マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その5):少〜多数群で訓練する
GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
(その3)では「少数群 vs 少数群」、(その4)では「多数群 vs 多数群」でトレーニングを行いました。その結果、それぞれにおいて、各エージェントは、ある程度の汎化能力を有する少数群戦闘エキスパート、多数群戦闘エキスパートのように学習できることが判りました。また、それらをセレクタを用いて、Subsumption architectureのような構造で組み合わせて用いる案を示しました。
今回は、これら両方の群数をカバーする、広いダイナミックレンジの群数での戦闘によってトレーニングを行ってみます。群数のダイナミックレンジが広くなるほど学習は困難になることが予想されるので、本手法が、ダイナミックレンジを広くしても通用するのか確認したいと思います。
実施内容は以下の通りです。
- はじめに、Red team のエージェント数(群数)を [1, 8]、Blue team のエージェント数(群数)を [1, 7]として、ネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、各チームのエージェント数(群数)を外挿方向に増やして戦闘性能がどう変化するのか見てみます。
実行環境
- (その3)と同じ
PPOハイパーパラメータ
- (その3)と同じ
シミュレーション条件
- (その3)と同じ
トレーニング履歴
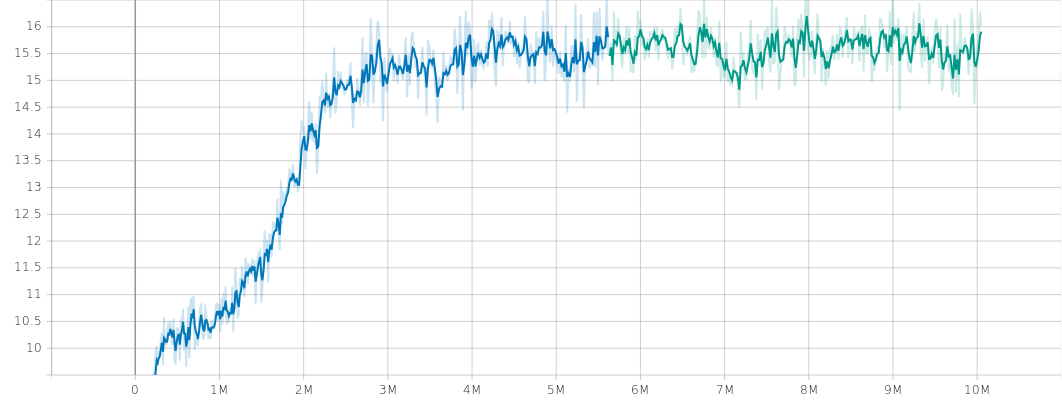
グラフの途中で色が変わっているのは、GCP の Preemptive vm が最大24時間でシャットダウンされてしまうので、シャットダウン後、継続学習を行っているためです。
下図で、縦軸はエピソード報酬、横軸が更新ステップです。安定して学習しています。ただし、(その3)、(その4)のエキスパートの学習ほどには安定していません。学習が、より難しくなったということだと思われます。
