GitHub Code
作成した Code は、下記 GitHub の ”A_SimpleEnvironment” フォルダにあります。
GitHub - DreamMaker-Ai/MultiAgent_BattleField
実施内容
- はじめに、Red team の初期エージェント数(群数)を [1, 3]、Blue team の初期エージェント数(群数)を [1, 2] として、少数群 vs 少数群の設定でネットワークをトレーニングし、その性能を評価します。
- 次に、ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を増やして(つまり、戦力を小分けにして散開させて)戦闘性能がどの程度劣化するのか見てみます。
実行環境
- Google Cloud Platform (GCP) preemptive E2 12 vcpu で 24時間 x 2。DenseNet ベースの画像処理が結構大きいので、本当は gpu を使いたいのですが、preemptive では使わせてもらえないらしいので、cpu だけで頑張っています。
- 22 rollout workers(トレーニング対象となるRed teamエージェント数が最大3なので、多めに設定しました。この辺り、あまり根拠はないです。)
- CPU使用率 66% 程度だったので、もう少し少ない vcpu でいけると思いました。お金に余裕があれば、1 worker に 1 agent を割り当てると効率が良いはずです。
PPOハイパーパラメータ
- Learning rate: lr = 5e-5, Adam
- Discount factor: γ = 0.99
シミュレーション条件
各チームの初期エージェント数(群数):各エピソードの初めに、Red team のエージェント数(群数)を [1,3] から、Blue team のエージェント数(群数)を [1,2] から乱択します。
Initial Force(初期兵力):各エピソードの始めに、両チームともに、ランダムに Force をチームのエージェントに配分します。エージェントの Force の最小値は 50 とします。Red team の Initial Force の合計は 500、Blue team は 490 としました。したがって、Red team の最大エージェント数(群数)は 10、Blue team は 9 になります。また、エージェント数が増えるほど、ほぼ同じForceの群となっていきます。この辺りは、将来もう少し工夫したいと思っています。
Efficiency(武器性能):全エピソードで、両チームともに 0.6 で固定しました。この場合、1タイムステップにおける兵力の消耗が大きいので、'mass' の戦術を採るためには、敵がいるグリッドに一丸となって侵攻する「タイミング・コントロール」が非常に重要となります。私の経験では、タイミング・コントロールは、強化学習の苦手とするところなので、少しだけチャレンジングです。
兵力消滅判定条件:エージェントの force が消耗して、初期兵力の10% 以下になると、そのエージェントは消滅することとしました。Δtが小さい場合、Lanchester モデルの解は0に漸近します。このため、この仮定が無いと Force=0 にならないので、戦闘が永遠に続いてしまう場合がありますので注意が必要です。
エピソード終了条件:各エピソードにおいて、どちらかのチームのエージェントが全て消滅するか、シミュレーション・ステップが最大値(=100)に達した場合、そのエピソードは終了とします。
トレーニング履歴
以下のグラフの途中で色が変わっているのは、GCP の Preemptive vm が最大24時間でシャットダウンされてしまうので、シャットダウン後、継続学習を行っているためです。(お金が無いので、ケチっているだけです)。
下図で、縦軸はエピソード報酬、横軸が更新ステップです。安定して学習しているのが判ります。
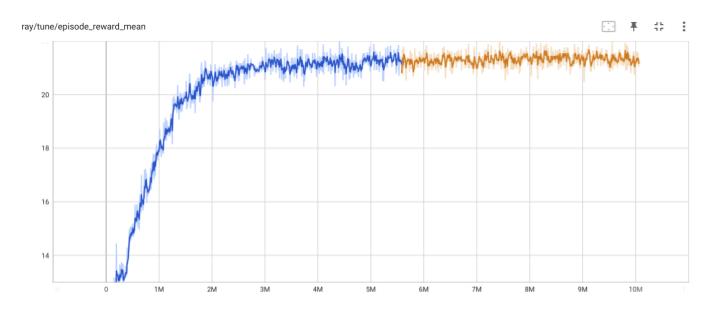
下図は、平均エピソード長の履歴です。戦場サイズが 10x10 なので、平均エピソード長が12ぐらいになっていて、妥当ではないでしょうか。

