期条件を考えます。(彼我の群の戦闘効率は同じとします)。
この時、Lanchester model によれば、red team が勝つためには、兵力20の群が、兵力490 の群と一丸になって(つまり、510 の兵力となって)blue teamに当たることが必須です。しかしながら、兵力 20 の群は弱小なので戦いの途中で消耗し殲滅されてしまいます。この場合、通常の強化学習の枠組みでは、ゲームの勝敗に応じて報酬が与えられるため、兵力 20 の群には、負の報酬(ペナルティ)が与えられることになります。この結果、小さな兵力の群は戦闘に参加しない方向に学習してしまいます。しかし、実際には、チームの勝利のためには、この小さな群の犠牲が必須なので、正の報酬(ご褒美)を与える必要があります。多数エージェントと多数エージェントが、戦域のあちらこちらで戦闘する場合、話はもっと複雑になるので、いつ正の報酬を与え、いつ負の報酬を与えればよいのか訳が分からなくなります。このため、マルチエージェント強化学習では、普通の強化学習以上に、報酬設計を考える必要があります。
色々と試行錯誤して、戦闘の勝敗で報酬を与えるのではなく、大きな敵の "mass" に、大きな "mass" でぶつかった場合に、その "mass" の大きさに応じて報酬を与えることにしました。これは、前記の海兵隊の研究、海兵隊教本(MCDP "1-0 Operations")、ランチェスター・モデルの分割戦略から試行錯誤で考案しました。背景にあるアイデアは、「確率的要因が無い場合、勝敗の結果は、戦闘が行われているグリッドでの彼我の "mass" のサイズで決まる(戦う前に勝負は決まっている)」です。
具体的には、タイムステップ t で、以下の式でグリッド (i, j) に位置するRed teamエージェントに報酬を与えました。"*100"は、報酬の大きさが適当になるように設定した係数です。(もう少し、小さいほうが良かったかもしれません)。
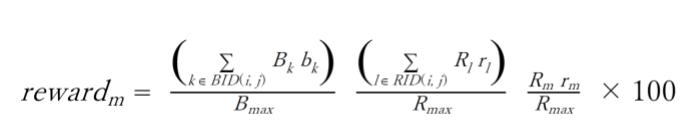
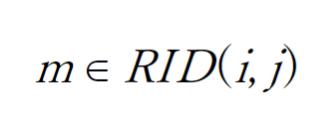
where
- BID(i, j):グリッド (i, j) に位置する Blue team のエージェントの ID
- RID(i, j):グリッド (i, j) に位置する Red team のエージェントの ID
- Bk: Blue team のエージェント k の force
- bk: Blue team のエージェント k の efficiency
- Rl: Red team のエージェント l の force
- rl: Red team のエージェント l の efficiency
- Bmax: Blue team のエージェントの初期 force の合計
- Rmax: Red team のエージェントの初期 force の合計
上式右辺で、
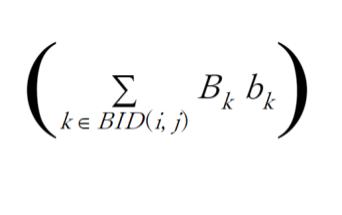
が、グリッド (i, j) に位置する Blue team エージェントの戦闘力('mass')= 兵力 x 武器性能 = force x efficiency の合計、
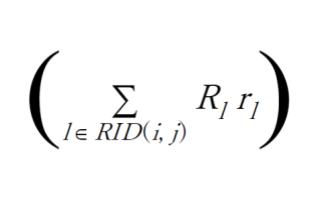
が、グリッド (i, j) に位置する Red team エージェント 闘力('mass')= 兵力 x 武器性能 = force x efficiency の合計に対応します。また、戦闘に参加したエージェントへの報酬配分は、
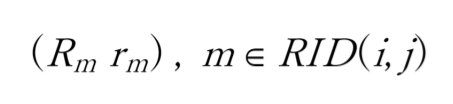
に従って与えます。これは、グリッド (i, j) での戦闘に参加した Red team エージェントの戦闘力 ('mass')に比例して報酬配分していることになります。したがって、大きな 戦闘力('mass') を提供するエージェントほど大きな報酬を受け取りますが、小さな戦闘力('mass')しか提供しないエージェントでも、戦闘力を提供する限りは応分の報酬を受け取ることになります。
あるグリッドにおけるチーム戦闘という観点でこの報酬を見ると、1つのグリッドに沢山のエージェントが集まって、強力な敵に当たり続けるほど大きな報酬を受け取ることになります。つまり、'mass' を重視し、(重要と思われる) 'mass' の大きな敵に当たる戦術を採るほど大きなチーム報酬を得ることになります。
また、戦闘の勝敗を報酬として与えた場合、1エピソードの最後に1回だけ報酬を与えることになりますが、この報酬は、各タイムステップで与えることが出来ます。従って、学習効率の向上も期待できます。
前記の海兵隊の研究でも、(少し違う形ですが)同じような考え方で報酬を与えた場合を検討していました。
また、戦闘を長引かせないインセンティブを各エージェントに与えるために、上記の報酬に加えて、各タイムステップで、全エージェントに -0.1 のペナルティ(負の報酬)を追加で与えました。
一方、チームとしての勝敗結果についての報酬ですが、チームとしての勝敗は各タイムステップでの戦闘力の大小で決定論的に決まるので、チームとしての勝敗結果についての報酬は与える必要が無いと考えました。
以上から、Red team全体としては、次の目的函数を最大化するようにトレーニングされることになります。E[・] は期待値(Expectation)です。
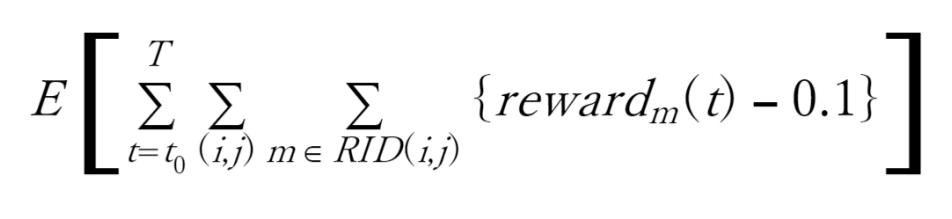
或いは、将来の曖昧さを割引率γで考慮した次の目的函数を最大化するようにトレーニングされることになります。
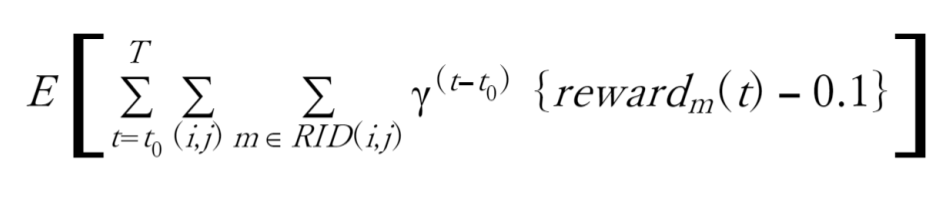
これをコード化した報酬が下記のコードです。
戦闘に参画している限り、提供できる戦闘力がどんなに少なくても最低 1.1 の報酬を与えることにしました(試行錯誤で決めました)。
def get_reward_8C(env, red_team_force, previous_red_team_force, blue_team_force, previous_blue_team_force,
red_team_efficiency, blue_team_efficiency):