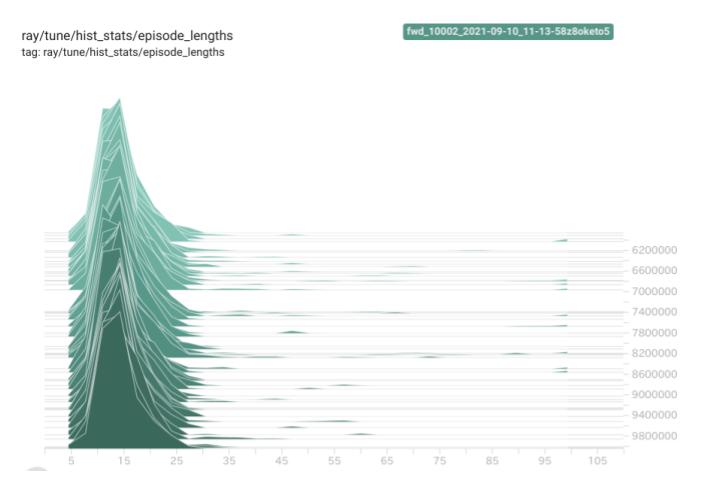
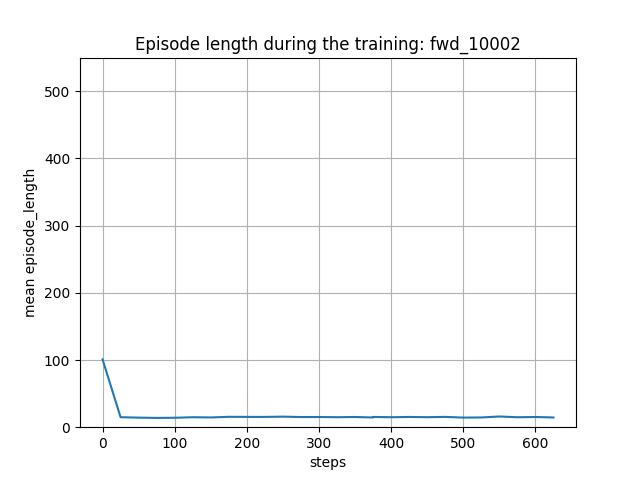
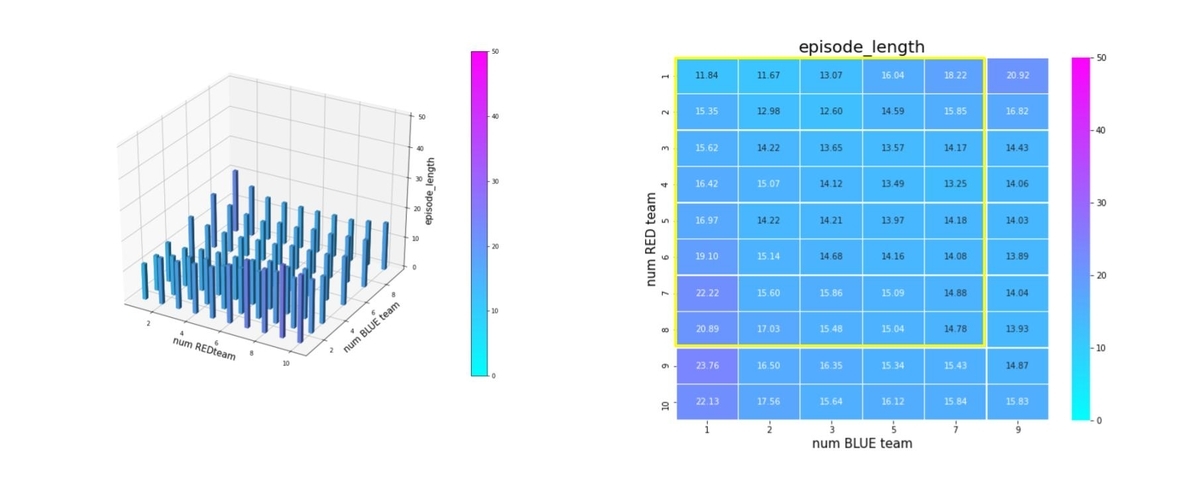
下図は、トレーニング時の平均エピソード長の履歴です。戦場サイズが 10x10 なので、群の数も考慮すると、平均エピソード長が15ぐらいになっていて、妥当ではないでしょうか。
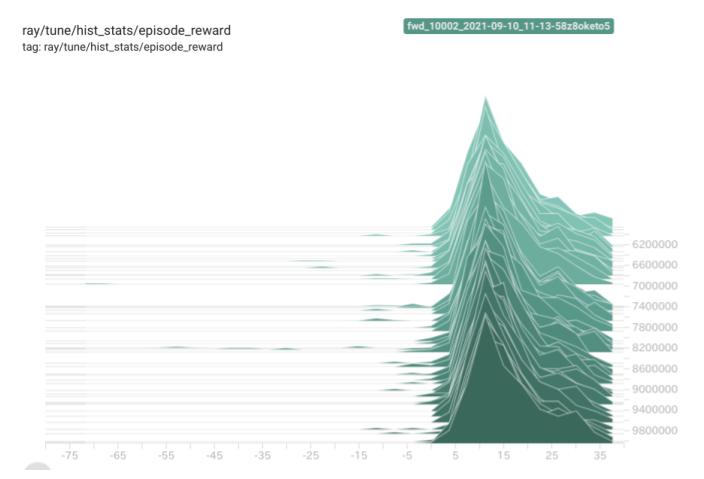
下図は、学習後半のチーム報酬の分布です。
下図は、学習後半のエピソード長の分布履歴です。
トレーニング時の評価結果
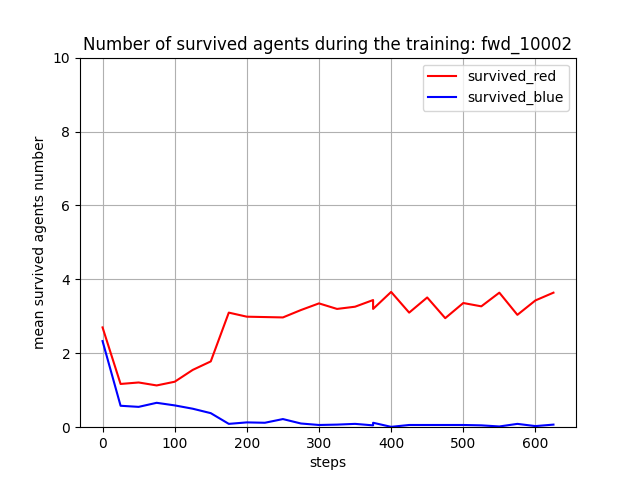
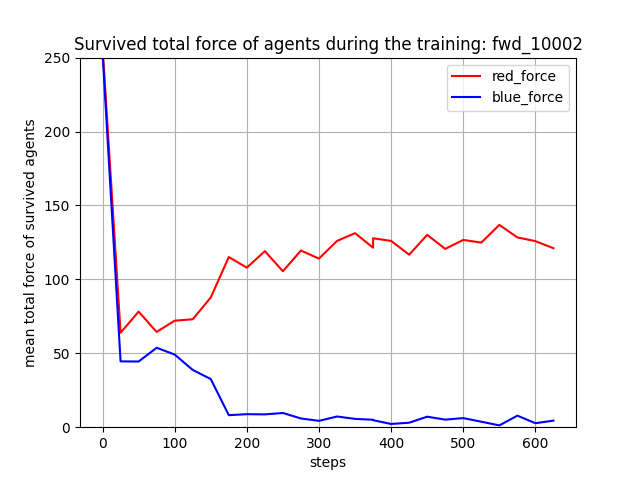
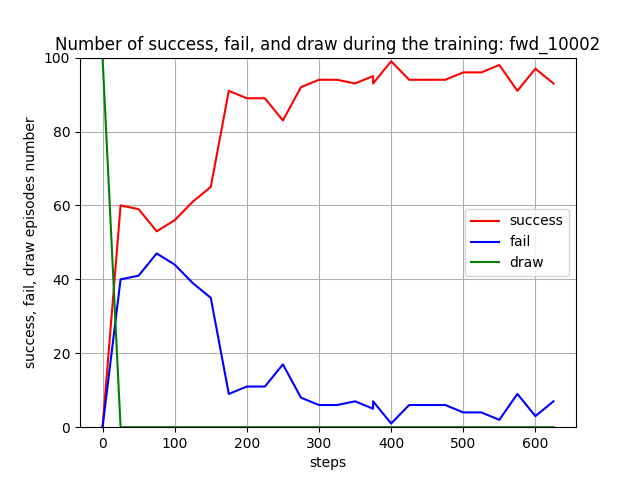
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [7, 8] で乱択しているので、学習が進んだ時の平均残存数=5 ~ 6 は、1~ 2 エージェントが戦闘で消耗することを意味します。
Blue team の残存エージェント数や残存兵力を完全に0にはできていませんが、学習は進んでいるので、手法としてはトレーニング時の群数のダイナミックレンジを拡げても本手法は機能すると考えられます。ただし、評価結果が安定し始めたぐらいの感じがするので、もう少しトレーニングは長くやった方がよさそうです。
性能評価
下表は、学習後のチームの性能を100回のシミュレーションを行って、定量的に確認したものです。ここで、
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
になっています。(これまでと同じです)。
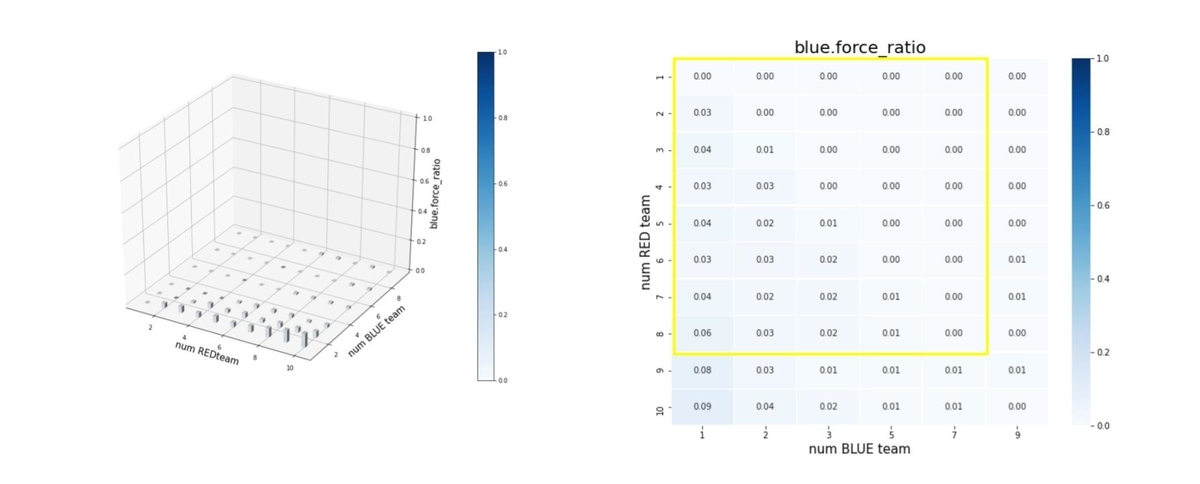