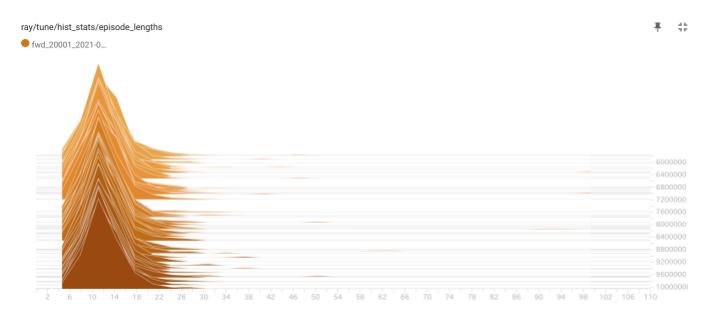
下図は、学習後半のエピソード長の分布履歴です。
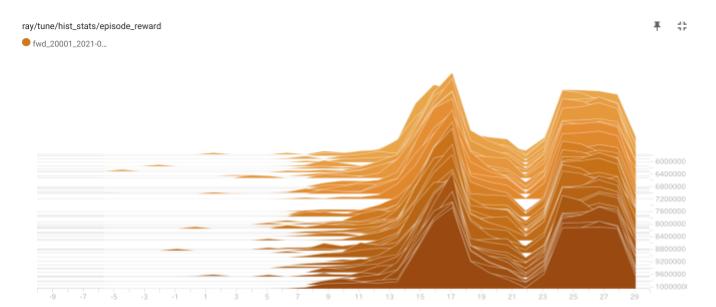
チーム報酬の分布は、双峰性になりました。これは、初期エージェント数により、得られる報酬が2通りあることを意味しています。ここは、もう少し解析すべきなのですが、先を急ぎたいので省略しました。
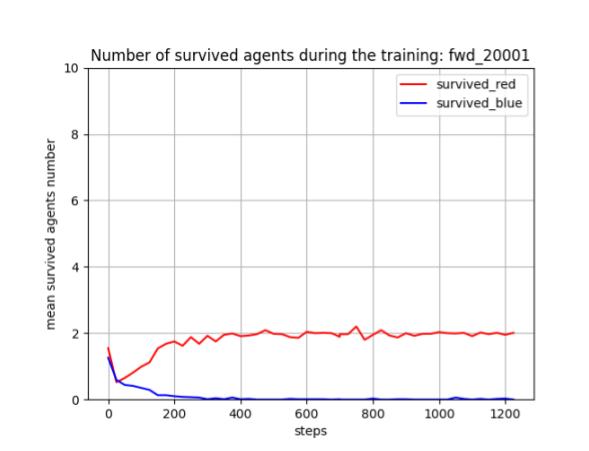
トレーニング時の評価結果
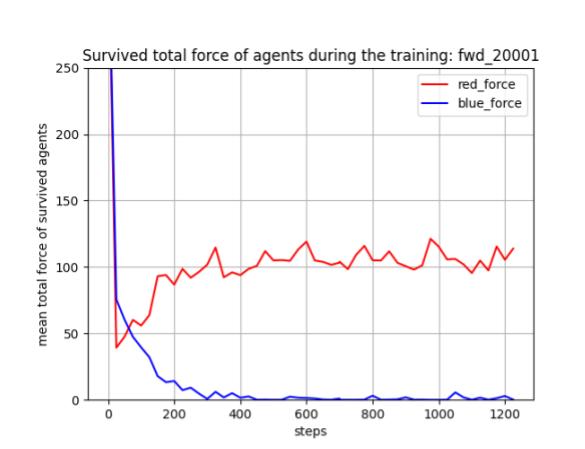
トレーニング時に、25イテレーションごとに100回テストを行って Red team と Blue team の残存エージェント数(残存群数)を評価しました。学習が進むと、Blue team の残存エージェント数が0となり、Blue team をほぼ壊滅できるようになっています。また、Red team エージェント数は [1, 3] で乱択しているので、学習が進んだ時の平均残存数=2 は、ほとんどの場合、全エージェントが残存していることを意味します。
これを平均残存兵力で見たのか下図です。Blue team の残存兵力はほぼ0になっています。Red team の残存兵力は 110 程度です。この最適解は、Red team が一丸となって、順に分割戦略で Blue team にあたった時の Lanchester model の残存兵力に近いものになっているはずです。エネルギー不足で、この計算は省略しました。いろいろ、省略が多くてゴメンナサイ。
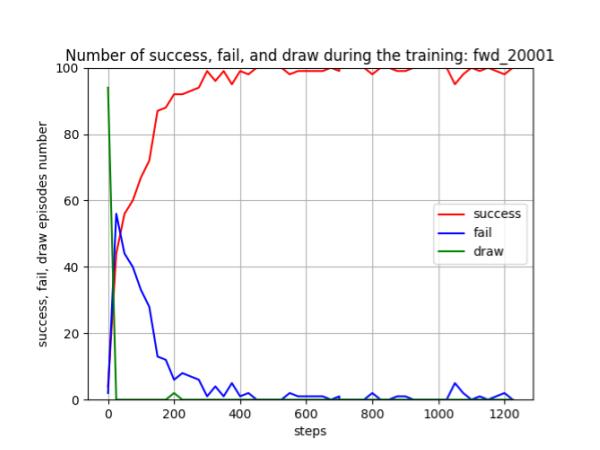
Blue team の残存兵力を0にできたエピソードを success、逆に Red team の残存兵力が0になってしまったエピソードを fail、どちらの兵力も0とはならなかったエピソードを draw と定義して、これらを100回のエピソードから算出したのが下図です。学習が進むと、ほぼ確実に success=100%、つまり、Blue team の残存兵力を0にできることが判ります。
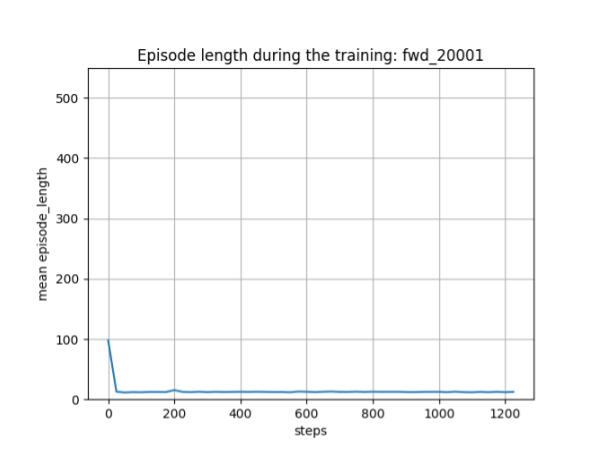
下図は、観点を変えて、エピソードの長さから学習の進捗状況を見たものです。戦域サイズが 10x10 で、エージェント数は少なく、1タイムステップでの兵力の消耗も大きいので、学習がちゃんと進んでいれば、ざっくり言って平均 10+α 回程度のタイムステップでエピソードが終われるはずです。実際、そのような結果となっています。一方、学習初期には、各エージェントは右往左往するので、最大エピソード長(=100)まで勝負がつきません。
性能評価
学習後のチームの性能を100回のシミュレーションを行って確認しました。
- NUM_RED:red teamの初期エージェント(群)数
- episode_length: 100回のシミュレーションの平均エピソード長
- red.alive_ratio:(エピソード終了時点での red team エージェント数)÷(初期 red team エージェント数)
- blue.alive_ratio:(エピソード終了時点での blue team エージェント数)÷(初期 blue team エージェント数)
- red.force_ratio:(エピソード終了時点での red team 兵力合計)÷(初期 red team 兵力合計)
- blue.force_ratio:(エピソード終了時点での blue team 兵力合計)÷(初期 blue team 兵力合計)
Blue team 初期エージェント数 = 1 の場合の結果は下表です。確実に、Blue team を撃破できる戦術を獲得していることが判ります。
BLUE Team Swarm 数 = 1
Blue team 初期エージェント数 = 2 の場合の結果は下表です。ここでも、確実に、Blue team を撃破できる戦術を獲得していることが判ります。また、Blue team が小分けになったことにより、Red team の残存兵力(red.force_ratio)が、上記 Table よりも大きくなっています。この残存兵力(red.force_ratio)が、0.33~0.36 とほぼ一定になっているので、Red team はエージェント数(群数)が多くても、"mass" を活かした戦術が生成できているのではないかと期待できます。