# 8Bの足切り 0.5 → 1.1
blue_size = np.sum(previous_blue_team_force * blue_team_efficiency)
red_size = np.sum(previous_red_team_force * red_team_efficiency)
red_reward = (blue_size / env.blue_max_force) * (red_size / env.red_max_force) \
* (previous_red_team_force * red_team_efficiency) / env.red_max_force * 100
# red_reward = (blue_size / env.blue_max_force) * (red_size / env.red_max_force) \
# * (previous_red_team_force * red_team_efficiency) / env.red_max_force * 100 * 3
# red_reward = np.maximum(red_reward, 0.1 / env.dt * 0.5)
red_reward = np.maximum(red_reward, 1.1)
return red_reward
各エージェントのアーキテクチャ
グリッド状のゲームの代表例は、囲碁、将棋、チェスです。これらを統一的に取り扱ったのが有名な AlphaZero や MuZero です。これらでは、MCTS(モンテカルロ木探索)とニューラ ルネットを組み合わせて盤面から状況を認識し、行動決定しています。盤面を認識するニューラルネットには、ResNet(をベースとしたもの)が用いられています。DeepMind は、ResNet が好きなようで、AlphaStar でも使っています。
画像の認識では、ResNet は確かに重要な一つの選択肢なのですが、本件では、多数の異なるマップとしての画像を取り扱うので、CVPR-2017 で Best paper award を取った DenseNet の方が適当と考え、使ってみることとしました。とは言え、本件はチェスと考え方は似ているので、ResNet も実装して、比較してみる必要があると思います。ただ、DenseNet も ResNet もオリジナルはとても深いネットワークなので、私のビンテージマシンを使って強化学習で最適化するには、かなり浅めのネットワークにする必要があります。したがって、正しい比較のためには、それぞれを最適化したうえで比較しないと意味がないので、計算リソースに余裕がない私としては見送らざるを得ませんでした。(学習済みの DenseNet や ResNet を転移させる方法もあるのですが、マップサイズを(224, 224, 3)等の特定のサイズに変換する必要があるため、不整合が起きそうな気がしたので今回は使用しませんでした)。
また、人間は、行動を考えるにあたって、与えられたマップを統合したり、新たなマップを作成するのが普通です。この働きをさせるために、入力マップと DenseNet の間に 1x1 Convolution 層を挿入しました。(オリジナルの DenseNet では、ここは MaxPooling を使っています。リソースが無いので、オリジナルとの比較はしていません。ゴメンナサイ)。これにより、入力された6枚のマップ(チャネル)から、同じサイズの多数(とりあえず32枚と設定しました。根拠はありません)のマップ(チャネル)を生成し ResNet に入力することとしました。ここで、どのようなマップが自動生成されるのかは非常に興味があります。
AlphaZero や MuZero では、過去数手の盤面も入力としていますが、さしあたっては、問題がシンプルなので、現在の状態を示すマップのみの入力でそれなりに行けるはずと考え、履歴情報の入力は無いものとしました。他エージェントの意図を察するためには、他エージェントの動きの履歴(= 過去の盤面)が必要なので、履歴情報を使うことで性能が向上する可能性はあると思っています。あるいは、network をリカレント型にしたり、Transformer 形にしたりしてシーケンス・データを取り扱うことで、履歴情報をエージェントの内部に埋め込む方法もあります。これらの方法は非常に興味深いのですが、一般的には、性能向上と引き換えに学習時間が猛烈に増大するので、後回しにしました。
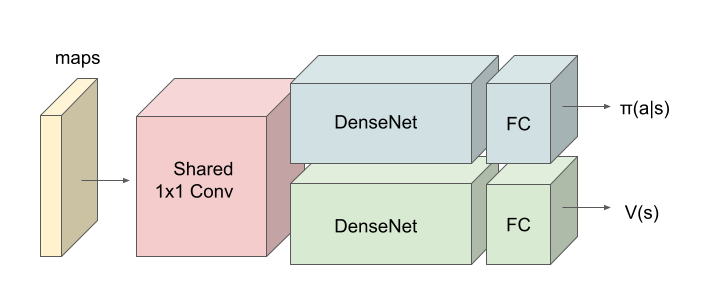
以上を踏まえ、最初の一歩の Agent Architecture は下図としました。1x1 Convolution 以外は、Policy network と Value network の重み共有はしない形としました。一般論としては、「Policy network と Value network は、一部重み共有した方が汎化能力が高くなる」と、どこかで読んだことがあるのですが、何処まで共有するのかという問題があるので、まずはシンプルな設定として極端な形でやってみることにしました。FC は全結合(Full Connection)層、π(a|s) はポリシー出力(アクション)、v(s) は value 出力を表します。
アーキテクチャの意図は、Shared 1x1 Conv から DenseNet までが「戦況の認知系」、DenseNet 出力が、エージェントが認知した戦況全体(Big picture)や、その中で自分が置かれた状況等の「戦況コンテキスト(Context)が集約された表現(Representation)」、FCが戦況コンテキストからアクションを生成する「行動決定系」です。また、価値函数V(s)は、「現在の戦況 s の良し悪しの程度」の推定値、π(a|s) は現在の戦況 s におけるエージェントの行動選択確率です。
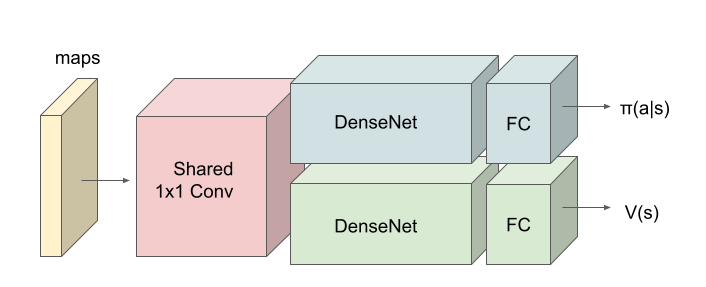
具体的には、エージェントは次のアーキテクチャとしています。問題に対して、ネットが深すぎるような気はしたのですが、将来、マップサイズを大きくすることも想定して、深めに設定しました。