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。ここで、num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸が blue_force_ratioです。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。
Blue teamの残存兵力はかなり小さくできているので、Red teamのエージェントは、彼我の群数が大きく変動しても戦えるような戦術を学習していることが判ります。
図を見ると戦術全体のバランスは悪くはないのですが、特に、少ないエージェント(群)で構成された Blue team に、多数のエージェント(群)で構成された Red team で攻撃するようなシナリオになると、性能が少し劣化しています。やはり、巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するシナリオほど、学習が困難なようです。
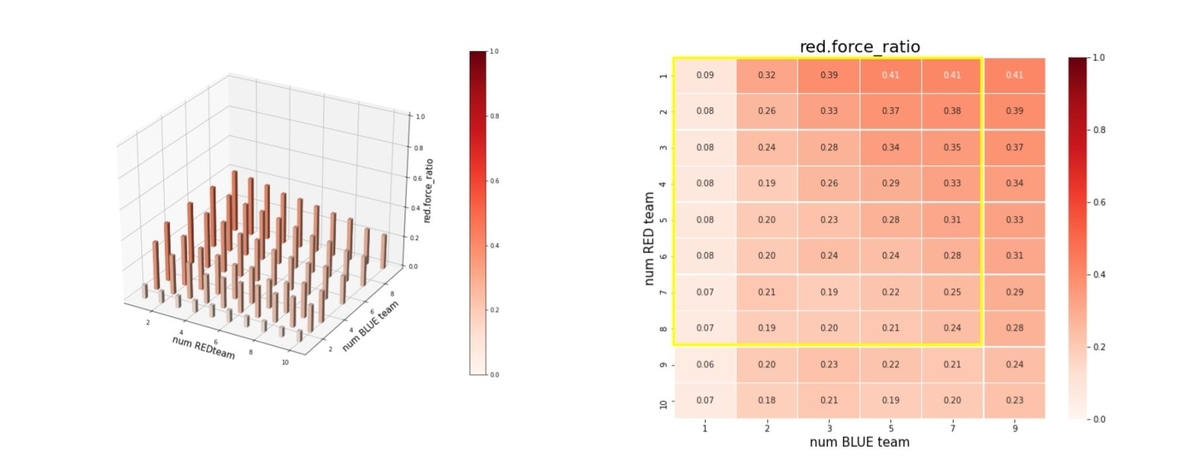
この時の red teamの残存兵力は下図になります。red_force_ratio は以下で定義しています。左図のバーグラフの縦軸が red_force_ratioです。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するケースでは、残存兵力が僅かになっています。
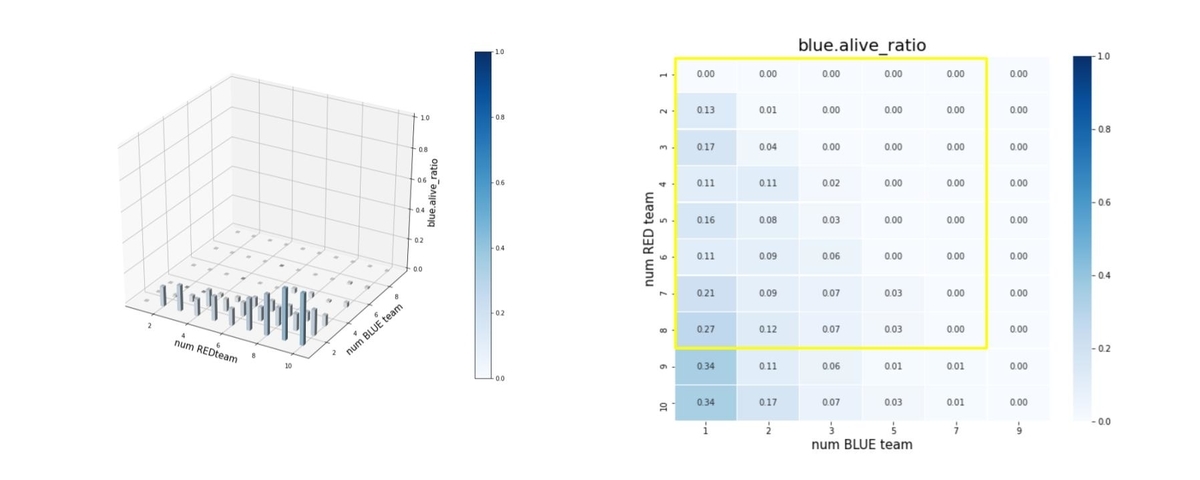
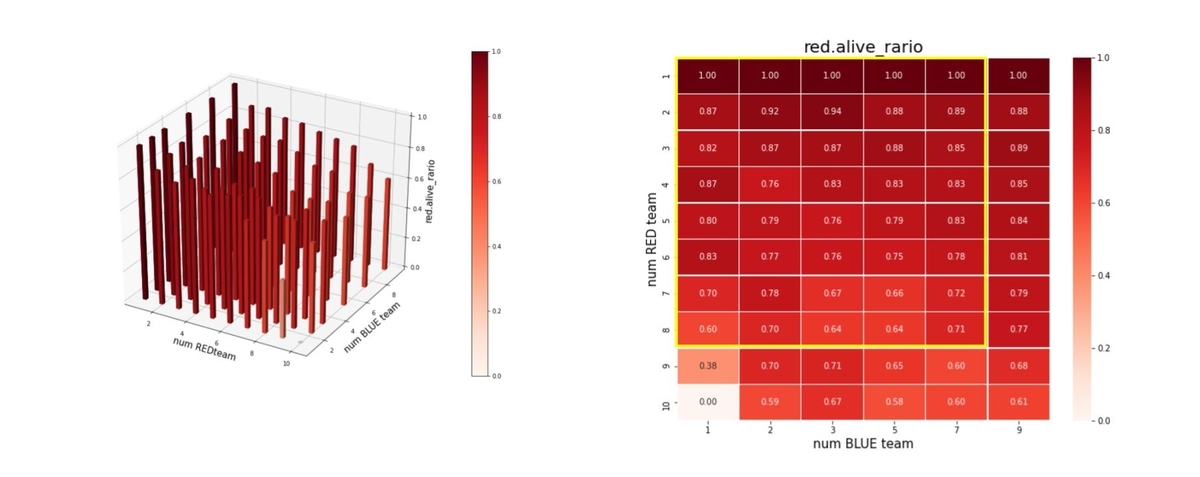
以上のことは、残存兵力ではなく、残存エージェント数からも読み取ることが出来ます。これを下図に示します。
成功率を以下で定義します。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
これをバーグラフと heatmap にしたのが下図です。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘するケースほど、成功率が低下しています。
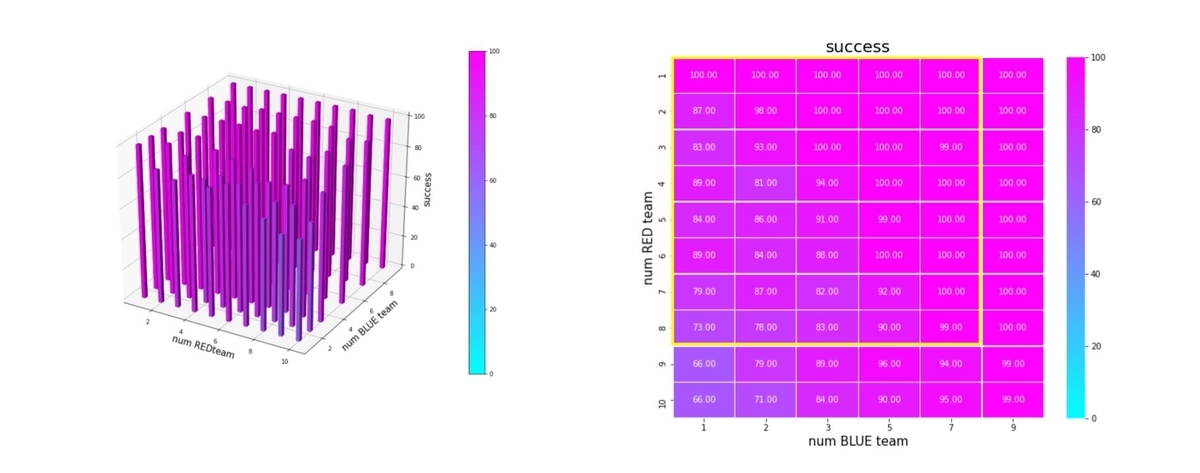