BLUE Team Swarm数 = 2
生成された戦術
1 swarm vs 1 swarm
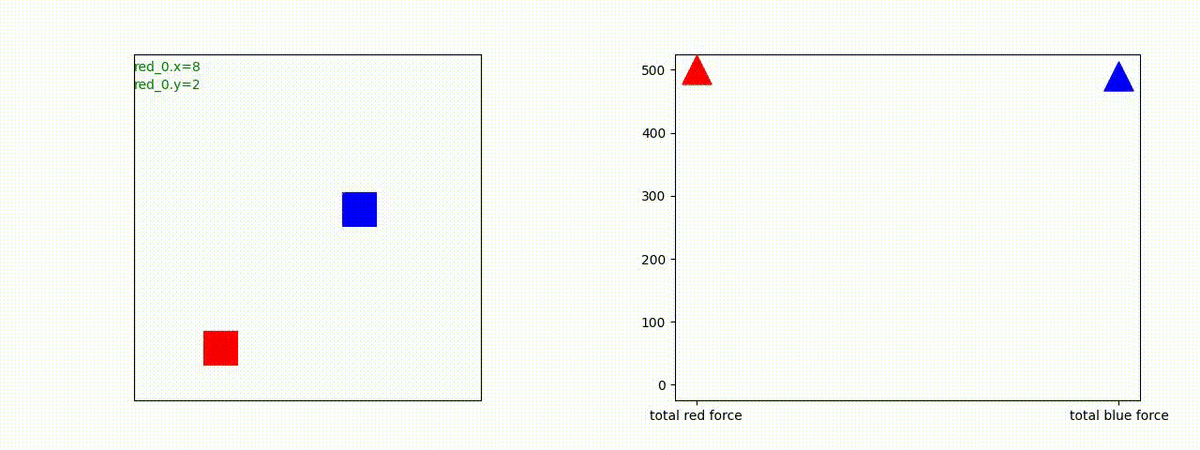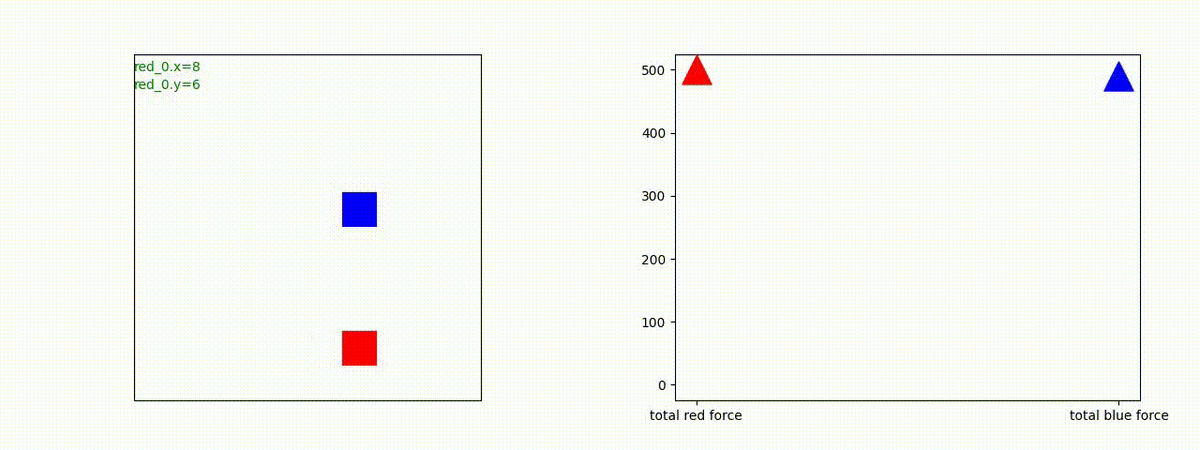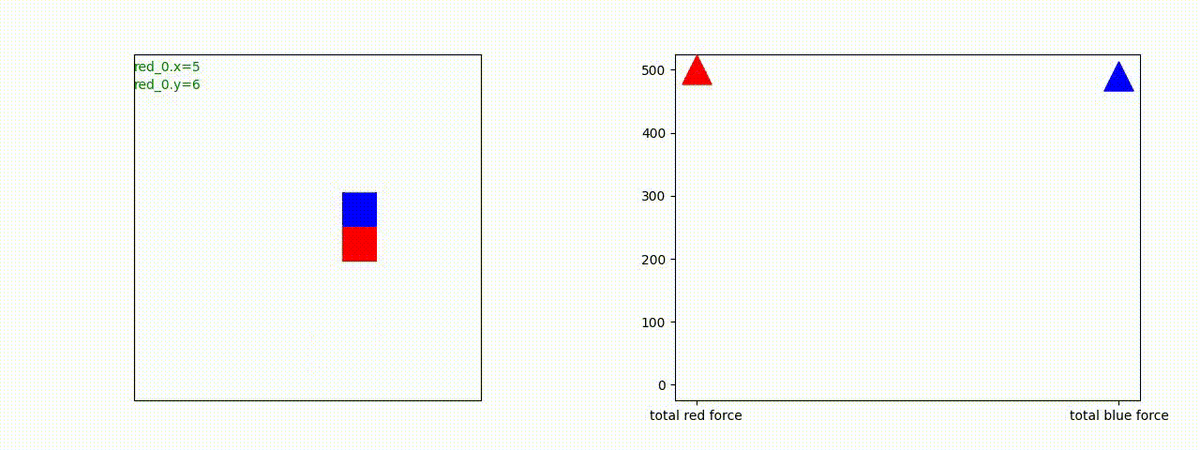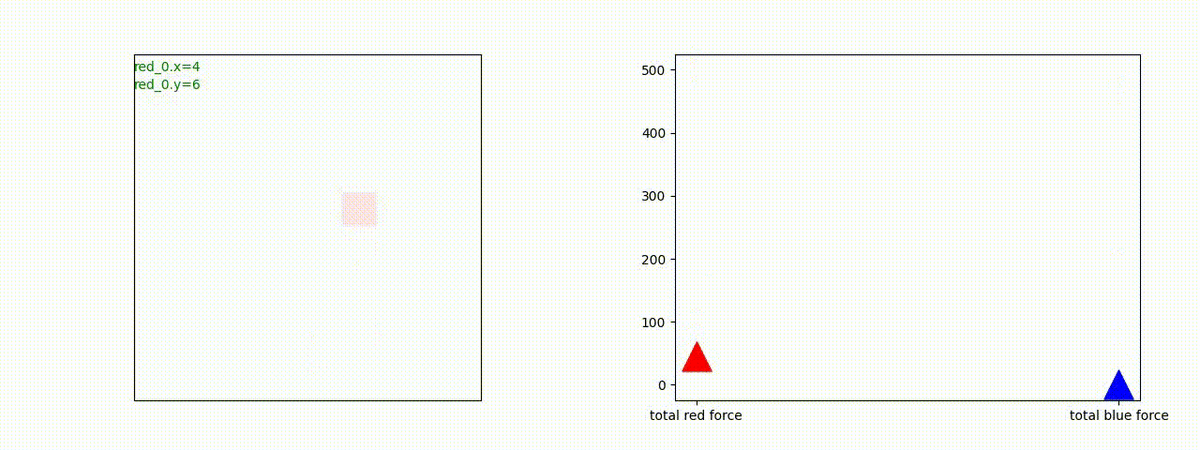
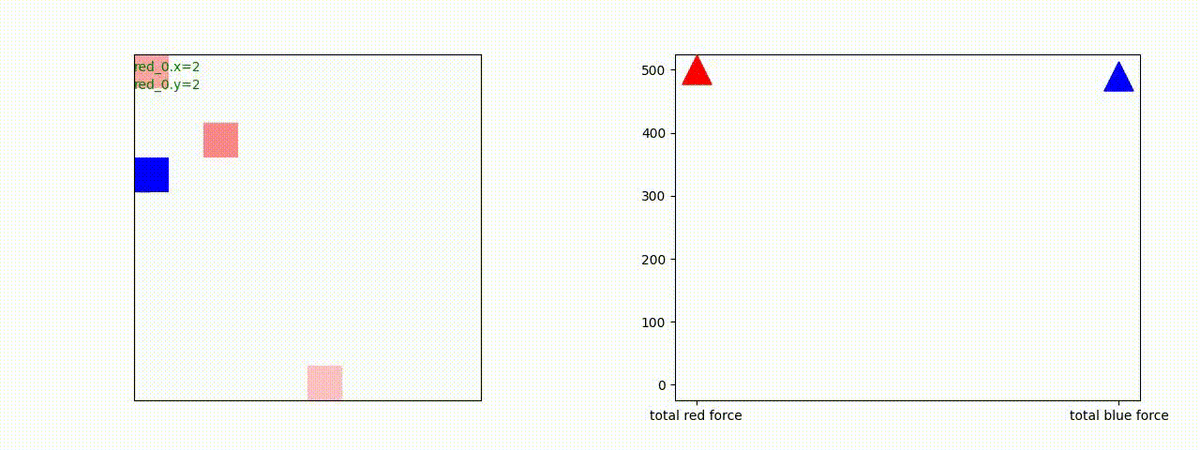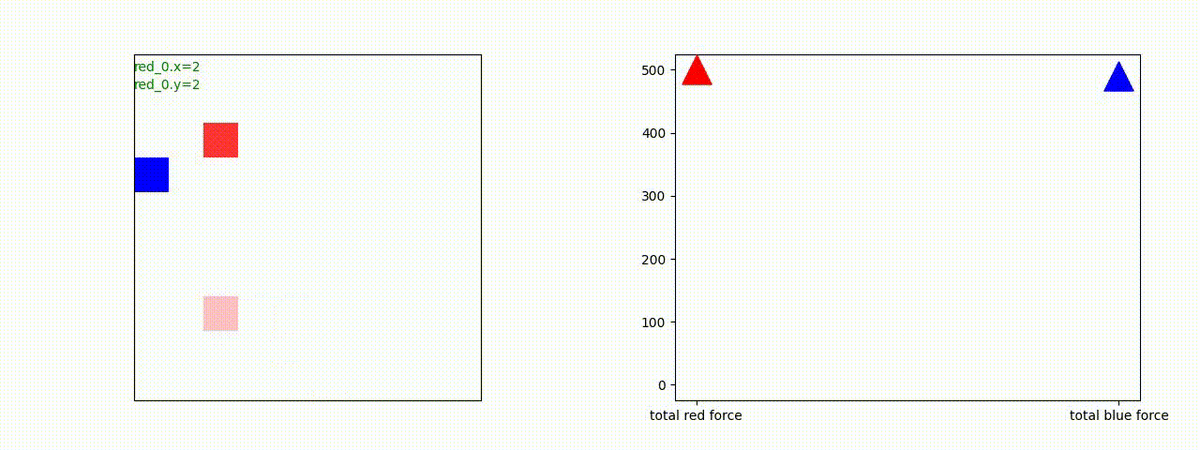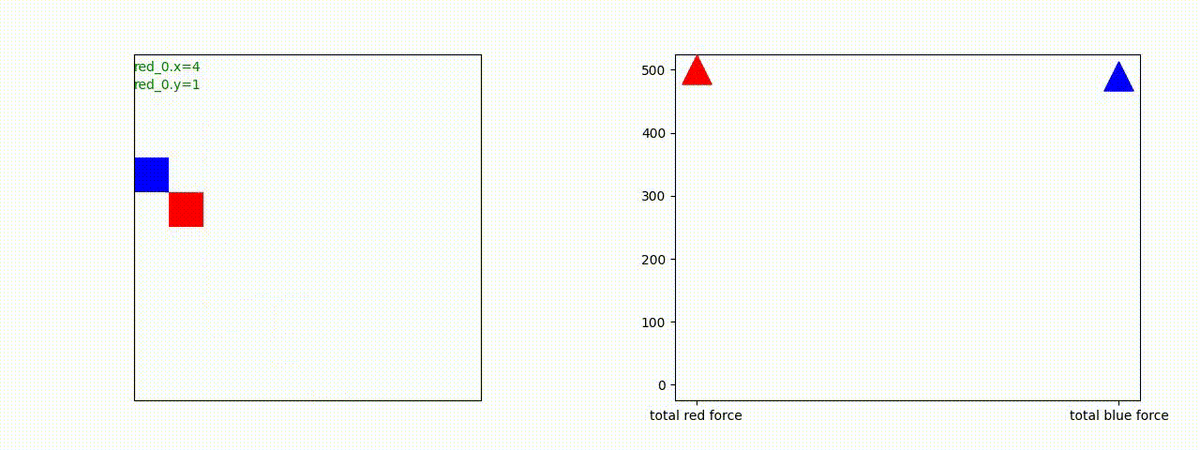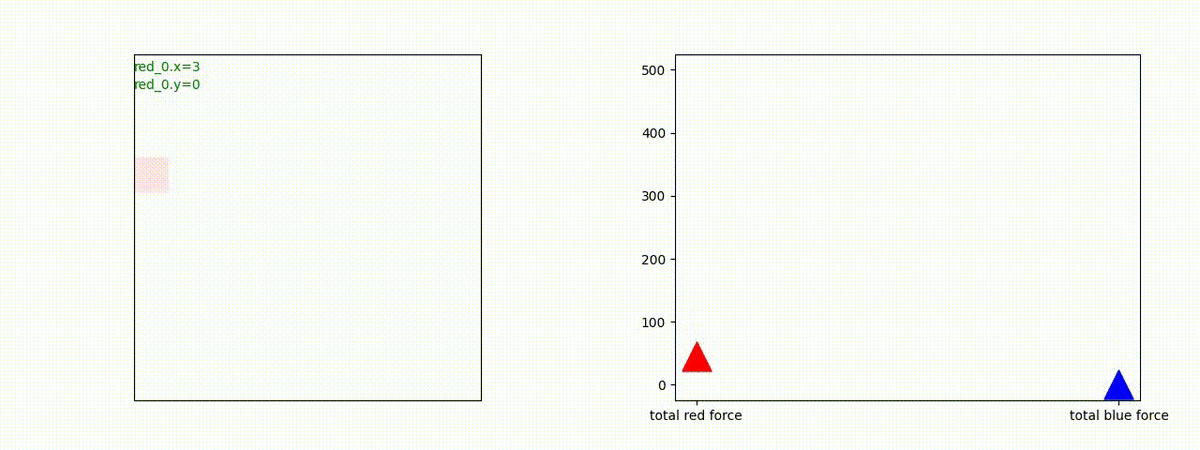
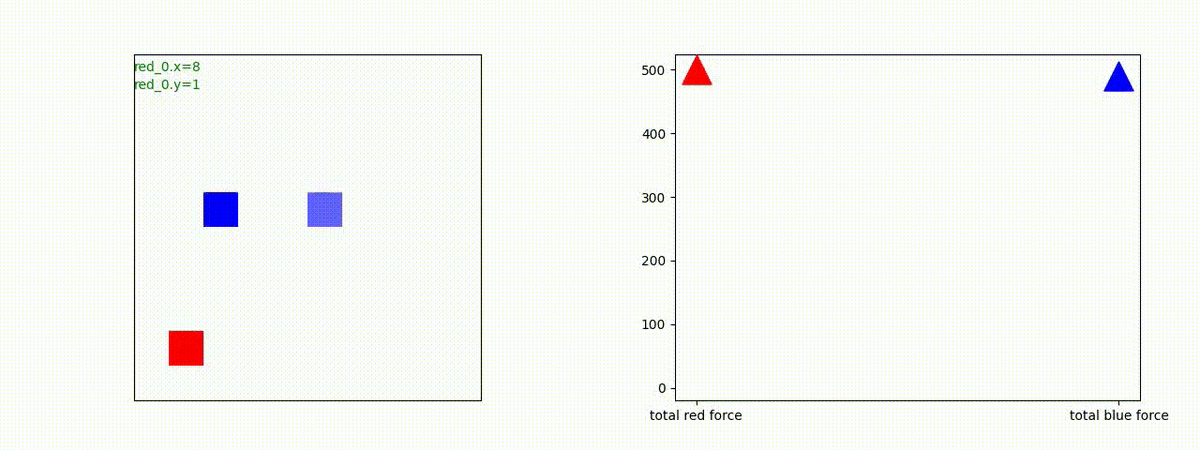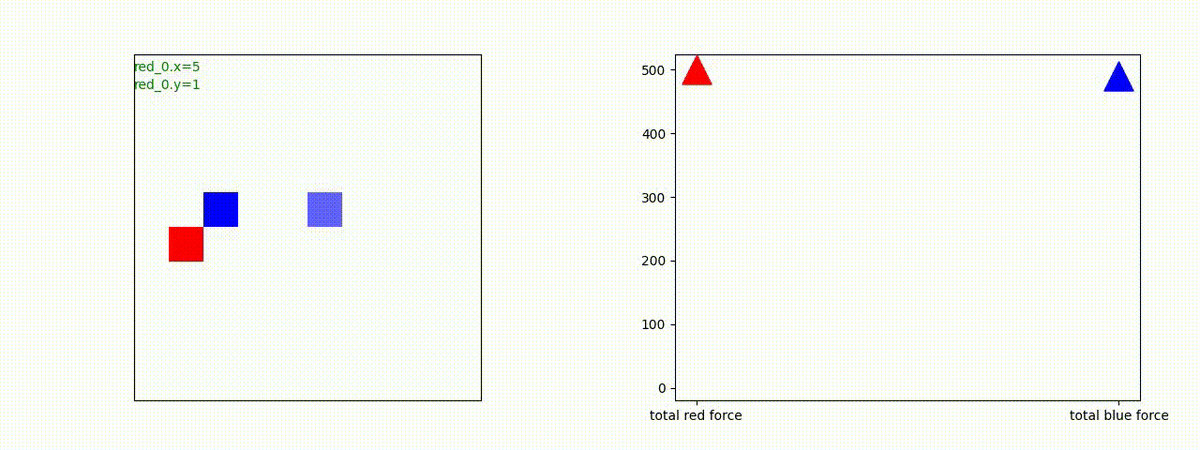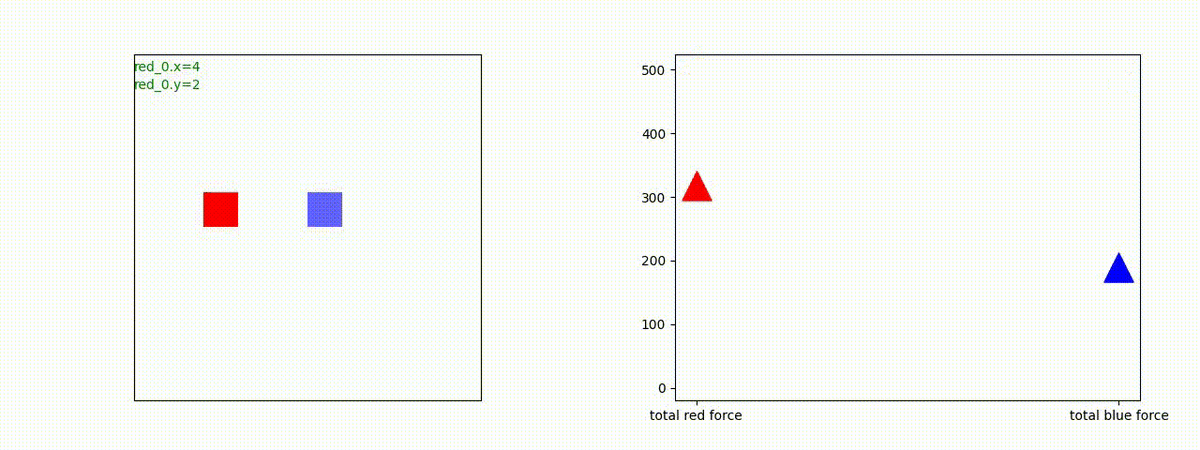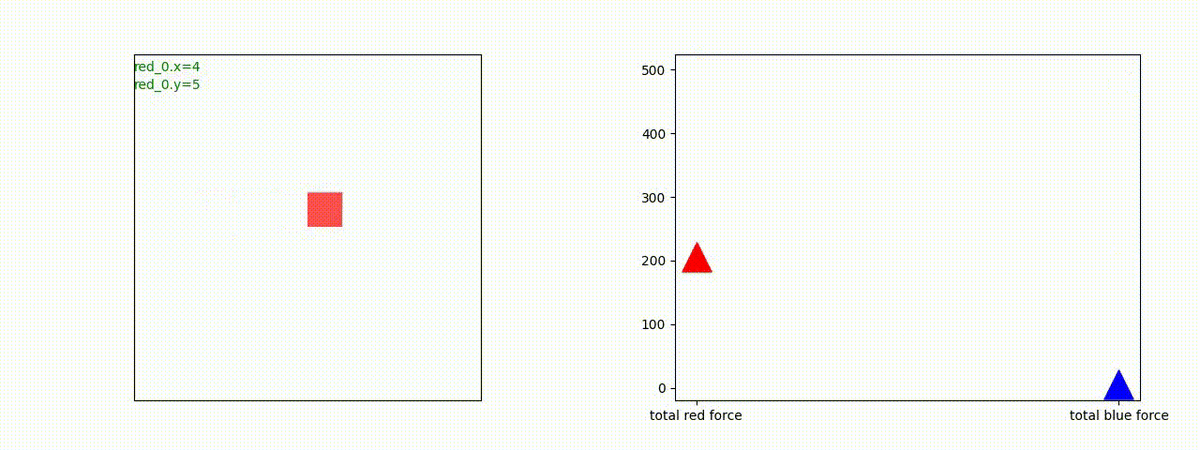
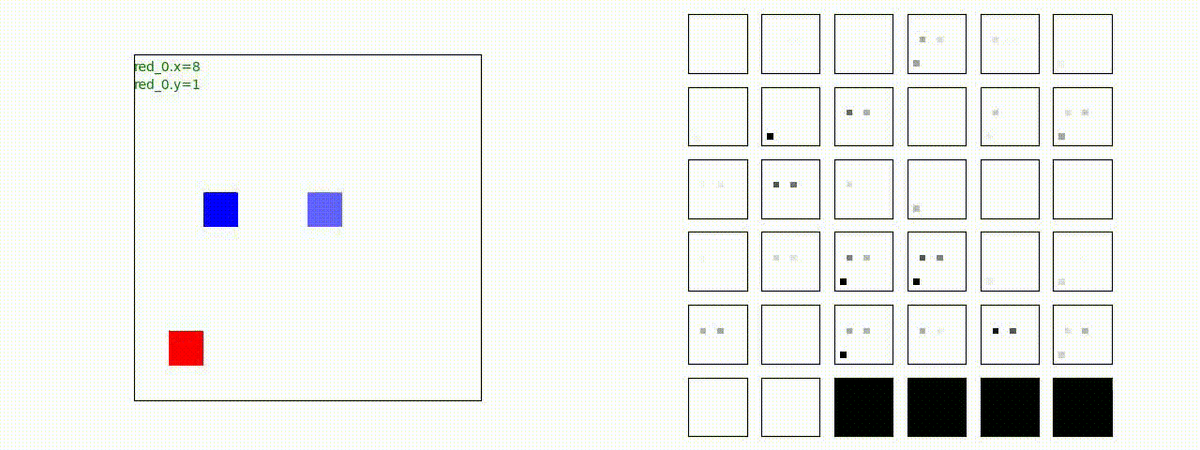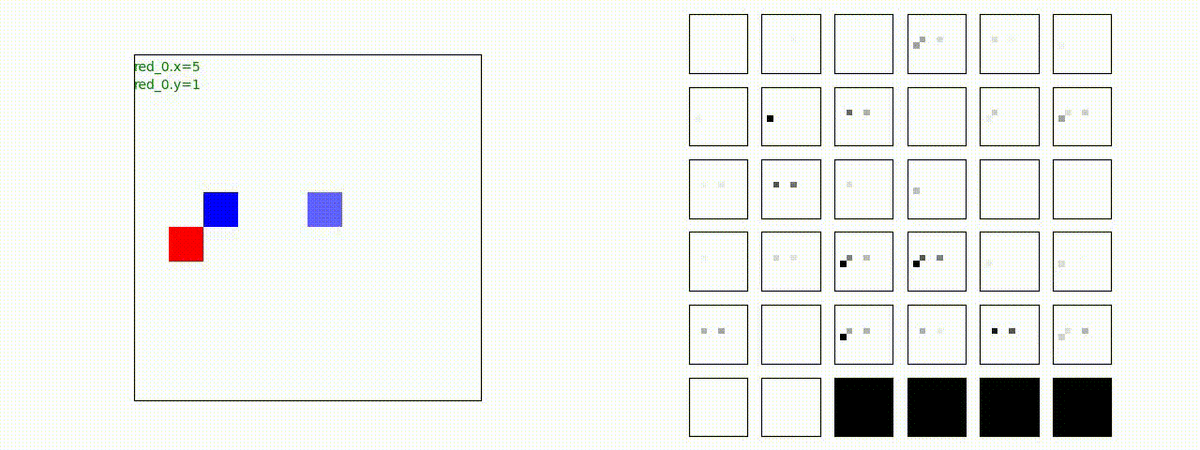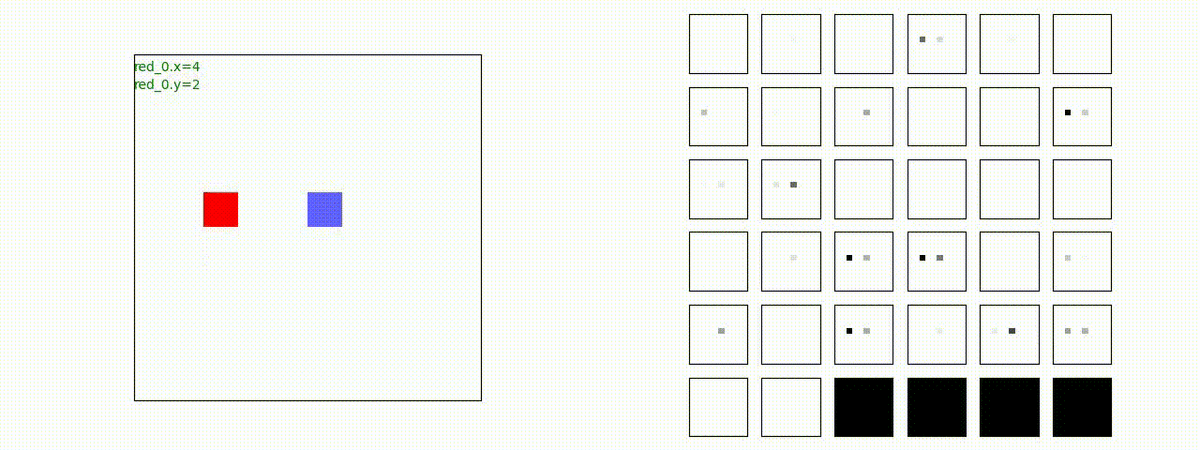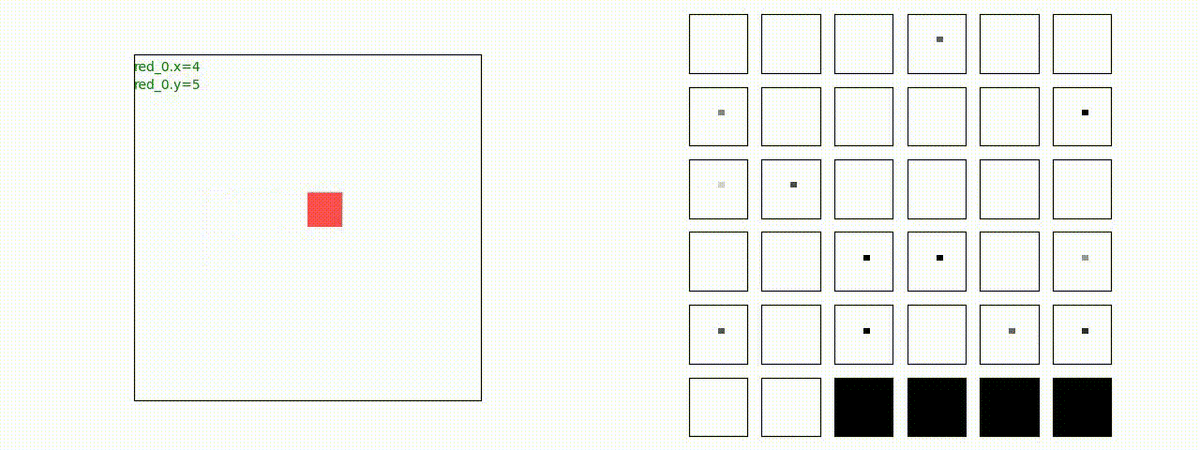
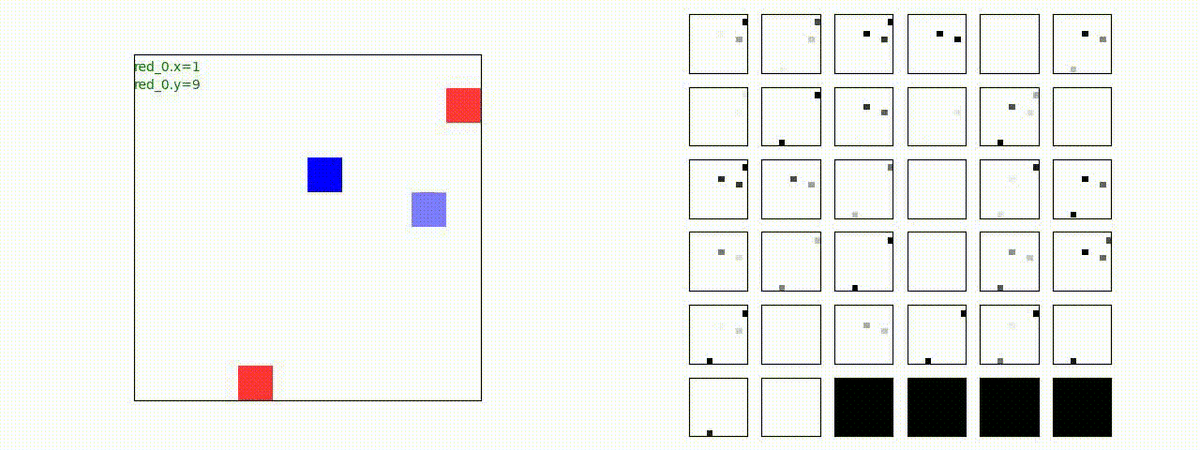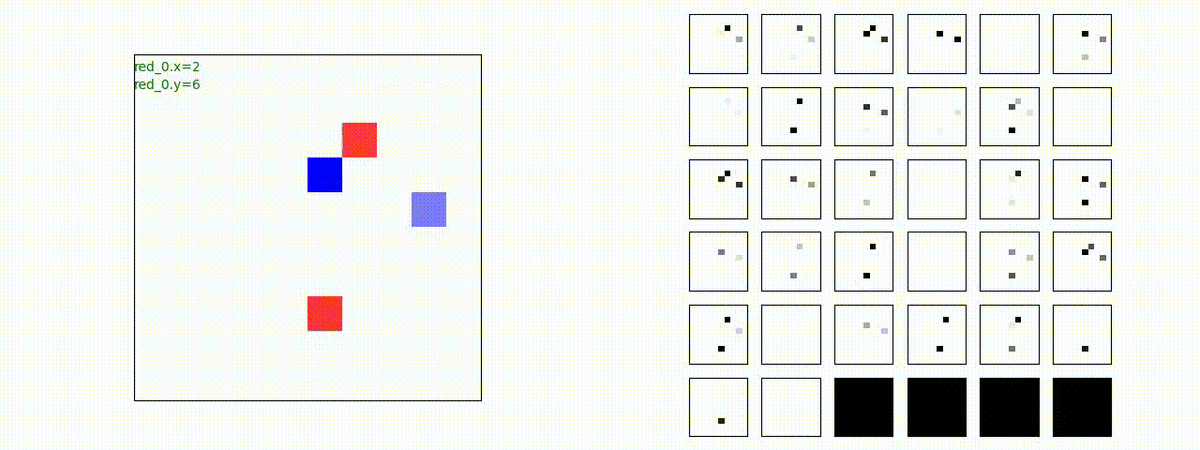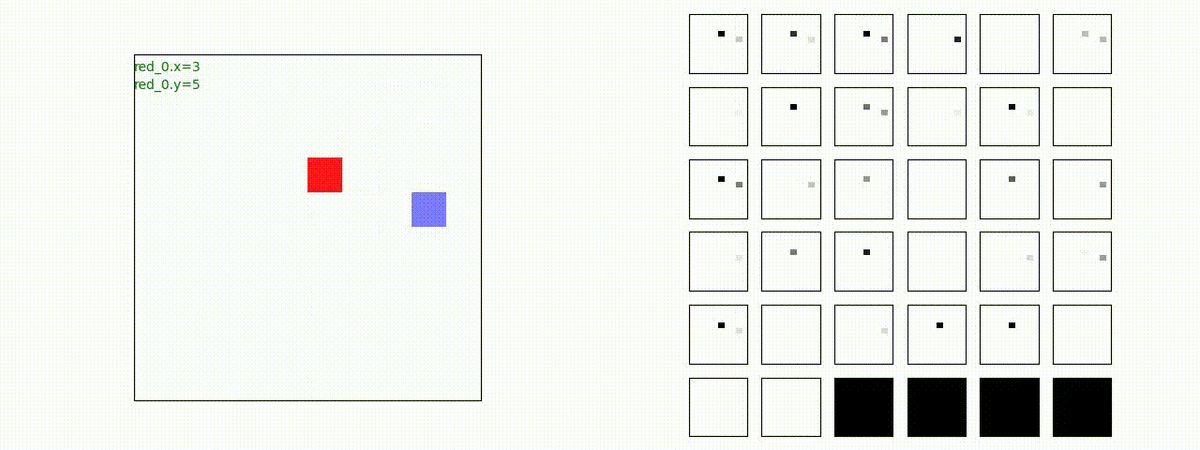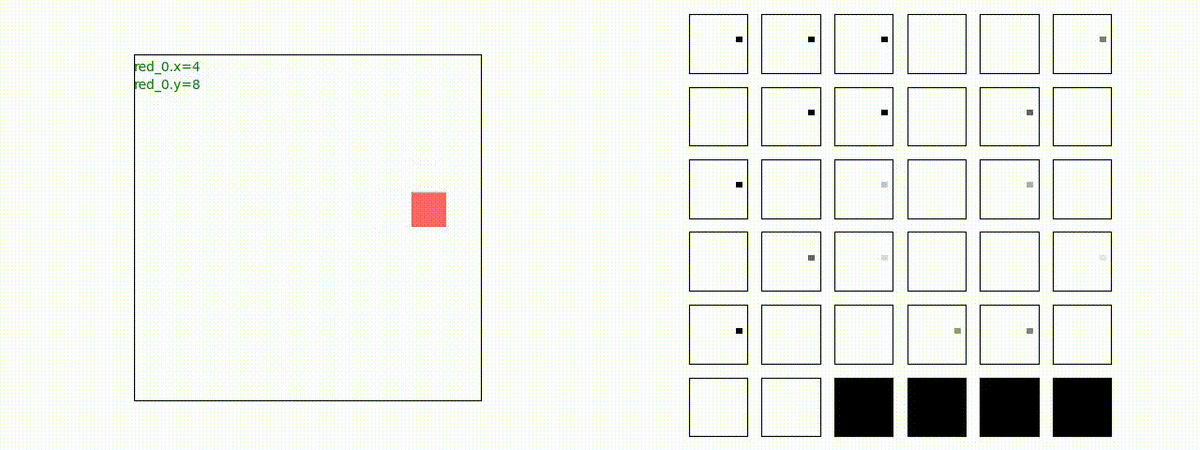
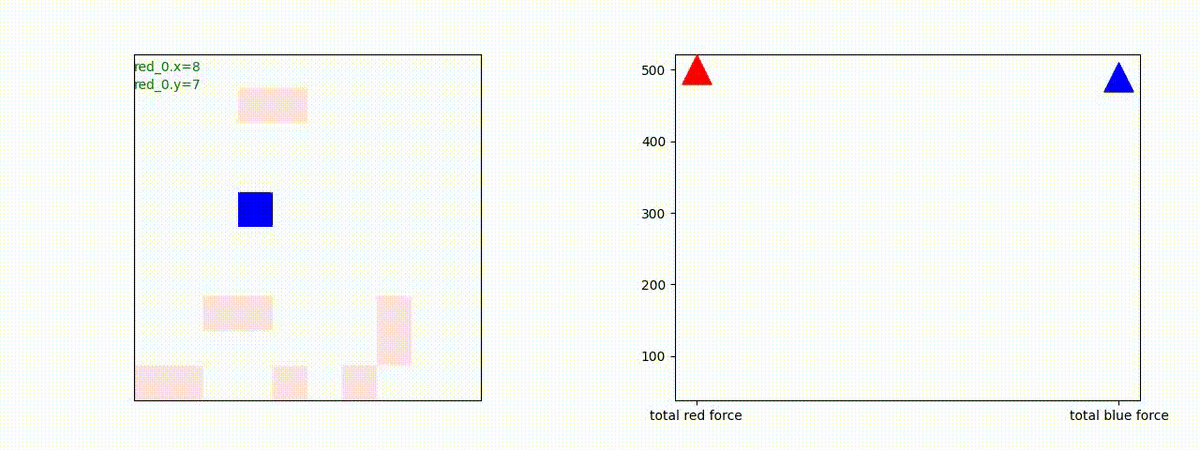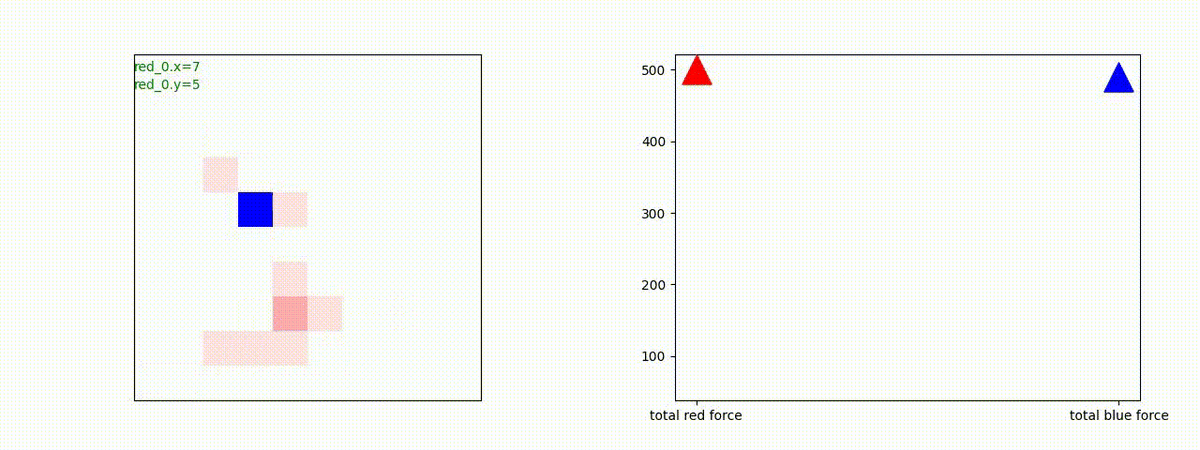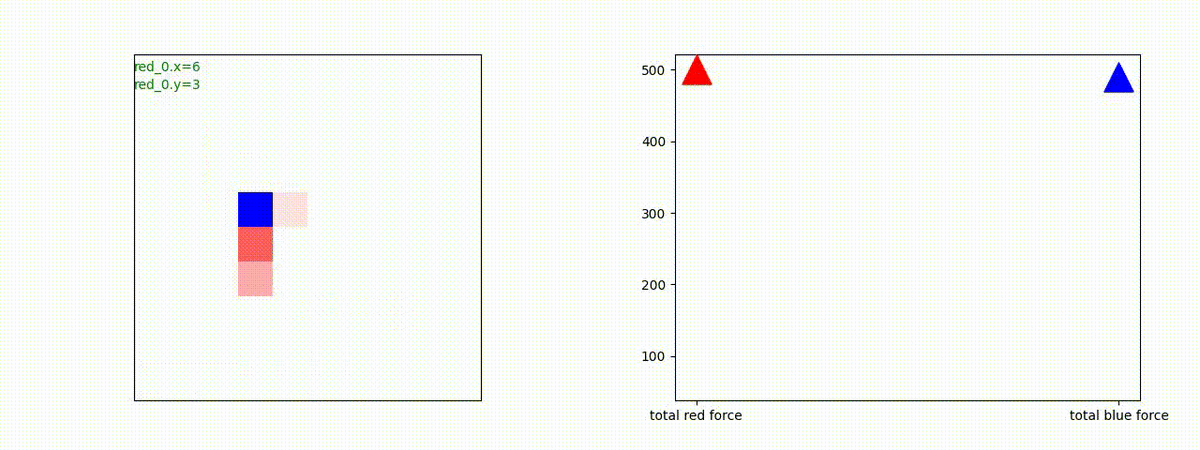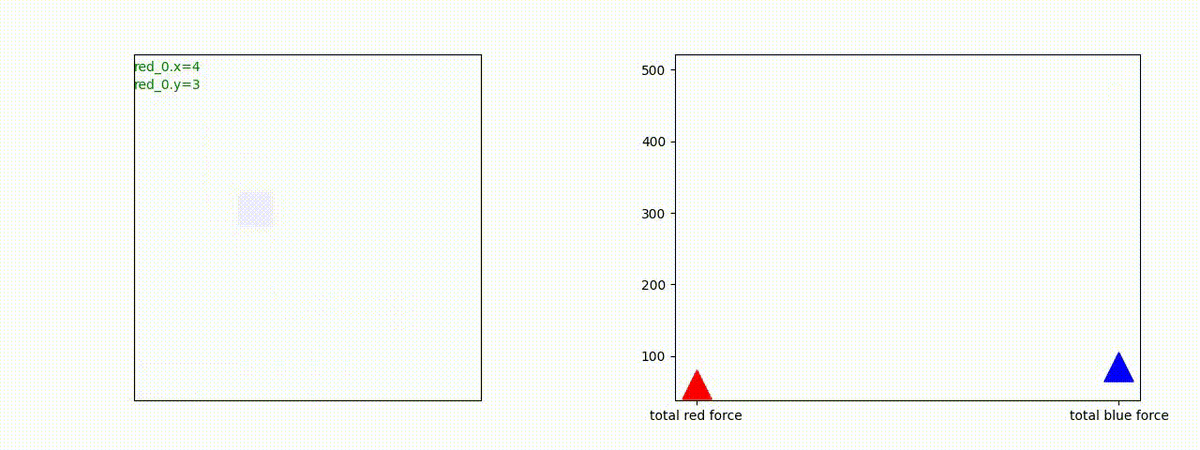
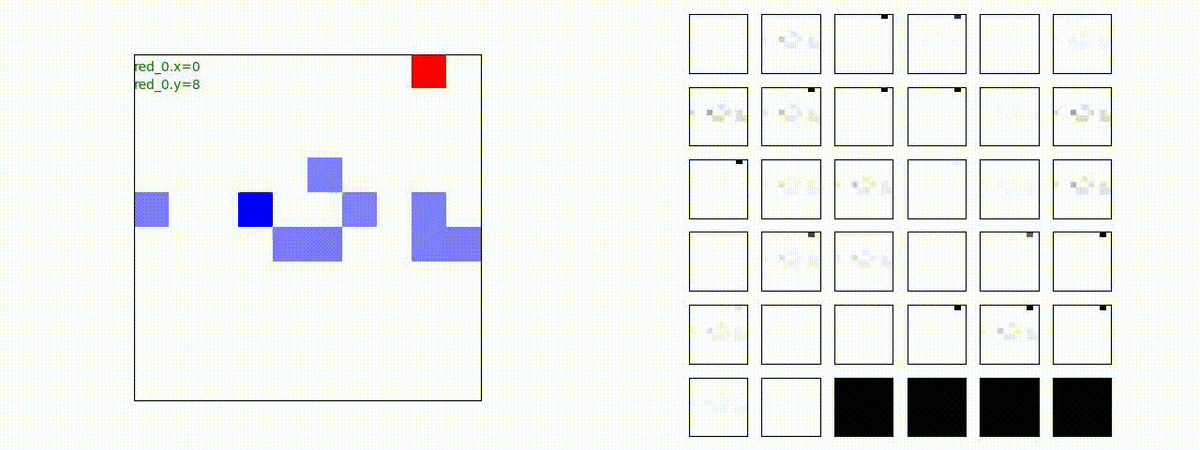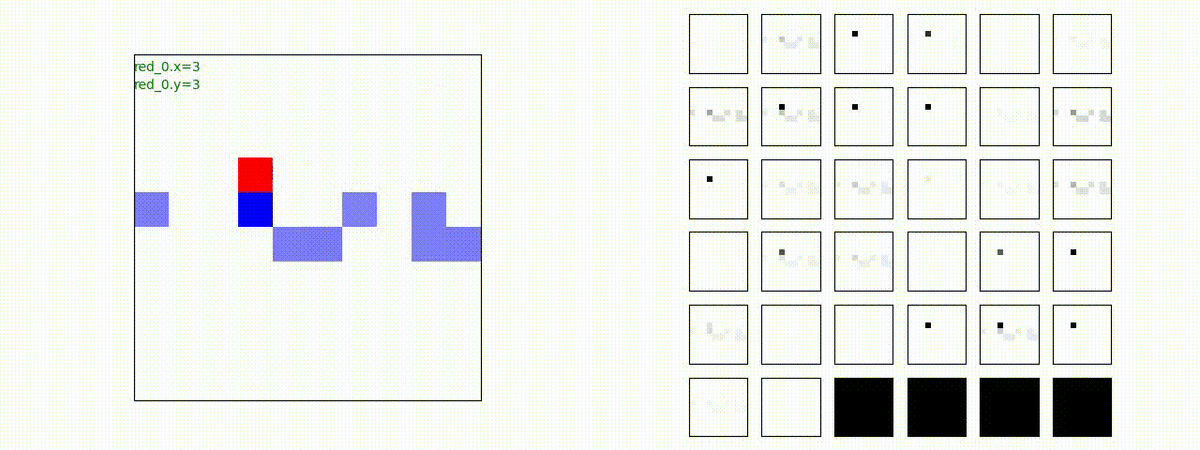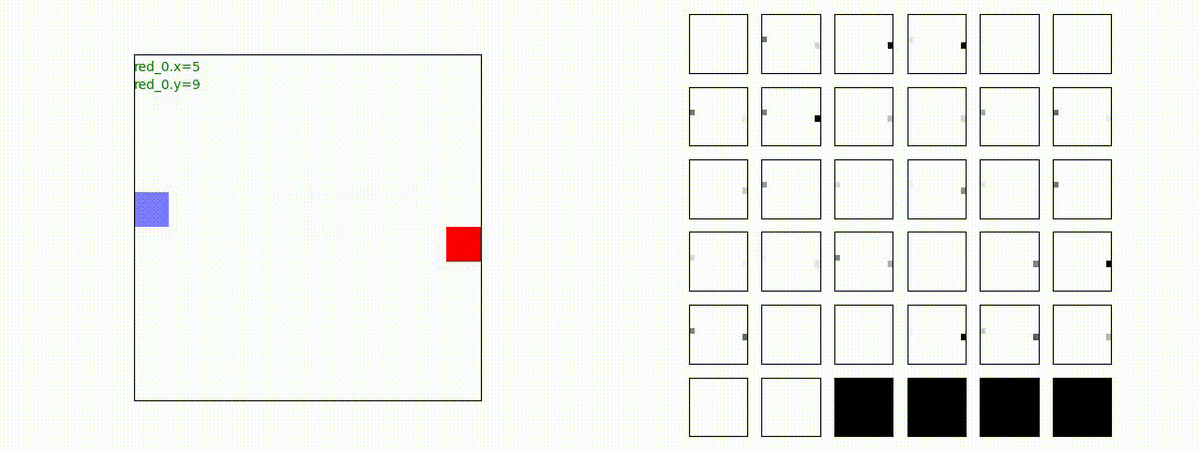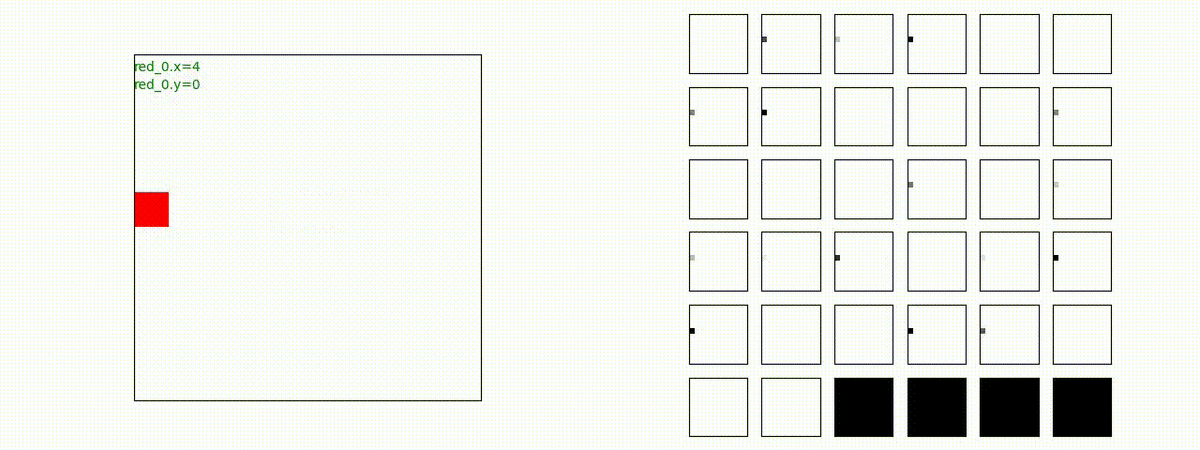
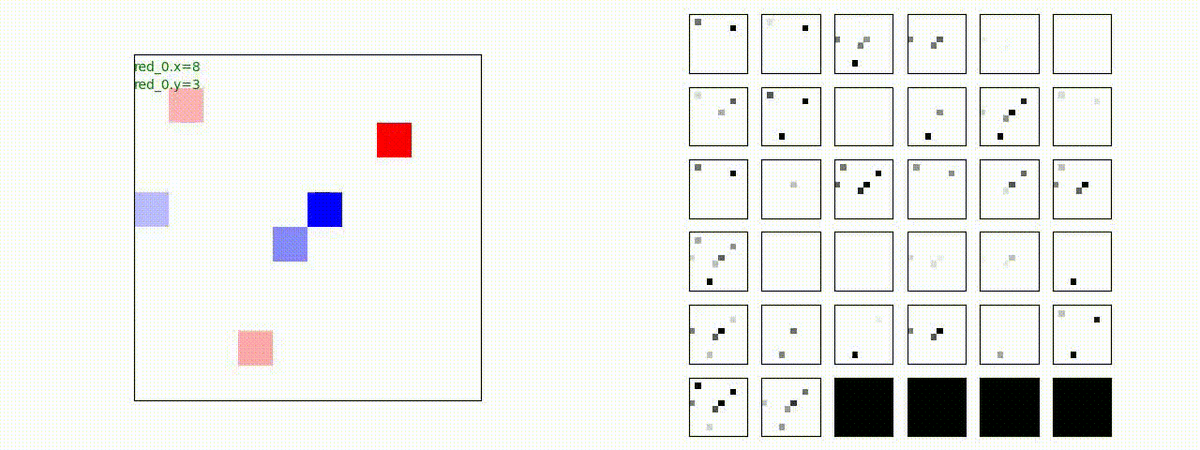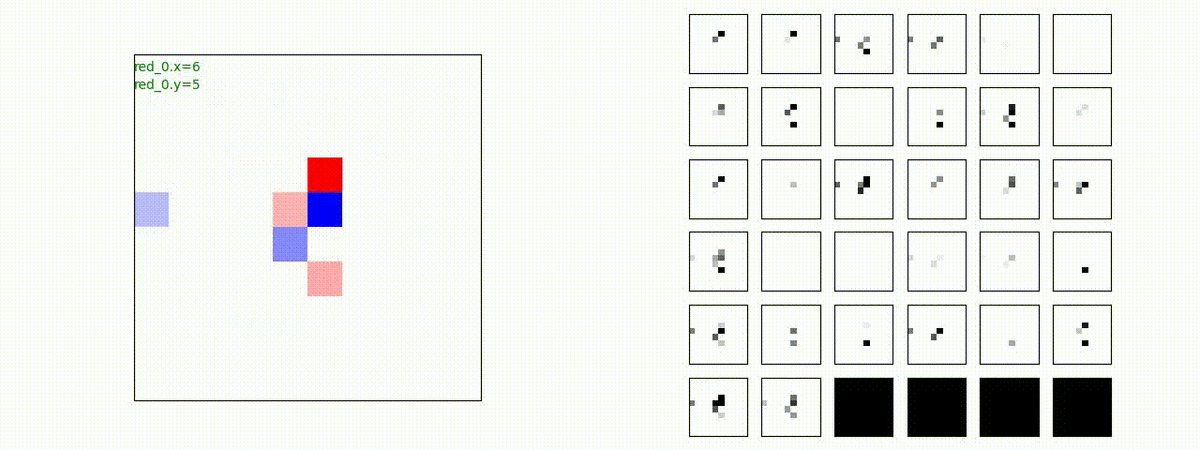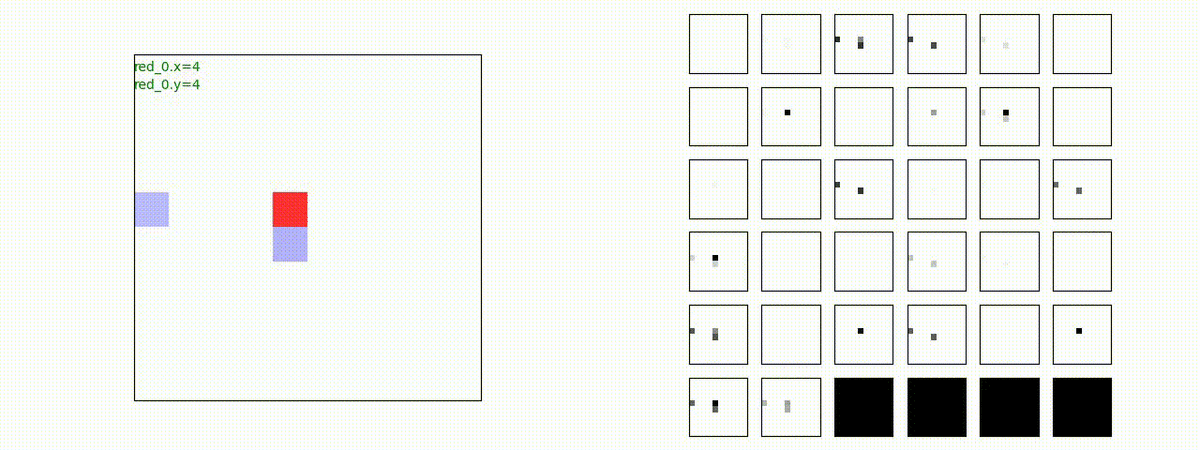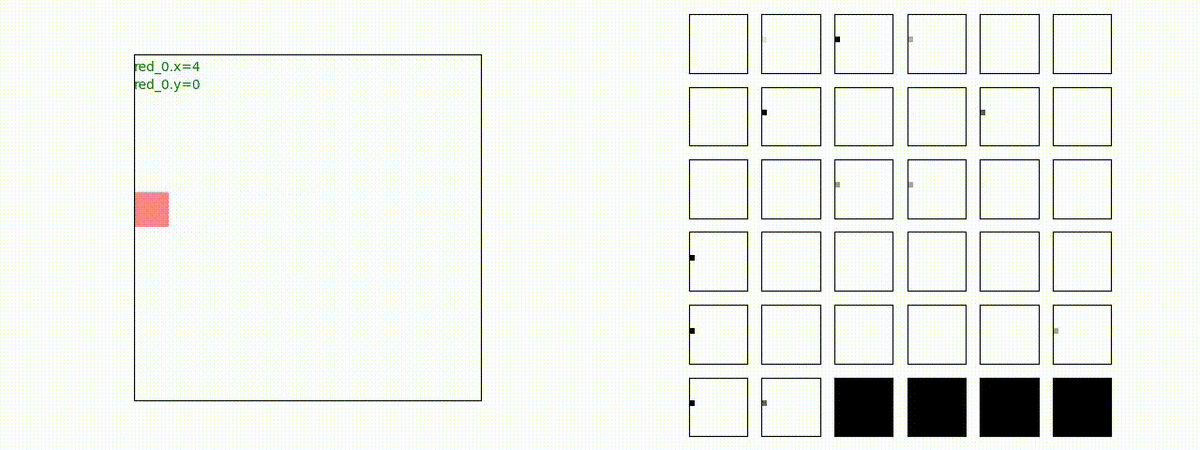
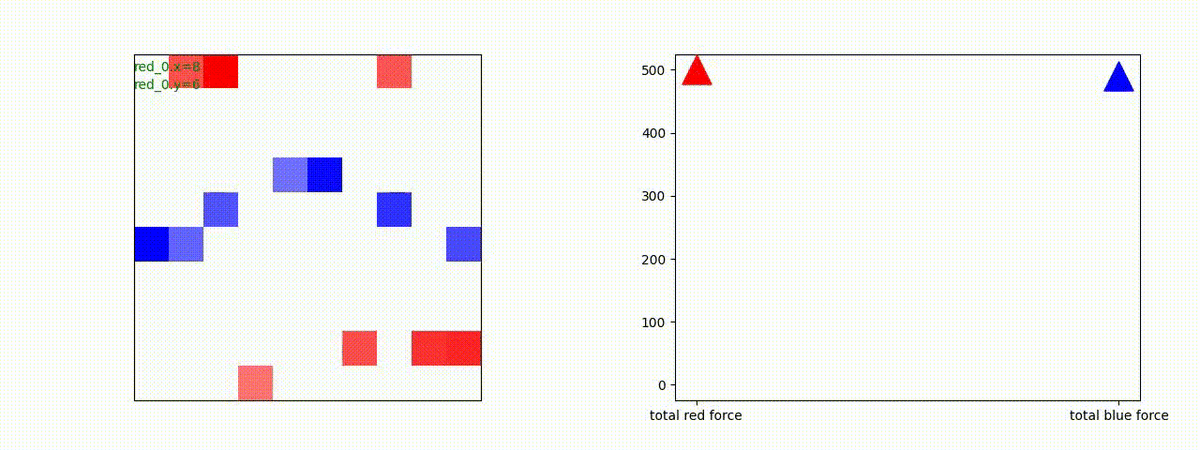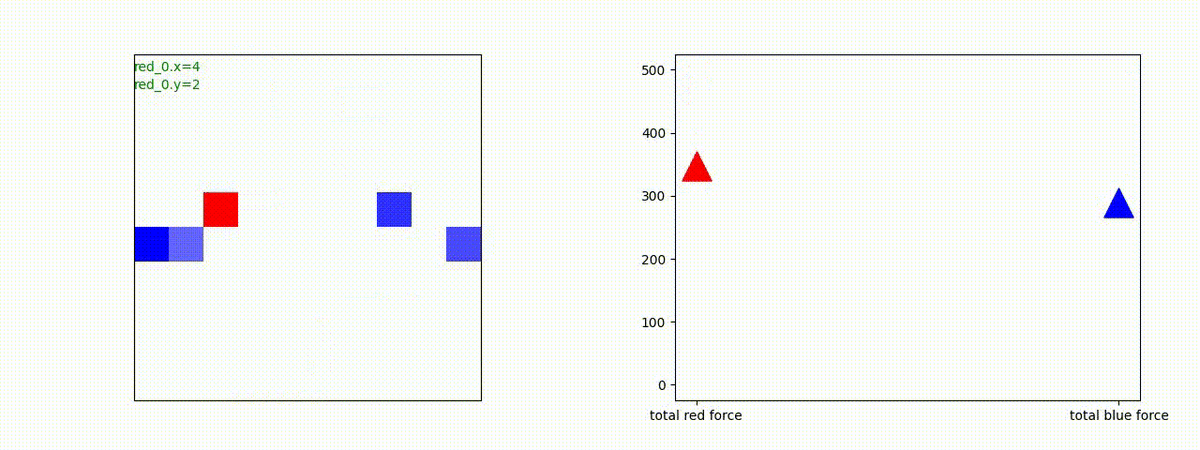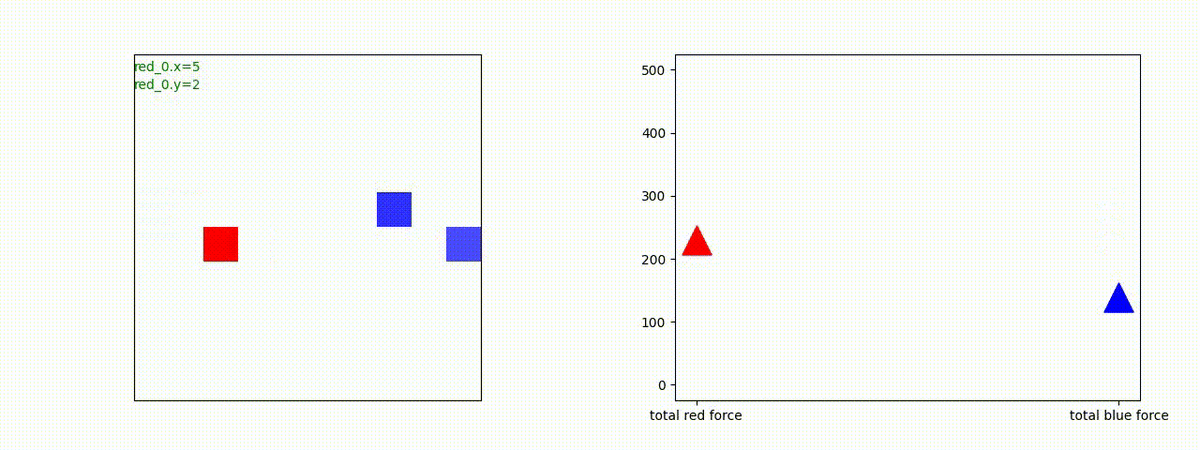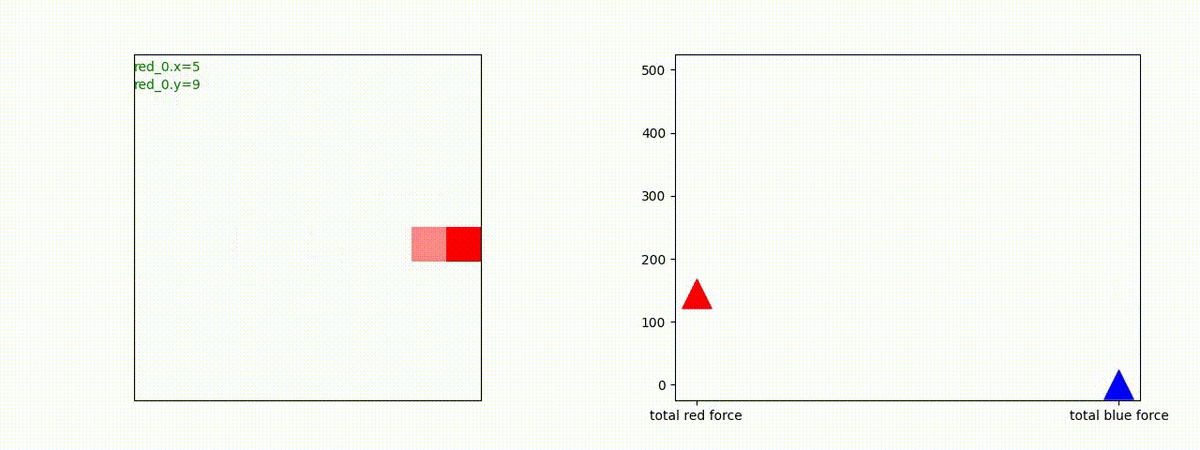
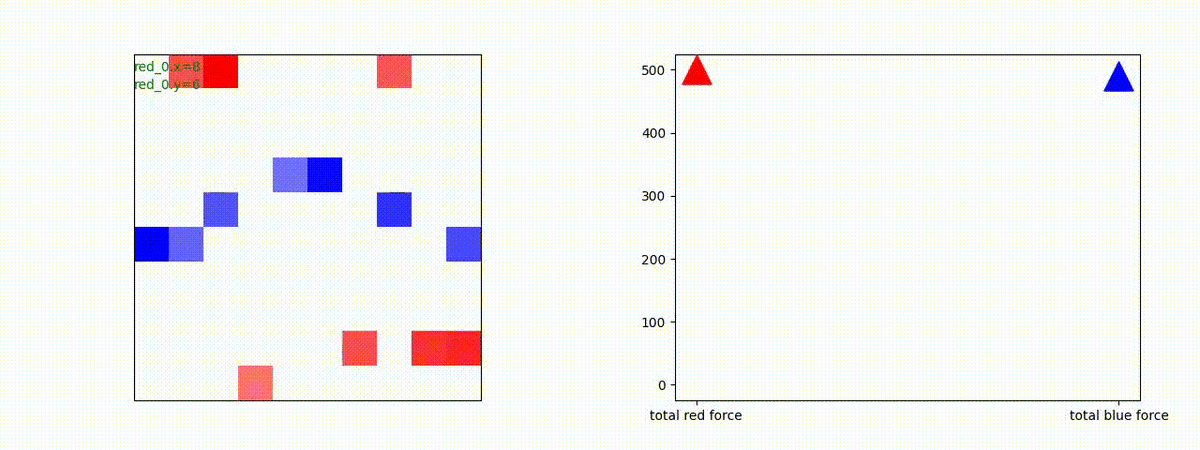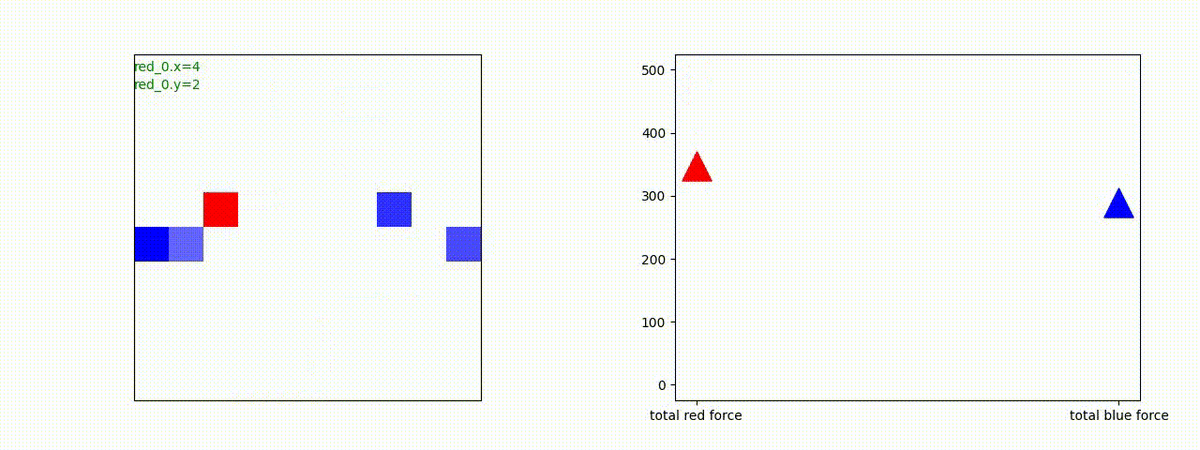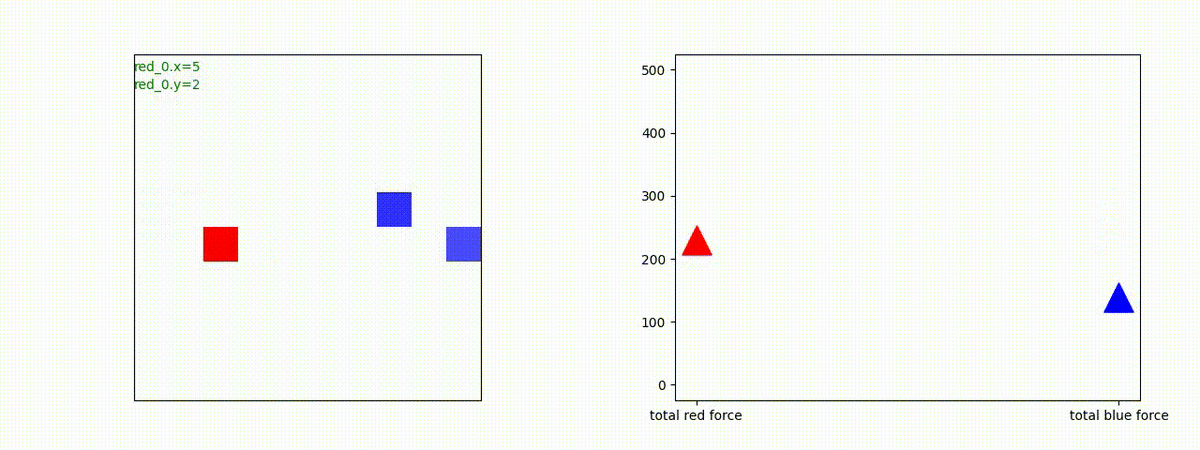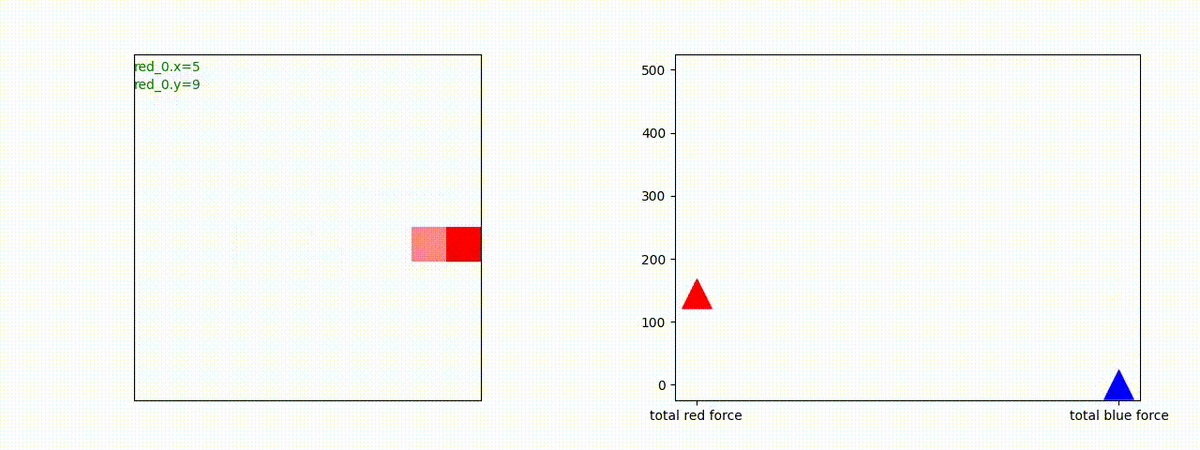