DenseNet のブロック数、成長率(Growth factor)、圧縮率(Compression factor)、フィルタ数等のハイパラは気分だけで決めました。したがって、最適化の余地は多分にあります。
最下段にある Dense 層は全結合(FC)層のことです。(Tensorflow では、全結合層を Dense layer と呼んでいます。DenseNet のことではありませんので、混同しないでください)。
また、最下段の全結合層(Dense 層)の前で、普通は画像から Flatten( ) で、チャンネル内の個々の画像を1次元アレイに変換することが多いのですが、DenseNet では、GlobalAberagePooling2D( ) で1次元アレイに変換します。これは、DenseNet では、チャンネル単位で積層するため、ここもチャンネル毎のサマリーを取得するのが適当との考え方に依ります。実際には、 Flatten( ) の方が良いのか、GlobalAberagePooling2D( ) の方が良いのかはやって見ないと分かりません。これは性能に対しインパクトがありそうなのですが、確認に時間がかかるので省略しました。
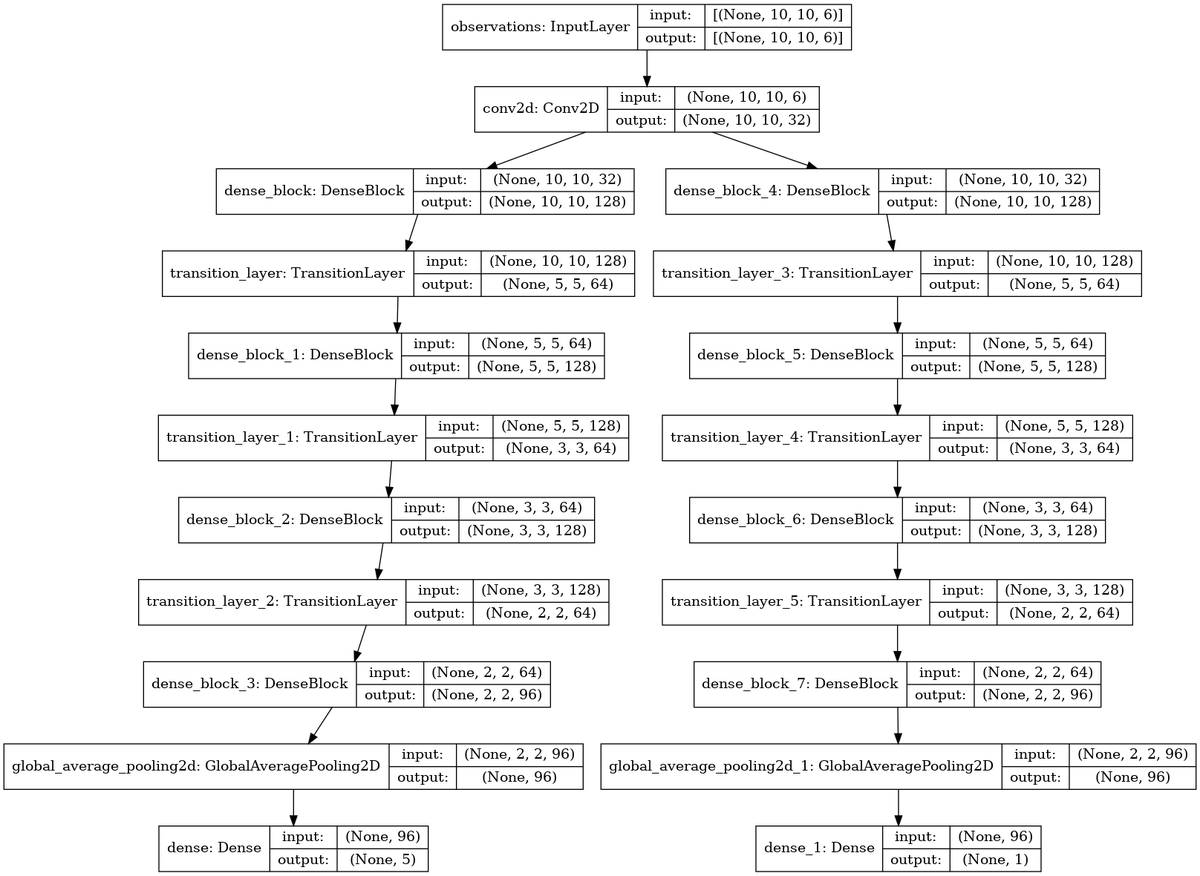
トレーニング可能なパラメータ数は、798,118です。
以上は、コードで書くと下記となります。DenseNet の構成要素となる Dense ブロック、Transition 層は、適当に設定しました(最適化は、全くしていません)。
コーディングは、
Custom DenseNet of Tensorflow2.0 - Programmer Sought を参考にしました。
Bottleneck 層は、基本ブロックで、特徴量マップを追加します。
class Bottleneck(Model):
def __init__(self, growth_facotr, drop_rate):
super(Bottleneck, self).__init__()
self.bn1 = BatchNormalization()
self.av1 = Activation('relu')
self.conv1 = Conv2D(filters=4 * growth_facotr,
kernel_size=(1, 1),
strides=1,
padding='same')
self.bn2 = BatchNormalization()
self.av2 = Activation('relu')
self.conv2 = Conv2D(filters=growth_facotr,
kernel_size=(3, 3),
strides=1,
padding='same')
self.dropout = Dropout(rate=drop_rate)
self.list_layers = [self.bn1,
self.av1,
self.conv1,
self.bn2,
self.av2,
self.conv2,
self.dropout]
def call(self, x):
y = x
for layer in self.list_layers:
y = layer(y)
y = Concatenate(axis=-1)([x, y])
return y
DenseBlock 層は、基本ブロックである Bottleneck を積層したものです。
class DenseBlock(Model):
def __init__(self, num_layers, growth_factor, drop_rate):
super(DenseBlock, self).__init__()
self.num_layers = num_layers
self.growth_factor = growth_factor
self.drop_rate = drop_rate
self.list_layers = []
for _ in range(num_layers):
self.list_layers.append(Bottleneck(growth_facotr=self.growth_factor,
drop_rate=self.drop_rate))
def call(self, x):
for layer in self.list_layers:
x = layer(x)
return x
Transition 層は、チャネル数とマップサイズを圧縮する層です。
class TransitionLayer(Model):
def __init__(self, out_channels):
super(TransitionLayer, self).__init__()
self.bn = BatchNormalization()
self.av = Activation('relu')
self.conv = Conv2D(filters=out_channels,
kernel_size=(1, 1),
strides=1,
padding='same')
self.avgpool = AveragePooling2D(pool_size=(2, 2),
strides=2,
padding='same')
self.list_layers = [self.bn,
self.av,
self.conv,
self.avgpool]
def call(self, x):
for layer in self.list_layers:
x = layer(x)
return x
DenseNet 本体です。DenseNetは、DenseBlock と Transition 層を交互に積層したものですので、特徴量マップを追加し圧縮する作業を繰り返します。最後に、GlobalAveragePooling2D で各特徴量マップを代表させます。この代表特徴量から、全結合層を通してポリシー π(a|s) と価値函数 V(s) を予測します。
class DenseNetModel(TFModelV2):
def __init__(self, obs_space, action_space, num_outputs, Model_config, name):