平均エピソード長は下図です。(その3)、(その4)のように少数群で訓練した場合と違って、成功率が低下するようなシナリオでも、エピソード長が極端に長くなっていません。これは、このようなシナリオでは、エージェントが右往左往して成功率が低下するのではなく、生成した戦術が悪くて失敗していることになります。この辺りは、今後の改良ポイントだと思っています。
生成された戦術
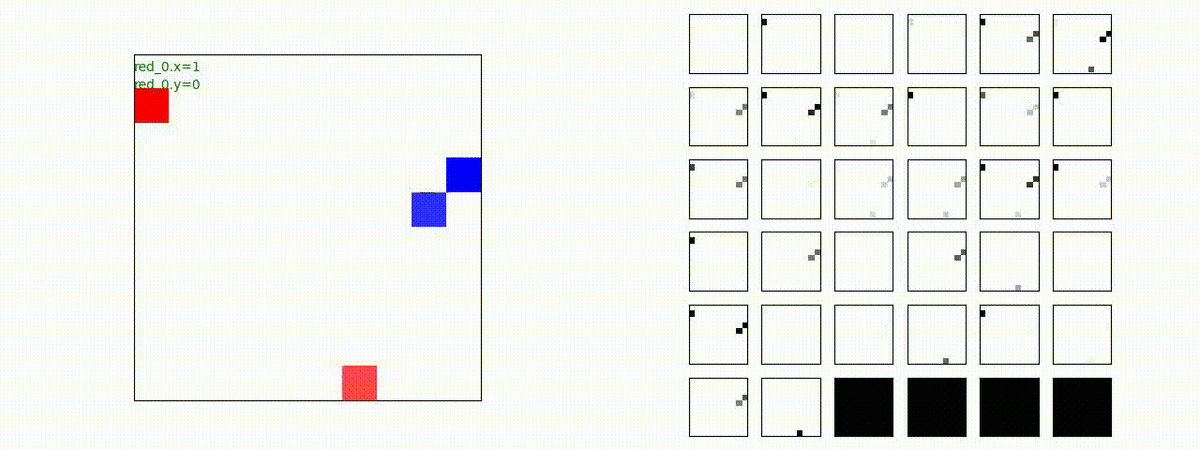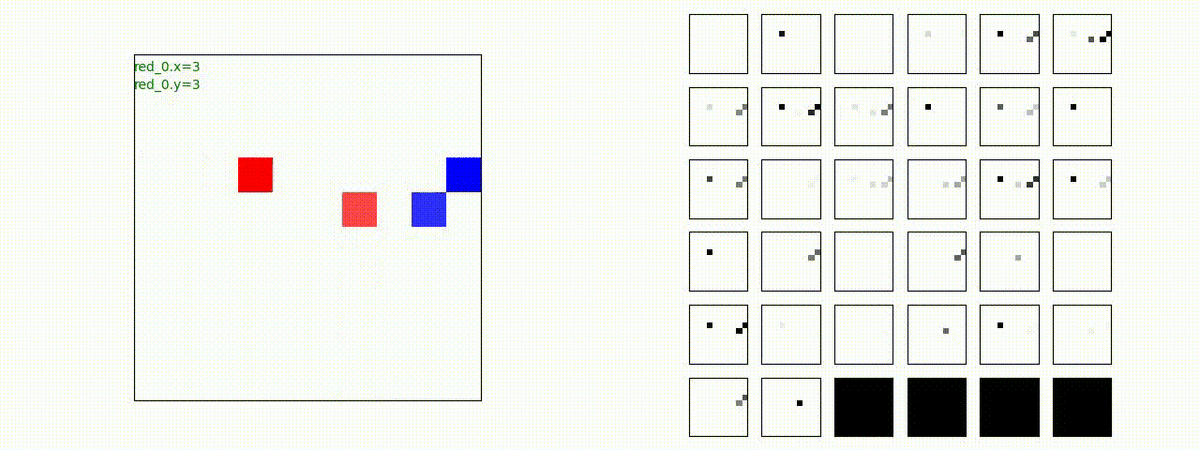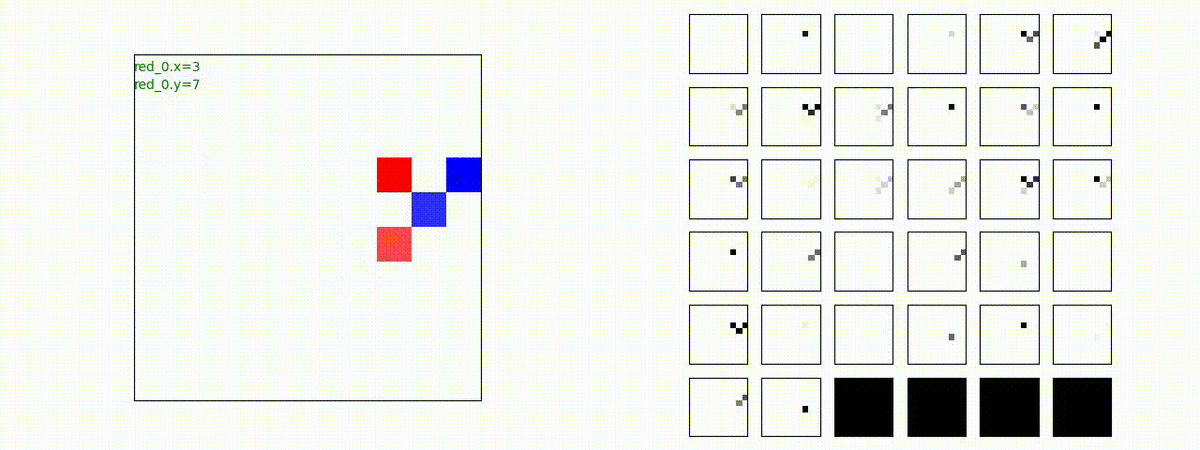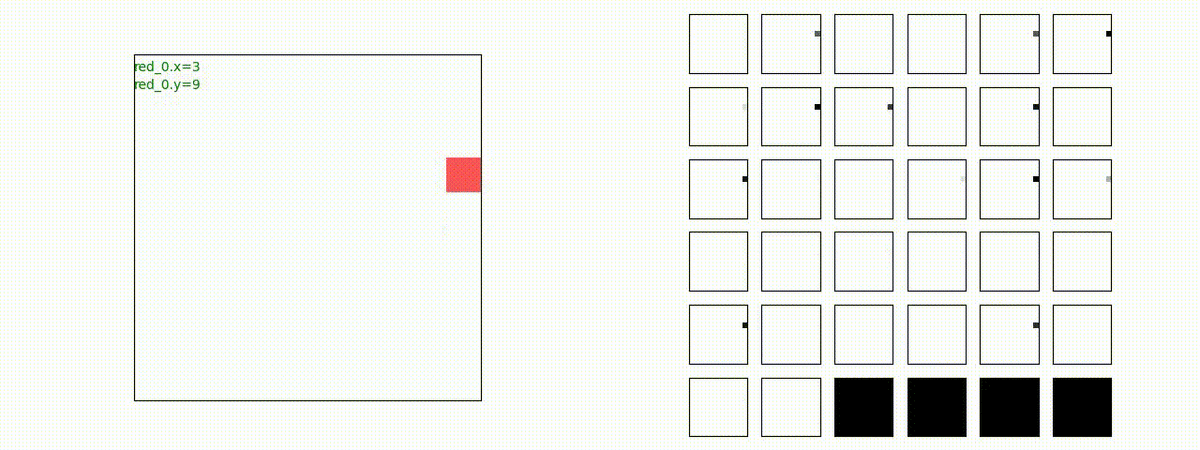
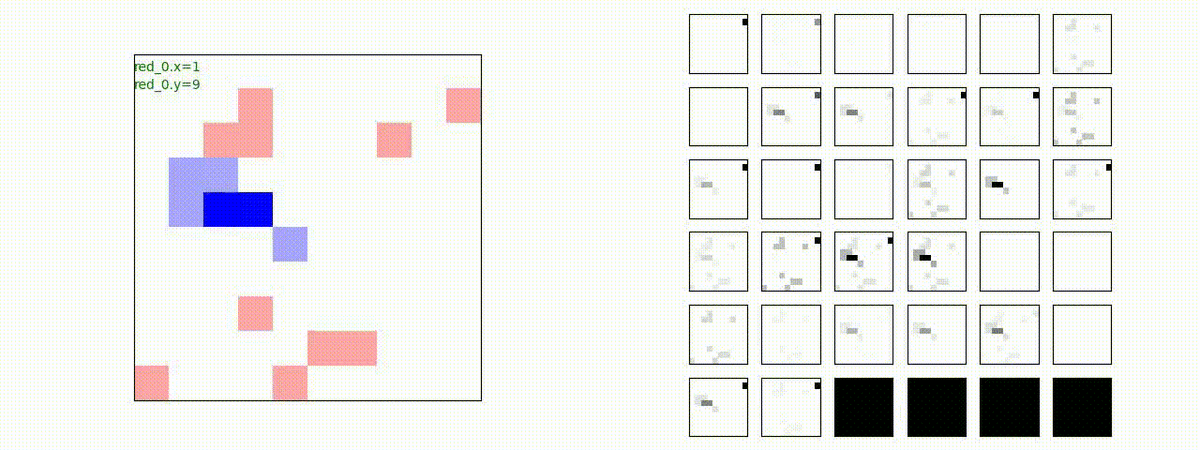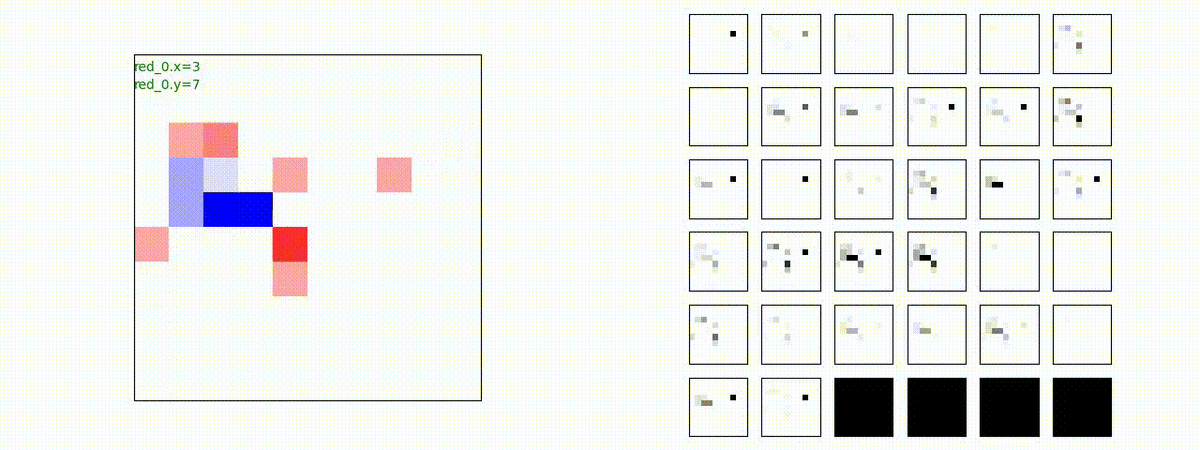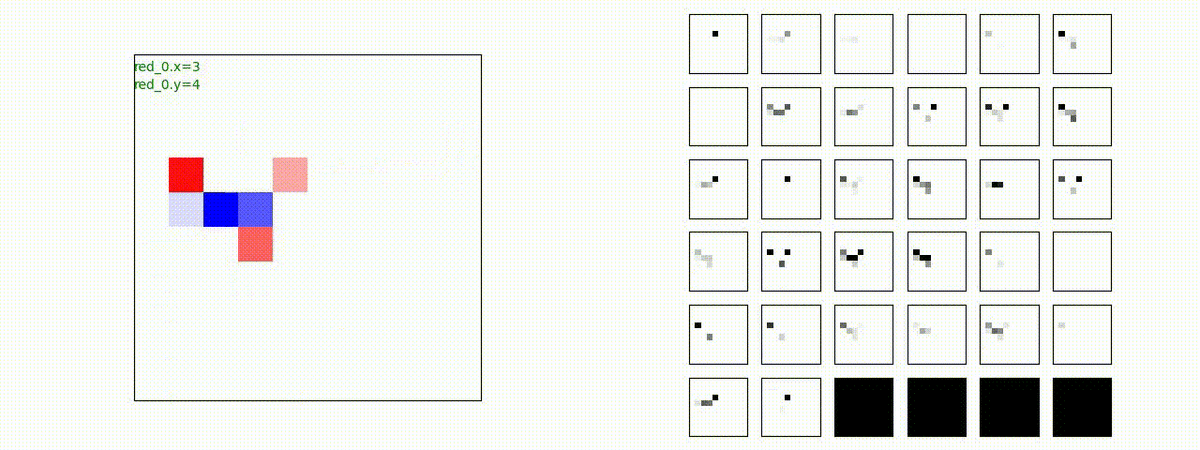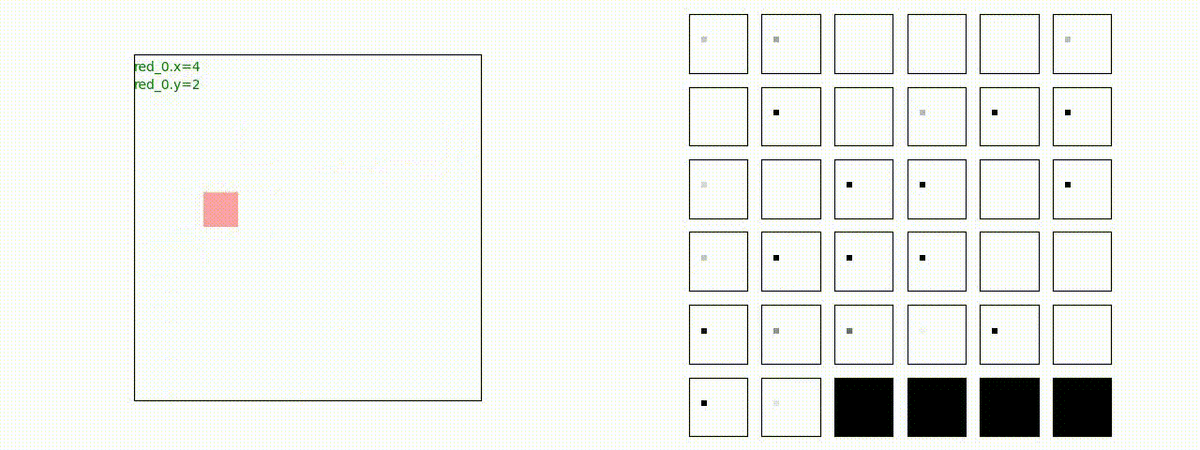
はじめに、学習時に含まれる群数での戦闘で生成された戦術の例を示します。見方はこれまでと同じで、左が交戦状況、右が残存兵力又は 1x1 Conv が入力マップを元に新たに生成し直した32枚のマップです。
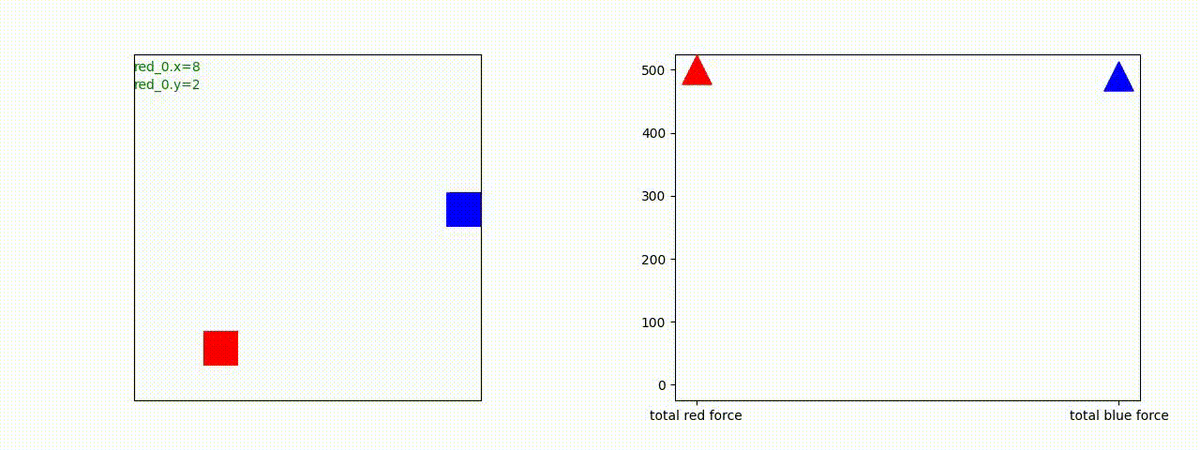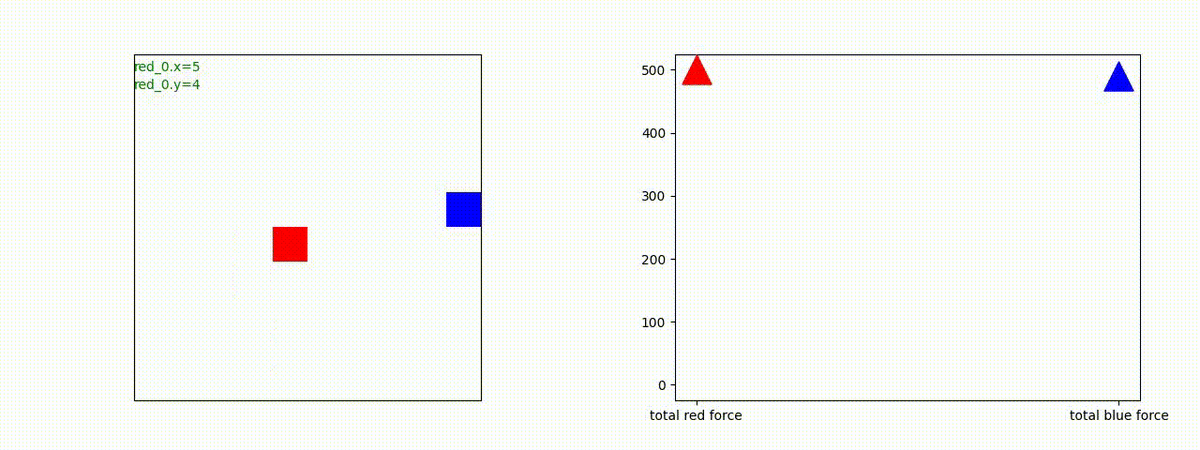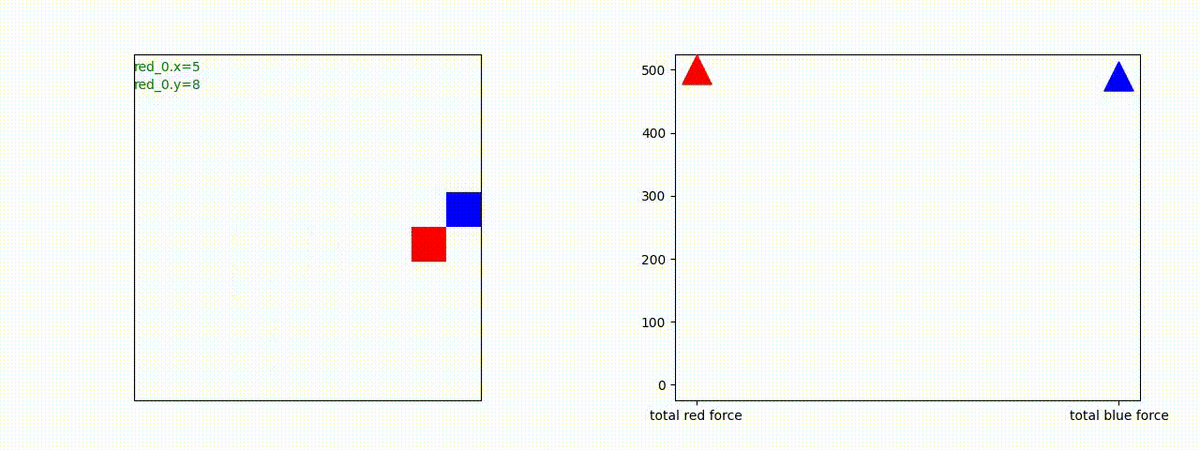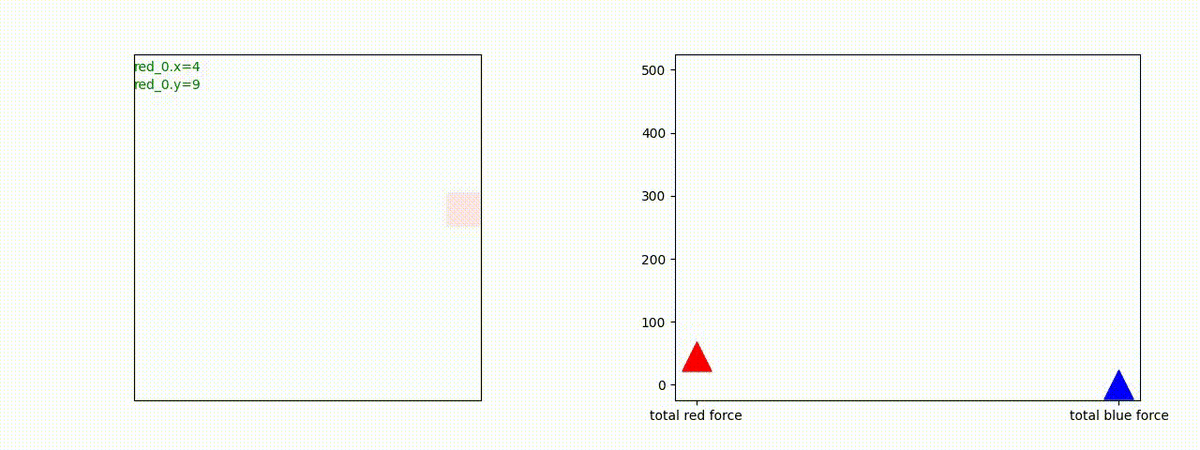
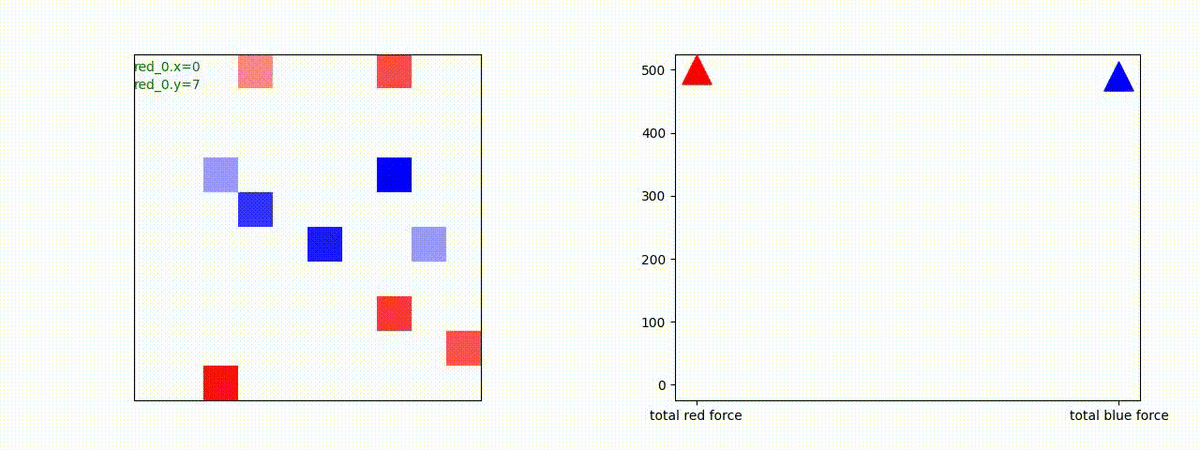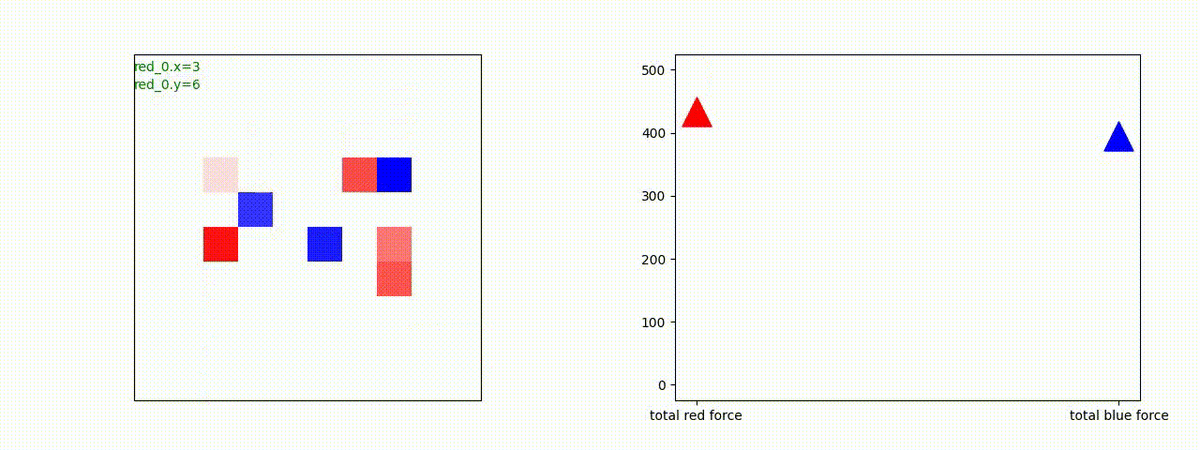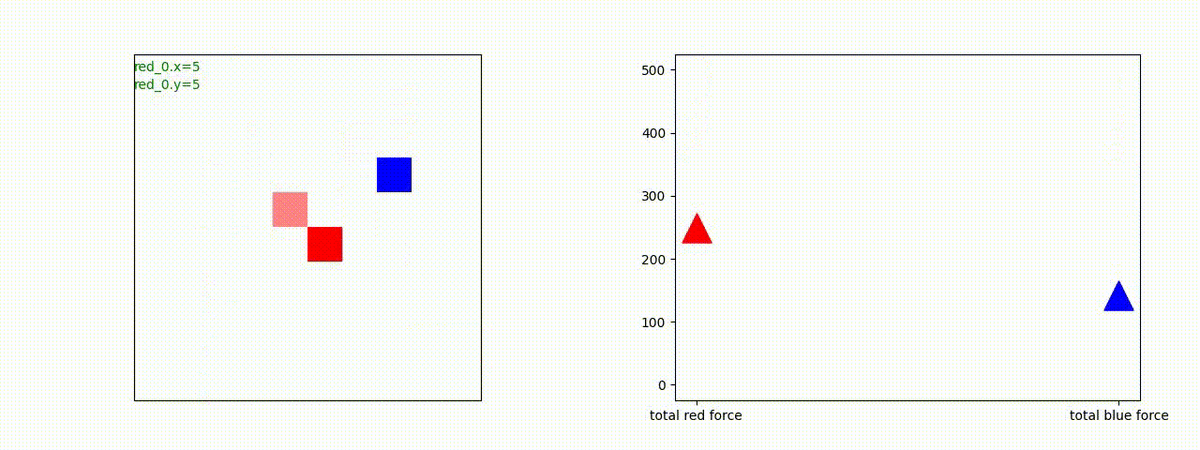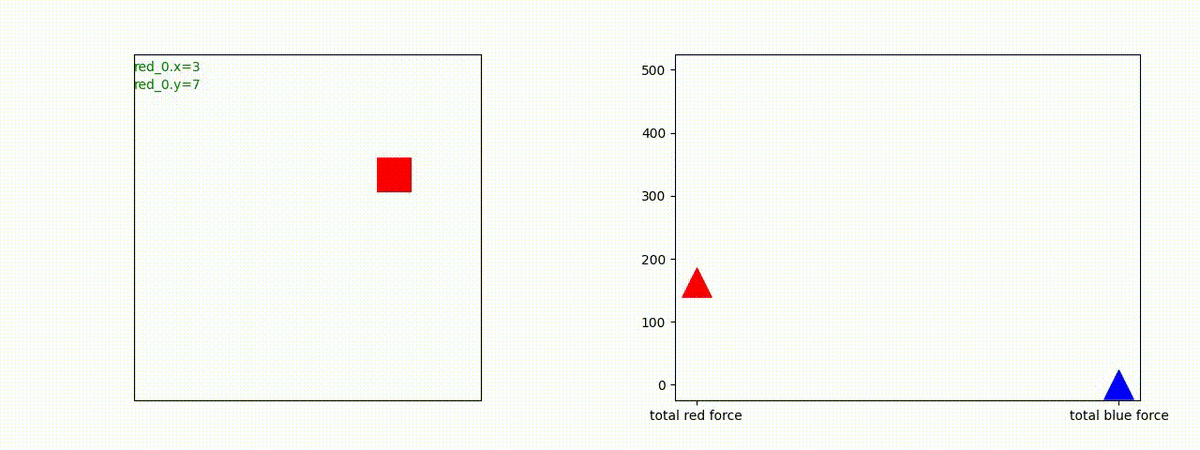
Red team = 1 swarm vs Blue team = 1 swarm