下図(左)は、戦闘状況を示します。赤い正方形が Red team のエージェント(群)、青い正方形が Blue team のエージェント(群)を示します。画面左上の座標値は、red team の0番目のエージェント( "red_0" と呼称)の位置を示します。また、色の濃さが戦闘力(Force)の大きさを表し、色が濃いほど大きな戦闘力であることを示します。したがって、戦闘が進むに連れ、戦闘力は消耗して色が薄くなってゆきます。また、同一グリッドに Red team と Blue team が混在する場合は、チームの戦闘力の差を表していますので、色が薄いほど拮抗した戦闘がそのグリッドで行われていることになります。戦闘が進んだ時に色が濃くなるのは、それだけその色のチームの戦闘力が相対的に優位になったことを表しています。
下図(右)の赤、青三角は、夫々 Red team, Blue team の残存戦闘力(群の構成メンバー数)を示します。
Red team のエージェントは、敵(Blue team のエージェント)の位置を認識し、そのマスへ最短経路で移動し、敵が消耗して殲滅するまで敵と同じマスにとどまる戦術を学習しています。
但し、ごく稀ですが、1タイムステップの遠回り経路をとることが有りました。
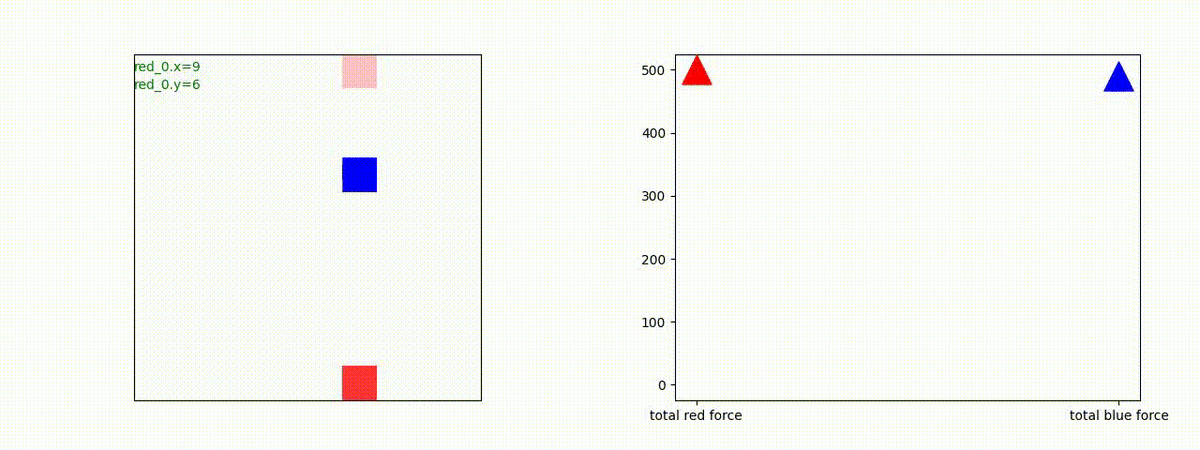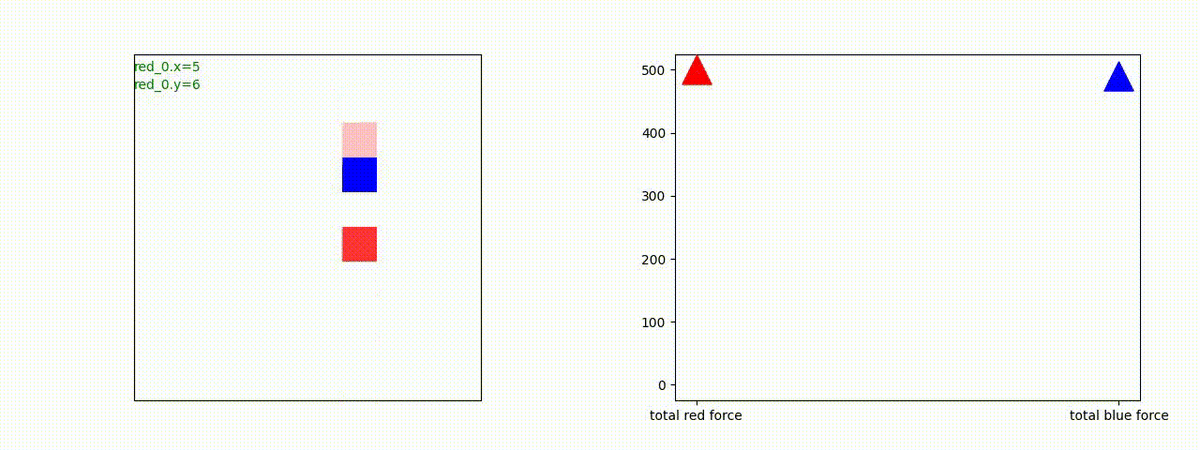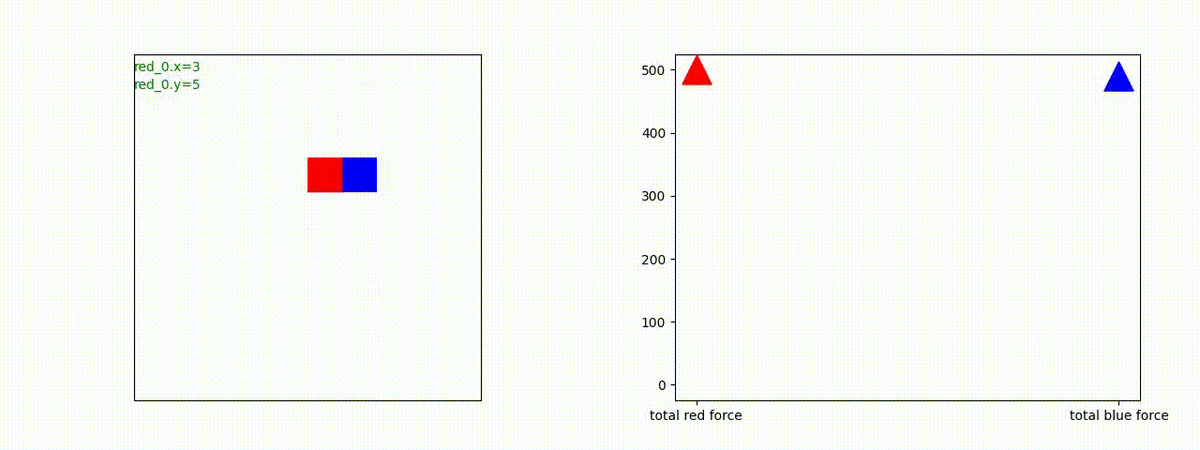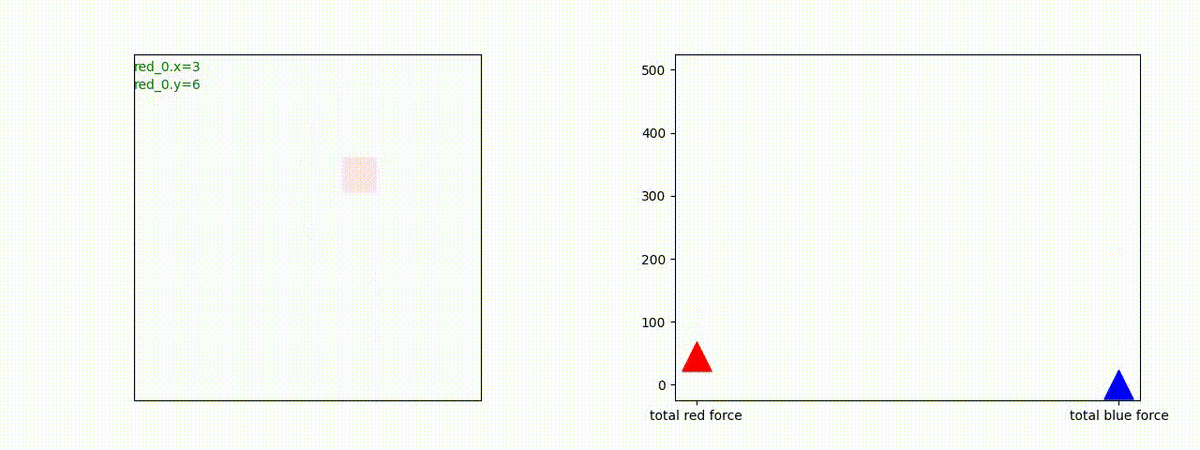
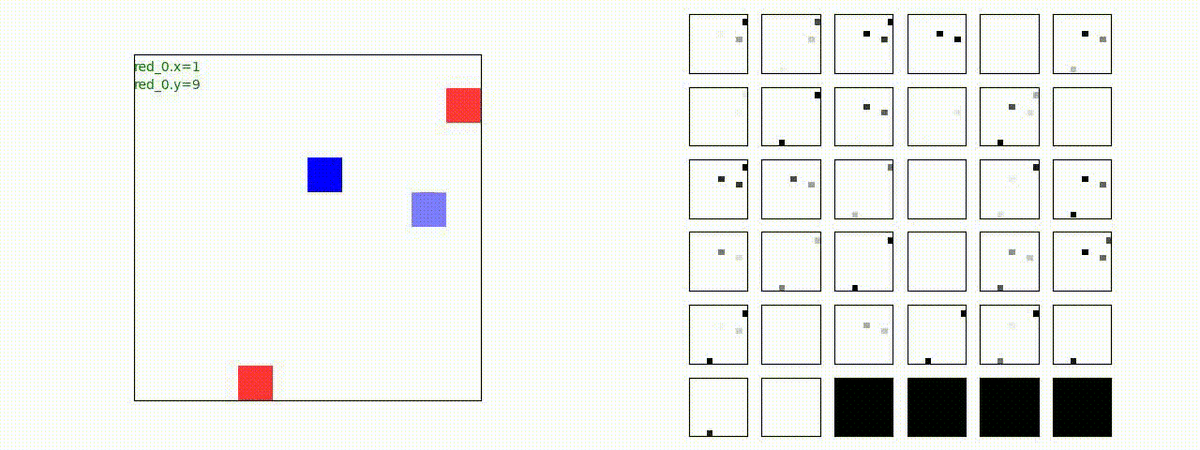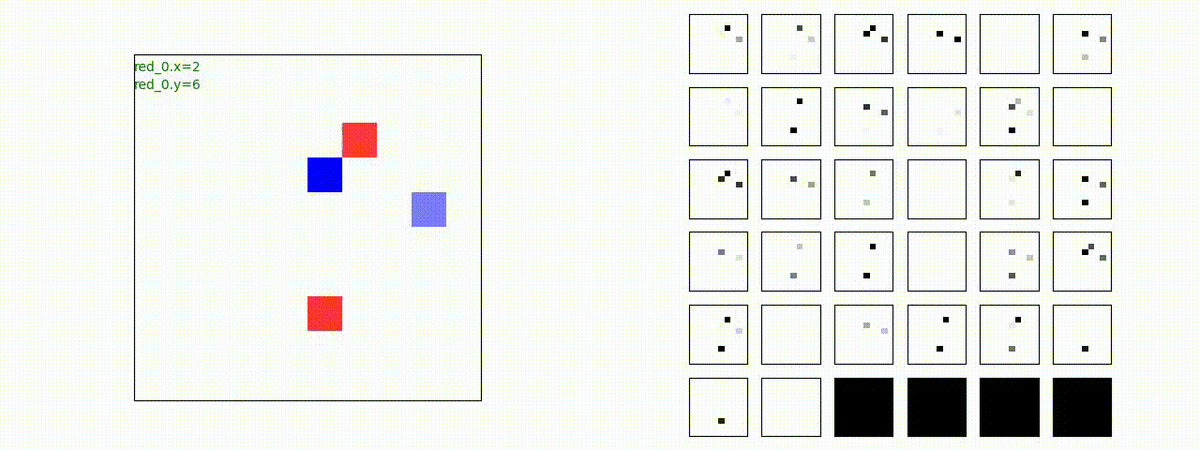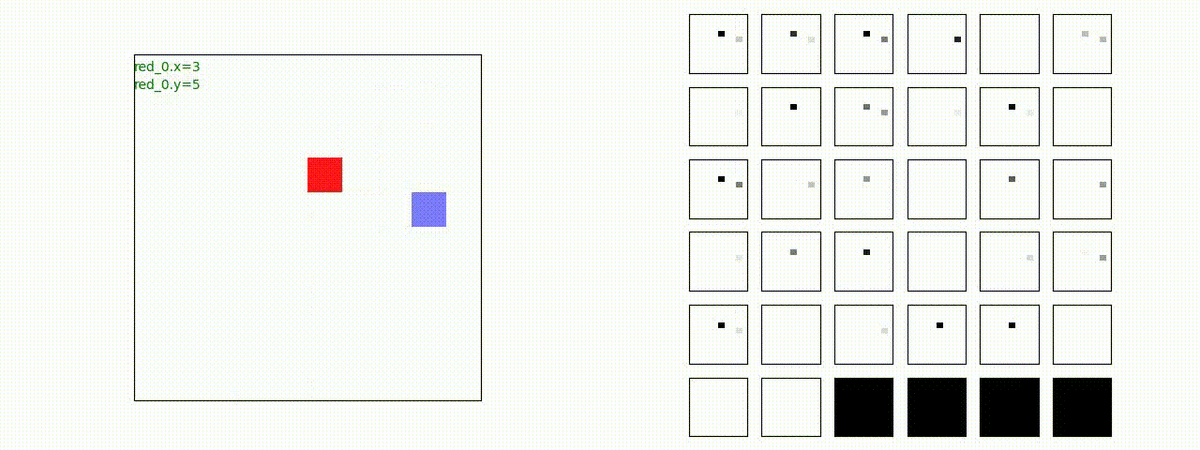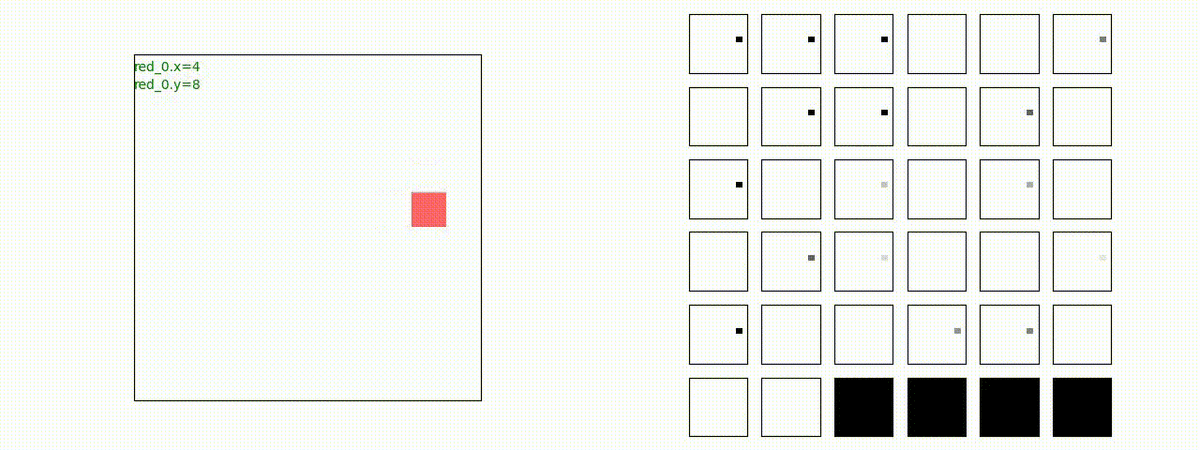
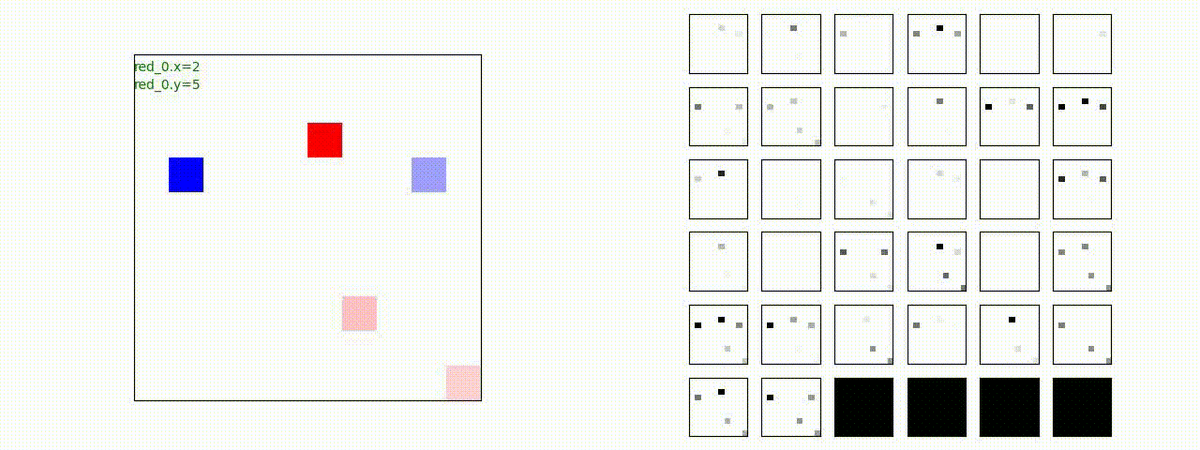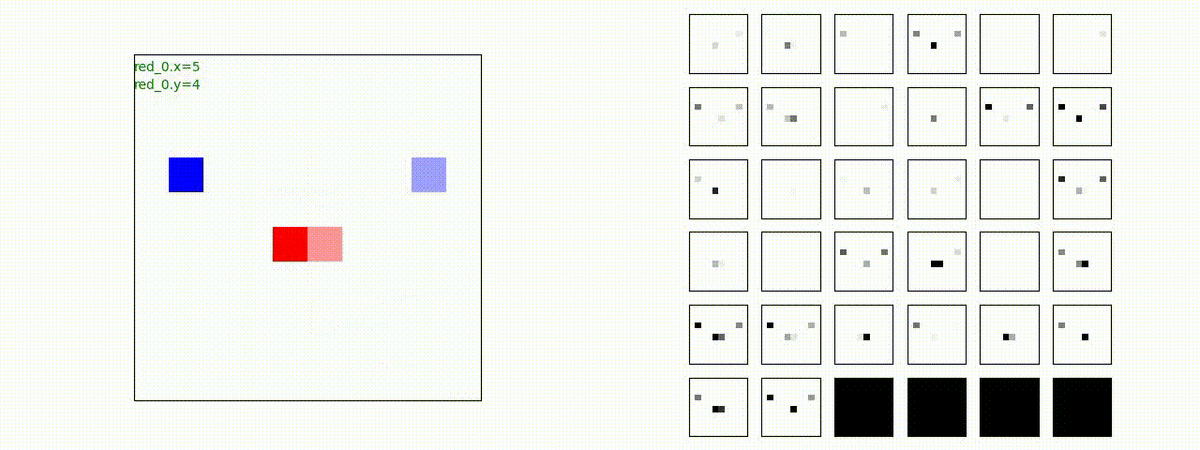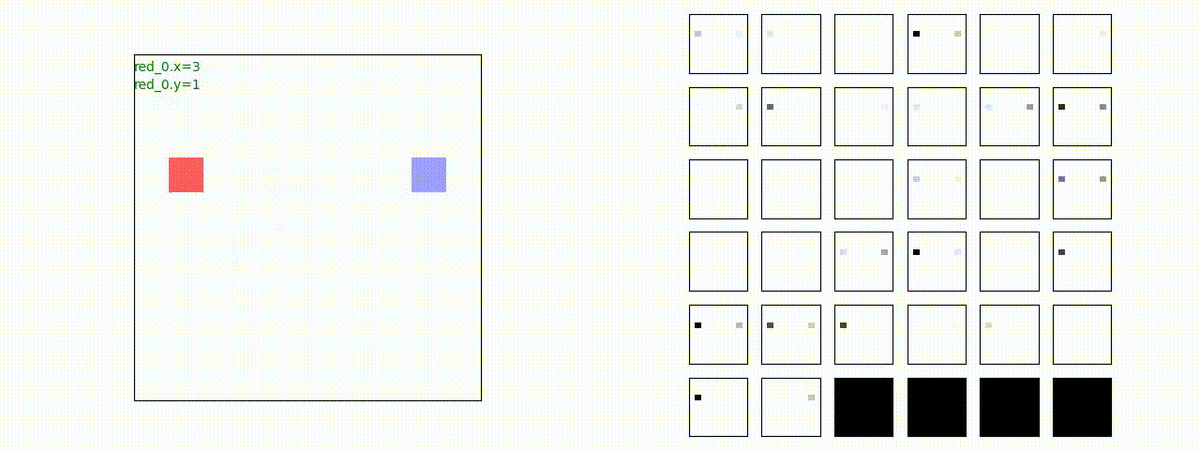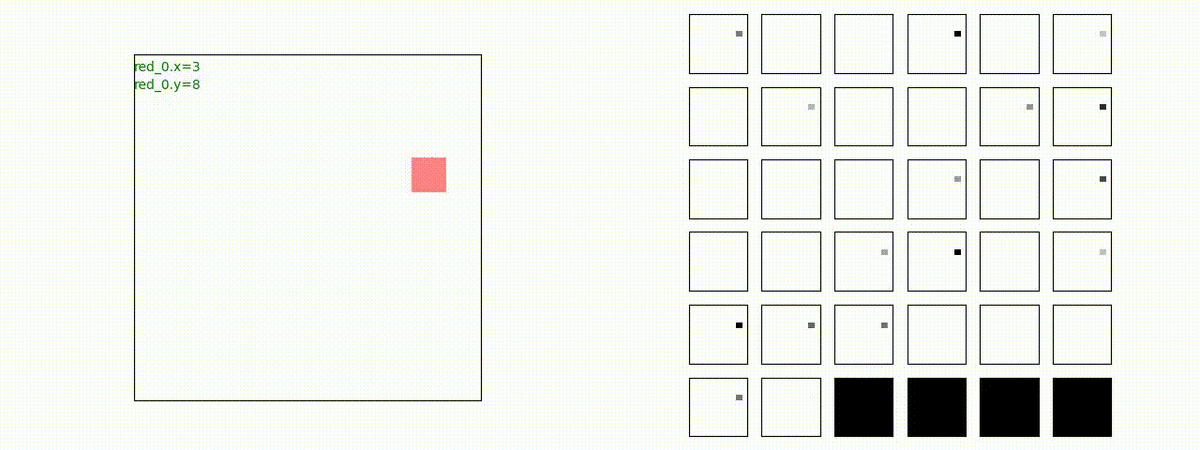
2 swarm vs 1 swarm
Red team のエージェントは、一丸となって巨大な Blue Team のエージェントに当たる必要があるシナリオです。
このシナリオでは、2通りの戦術が生成されました。
1つめの戦術は、まず2つの swarm が一体化して巨大な戦闘力を有する1つの swarm になった後、初めて Blue team の swarm に攻撃を加える戦術です。
2つ目の戦術は、2手に分かれている Red team の swarm が、別々の方向から同じタイミングで Blue team の swarm に同時攻撃をかける戦術です。実際の戦闘では、このような挟撃戦術は、より効果があると思うのですが、Lanchester モデルは挟撃の効果をモデル化していないため、学習したエージェントが常にこの戦法をとるとは限りません。この辺りは、強化学習の問題ではなく、モデル化の問題です。
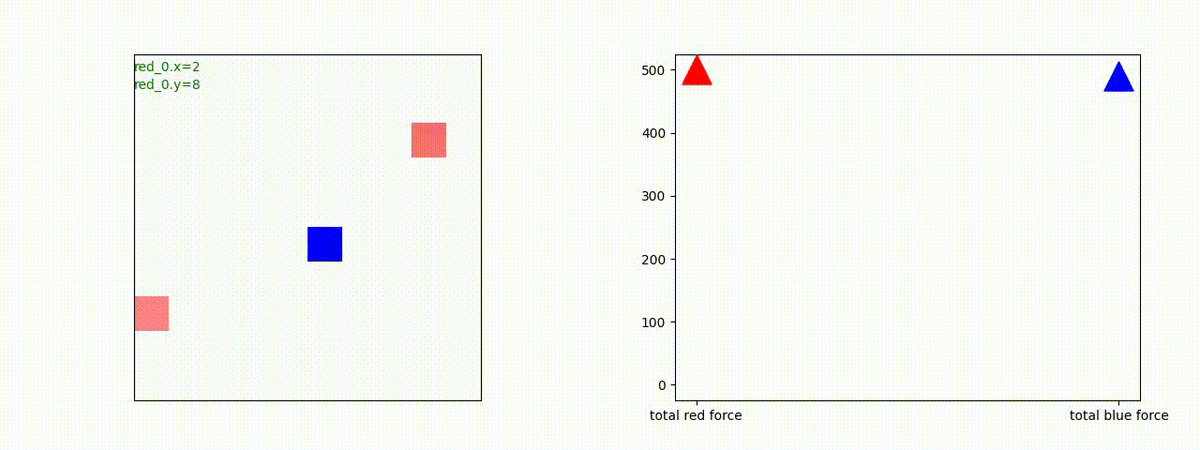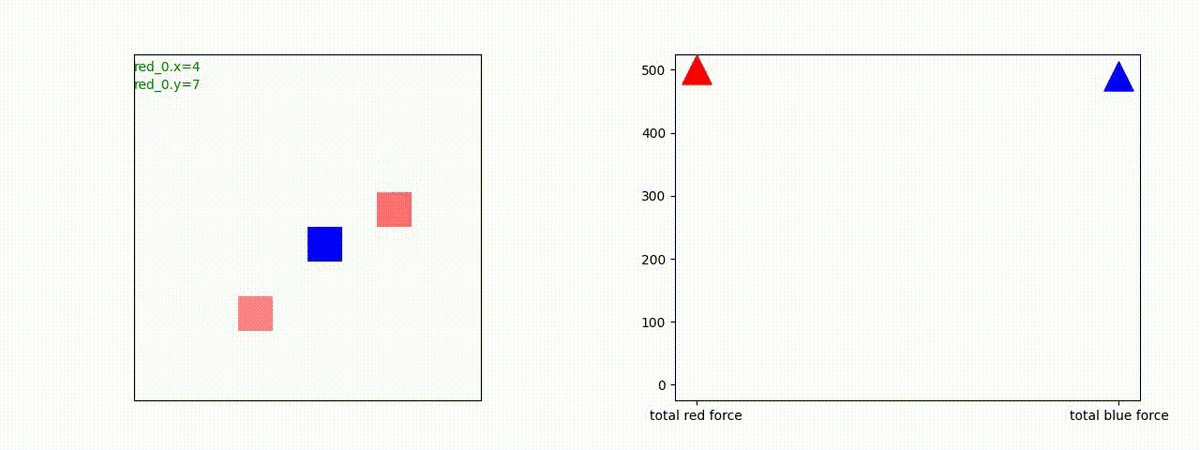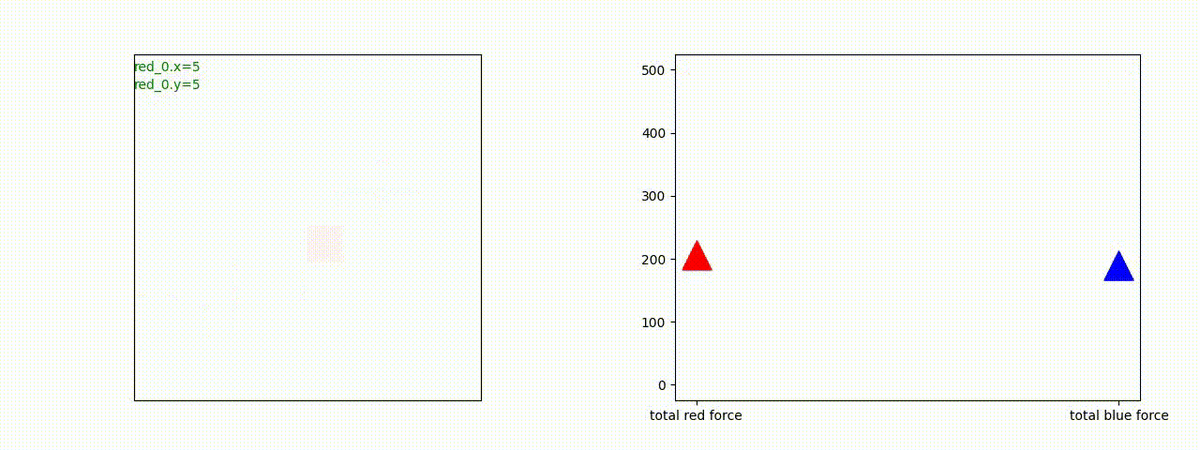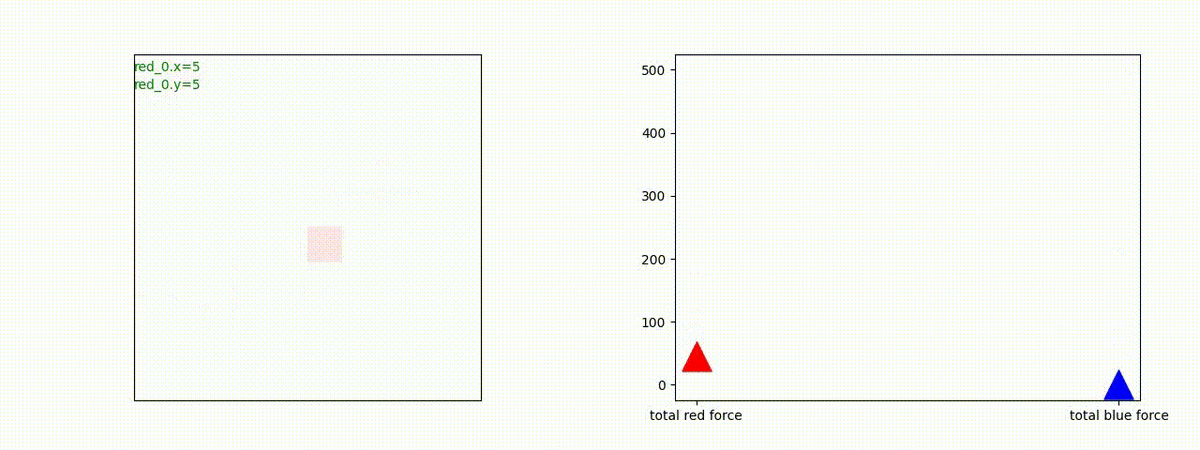
どのような戦況配置の時に、どちらの戦術をとることになるのか知りたかったので、いくつかケースを比較してみたのですが、私には判りませんでした。この分野は、XAI として熱心に研究されていますので、今後に期待しています。
3 swarm vs 1 swarm
再録になりますが、今回使っているアーキテクチャは下図になっています。
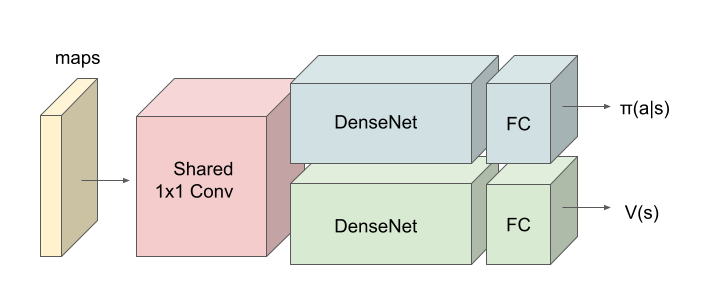
このアーキテクチャでは、各エージェントは、入力された6枚のマップ (10x10x6) から、1x1 Conv を使って、以降の認知系(DenseNet)に入力するマップ (10x10x32) を合計で 32 枚生成しています。どのようなマップが生成されるのかは、大変興味があるところだったので、エージェント 'red_0' の生成したマップを可視化してみました。(これらのマップは、当然、エージェント毎に異なります)。