super(DenseNetModel, self).__init__(obs_space, action_space, num_outputs, Model_config, name)
num_init_features = 16
growth_factor = 16
block_layers = [2, 2, 2, 1]
compression_factor = 0.5
drop_rate = 0.2
# First convolutin + batch normalization + pooling
self.conv = Conv2D(filters=num_init_features,
kernel_size=(1, 1),
strides=1,
padding='same')
### Policy net
# DenseBlock 1
self.pol_num_channels = num_init_features
self.pol_dense_block_1 = DenseBlock(num_layers=block_layers[0],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 1
self.pol_num_channels += growth_factor * block_layers[0]
self.pol_num_channels *= compression_factor
self.pol_transition_1 = TransitionLayer(out_channels=int(self.pol_num_channels))
# DenseBlock 2
self.pol_dense_block_2 = DenseBlock(num_layers=block_layers[1],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 2
self.pol_num_channels += growth_factor * block_layers[1]
self.pol_num_channels *= compression_factor
self.pol_transition_2 = TransitionLayer(out_channels=int(self.pol_num_channels))
# DenseBlock 3
self.pol_dense_block_3 = DenseBlock(num_layers=block_layers[2],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 3
self.pol_num_channels += growth_factor * block_layers[2]
self.pol_num_channels *= compression_factor
self.pol_transition_3 = TransitionLayer(out_channels=int(self.pol_num_channels))
# Dense Block 4
self.pol_dense_block_4 = DenseBlock(num_layers=block_layers[3],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Output global_average_pooling + full_connection
self.pol_avgpool = GlobalAveragePooling2D()
self.pol_fc = Dense(units=5, activation=None)
# Define policy model
inputs = Input(shape=obs_space.shape, name='observations')
conv1_out = self.conv(inputs)
x = self.pol_dense_block_1(conv1_out)
x = self.pol_transition_1(x)
# x = self.pol_dense_block_2(x)
# x = self.pol_transition_2(x)
# x = self.pol_dense_block_3(x)
# x = self.pol_transition_3(x)
x = self.pol_dense_block_4(x)
x = self.pol_avgpool(x)
pol_out = self.pol_fc(x) # (None, 5)
### Value net
# DenseBlock 1
self.val_num_channels = num_init_features
self.val_dense_block_1 = DenseBlock(num_layers=block_layers[0],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 1
self.val_num_channels += growth_factor * block_layers[0]
self.val_num_channels *= compression_factor
self.val_transition_1 = TransitionLayer(out_channels=int(self.val_num_channels))
# DenseBlock 2
self.val_dense_block_2 = DenseBlock(num_layers=block_layers[1],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 2
self.val_num_channels += growth_factor * block_layers[1]
self.val_num_channels *= compression_factor
self.val_transition_2 = TransitionLayer(out_channels=int(self.val_num_channels))