最短経路で敵のいるグリッドに到達し、そこにとどまることを学習しています。
1x1 Conv が入力マップを元に新たに生成し直した32枚のマップは以下のようになります。
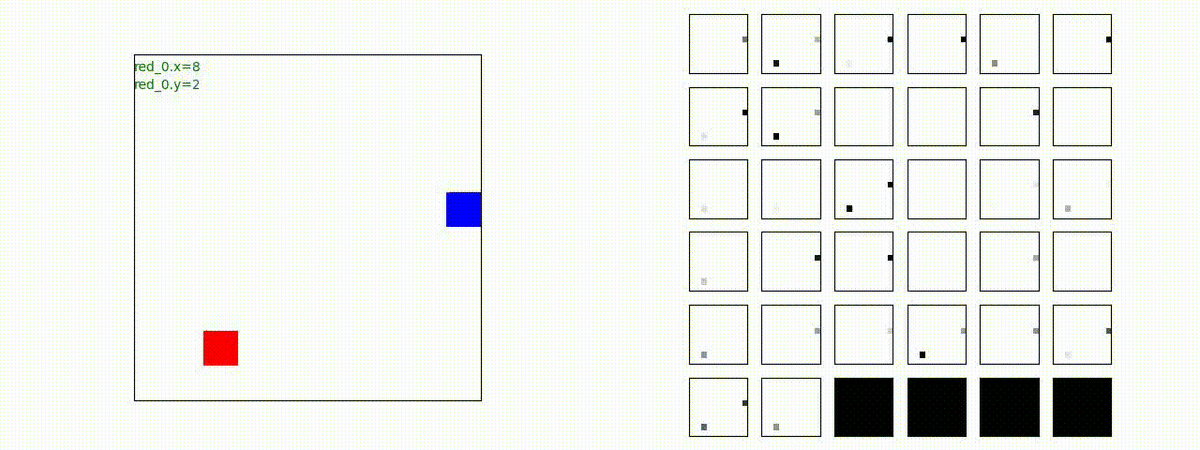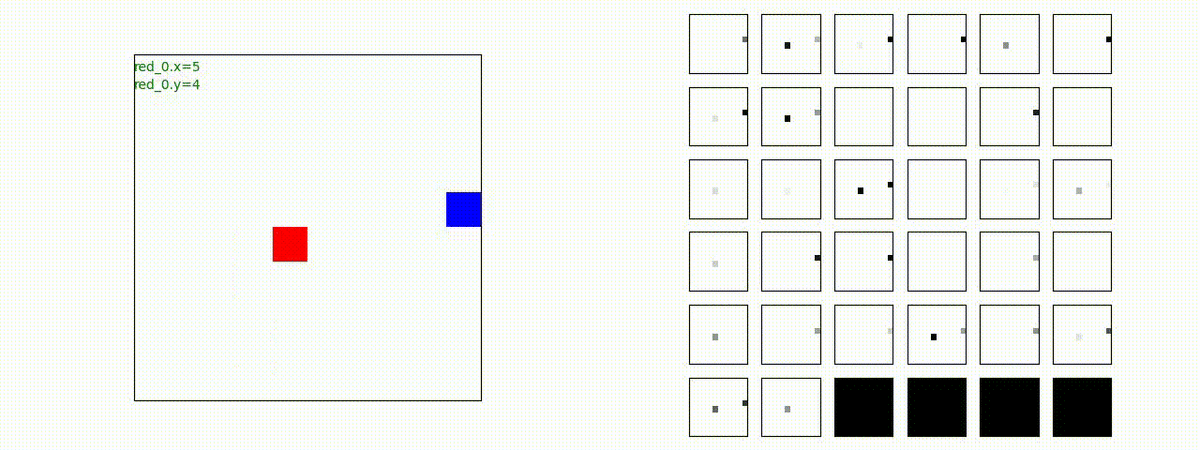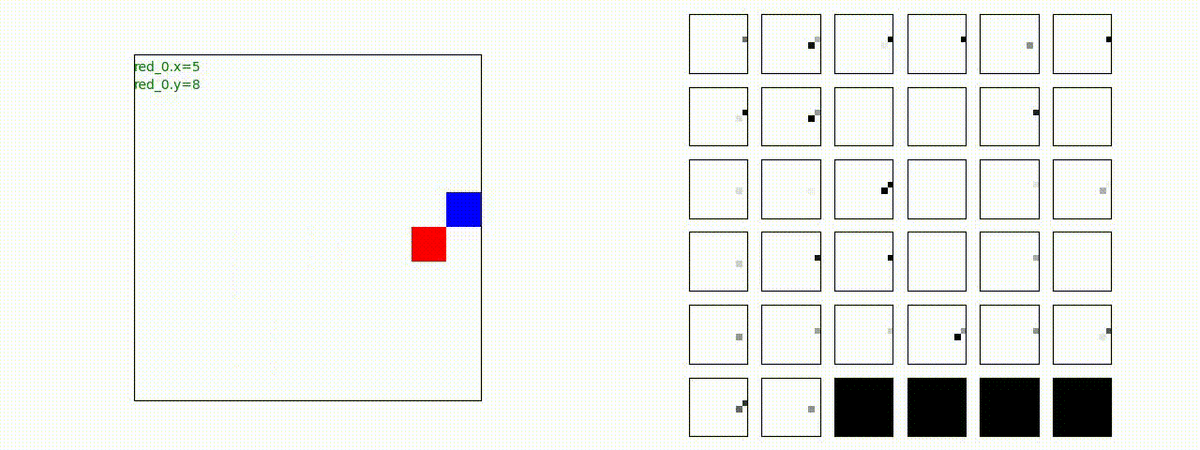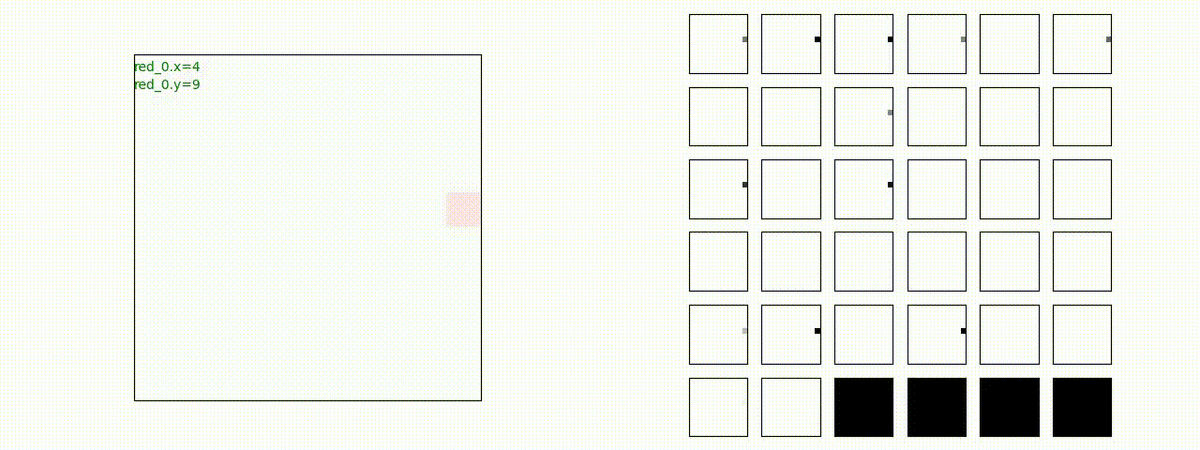
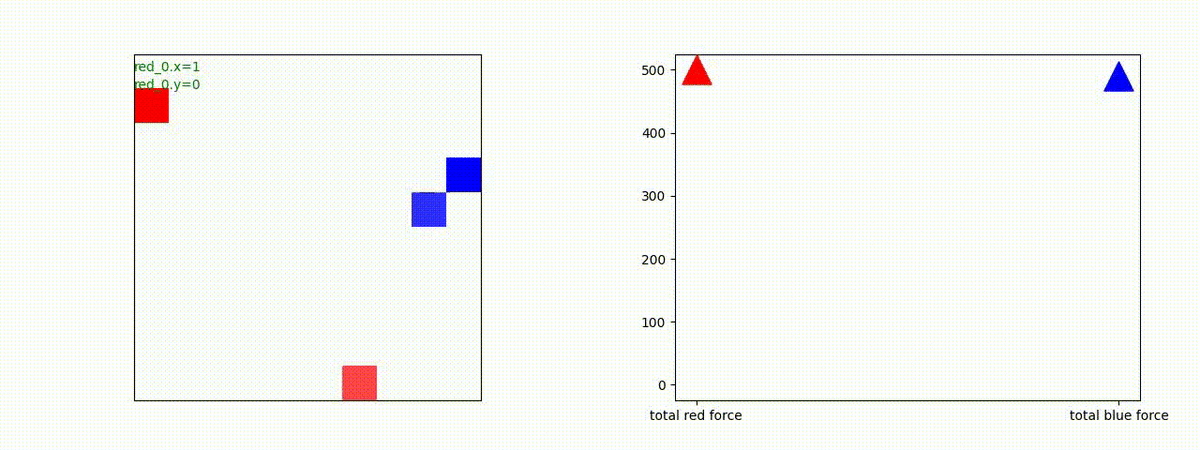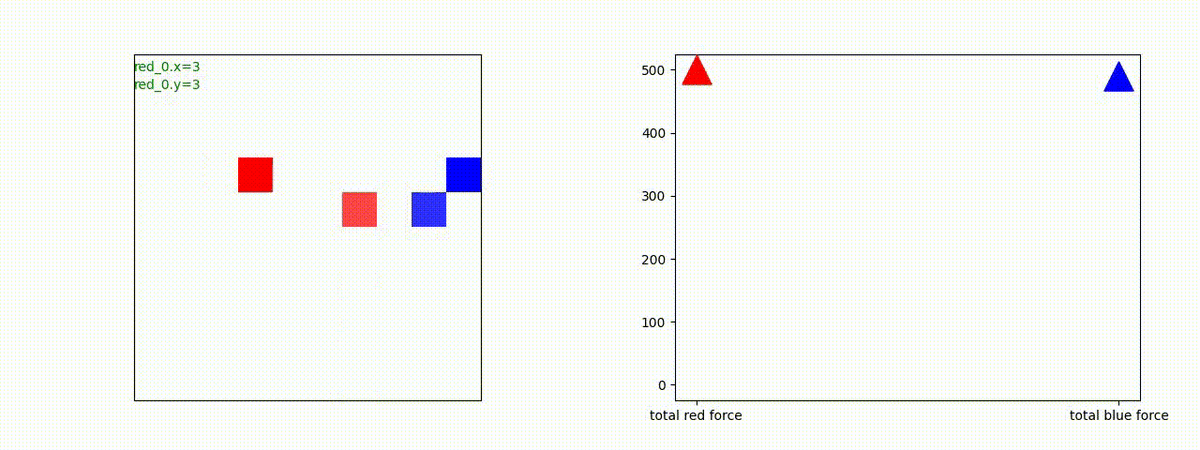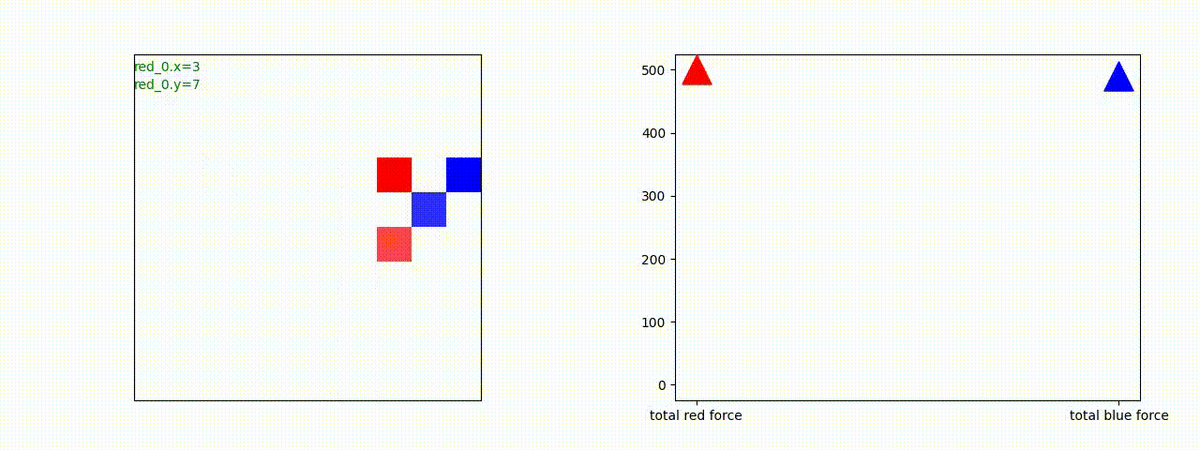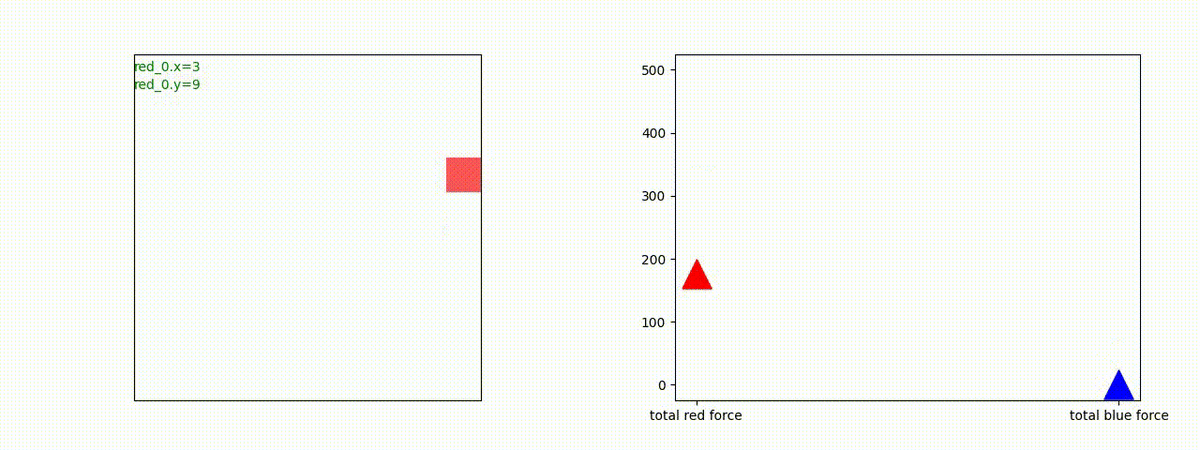
Red team = 2 swarms vs Blue team = 2 swarms
一つの大きな 'mass' となって、順に敵を撃破していく戦術が生成できています。
Red team = 3 swarms vs Blue team = 3 swarms
完全に一丸ではありませんが、敵よりも大きな 'mass' を構成して、敵を撃破していく戦術が生成できています。
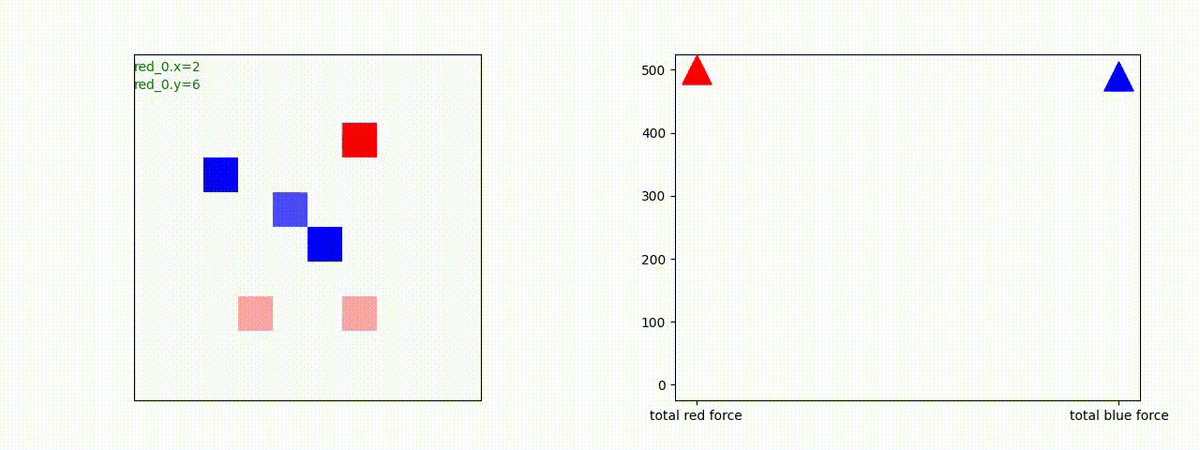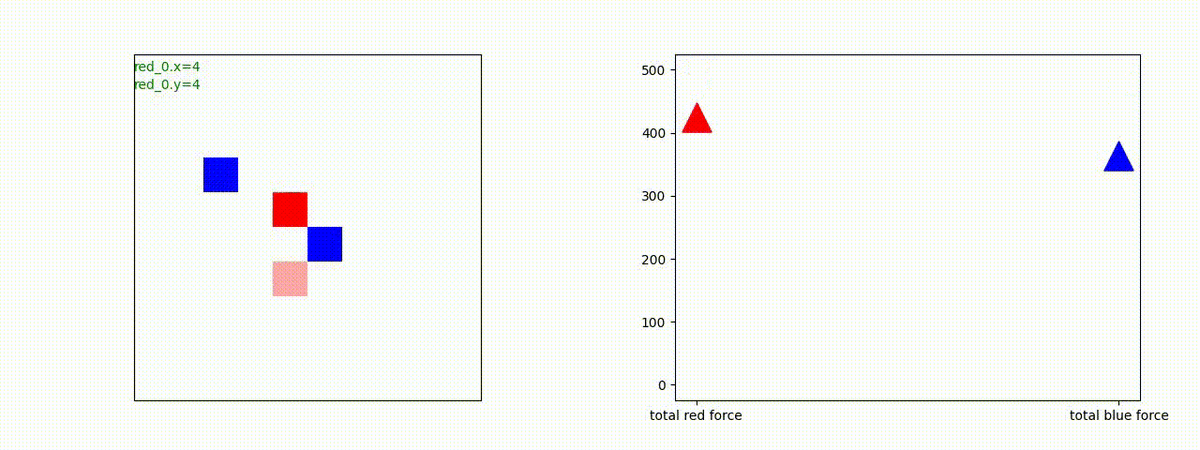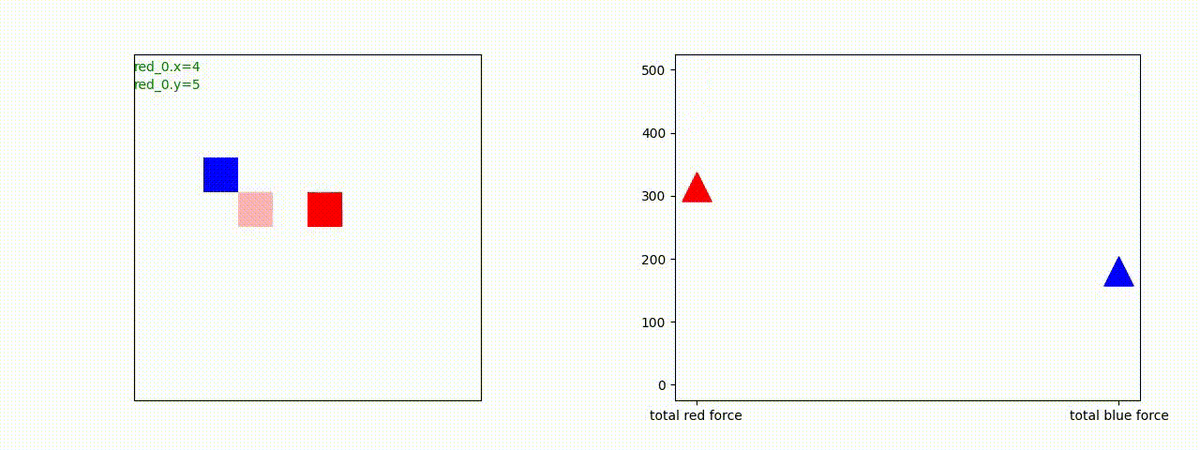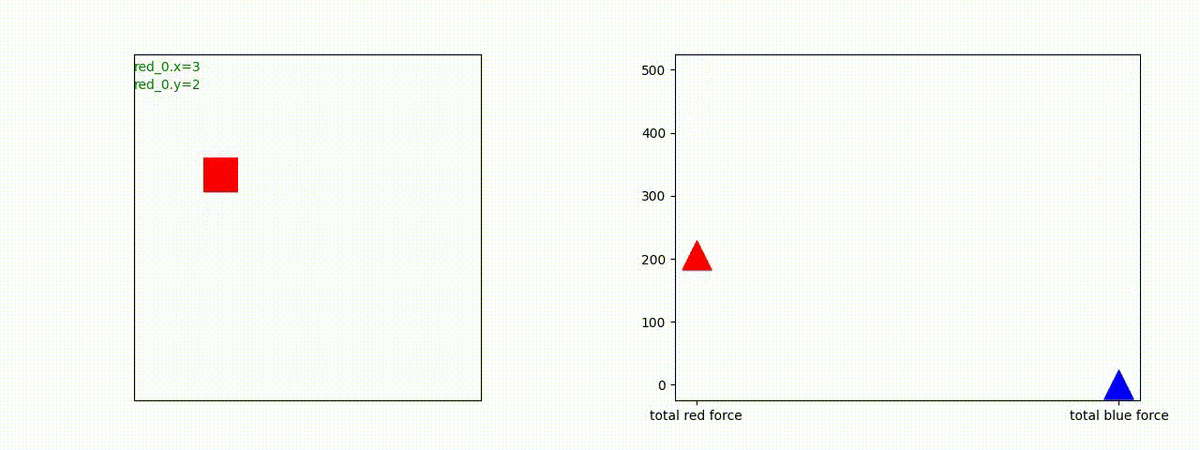
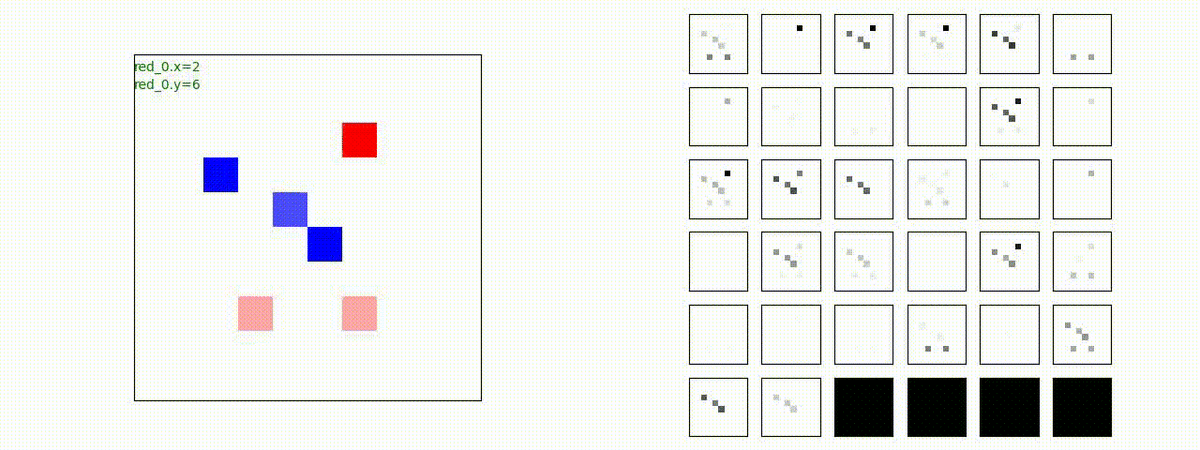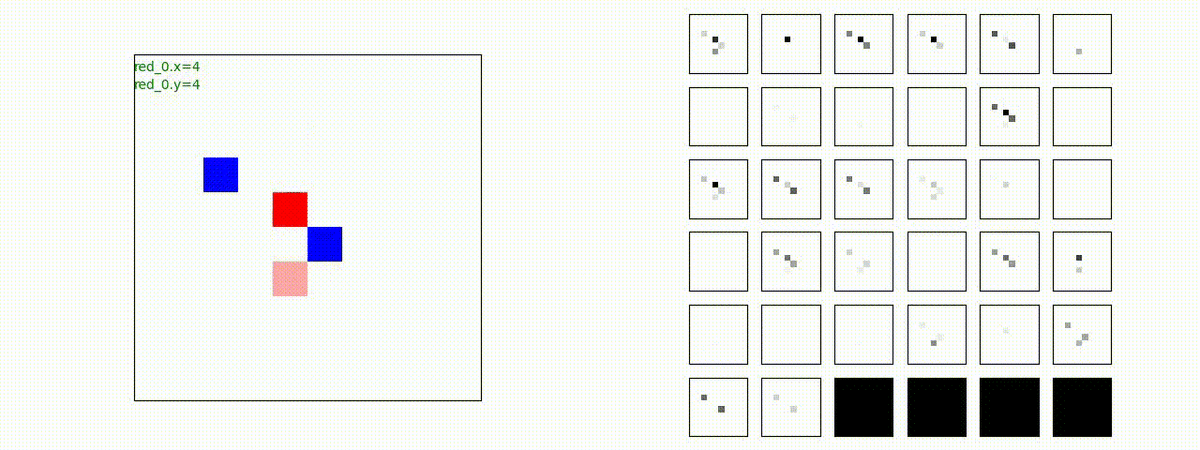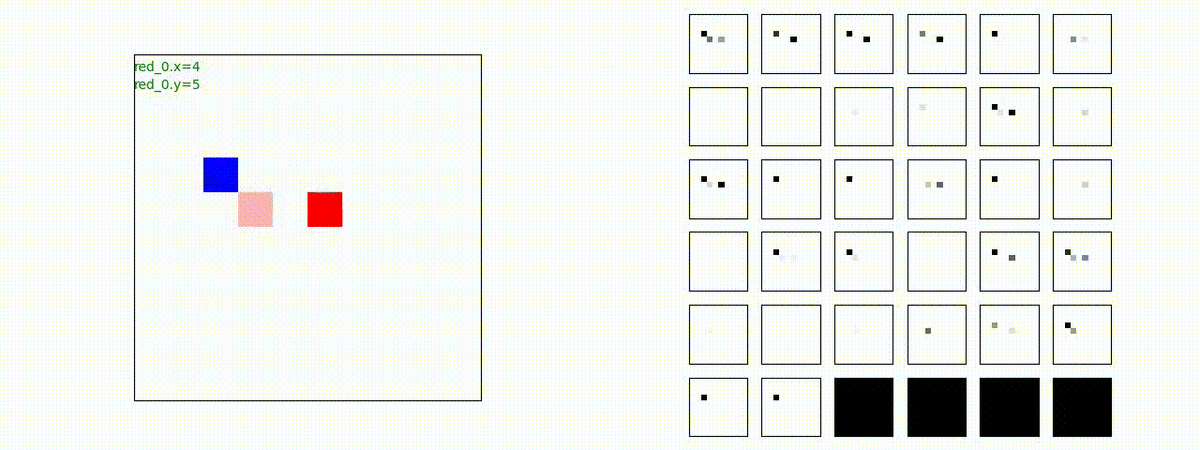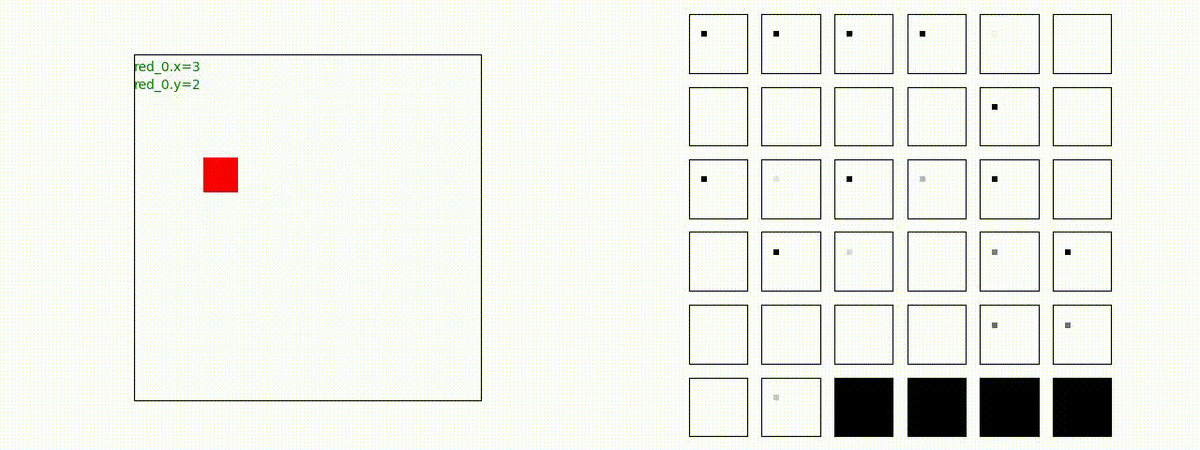
Red team = 5 swarms vs Blue team = 5 swarms