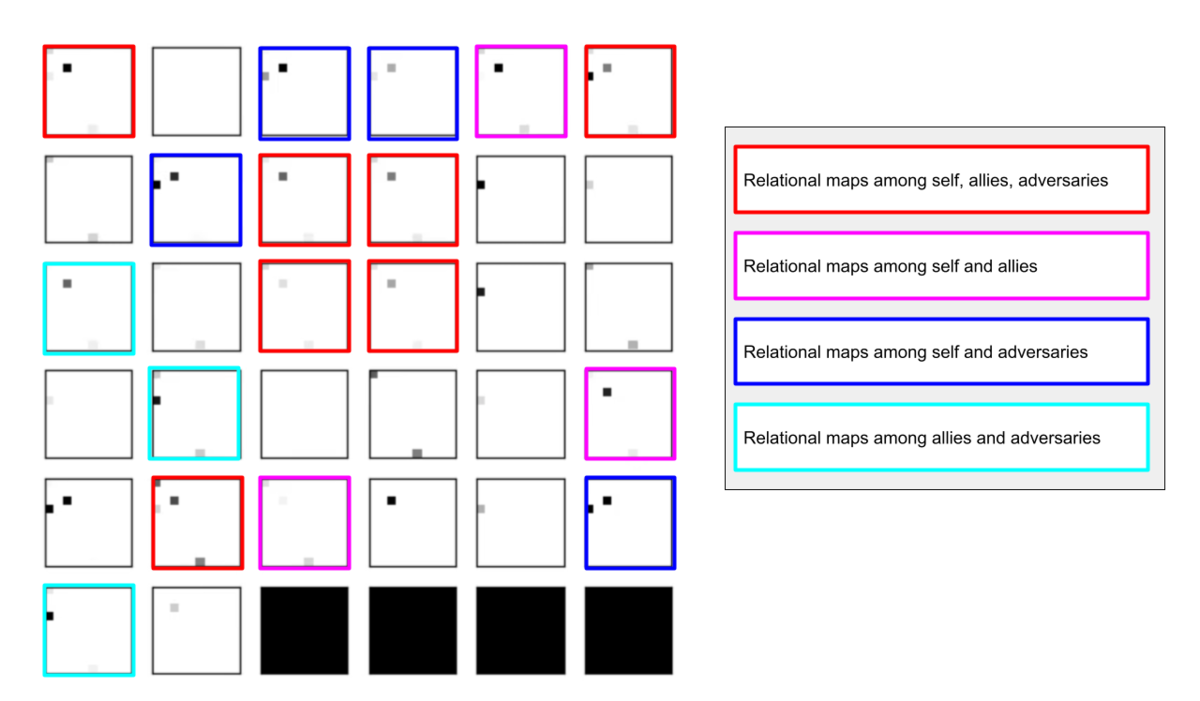
上図から、入力されたマップから、Shared 1x1 Conv が新たに以下のマップを作成して、DenseNet にハンドオーバーしていることが判ります。
- Red team, Blue team全体の配置や兵力を表していると思われる複数のマップ
- 自分('red_0')と、他の red team エージェントの位置や兵力を表していると思われる複数のマップ
- 自分('red_0')と Blue team のエージェントの位置や兵力を表していると思われる複数のマップ
- 他のred teamエージェントとBlue team のエージェントの位置や兵力を表していると思われる複数のマップ
これらのマップは、いずれも戦術を生成する上で意味があるマップとなっているように思えます。人間でも似たようなマップを作るのではないでしょうか。各 map はテンソル(数値アレイ)で与えられているので、定量的に解析しようと思えば解析できます。例えば、どのエージェントと組むのが良さそうなのかとか、どのblue teamを攻撃するのが良さそうなのかを表すようなマップが見つかるのかもしれません。ただ、この解析は相当時間がかかりそうだったので省略しました(ゴメンナサイ)。
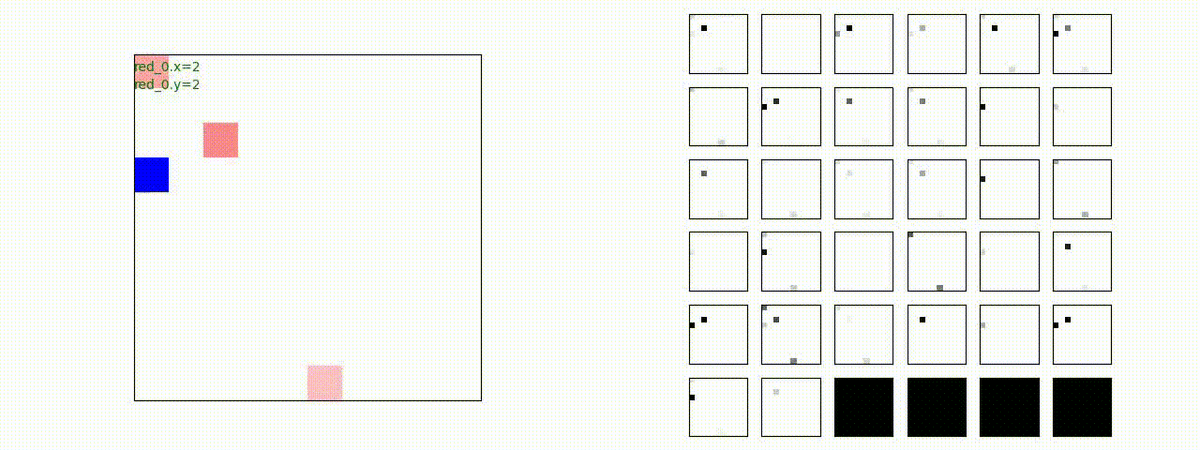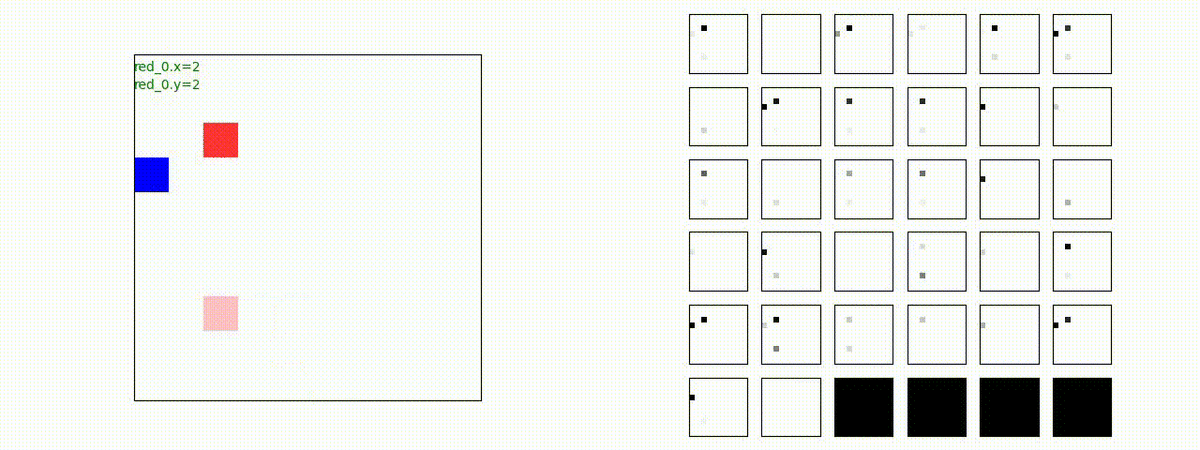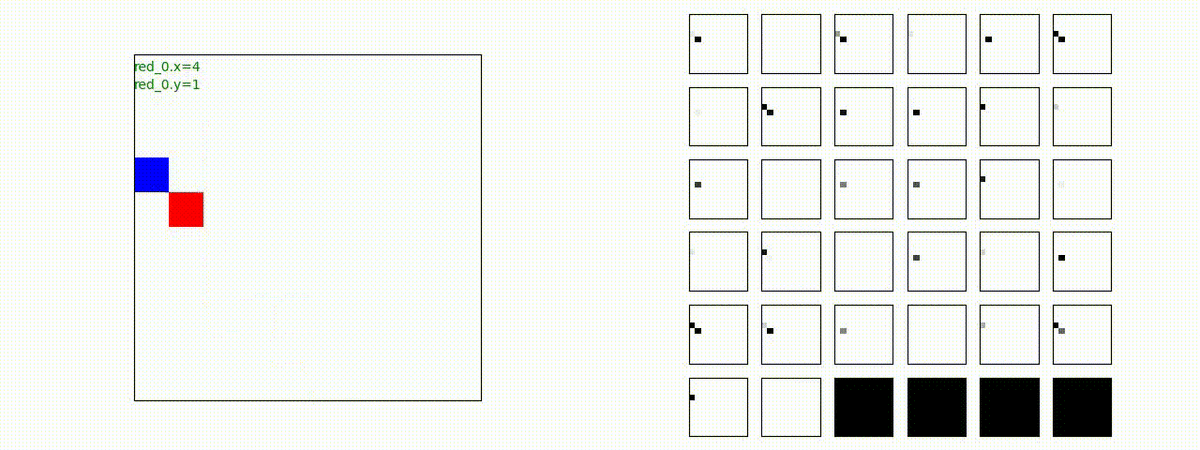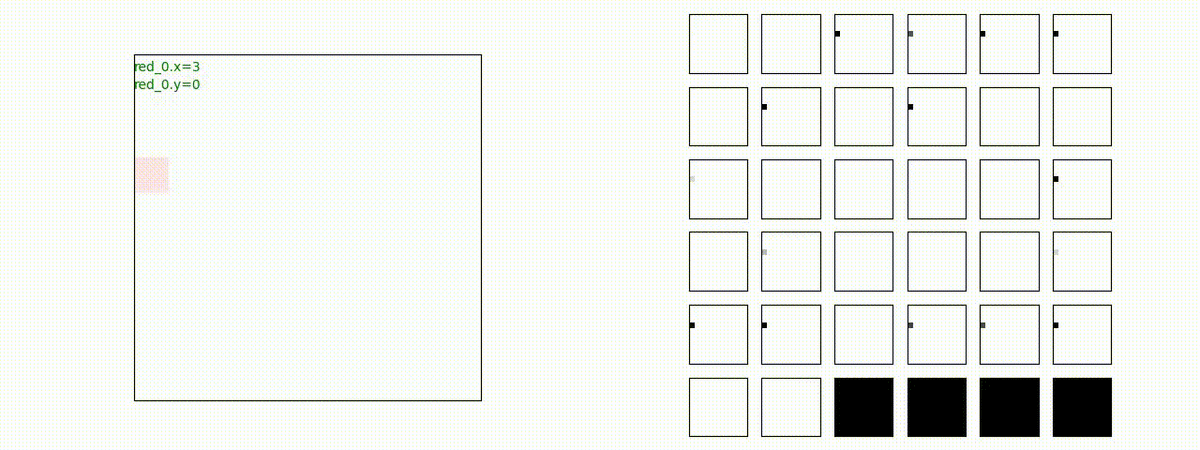
※ 1 x 1 conv 以外の層の出力も、同じようにして可視化してみたのですが、グリッドサイズが変わっている上に、チャネル数が増えているので、これを解析するのも諦めました。もう少し、XAIが進歩したら、面白い結果が出せるのかもしれません。
以下では、参考のために、エージェント 'red_0' の 1x1 Conv の出力である生成した新たなマップも示します。(エージェント数が増えてくると、眺めている分には楽しいのですが、目がちらちらしてしまい、マップの把握が出来なくなりました)。
また、例えば 「1 swarm vs 2 swarm」は、前が red team数、後ろが blue team 数を表します。つまり、「1 red team エージェント(群)vs 2 blue teamエージェント(群)」を意味します。
下記の動画から、red team が複数のエージェント(群)で構成されているようなシナリオでは、red teamは、'mass' を構成して blue team にあたる戦術を生成していることが判ります。
1 swarm vs 2 swarms
2 swarms vs 2 swarms
red team の各エージェント(群)は、'mass' を構成してから blue team にあたる戦術を獲得しています。
Shared 1 x1 Convが生成するマップは、更に複雑になり、見ている分には楽しいのですが、私には手が終えません。
3 swarms vs 2 swarms
red team の各エージェント(群)は、'mass' を構成してから blue team にあたる戦術を獲得しています。
ロバスト性(汎化能力)
戦況をマップで表し、マルチエージェントの枠組みを使うメリットの一つは、登場エージェント数を任意に増減できることです。もちろん、学習時に経験していないエージェント数に対しては、見たことが無いマップが入力されることになるので、性能は劣化するはずです。
ここでは、エージェント数を Red team = [1, 10], Blue team = [1, 9] として、トレーニング時には全く未経験の戦況にどこまで対応できるのか測って見ました。(トレーニング時のエージェント数は Red team = [1,3], Blue team = [1,2] です)。