# DenseBlock 3
self.val_dense_block_3 = DenseBlock(num_layers=block_layers[2],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Transition Layer 3
self.val_num_channels += growth_factor * block_layers[2]
self.val_num_channels *= compression_factor
self.val_transition_3 = TransitionLayer(out_channels=int(self.val_num_channels))
# Dense Block 4
self.val_dense_block_4 = DenseBlock(num_layers=block_layers[3],
growth_factor=growth_factor,
drop_rate=drop_rate)
# Output global_average_pooling + full_connection
self.val_avgpool = GlobalAveragePooling2D()
self.val_fc = Dense(units=1, activation=None)
# Define value model
y = self.val_dense_block_1(conv1_out)
y = self.val_transition_1(y)
# y = self.val_dense_block_2(y)
# y = self.val_transition_2(y)
# y = self.val_dense_block_3(y)
# y = self.val_transition_3(y)
y = self.val_dense_block_4(y)
y = self.val_avgpool(y)
val_out = self.val_fc(y) # (None, 1)
self.base_model = Model(inputs, [pol_out, val_out])
self.register_variables(self.base_model.variables)
def forward(self, input_dict, state, seq_lens):
obs = input_dict['obs']
model_out, self._value_out = self.base_model(obs) # (None,5), (None,1)
return model_out, state
def value_function(self):
return tf.reshape(self._value_out, [-1])
まとめ
手始めに解いてみて感触を得るのに手ごろな問題を設定し、報酬やエージェント・アーキテクチャを設計しました。
次回は、マルチエージェント強化学習を行って性能確認します。
マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その1):はじめに
追記@2021.10.08を書いた時に、なぜかフォーマットが乱れていました。修正しました。ゴメンナサイ
- はじめに
- (マルチエージェント)強化学習の研究例
- 研究の目的
- 群 vs 群の戦闘モデル(ランチェスター・戦闘モデル)
- 使用するマルチエージェント強化学習
- まとめ
- 追記 @2021.10.08
- 追記 @2023.03.04
Keyword
Swarm, Company, Platoon, Autonomous, Mass, Consolidation of force, Economy of force, Multi-agent, Reinforcement learning, Lanchester combat model, DenseNet, ResNet, PPO
群、小隊、中隊、兵力、戦闘効率、マルチエージェント強化学習、自律システム
はじめに
未来の戦闘では、多数のロボットやドローン等が中隊や小隊といったひとまとまりの「群(swarm)」を構成し、さらに複数の群が戦域の複数ヶ所に散開して、何らかの戦略や戦術に従って自律的に協調行動することが期待されます。 ここで、「自律的」とは、上位組織から指示されることなく自らの決心で行動することを意味しています。(より正確には、「自らのセンサで情報を収集する」ことも含むべきですが、問題を簡単にするために、しばらくの間はこの仮定は外しています)。
本記事では、これらの戦場に散開した自律的な中隊や小隊レベルの「複数群 vs 複数群」の戦闘を考え、マルチエージェント強化学習を使って効果的な「自律群間の協調戦闘戦術」を生成することを試みます。もう少し軍隊風に言えば、敵を殲滅するために、戦域に展開した自律的な中隊や小隊の動き方を生成することを試みます。マルチエージェントの枠組みで考えますので、戦術を中隊や小隊に与えて、それに従って動かすのではなく、中隊や小隊が自律的に決心した結果として戦術が創発します。
実際には、群の行動を実現するためには、群を構成する個々のメンバー(ロボットやドローン)の行動設計も必要となりますが、ここではそこには踏み込みません。群の構成メンバーは、群の決心に従って自律的に動くことを仮定しています。(これについては、複雑系の観点からのアプローチとしては、群を構成する個々のドローンに Boids と Subsumption architecture の技術を適用して、指示通りに群全体を動かす "Search and rescue with autonomous flying robots through behavior-based cooperative intelligence" 等が参考になるものと考えます。また、強化学習を使った、Guided Deep Reinforcement Learning for Swarm Systems等のアプローチも参考になるものと思います)。
追記2020.10.9: DARPAのOFFSET(Offensive Swarm-Enabled Tactics)プログラムでも似たことをやっていて、Northrop Grammanによる実証実験が間もなく行われるようです。ワクワクします。