同様に、完全に一丸ではありませんが、敵よりも大きな 'mass' を構成して、敵を撃破していく戦術が生成できています。
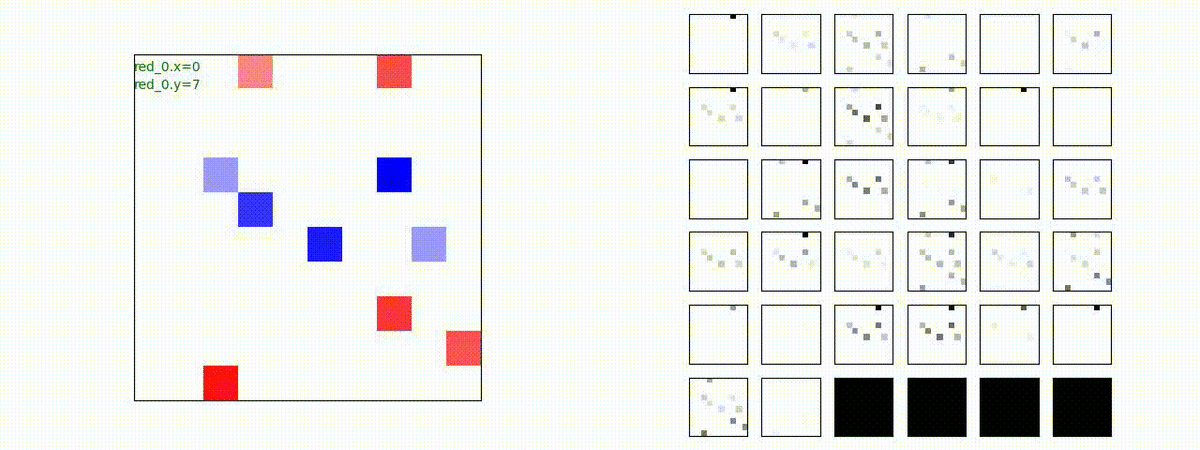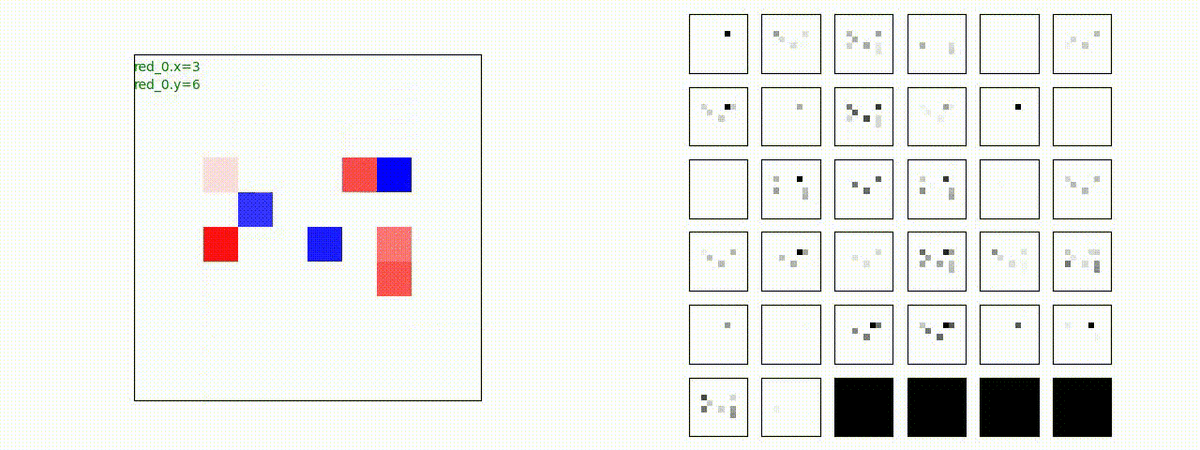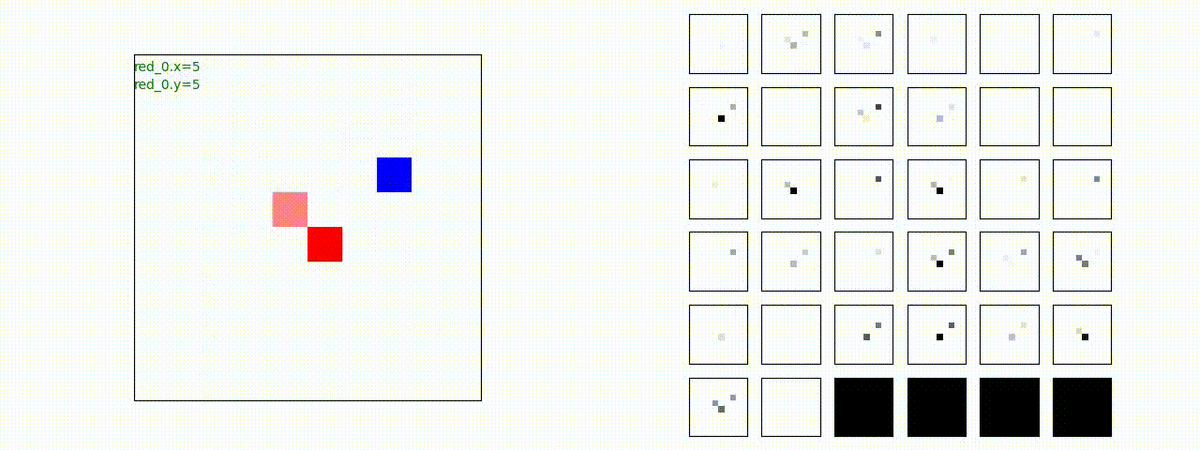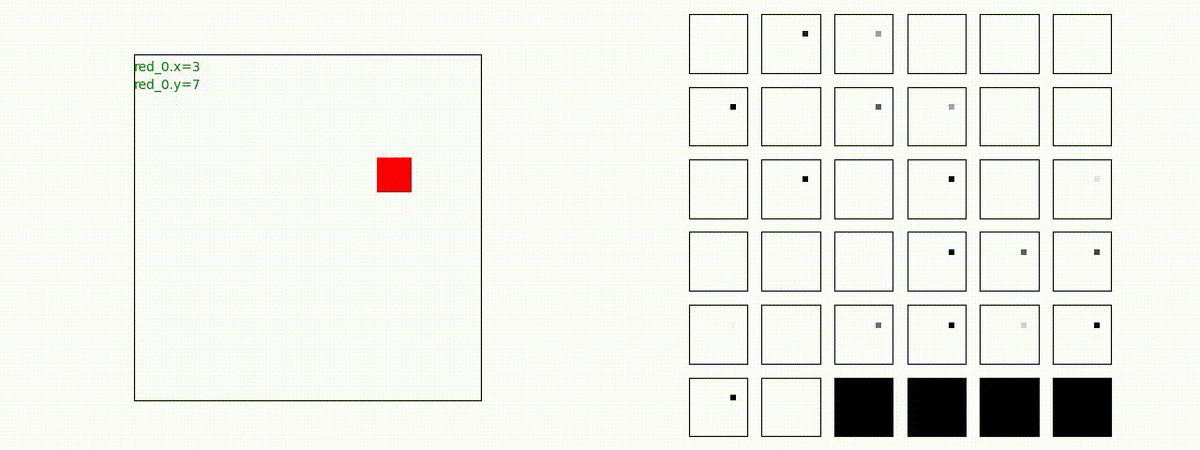
Red team = 8 swarms vs Blue team = 7 swarms
同様です。
汎化時の生成戦術例
トレーニング時よりも多いエージェント数(群数)のシナリオを使って、戦術を生成してみます。
Red team = 10 swarms vs Blue team = 1 swarm
これは学習時よりも多い red team のエージェント数での戦闘シナリオです。群数が外挿方向に増えても、"mass" 重視の戦術が生成出来ています。
特にこのシナリオでは、Blue teamは巨大な兵力を持った1つの群となっていて、これを撃破するための Red team が採り得る唯一の戦術は、Red team のエージェントが1つの塊となってから初めて Blue team のエージェントがいるグリッドに進出することです。この戦術が生成されていることが判ります。
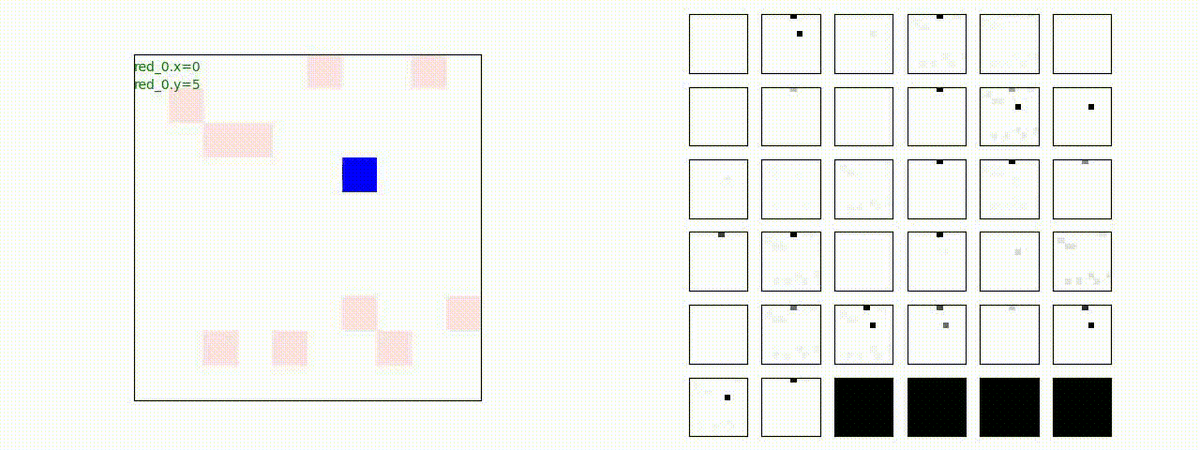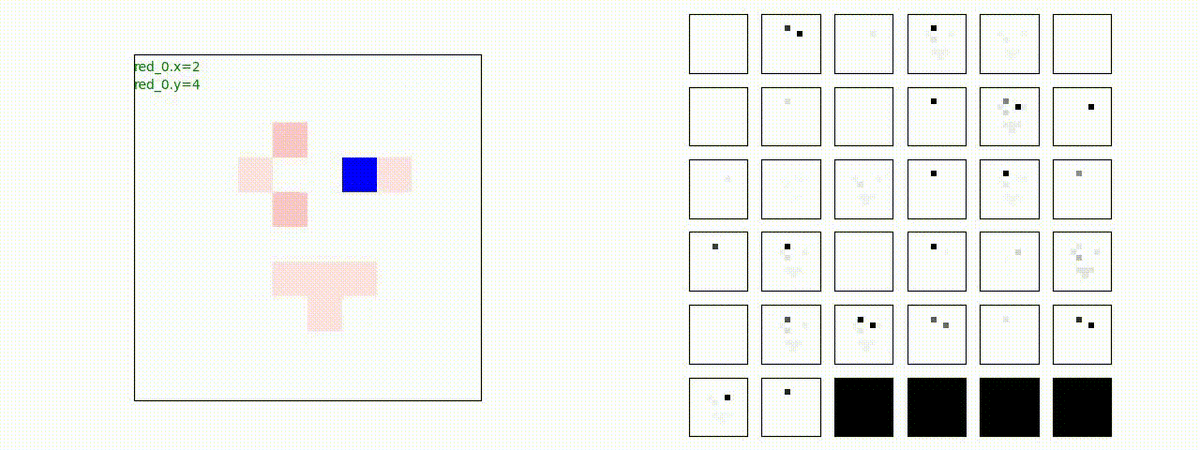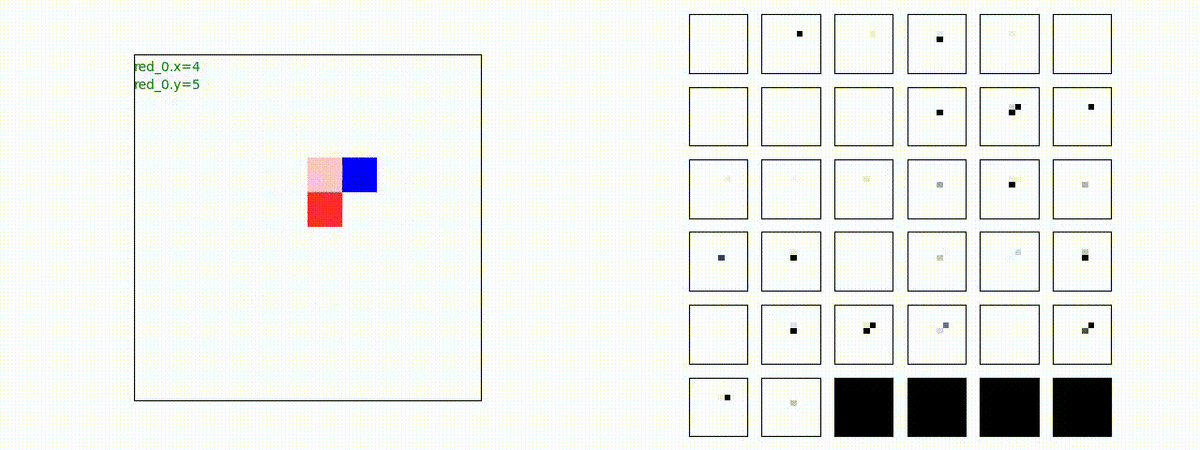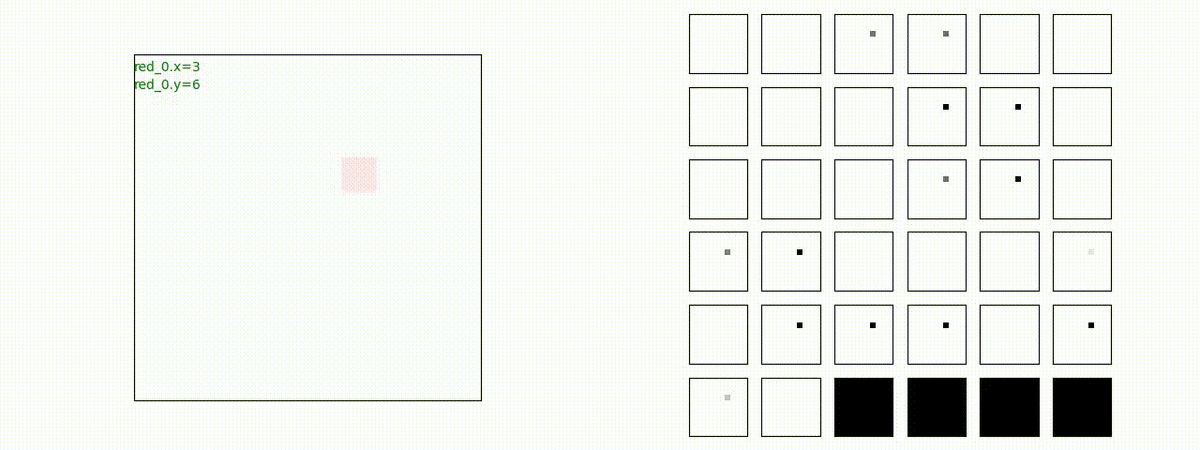
Red team = 1 swarm vs Blue team = 10 swarms
これは学習時よりも多い blue team のエージェント数での戦闘シナリオです。巨大な兵力で、弱小な敵を順に撃破していく必要があります。群数が外挿方向に増えても、敵を順に撃破していく戦術が生成できているのが判ります。