この場合、トレーニング時には見たことがないような、沢山のグリッドにエージェントが存在するきらびやかなマップがいきなり提示されることになるので、人間だったら、結構戸惑う状況だと思います。それでも、「敵の戦闘力以上の戦闘力になるように、味方エージェントと協調して一丸となって戦う」という "mass" のコンセプトをきちんと学習し理解できていれば、最適とまでは行かなくても一定の戦闘は出来る可能性があります。
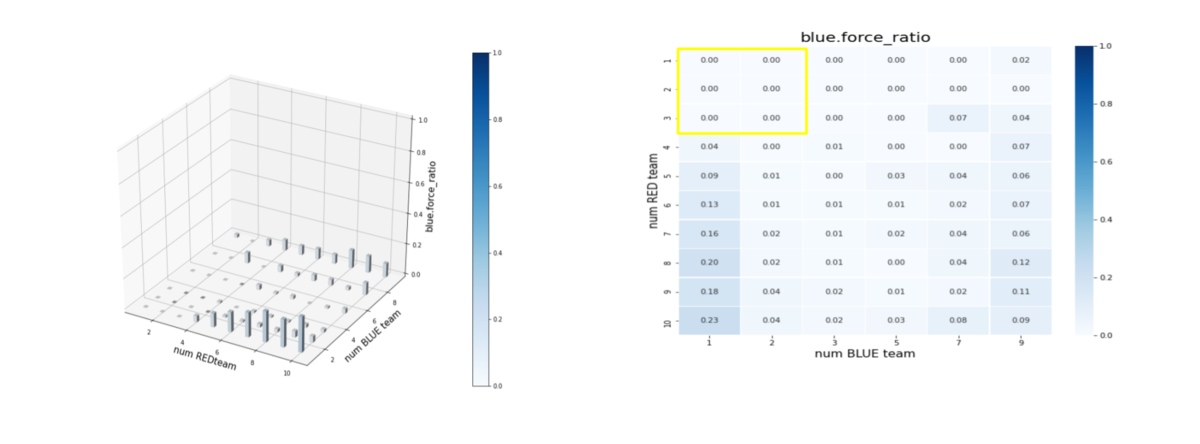
エピソード終了後の平均残存兵力(Force)を調べたのが下図です。この見せ方は、とても難しく何通りかやってみて、バーグラフとヒートマップに落ち着きました。(ヒートマップは、拡大してみてください)。
num RED team, num BLUE team が、夫々Red tem, Blue teamのエージェント数(群数)です。
左図のバーグラフの縦軸 blue_force_ratioは、
blue_force_ratio = Blue team残存兵力/Blue team初期兵力
を表します。
右図の heatmap は、blue_force_ratio の heatmap で、色が濃いほどblue_force_ratio が 1 に近い、つまり残存兵力が大きいことをを示します。数字は、blue_force_ratio の値を表します。また、黄色の枠で囲ったエリアが、トレーニング時に使用したマルチエージェント戦闘環境です。したがって、黄色から外れるほど、トレーニング時に見たことがない戦闘環境になります。
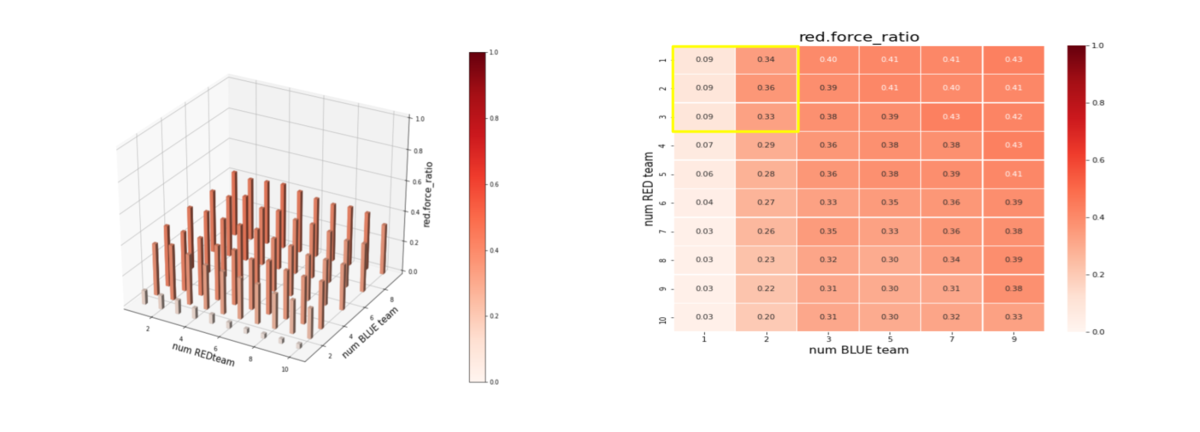
同様の解析を Red team の兵力に対して行ったのが下図です。red_force_ratio は以下で定義しています。
red_force_ratio = Red team残存兵力/Red team初期兵力
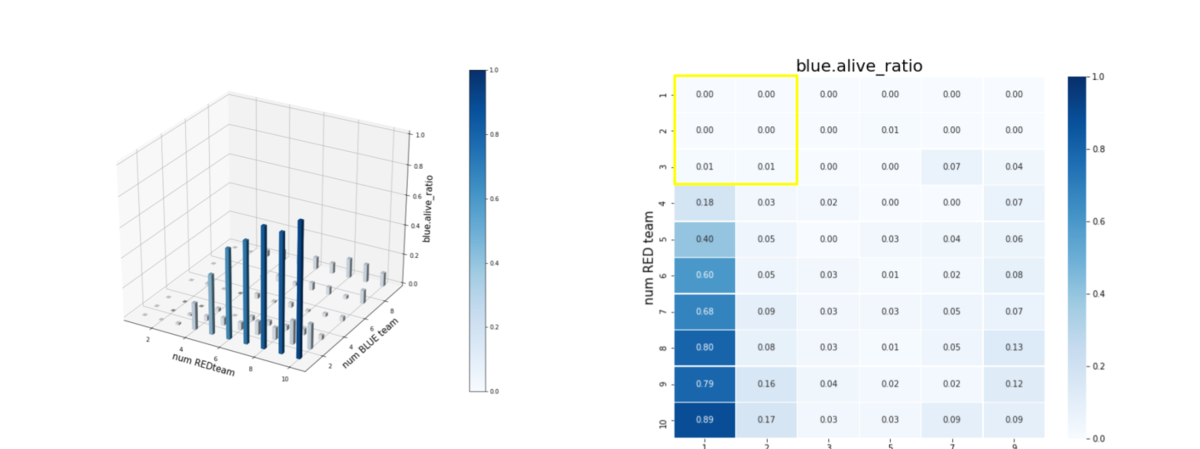
兵力(Force)の代わりに、残存エージェント数をグラフ化したのが下図です。blue_alive_ratio は以下で定義しています。
blue_alive_ratio = Blue team残存エージェント数/Blue team初期エージェント数
= Blue team残存群数/Blue team初期群数
Red team については、下図になります。red_alive_ratio は以下で定義しました。
red_alive_ratio = Red team残存エージェント数/Red team初期エージェント数
= Red team残存群数/Red team初期群数
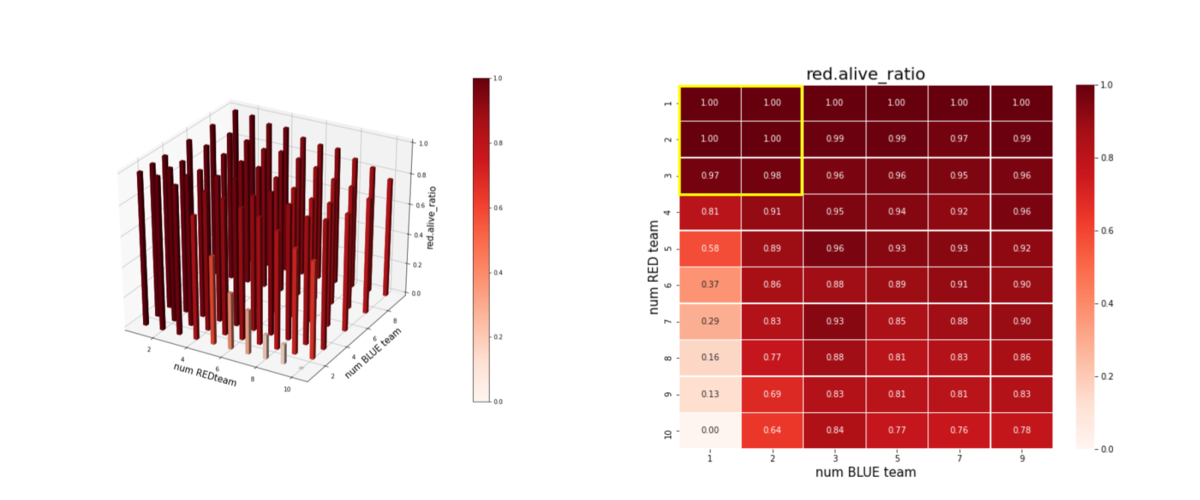
以上から、以下を読み取ることができます。
- Brue team のエージェント数 = 1 の時、つまり、Blue team が巨大な兵力を持った1つの群だけで構成されている場合、Red team のエージェント数がトレーニング時よりも増えると、Blue team の残存兵力は急激に大きくなる。この時の、Red team の残存兵力は僅かである。したがって、Red team は、外挿に耐えうるほどは "mass" 重視の戦術を学習しきれていない。
- Brue team、Red team のエージェント数が増えるほど、(外挿方向なので、当然ですが)、Brue team の残存兵力は増える。この時の Red team には、かなりの兵力が残存している。したがって、エージェント数が増えるほど、未知の環境に右往左往してしまい上手く戦いきれていない。
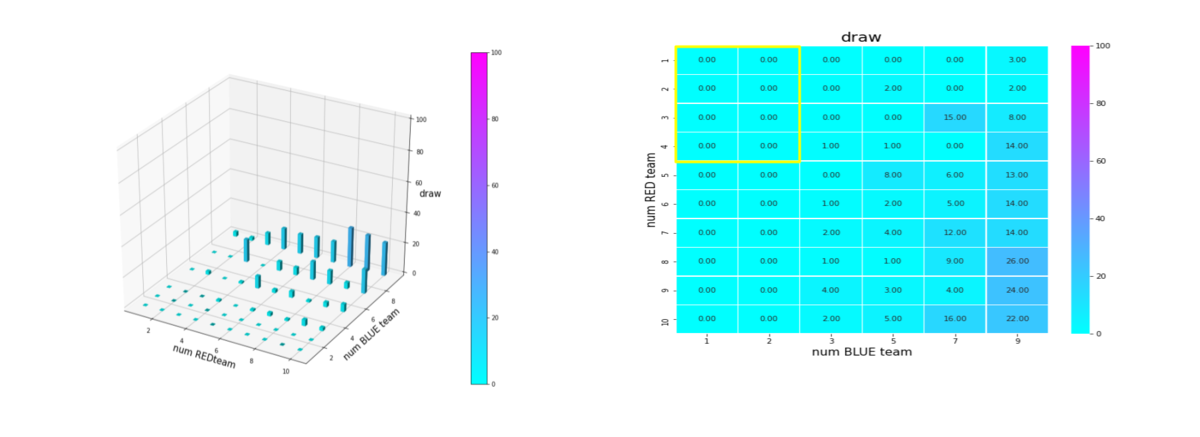
上記をもう少し分析します。成功率、引き分け率を以下で定義することにします。
success = Blue team の残存兵力=0となったエピソード数/全エピソード数
draw = どちらの tem の残存兵力も0にならなかったエピソード数/全エピソード数
これらをバーグラフと heatmap にしたのが下図です。
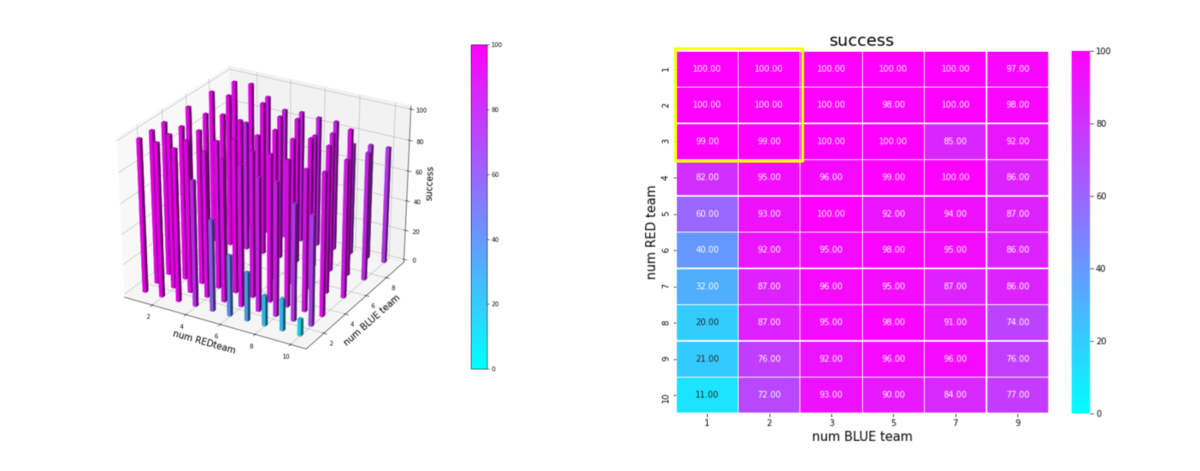
Brue team のエージェント数 = 1 の場合、Red team が小分けになるほど急速に成功率が減少します。