(マルチエージェント)強化学習の研究例
マルチエージェント強化学習は、学習が困難なことで知られています。その原因の一つは、同じ環境で他のエージェントも学習しているため、環境が非定常になることです。このため、COMA (2017), MADDPG (2018), QMIX (2018) 等のかなり凝った手法が提案されていますが、未だ決定打ではないと感じています(個人の感想です)。
一方、力づくで、多数のエンティティ(ここでは登場者)を扱った強化学習の研究としては、RTS(Real Time Simulation) ゲームを対象とした Alpha Star (DeepMind, 2019), Dota II (OpenAI, 2019), Hide & Seek (OpenAI, 2019) 等が有名です。これらは、いずれも初見でかなりの衝撃を覚えましたが、とにかく力ずくなので、残念ながら趣味でちょっと実装してみるというレベルのコードやトレーニング用ハードウェア構成ではありません。Google や OpenAI レベルのリソースが必要です。ただ、いずれも優れたアイデアが満載ですので、とても参考になりました。
AlphaStar では、中央制御によるプランニングにより、多数のエンティティをコントロールして、RTS ゲームの長期に渡る複雑なプランニングを強化学習しています。その結果、プロのゲーマを上回る性能を達成しました。(この研究では、リーグ戦方式の対戦で強化学習することをマルチエージェント強化学習と呼んでいるので、普通のマルチエージェント強化学習とはイメージが異なります。)
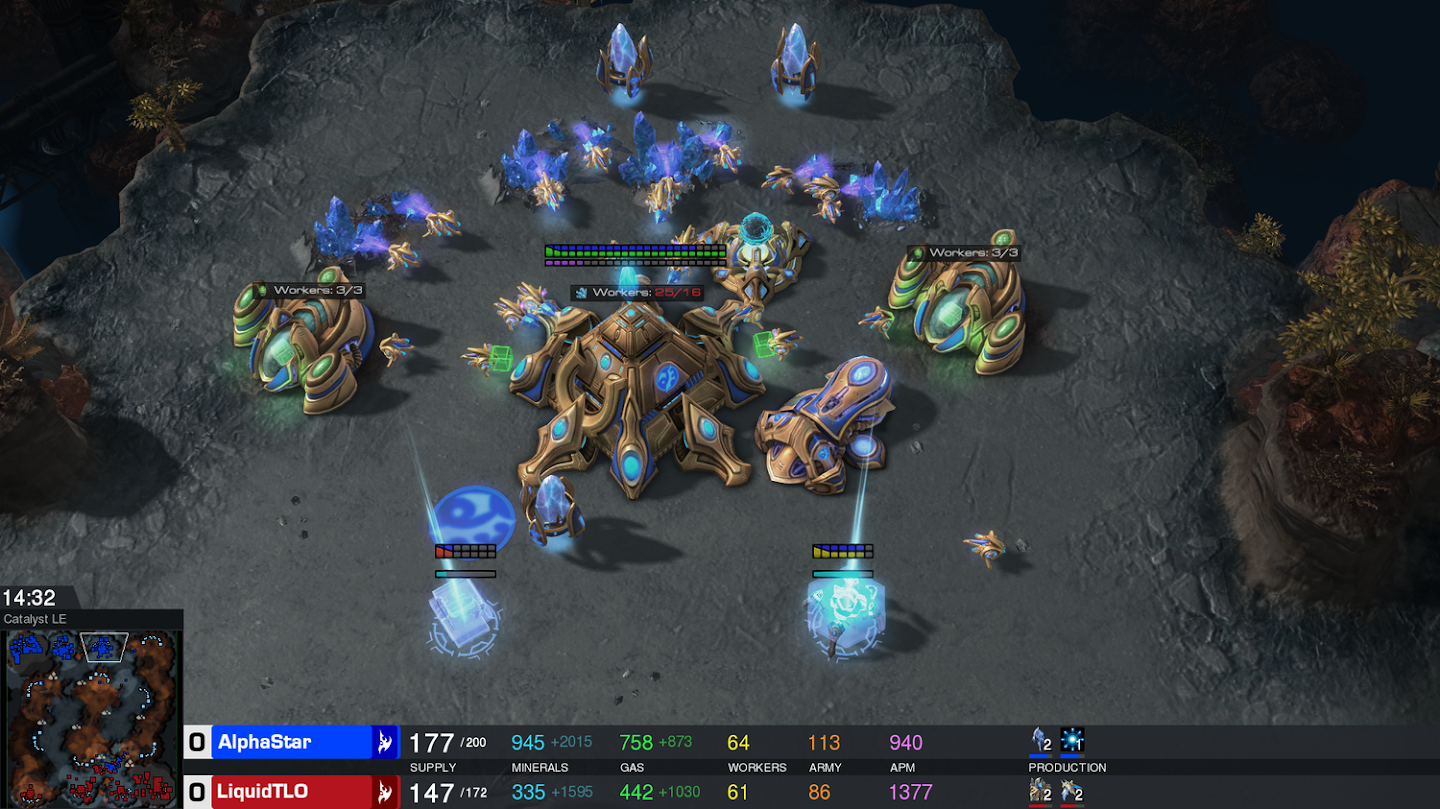
Dota IIでは、5つのキャラクター(エージェント)を選択し、これらのエージェントをマルチエージェント強化学習することで、ゲーマーのグランドマスター・レベルの性能を達成しています。学習にはDPPO(Distributed PPO)を使っています。実験では、5つのAI vs 5つのAI, 5つのAI vs 5人のゲーマー、AIとゲーマーの混合チーム vs AIとゲーマーの混合チームの対戦を行っています。興味深いのは、 AIとゲーマーの混合チームの対戦において、ゲーマーが「AIの方が人間よりも協力的だった」とコメントしていることです。

Hide and Seekでは、任意のマップにおける複数の自律エージェントの協調制御をマルチエージェント強化学習しています。これも学習にはDPPO(Distributed PPO)を使っています。これはエージェントがとてもキュートです。エージェントのアーキテクチャには、Transformer ですっかり有名になったアテンション機構が空間的に使われていて勉強になりました。ただし、エージェント数は 2 vs 2 なので、多数とまでは言えません。
これらの華やかな成果を受けて、遅まきながら諸外国の軍関連の機関でも強化学習の応用研究が進められています。(マルチエージェント強化学習の応用研究は、軍事ではまだ見たことがありませんが、きっとやっていると思います)。
複数エンティティによる戦闘プランニングを強化学習した研究には、ランド研究所の "Air Dominance Through Machine earning: A Preliminary Exploration of Artificial Intelligence–Assisted Mission Planning" (機械学習による航空支配), 2020 が挙げられます。これについては、実装も含めて下記記事として纏めています。この研究自体の方向性は AlphaStar に近いもので、中央集権的なエージェントによる複数エンティティのプランニングになっています。軍事では、任意数のエンティティを取り扱えることは重要です。このレポート自体は任意数のエンティティを取り扱うものではありませんが、将来研究の項で、戦場をグリッドに分割し、任意数のエンティティを取り扱う構想が述べられています。このアイデアは参考になりました。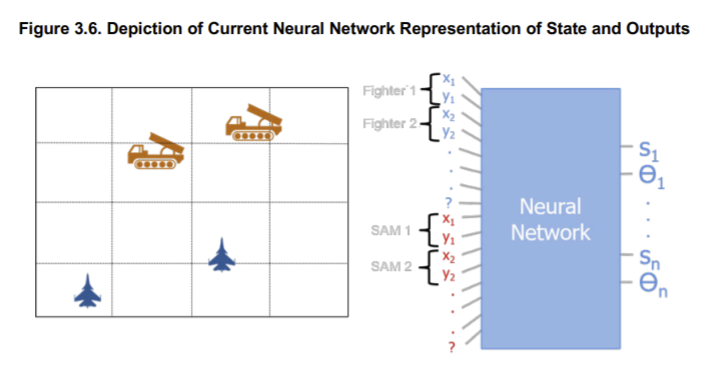
ランド研究所のレポートと同様の方向をめざした研究としては、強化学習により、複数のSUV(無人艦艇)の編隊ナビゲーションをプランニングするUniversity Collage of London のチームの研究(2019)が挙げられます。
ランド研究所のレポートと同様の方向をめざした研究としては、強化学習により、複数のSUV(無人艦艇)の編隊ナビゲーションをプランニングするUniversity Collage of London のチームの研究(2019)が挙げられます。
US Marine Corps(海兵隊)の研究 "Developing Combat Behavior through Reinforcement Learning in Wargames and Simulations", 2020 では、中隊(company)、小隊(platoon)レベルの戦闘行動を、強化学習により生成することを試みています。
今回は、これを大いに参考にしました。この研究では、戦闘をターン制のゲームとしてとらえ、タイムステップ当たり1つの中隊又は小隊の戦闘行動を生成するようネットをトレーニングしています。イメージとしては、「信長の野望」をAI化したと思えば近いものになります。(私が知っている「信長の野望」は数十年前のものなので、最近は変わっているかもしれません)。
ターン制なので、登場エンティティ数が多ければ多いほど、小隊・中隊の行動が一巡するのに時間がかかってしまうため、実際の戦闘とは異なったものとなってしまいます。これを避けるために、この研究では、後に述べるランチェスター・モデルの戦闘効率をかなり小さく採って、影響が現れないようにしていました。これは、シミュレーションのタイムステップを非常に小さく採っていることと同等なので、1回のシミュレーションに要する時間が長くなるという問題があります。(つまり、計算リソースが無い私のような趣味人には厳しい)。
この海兵隊の研究では、学習した戦術を "Mass"(集中)と "Economy of Force"(力の経済性)の観点から分析している点が海兵隊らしく面白いと思いました。"Mass" と、"Economy of Force" は、海兵隊教本 MCDP "1-0 Operations" において、それぞれ以下で定義されています。