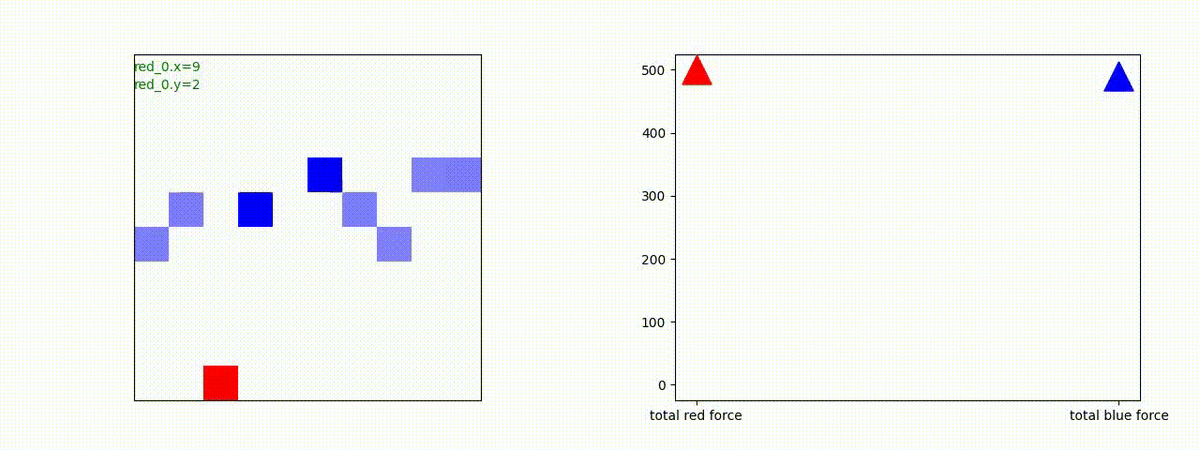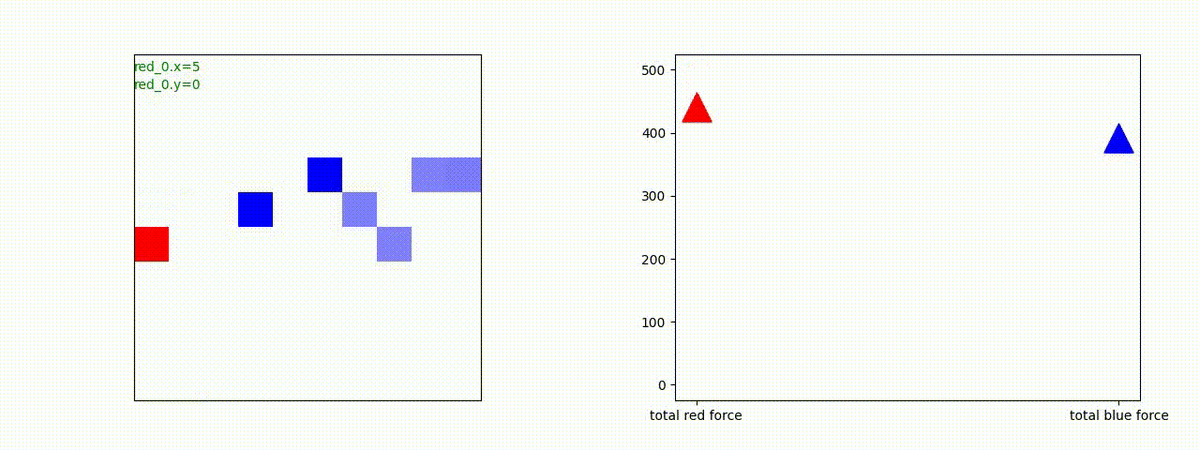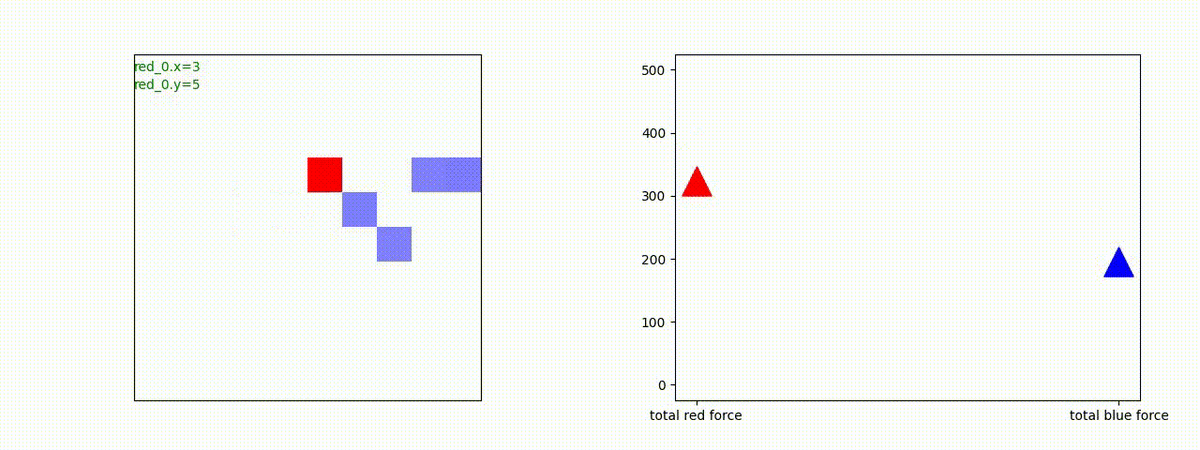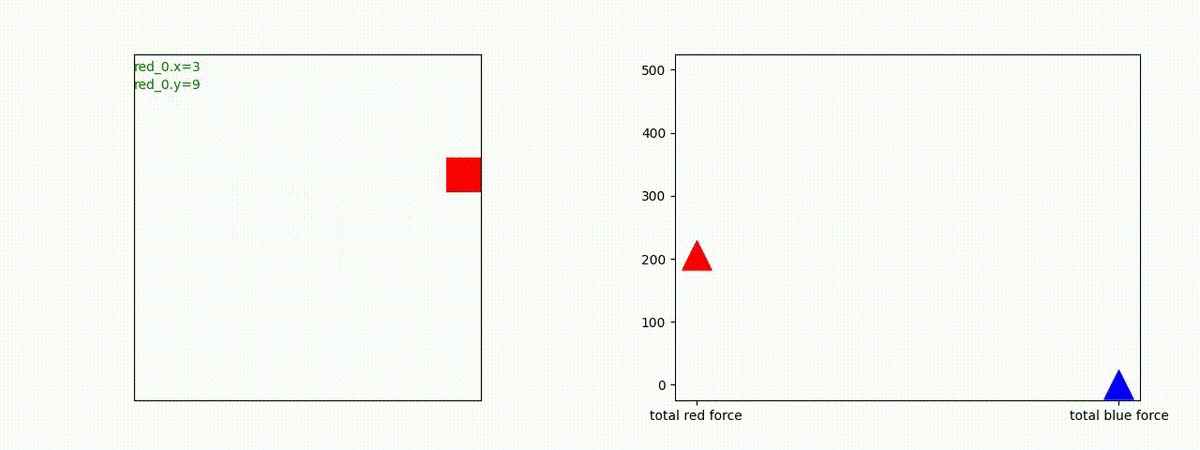
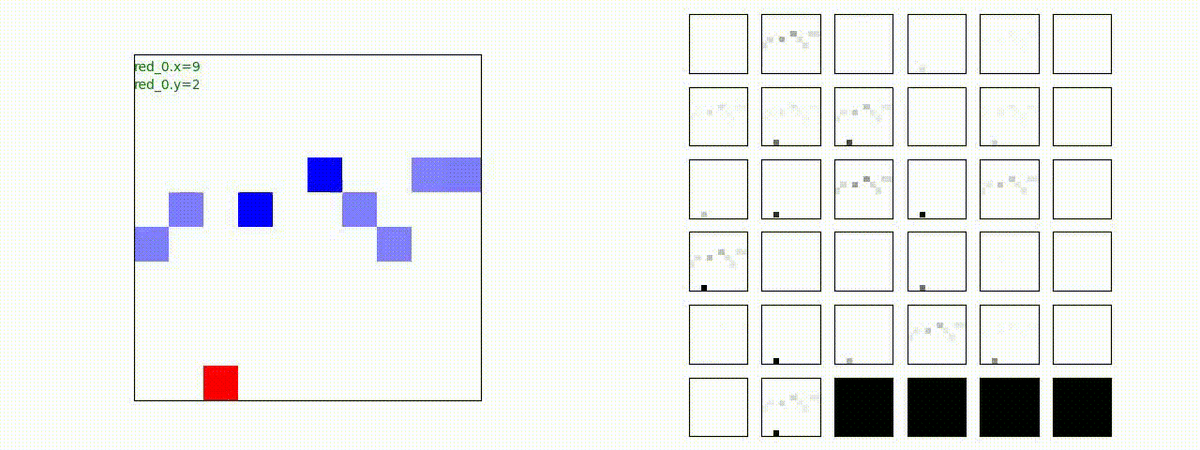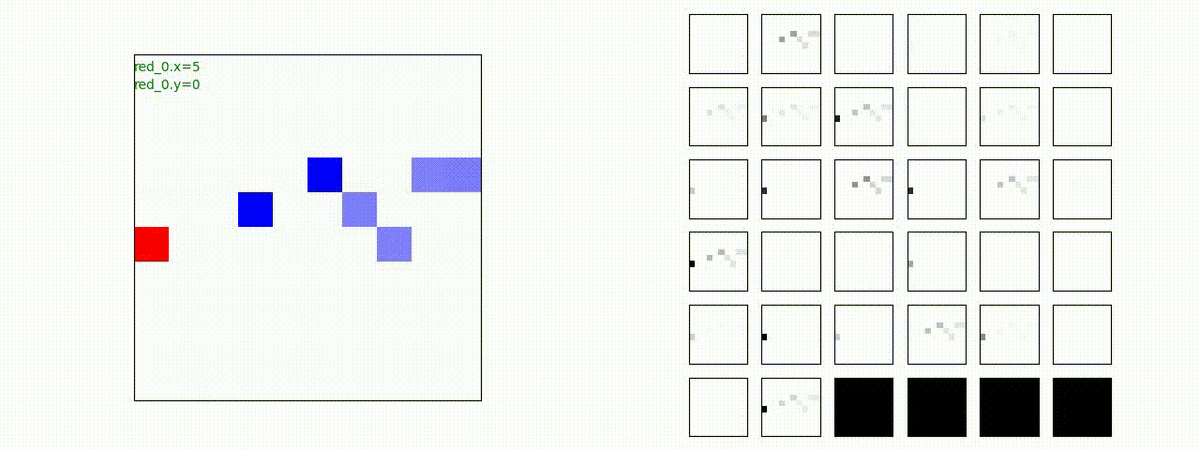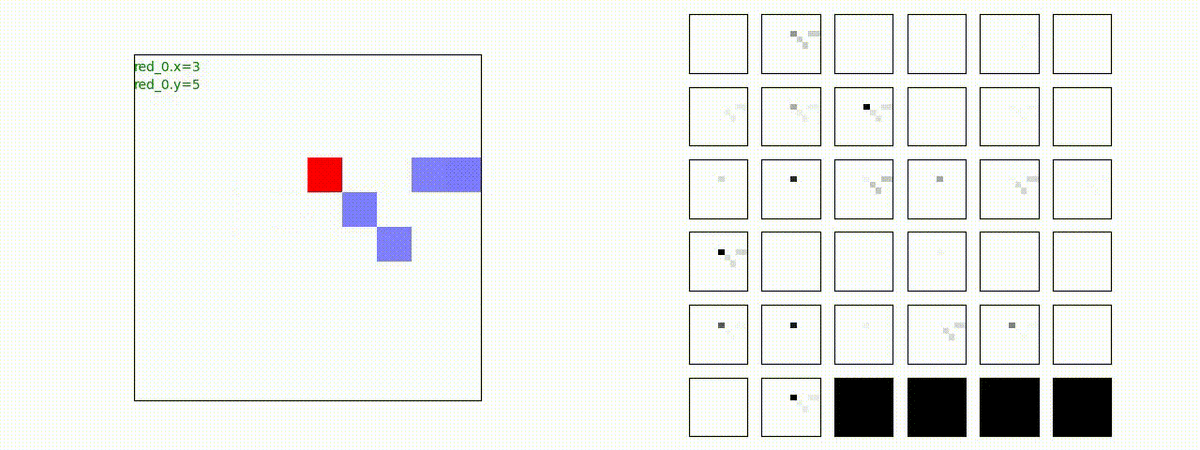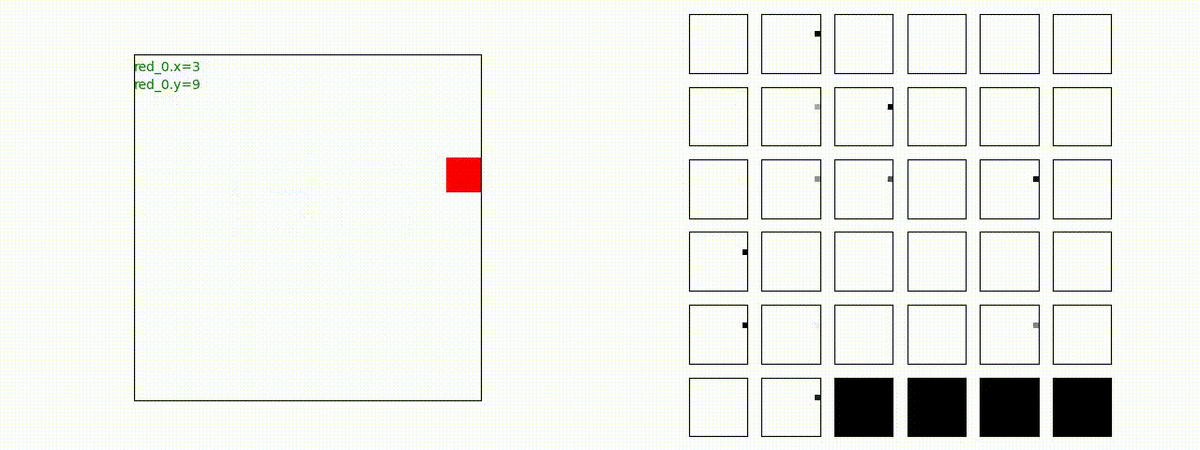
Red team = 10 swarms vs Blue team = 10 swarms
これは、彼我ともに学習時よりも多いエージェント数での戦闘シナリオです。群が完全に一丸となった "mass" 重視の戦術の生成とまでは行っていませんが、敵よりも巨大な 'mass' を構成して、敵を撃破していく戦術が生成できているのが判ります。
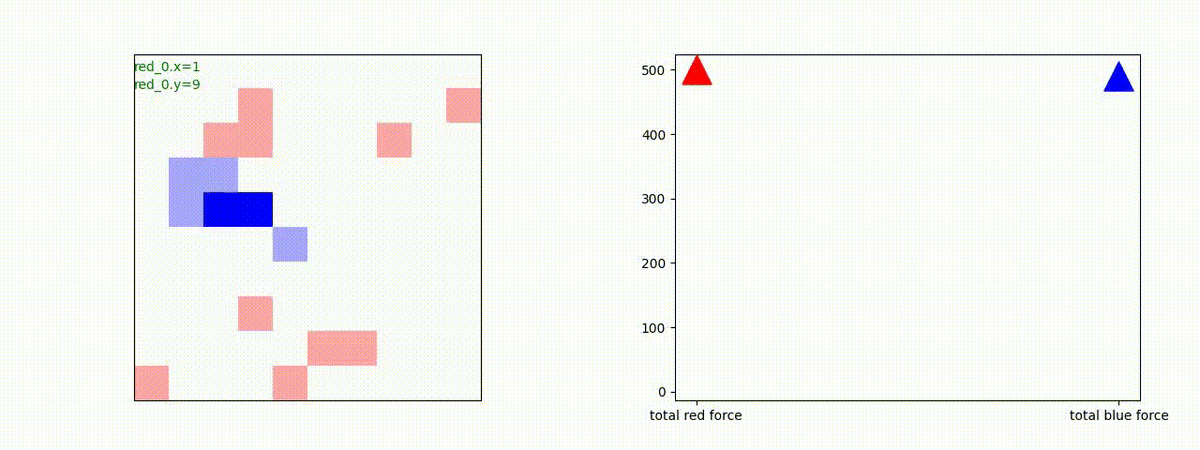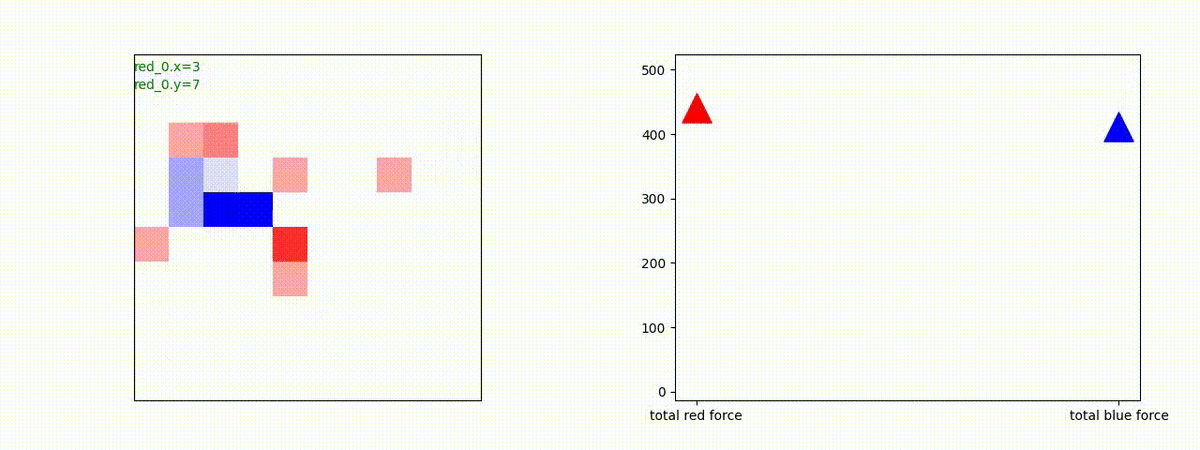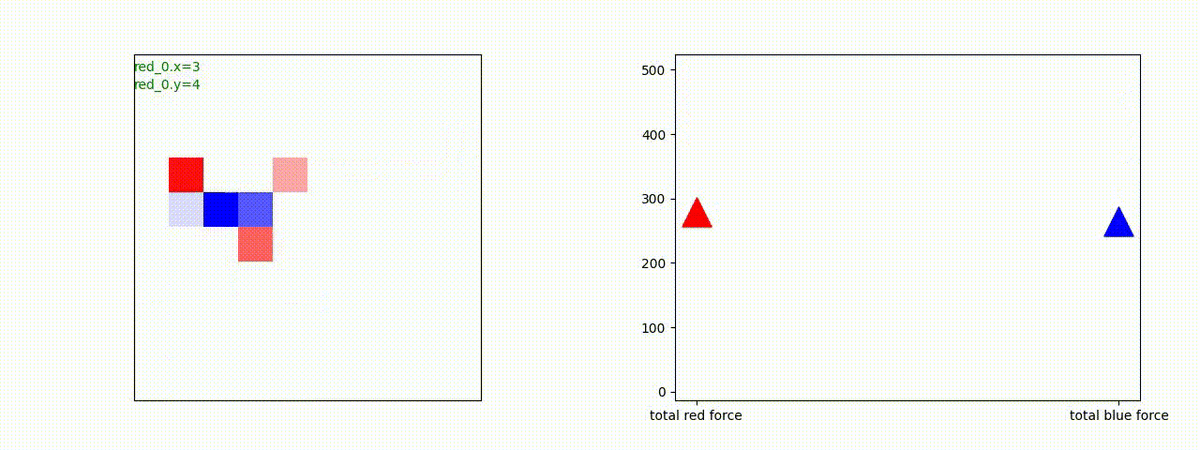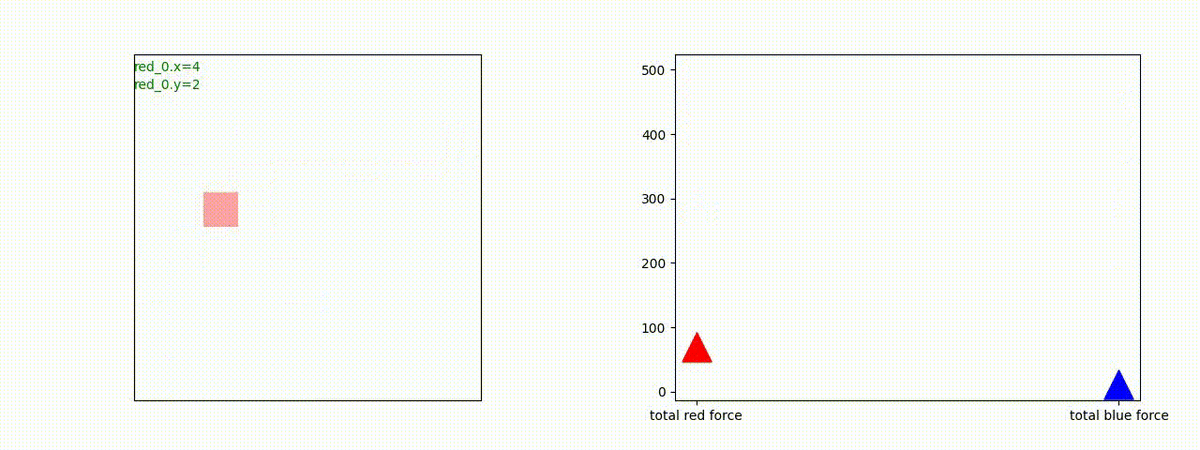
将来研究
今回トレーニングしたエージェントは、全体としての性能バランスは、(その3)でトレーニングした少数群戦闘エキスパートや(その4)でトレーニングした多数群戦闘エキスパートよりも優れています。
しかしながら、特に、少ないエージェント(群)で構成された Blue team に、多数のエージェント(群)で構成された Red team で当たるようなシナリオになるほど、性能が劣化し学習が不十分になっていることが判りました。巨大な兵力の群に、小分けにされた小さな兵力の多数の群で戦闘することほど、学習が困難なようです。ここは、少ないエージェント(群)で構成された Blue team に対する戦闘は(その3)でトレーニングした少数群戦闘エキスパートに任せた方がよさそうです。