一方、Brue team, Red_team のエージェント数がともに増えた場合、draw になる割合が増えていきます。これは、上手く戦えずエージェントが未知の環境で右往左往していることを裏付けています。
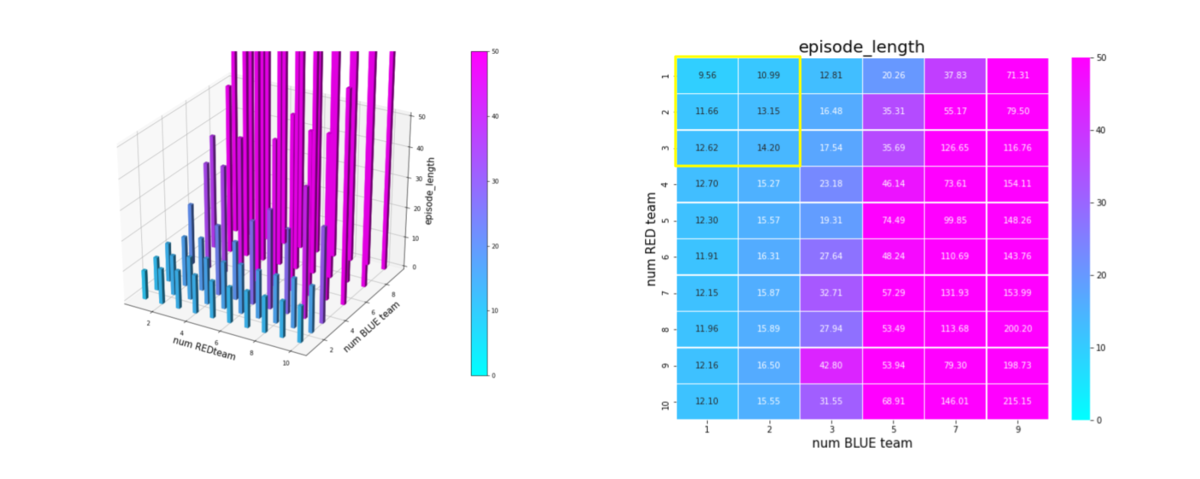
これをエピソード長で見てみます。戦場サイズが 10x10 なので、上手く戦っていれば平均10~20ぐらいのエピソード長で戦闘は終了するはずです。
エピソード長は、Brue team のエージェント数 = 1 の場合、Red_team 数が増えても長くなっていません。やはり、強大な敵に小分けの戦闘力で当たる場合、mass 戦略を発揮しにくくなっているのが判ります。
一方、Brue team, Red_team のエージェント数がともに増えた場合、エピソード長は増大し、エージェントが未知の環境で右往左往していることが判ります。
生成された戦術例(汎化性能)
実際に、どういった戦闘状況になるのか、いくつか生成例を下記に示します。図の見方は、先の動画と同じです。
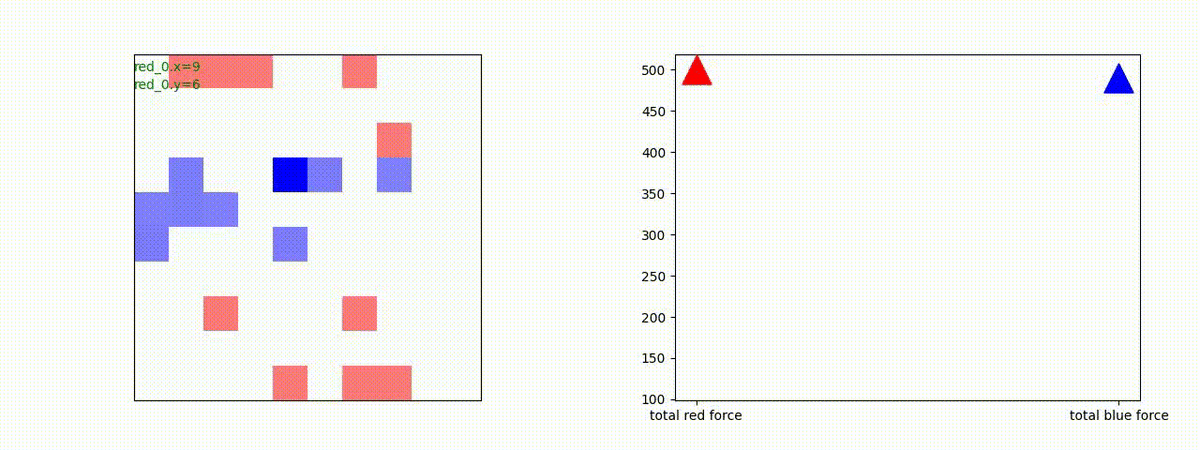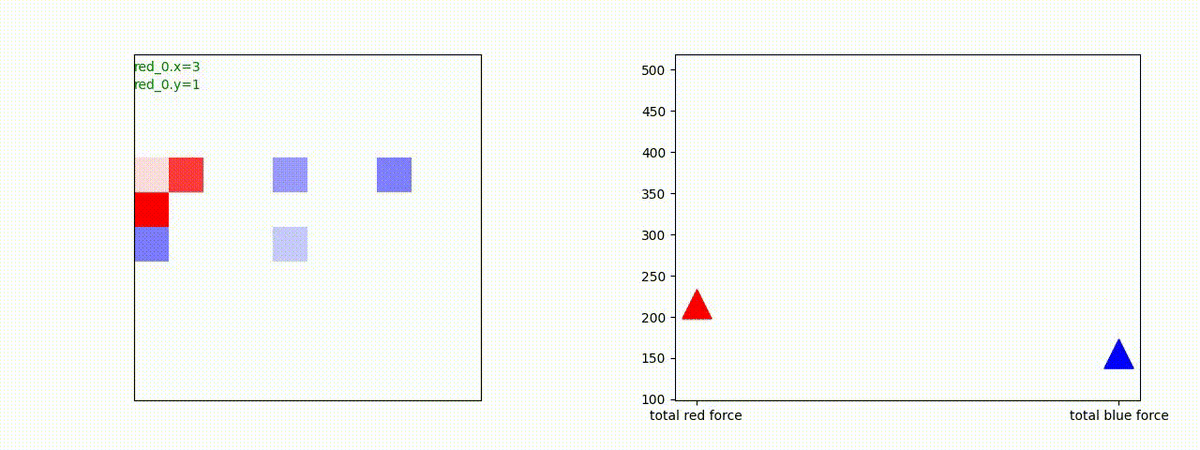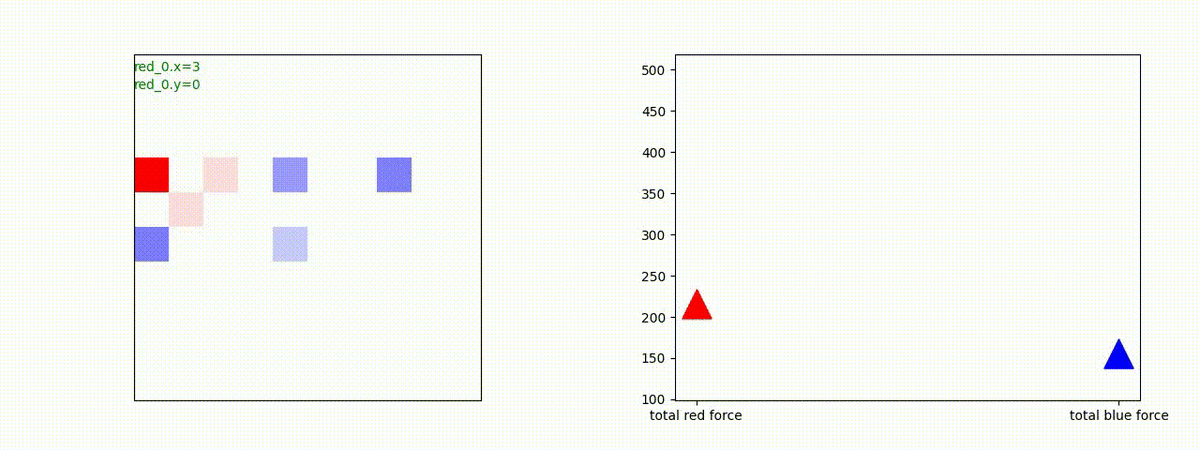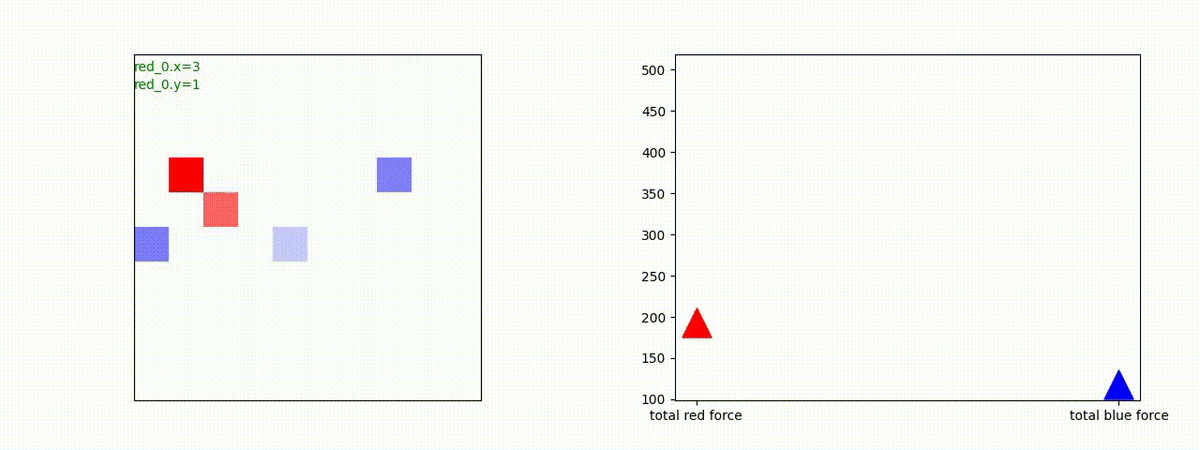
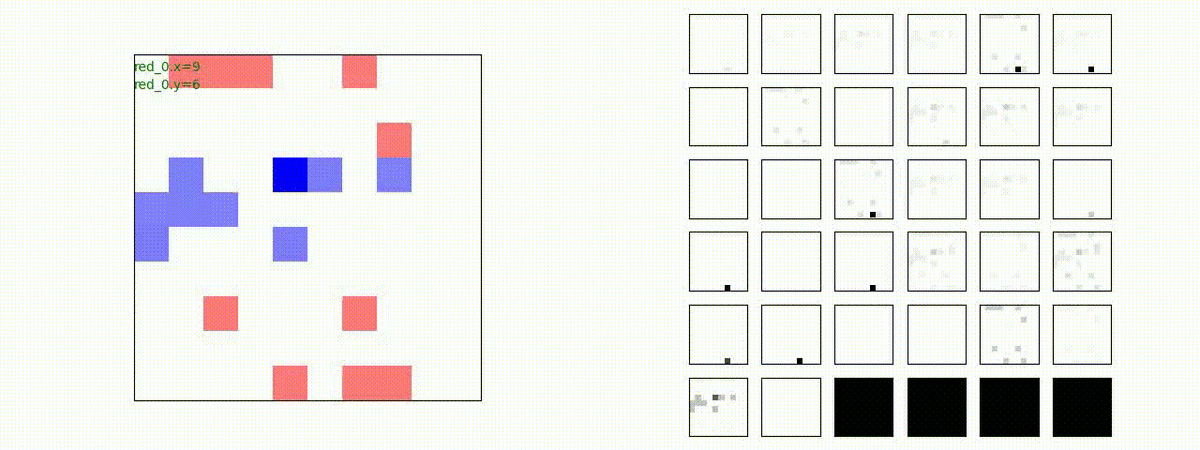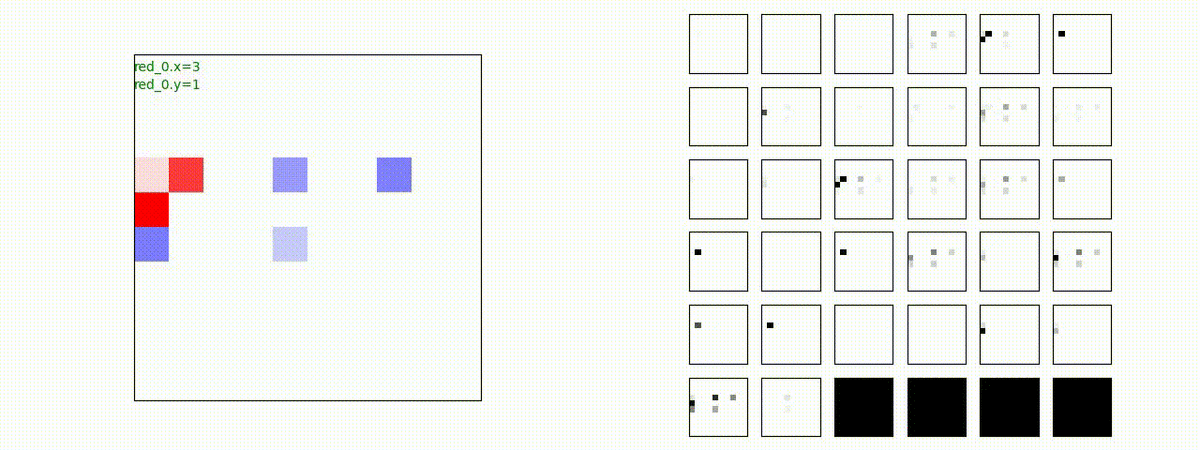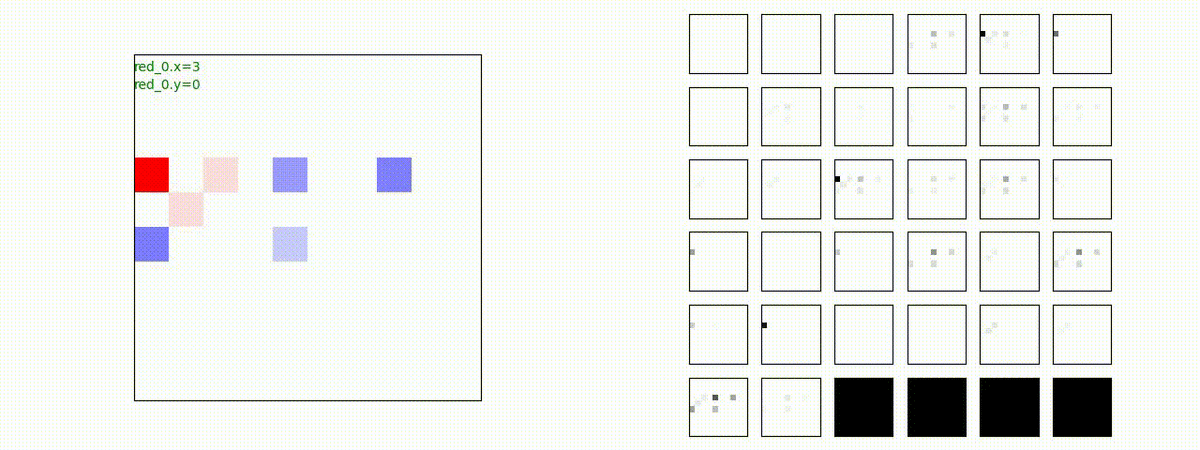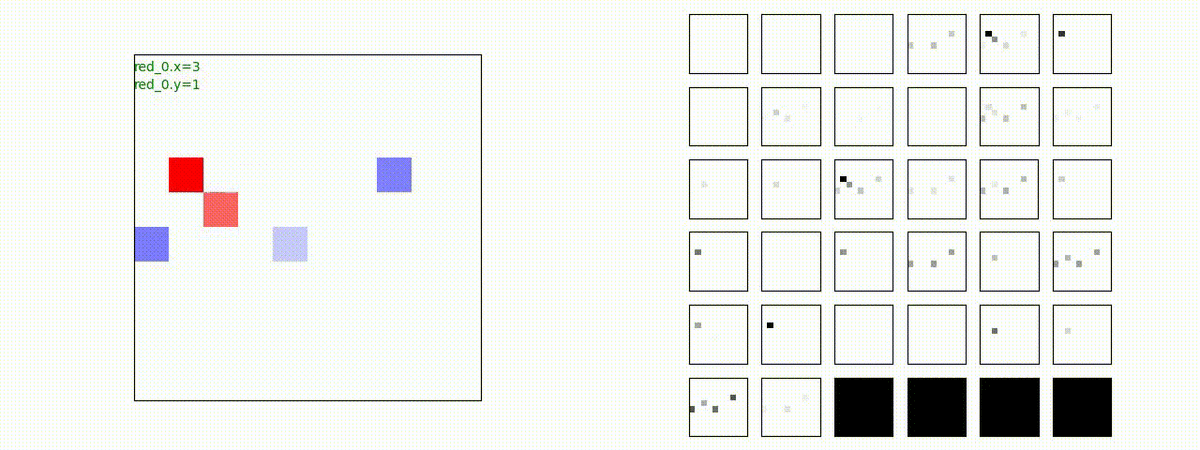
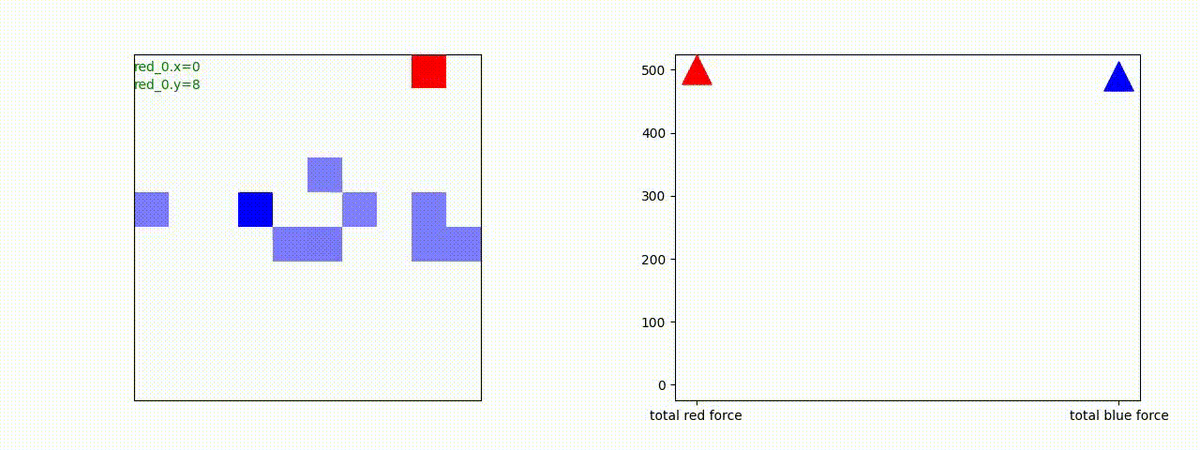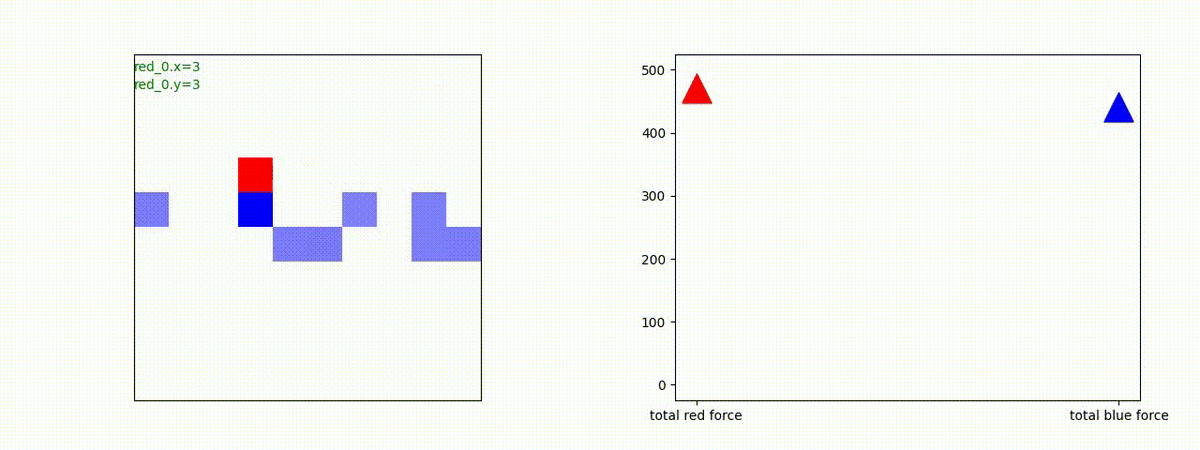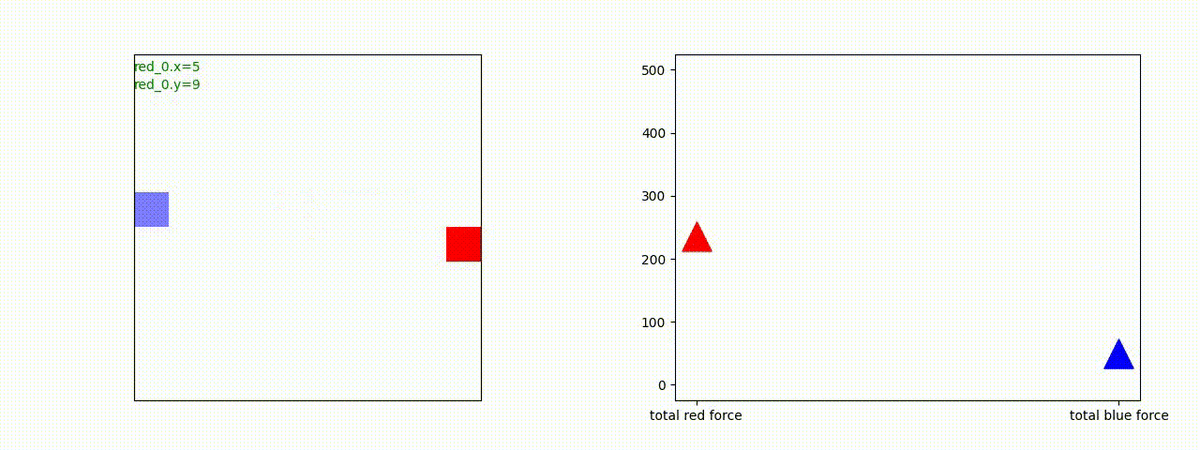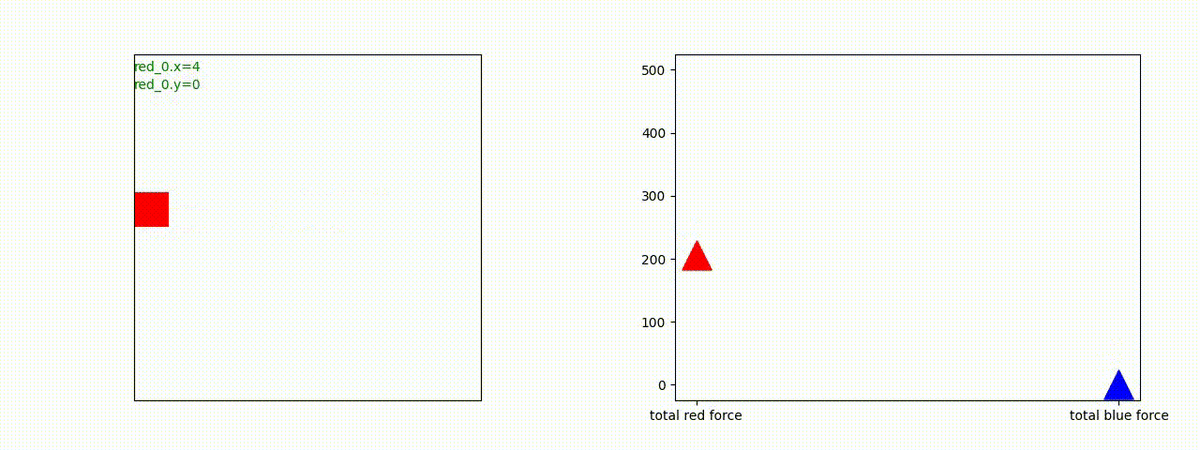
Red_team=10 swarms vs Blue_team=1 swarm
戦域に小分けになって散開した Red teamが、1つの巨大な戦闘力を有する Blue team と戦うシナリオです。Red team の各エージェントは、mass を重視した大きな戦闘力となるよう自律的に集合して来るのですが、後一歩タイミングを揃えることがでないために、わずかの差で Blue team に撃破されます。他のケースも、いくつか調べたのですが、同様の傾向が見られました。
やはり、強化学習はタイミングのコントロールは、あまり得意ではないようです。
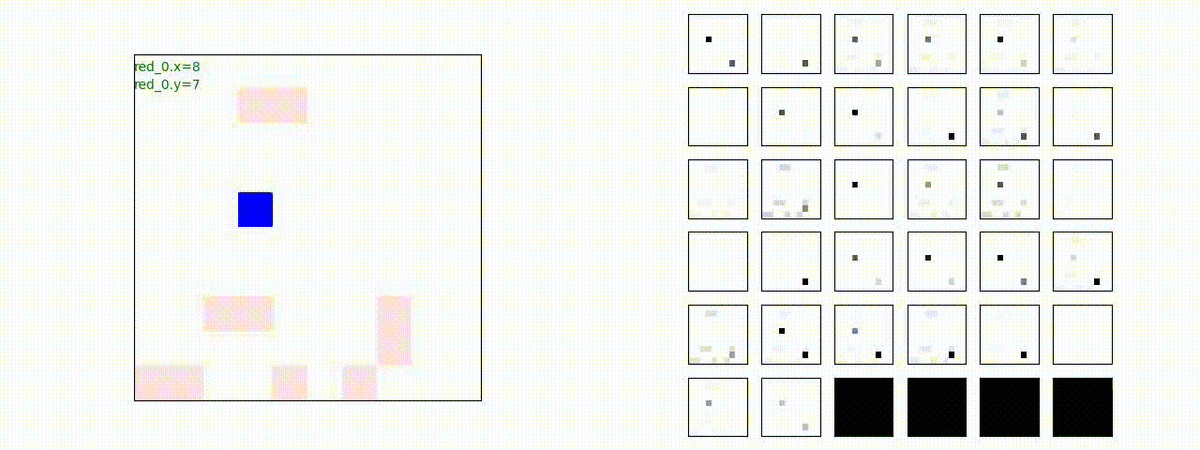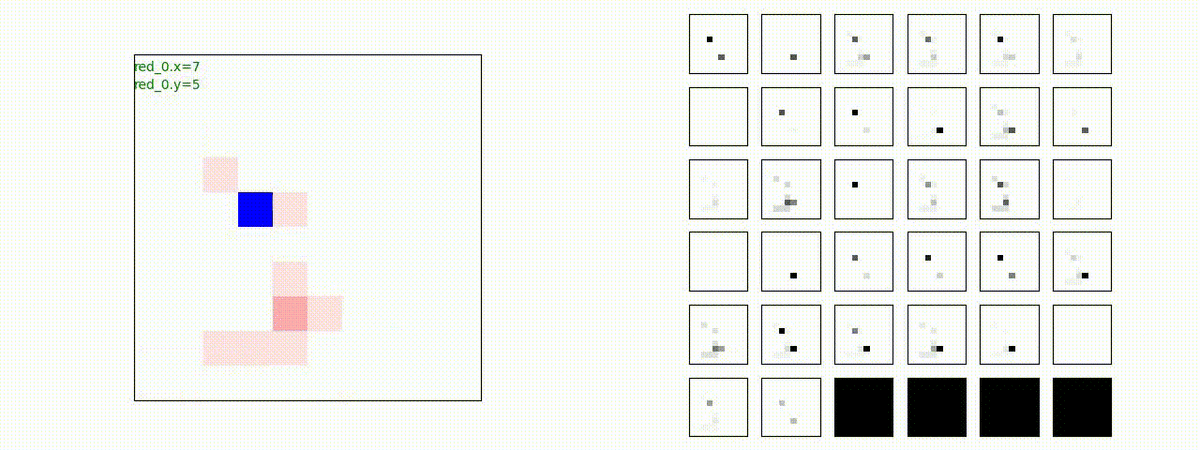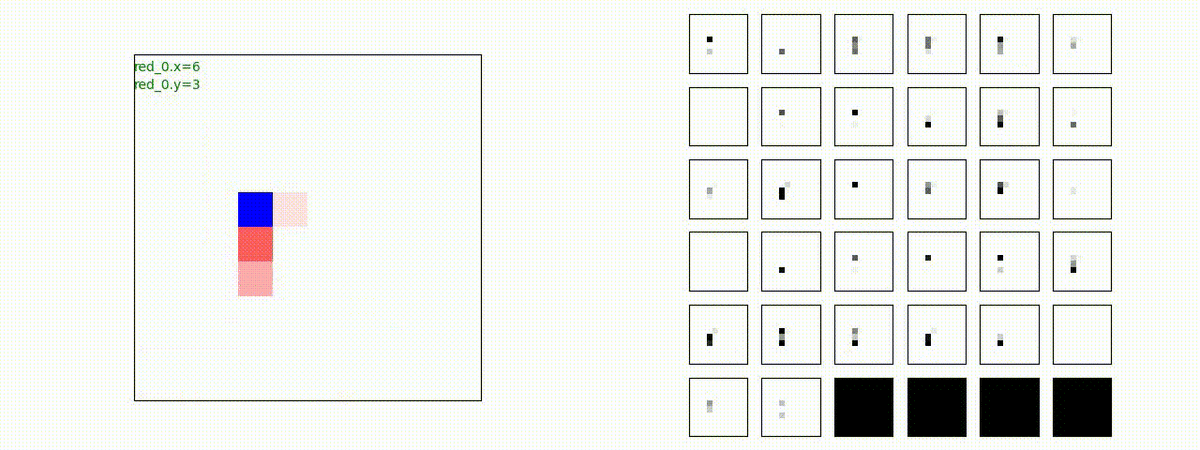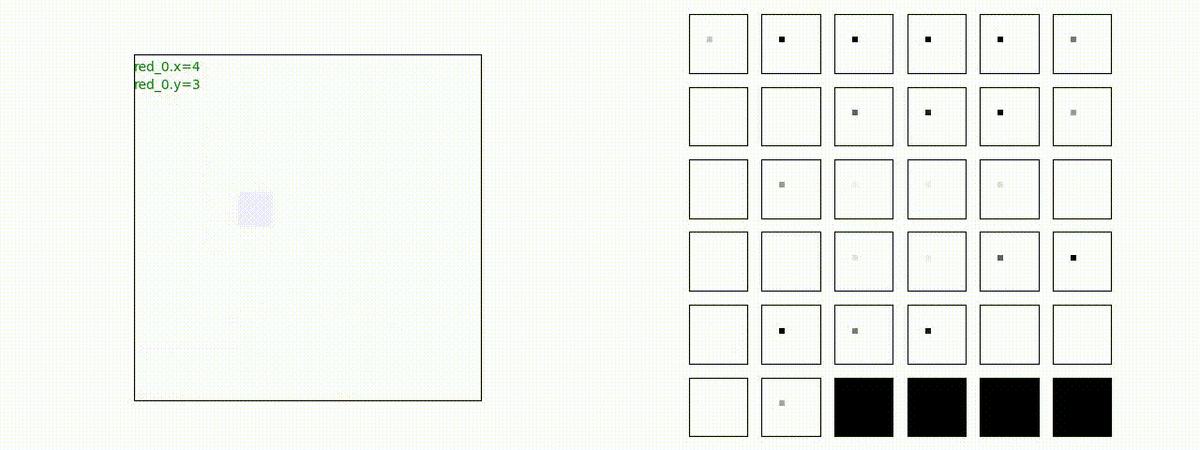
Red_team=10 swarms vs Blue_team=10 swarms
以下は、Red team が上手く戦い、Blue team を壊滅させた「レア」ケースです。
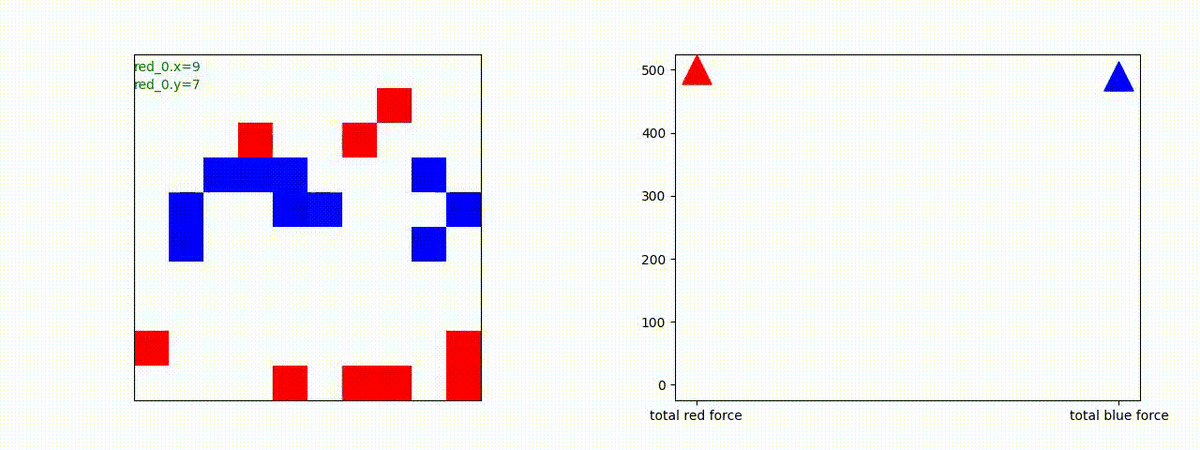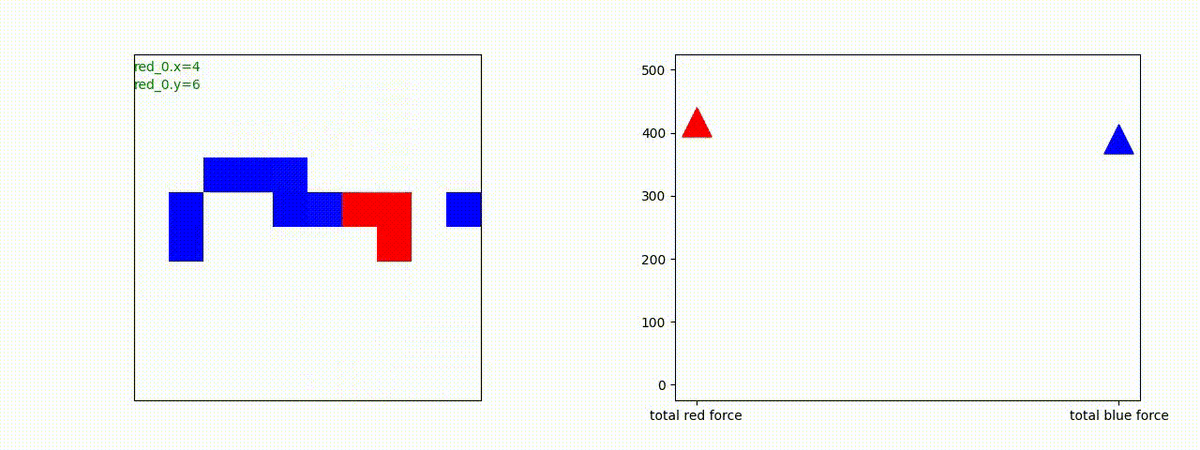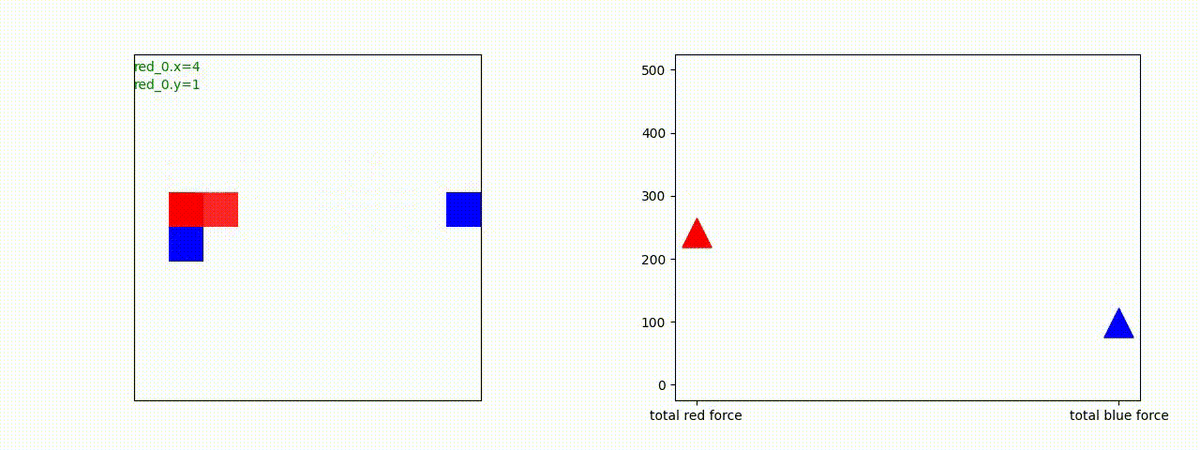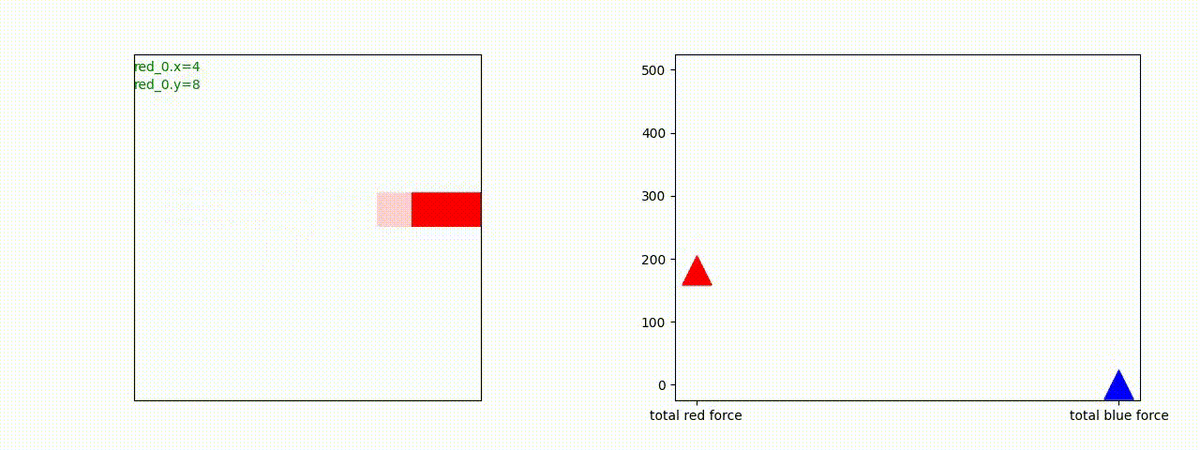
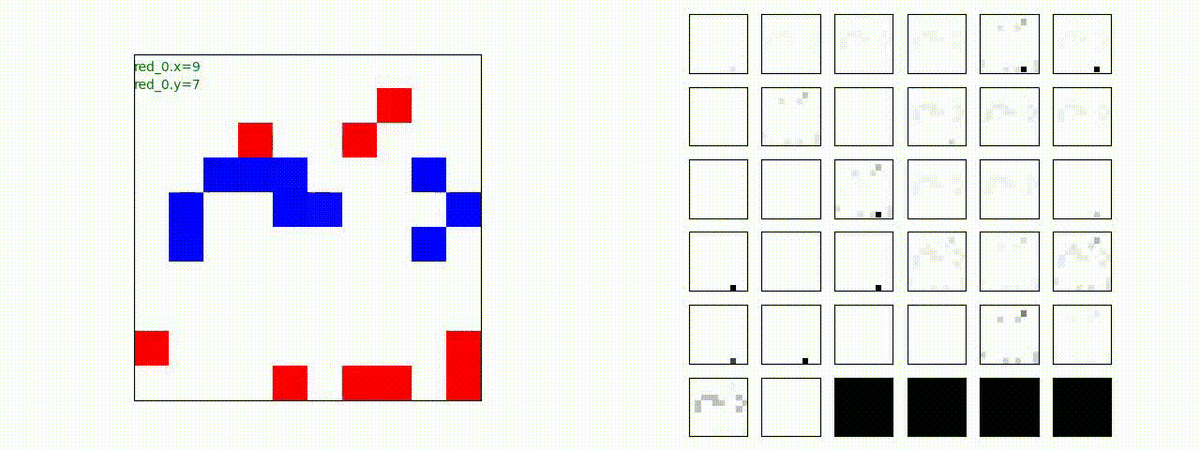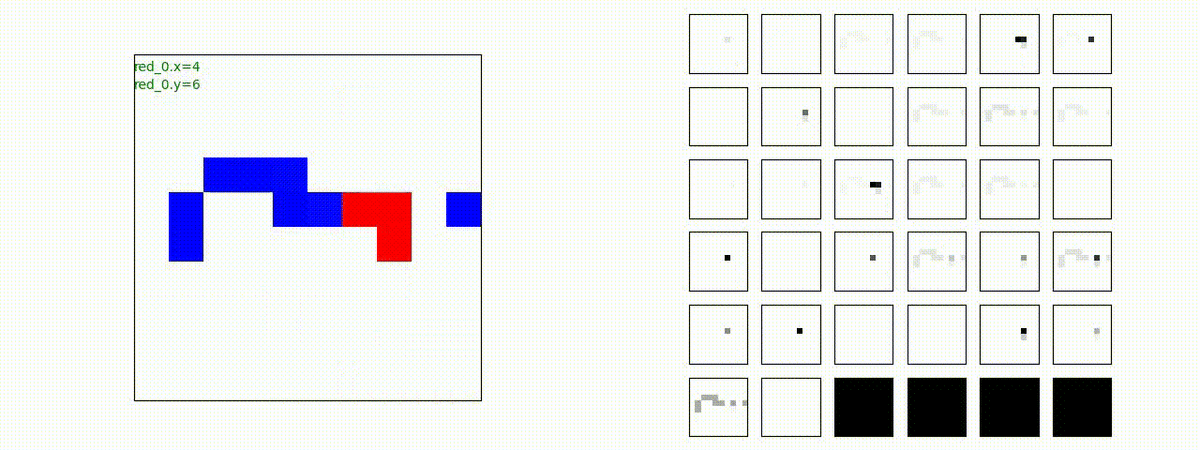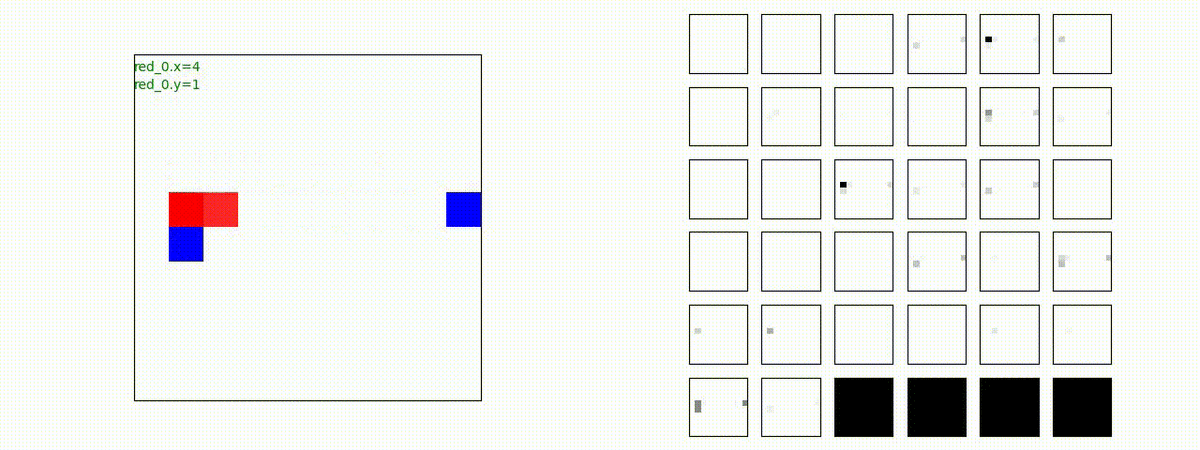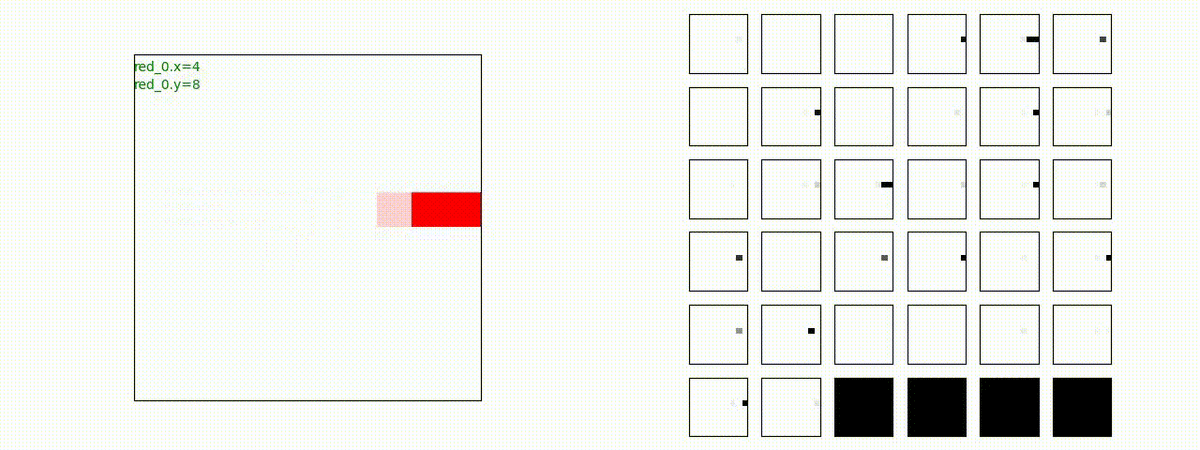