Mass:決定的な結果をもたらすために、決定的な場所と時間に友軍能力を集中すること。力の統合(Consolidation of Force)
Economy of Force:プライマリーな目的を達成するために、最小限必要な戦力(Minimum essential combat power)を副次的な目的に割り当てること
研究の目的
本記事では、これらの軍事研究と DeepMind や OpenAI の研究等とを参考にして、問題をマルチエージェント強化学習のセッティングにすることで、戦場に散開した複数の群(swarm)の自律的な協調戦闘戦術の生成を試みました。最も類似している研究は、海兵隊の研究ですが、ターン制ではなく、マルチエージェントによる協調問題として解くことで、多数の群が同時に自律行動できるようにしました。
また、マルチエージェント強化学習のフレームワークとすることで扱える群の数も任意数となりました。解こうとしている最終的な問題環境、自群、友群、敵群の各種情報が、2次元地図(n x nでグリッド化)に表現されているものとします。群の一番判りやすいイメージは、海兵隊の研究で使われている中隊、小隊です。以下では、「我」を Red team、「彼」を Blue teamとし、各チームは大きさ(構成メンバー数)と保有する武器が異なる複数の群で構成されているものとします。
また、便宜上、各群をエージェントと呼ぶことにします。したがって、Red team, Blue teamは夫々複数のエージェントの集合体になります。
※ 本稿では、群の構成メンバーの戦術ではなく、「群の戦術」を生成するのが目的なので、群の構成メンバーがエージェントではなく、群=エージェント、複数の群=マルチエージェントと呼ぶことに留意してください。勿論、極限として構成メンバーが一人の群を考えれば、生成される戦術は群の構成メンバーの戦術とみなすこともできますが、それを特に企図している訳ではありません。
目的は、これらエージェント(群)が、取得したマップから自律的に戦況を判断して行動し、敵のエージェント(群)を殲滅する戦術を強化学習により学習することです。自群をagent-i、自群以外の友群を{agent-j, j≠i}とします。また、エージェントの兵力数(群の構成メンバー数)をForce、群の戦闘効率(武器性能)をEfficiencyと呼ぶことにします。
Force は戦闘によってランチャスター・モデル(後出)に従って消耗して行きますが、Efficiencyは戦闘期間を通じて一定の値をとるものとします。
グリッド化されたマップには、自群、友群、敵群、環境等の各種情報が、別々のマップとして表現されるものとします。具体的には、下図に示すように、各マップが夫々別の特徴量を表すものとします。この辺りのマップ化は、AlphaZero のチェスや将棋を参考にしました。
1) 自群位置、自群兵力(agent-i force)、自群戦闘効率(agent-i efficiency,)
2) 友群位置、友群兵力、友群戦闘効率(戦域に異なる戦闘効率の群が混在する時は、戦闘効率毎にマップ化されているものとします)。
3) 敵群位置、敵群兵力、敵群戦闘効率
4) 環境情報(壁のように通過できない建造物の位置を示すマップ、川や沼のように通過は出来るが、通過時に戦闘効率や移動速度が低下する環境位置を示すマップ等で、これらは環境の種類・特性ごとにマップ化されているものとします)。

戦闘目的によっては、さらに、防護エリアマップ、ターゲット・エリアマップ等のような目的を表すマップが追加で与えられるものとします。
自群、友群、敵群、環境等をマップで表すメリットは幾つかあります。
- 任意数の敵群エージェント数(群数)を取り扱うことが可能です。
- 自群と友群を別のマップにすることで、任意数の友群エージェント数(友群数)を取り扱うことも可能になります。
- 自群と友群を別のマップにすることで、自律システムに適したマルチエージェント設定で問題を解くことが可能になります。
- 数値で表すよりも簡単に、複雑な環境や戦闘目的を、表現することが可能です。これは、人と自律システムが会話する際の重要な要件だと思います。
一方、ディメリットは、(マルチエージェント)強化学習が困難、或いは長時間かかるようになることです。Ai にとって、例えばマップ上で位置を認識することは、(x, y)座標値で位置を認識するよりも、ずっと困難です。
これらのマップは、それぞれ nxn の2次元配列(nxnx1 のテンソル)になるので、マップが c 枚ある時は、エージェント(群)に与えられるマップ全体は nxnxc のテンソルとして与えられることになります。群が自律群(Autonomous swarm)であれば、これらのマップは、エージェント自身が有するインテリジェント・センサによって取得されます。一方、非自律群(Non-autonomous swarm)であれば、群を指揮統制する C4I 系(Command, Control, Comunication, Control and Intelligence)から通信を介してマップが与えられます。(実際は、両者の中間になると思います)。
いずれの場合も、(特に、自身のセンサで取得する場合は)、マップ情報は、エージェント毎に異なる可能性があります。したがって、部分観測マルコフ決定過程(POMDP, Partially Observable Markov Decision Process)と呼ばれる、もう一つの厄介さがさらに追加になります。
各タイムステップで、各エージェントは、これらのマップ情報と学習したポリシーに従って、東西南北いずれかへの移動、又は移動しないの5択から群としてのアクションを決定します。このアクションのシーケンスが、群の戦術ということになります。
この際、エージェント間(群間)には通信が無いものとします。(最前線にいるエージェント間に通信ネットワークがあるという仮定は、電子戦の時代には無理な気がします)。このため、各エージェントの決心は、同じタイム・ステップでは他のエージェントには判りません。他エージェントの決心は、あくまで次タイムステップで取得したマップからのみ認識できることになります。つまり、他エージェントの決心を知るまでには時間遅れが生じます。