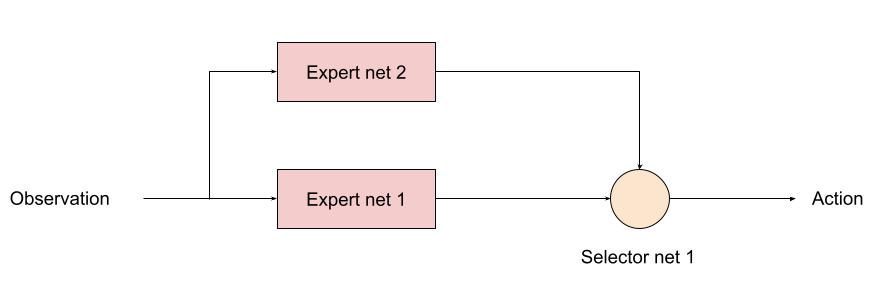
そこで、今回学習したエージェントを使って、転移学習により少数群戦闘エキスパート(Expert 1)と多数群戦闘エキスパート(Expert 2)をトレーニングすることが考えられます。
全体アーキテクチャは、下図を考えました。ここで、Expert 1 と Expert 2 の重みの初期値を今回トレーニングしたエージェントの重みとします。また、selector net 1 は適当なアーキテクチャを持ったニューラルネットで、重みはランダムに初期化します。
※ 将来研究として、(その4)では先にエキスパートを個別にトレーニングし、それらをフリーズさせて、後からセレクタをトレーニングする方法を考えてみましたが、今回のはその逆です。工業製品的には(その4)のやり方が良いと思います。今回の案は純粋に私の好奇心です。このセットアップで、自動で、少数群戦闘エキスパートと多数群戦闘エキスパートとに「分化」してくれるのか興味があります。たぶん、何らかの工夫が必要です。これは、ひと段落したらやってみたいと思います。
まとめ
- Red team の初期エージェント数(群数)を [1, 8]、Blue team の初期エージェント数(群数)を [1, 7] として、ネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、完璧ではありませんが、"mass" を構成して戦う戦術を学習でき、上手く戦況をハンドリングできている(ほとんどいつも Blue team を殲滅できる)ことが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を外挿方向に増やしても(つまり、戦力の小さな多数群にしても)、戦闘性能は劣化しませんでした。
実際の戦闘では、シナリオによって、"mass" と ”Economy of Force” のバランスを変えた戦術が欲しいことがあります。このため、次回記事では、本手法で "mass" と ”Economy of Force” のバランスを変えた戦術を生成できるのか試してみます。