多くの場合、上手くは行かず、Red team のエージェントは、時間切れになるまで右往左往します。途中までは、上手く戦っているのに、途中から右往左往してしまいます。この段階で、Red team の戦闘力は、Blue team よりも高く、Red team = 2, Blue team=4 という戦闘様相になっているので戦えないことはないと思うのですが・・・。ここは、もう少し分析すると改善点がでてくる気がします。
Red team=1 swarm vs Blue tem=10 swarms
小分けになった Blue team を強大な Red team の swarm が順番に撃破していくケースで、「敵を撃破する」というコンセプトは、きちんと学習できていることを確認しました。
上記の両極端な例以外の戦闘様相における生成された戦術の例を以下に示しておきます。
Red team = 3 swarms vs Blue team = 3 swarms
これくらいの外挿は全く問題ありませんでした。
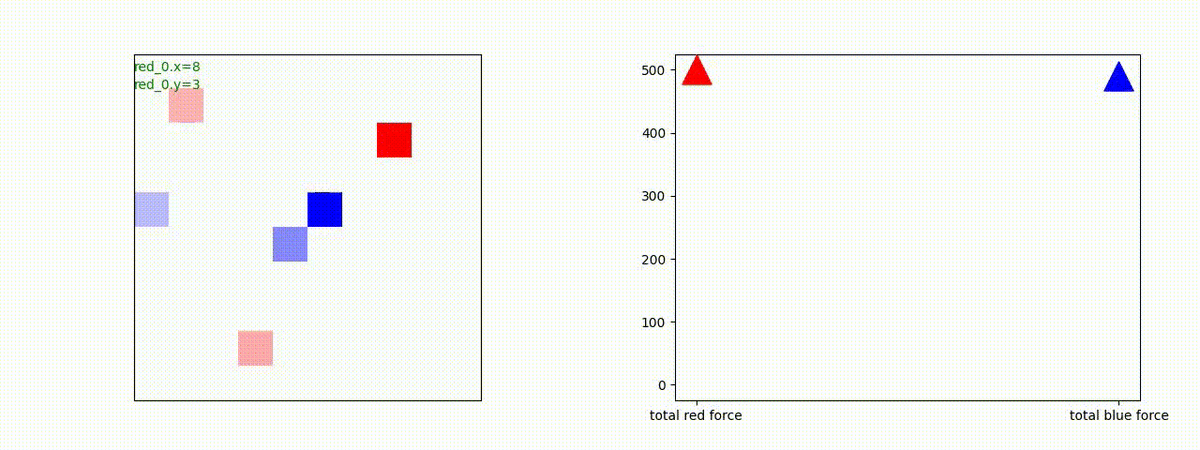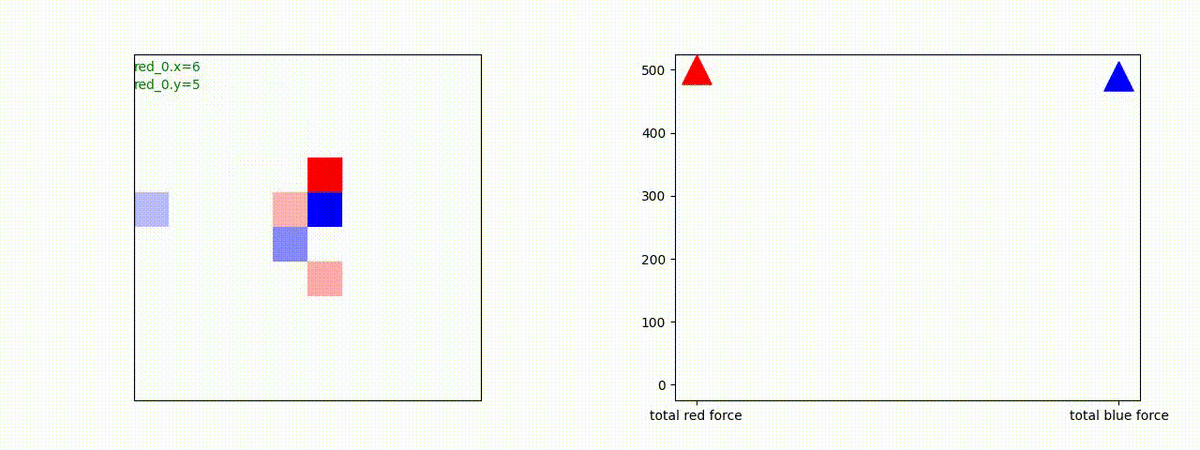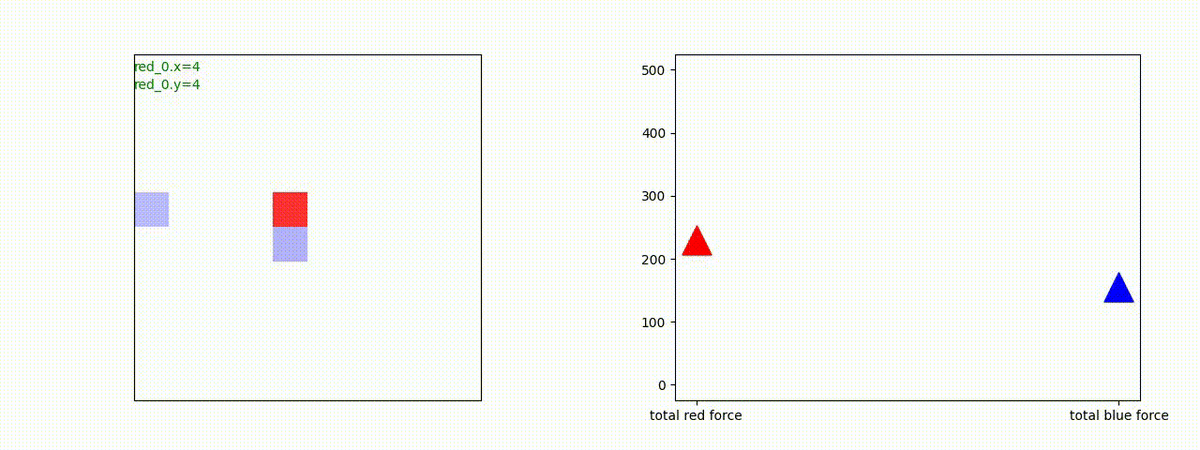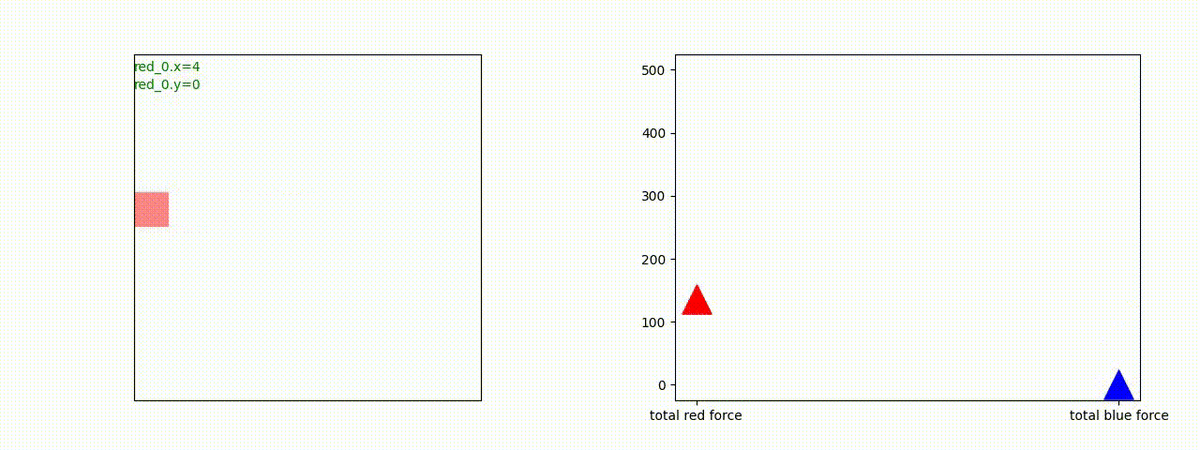
Red team = 5 swarms vs Blue team = 5 swarms
これくらいの戦闘様相までは、red teamのエージェントは、一つの "mass" となって戦うことができます。
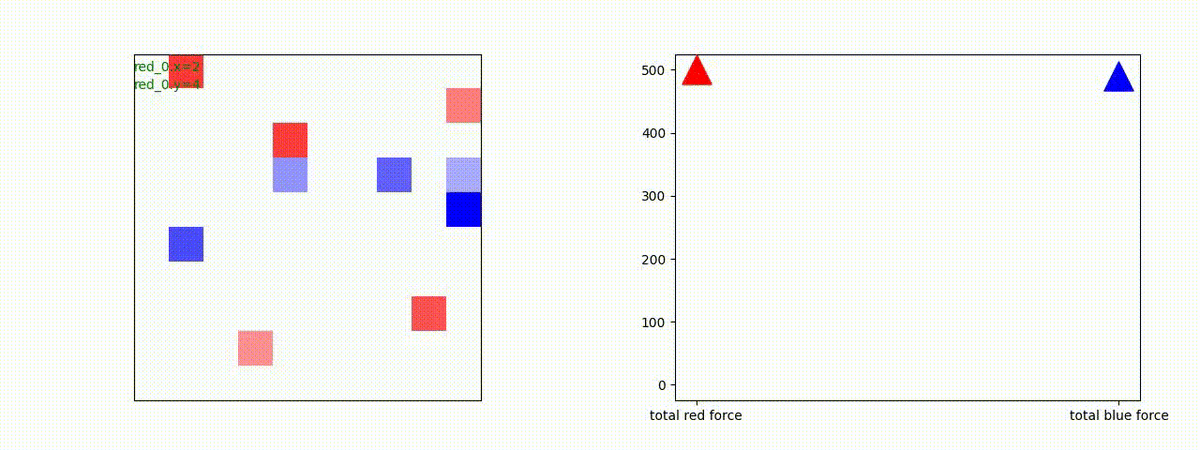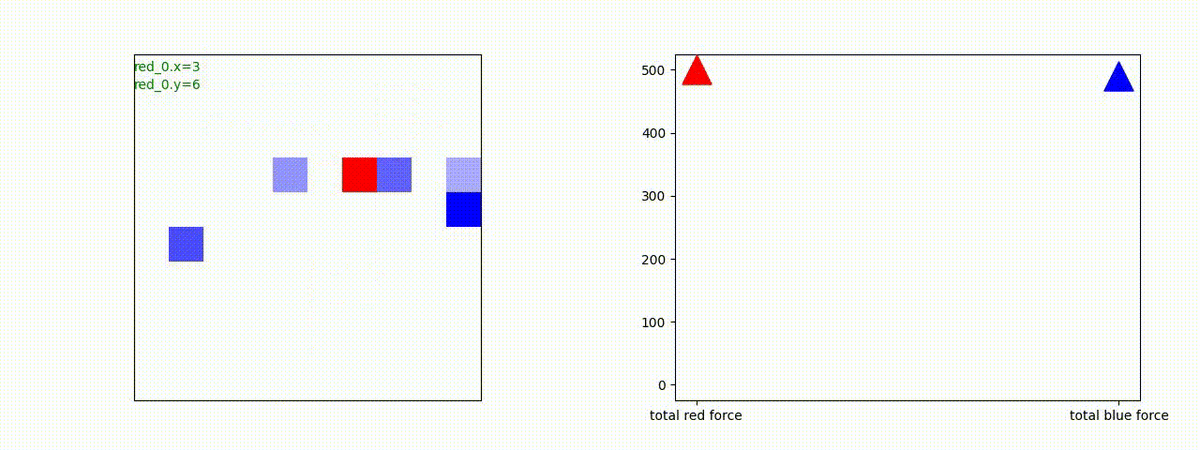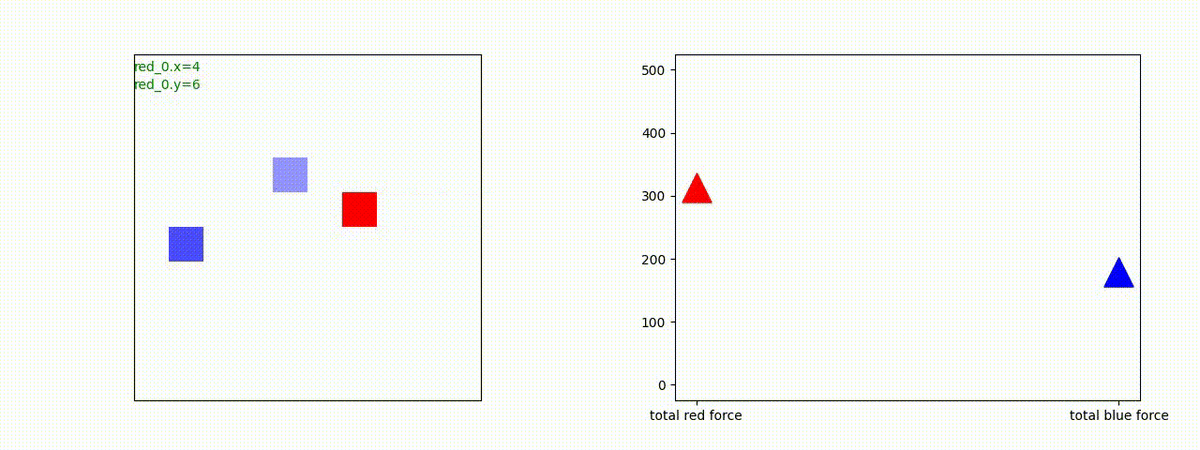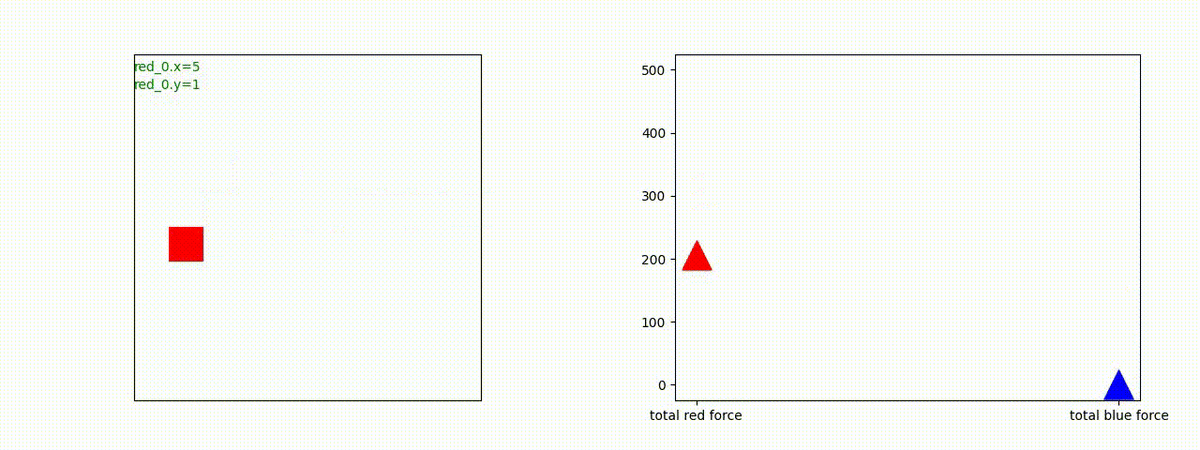
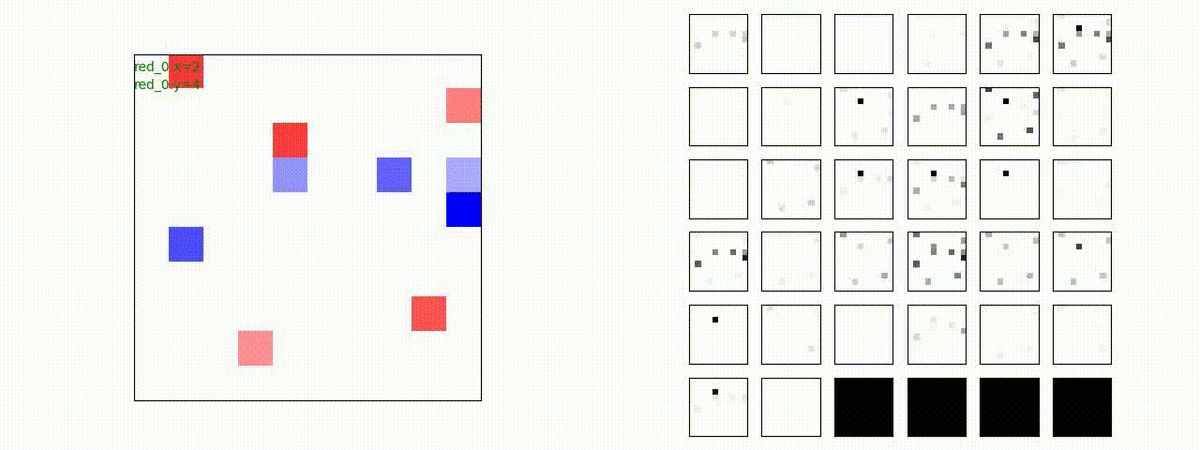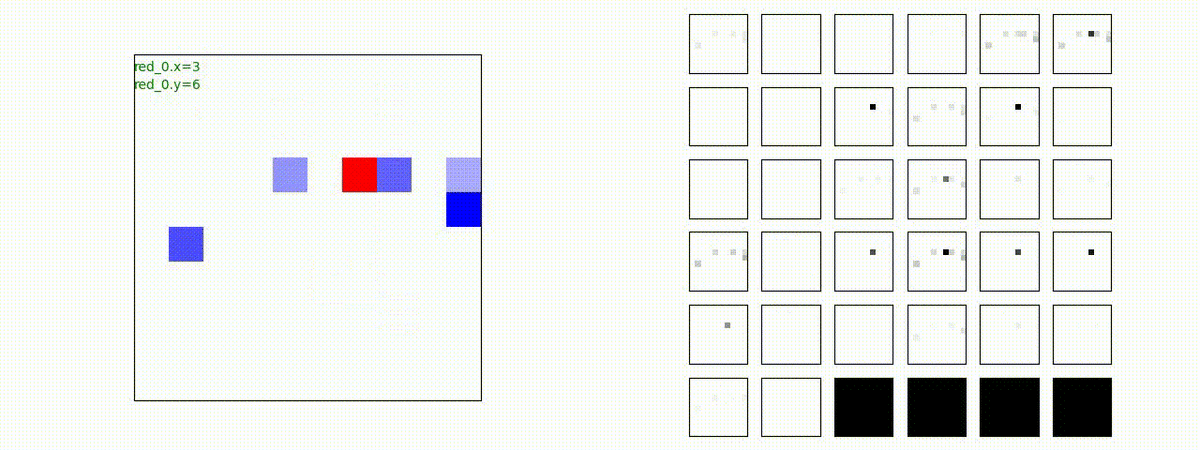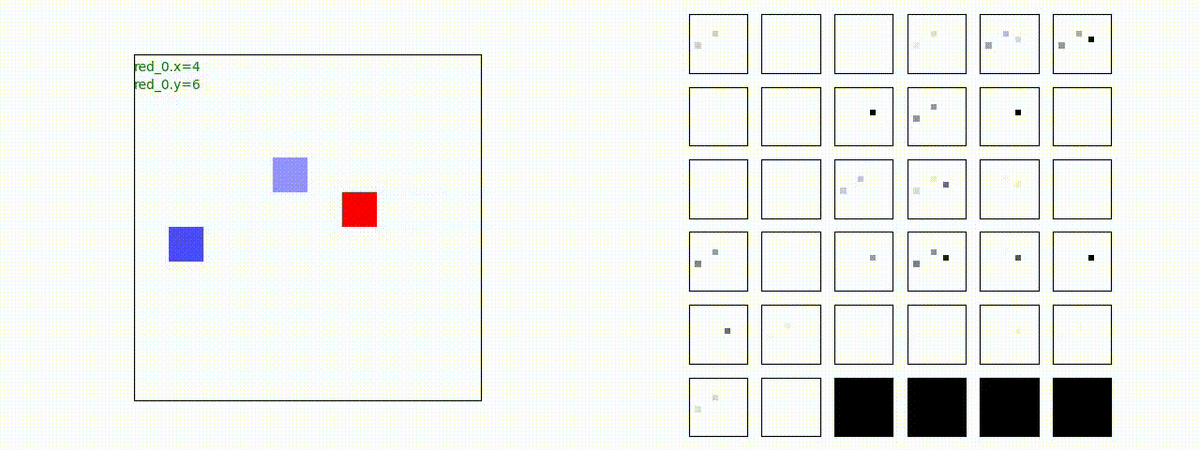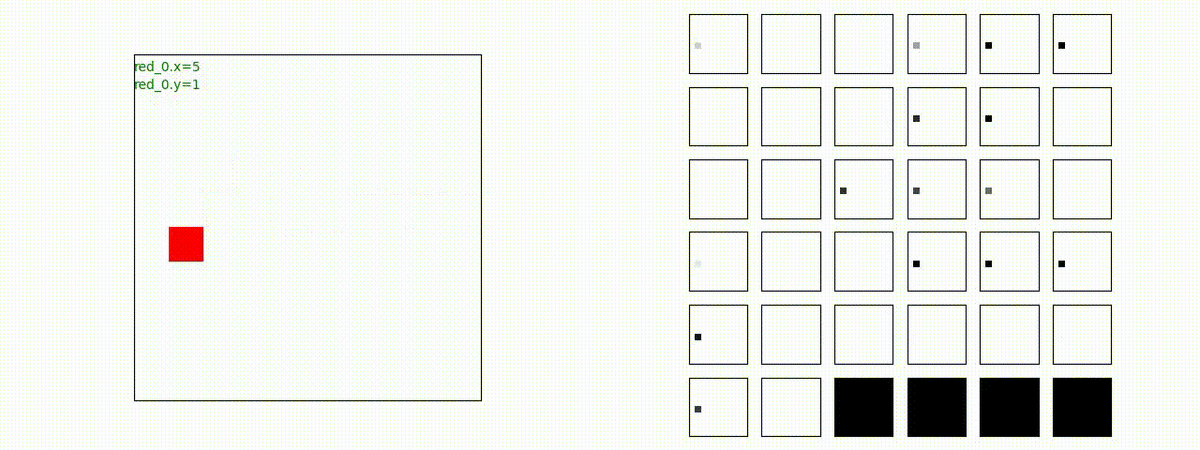
Red team = 8 swarms vs Blue team = 7 swarms
一つの mass とまでは行きませんが、上手く戦うことができます。初期マップで Red team が 7 エージェントになっていますが、これは同一マスに2エージェントが居るためです。
まとめ
- Red team の初期エージェント数(群数)を [1, 3]、Blue team の初期エージェント数(群数)を [1, 2] として、少数群 vs 少数群の設定でネットワークをトレーニングし、その性能を評価しました。トレーニングに使用した条件下であれば、各エージェントは、"mass"を構成して戦う戦術を学習できていることが判りました。
- ロバスト性(汎化能力)を測るために、トレーニング後、(チーム全体の初期総兵力数はトレーニング時と同じに保ったまま)、各チームのエージェント数(群数)を増やして(つまり、戦力を小分けにして散開させて)戦闘性能がどの程度劣化するのか見てみました。
- Red teamのエージェントは、彼我のエージェント数がトレーニング時の2倍強程度までの外挿であれば、問題なく "mass" を活かした戦術で戦うことができました。
- 「10 read team swarm vs 1 blue team swarm」のように、巨大な兵力の Blue team に対し、小分けされる方向に外挿された状況では、Red team のエージェントは、タイミングコントロールが後一歩及ばないため、”mass"を活かした戦術で戦うことができなくなりました。
- 「10 read team swarm vs 10 blue team swarm」のように、彼我のエージェント数がトレーニング時よりも遥かに増えると、Red team のエージェントは右往左往し始め、上手く戦うことができませんでした。
次回記事では、今回とは逆に、Red team, Blue team のトレーニングを多数群 vs 多数群で行い、少ないエージェント数に対するロバスト性(汎化能力)を図ってみたいと思います。