したがって、各エージェントは、他エージェントの意図をマップから予測してアクションを起こす必要があります。つまり、エージェントの協調行動は、「阿吽の呼吸」として創発される必要があります。
なお、Red team と Blue team は、同じグリッドに入ると自動的に戦闘を開始し、同じグリッドにいる間は戦闘を継続するものとします。
群 vs 群の戦闘モデル(ランチェスター・戦闘モデル)
群 vs 群の戦闘モデルとしては、海兵隊の研究と同様にランチェスターモデルを用います。このモデルは決定論的(Deterministic)ですが、海兵隊の研究では確率論的(Stochastic)なモデルも検討されています。今回は、問題をシンプルにするために、オリジナルの決定論的なランチェスター・モデルを用います。
ランチェスター・モデルでは、x を自群の兵力(Force, 構成メンバー数)、y を敵群の兵力、α を自群の戦闘効率(Efficiency, 武器性能)、β を敵群の戦闘効率、Δt を経過時間(タイム・ステップの大きさ)とすると、自群、敵群の兵力の消耗量 Δx, Δy は、それぞれ以下で与えられます。
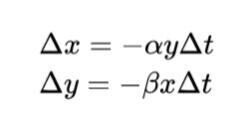
時間経過 Δt が小さい場合、上式は常微分方程式で近似出来ます。
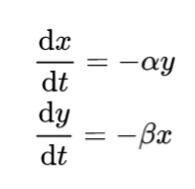
ランチェスターモデルから導出される重要な結果の一つが、分割戦略です。
これは、戦闘力が小さな軍隊でも、何らかの方法で敵を分割することが出来た場合は、順繰りに敵を個別撃破していくことで、最終的に勝利を収めることが出来るというものです。これは、海兵隊の "mass" と "economy of force" の基になっている考え方です(と教本に書いてあったと記憶しています)。
下図に、シミュレーションの結果を示します。横軸が戦闘開始からの経過時間、縦軸が各 team の残存兵力です。青ラインが Blue team の残存兵力、橙ラインが red team の残存兵力の遷移を示します。red team の初期兵力は 400、blue team の初期兵力は 500 としています。彼我の武器性能 (efficiency=0.7) は同一としています。したがって、1対1のガチンコ勝負の場合、red team に勝ち目はありません。
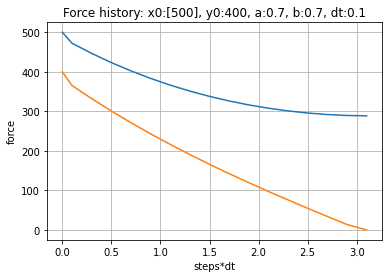
しかしながら、red team が何らかの方法により、blue team を (250,250) の群に2分割できた場合、これらに順繰りに(シーケンシャルに)対処していくことで red team は勝利することが出来ます。シミュレーションは、戦闘中の敵群兵力が消滅したら、次の敵群と戦うと仮定して計算しています。
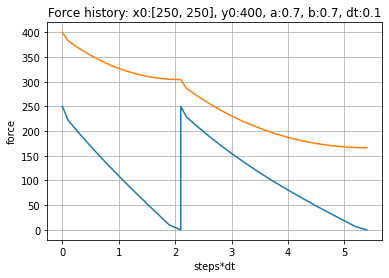
この効果は、blue team を小さな多数群に分割できた場合ほど大きくなります。例えば、blue team の兵力を (100, 100, 100, 100, 100) と5つの小群に分割できたような場合、初期兵力では劣っていた red team が、想像以上の圧勝を得ることになります。
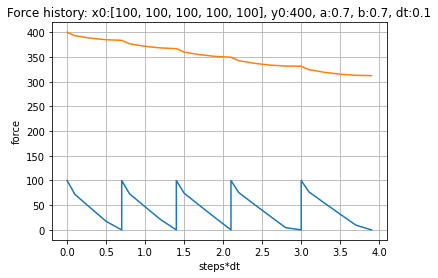
これから、小出しに戦力投入することがいかに不利で、海兵隊が重要視する "mass(consolidation of force)" がいかに重要かが判ります。
以上から、戦場に様々な兵力や戦闘効率のエージェント(群)が散開している場合、勝利を収めるためには、散開した様々な戦力のエージェントは、陽には与えられていないランチェスターモデルを理解し、自己、友群、敵群、環境状況、残存兵力、戦闘効率等をマップから認知・識別し、彼我の動きを阿吽の呼吸で予測して、適切な "Mass" と "Economy of force" を得ることが出来る協調戦術に変換し、各自のアクションとして自律的に実行することを学習しなければならないことが判ります。
これを、「マルチエージェント強化学習の枠組みで学習」させてみようというのが今回の趣旨になります。
使用するマルチエージェント強化学習
今回は、マルチエージェント強化学習に係る初期の論文 "Multiagent Cooperation and Competition with Deep Reinforcement Learning"、(2015) と同じく、最も単純な実装にしました。平たく言えば、報酬設計だけでなんとかしよう、という考え方です。
red team の全エージェントは、同じ一つのニューラル・ネットをブロードキャストしたコピーを持ちます。これは、少し見方を変えると、全エージェントが1つのニューラルネットを共有していることになります。環境とのインタラクション(ロールアウト)時には他のエージェントは環境の一部とみなします。そして、全エージェントが、ロールアウトして収集した遷移情報を使って、確率的勾配法でこの共有しているネットを更新することで学習を進めます。バッチ分のデータを使った更新が終わると、新しいネットのコピーを各エージェントにブロードキャストし、次のサイクルに入ります。
学習後の実行については、エージェントは、自分が持っているニューラルネットのコピーを使って、他のエージェントの決心とは独立して、観測から行動を自ら決心します。
したがって、全体のフレームワークとしては、学習は中央集約的、学習用のデータ収集と学習後の意思決定・実行は自律分散的となります。

まとめ
これから、マルチエージェント強化学習で解こうとしている問題について整理しました。このままでは、少し問題が複雑すぎるので、次回は、この問題をもう少しシンプルにして、初トライとして適当なレベルの問題を設定します。
追記 @2021.10.08
わりと似たことをやっているスタンフォード大のレポートを見つけました。PPOではなく、DQNを使っています。2016年ごろのレポートではないかと思います。
http://cs231n.stanford.edu/reports/2016/pdfs/122_Report.pdf