マルチエージェント強化学習を使って、複数群 vs 複数群のための協調戦闘戦術を生成してみる(その1):はじめに
追記@2021.10.08を書いた時に、なぜかフォーマットが乱れていました。修正しました。ゴメンナサイ
- はじめに
- (マルチエージェント)強化学習の研究例
- 研究の目的
- 群 vs 群の戦闘モデル(ランチェスター・戦闘モデル)
- 使用するマルチエージェント強化学習
- まとめ
- 追記 @2021.10.08
- 追記 @2023.03.04
Keyword
Swarm, Company, Platoon, Autonomous, Mass, Consolidation of force, Economy of force, Multi-agent, Reinforcement learning, Lanchester combat model, DenseNet, ResNet, PPO
群、小隊、中隊、兵力、戦闘効率、マルチエージェント強化学習、自律システム
はじめに
未来の戦闘では、多数のロボットやドローン等が中隊や小隊といったひとまとまりの「群(swarm)」を構成し、さらに複数の群が戦域の複数ヶ所に散開して、何らかの戦略や戦術に従って自律的に協調行動することが期待されます。 ここで、「自律的」とは、上位組織から指示されることなく自らの決心で行動することを意味しています。(より正確には、「自らのセンサで情報を収集する」ことも含むべきですが、問題を簡単にするために、しばらくの間はこの仮定は外しています)。
本記事では、これらの戦場に散開した自律的な中隊や小隊レベルの「複数群 vs 複数群」の戦闘を考え、マルチエージェント強化学習を使って効果的な「自律群間の協調戦闘戦術」を生成することを試みます。もう少し軍隊風に言えば、敵を殲滅するために、戦域に展開した自律的な中隊や小隊の動き方を生成することを試みます。マルチエージェントの枠組みで考えますので、戦術を中隊や小隊に与えて、それに従って動かすのではなく、中隊や小隊が自律的に決心した結果として戦術が創発します。
実際には、群の行動を実現するためには、群を構成する個々のメンバー(ロボットやドローン)の行動設計も必要となりますが、ここではそこには踏み込みません。群の構成メンバーは、群の決心に従って自律的に動くことを仮定しています。(これについては、複雑系の観点からのアプローチとしては、群を構成する個々のドローンに Boids と Subsumption architecture の技術を適用して、指示通りに群全体を動かす "Search and rescue with autonomous flying robots through behavior-based cooperative intelligence" 等が参考になるものと考えます。また、強化学習を使った、Guided Deep Reinforcement Learning for Swarm Systems等のアプローチも参考になるものと思います)。
追記2020.10.9: DARPAのOFFSET(Offensive Swarm-Enabled Tactics)プログラムでも似たことをやっていて、Northrop Grammanによる実証実験が間もなく行われるようです。ワクワクします。
(マルチエージェント)強化学習の研究例
マルチエージェント強化学習は、学習が困難なことで知られています。その原因の一つは、同じ環境で他のエージェントも学習しているため、環境が非定常になることです。このため、COMA (2017), MADDPG (2018), QMIX (2018) 等のかなり凝った手法が提案されていますが、未だ決定打ではないと感じています(個人の感想です)。
一方、力づくで、多数のエンティティ(ここでは登場者)を扱った強化学習の研究としては、RTS(Real Time Simulation) ゲームを対象とした Alpha Star (DeepMind, 2019), Dota II (OpenAI, 2019), Hide & Seek (OpenAI, 2019) 等が有名です。これらは、いずれも初見でかなりの衝撃を覚えましたが、とにかく力ずくなので、残念ながら趣味でちょっと実装してみるというレベルのコードやトレーニング用ハードウェア構成ではありません。Google や OpenAI レベルのリソースが必要です。ただ、いずれも優れたアイデアが満載ですので、とても参考になりました。
AlphaStar では、中央制御によるプランニングにより、多数のエンティティをコントロールして、RTS ゲームの長期に渡る複雑なプランニングを強化学習しています。その結果、プロのゲーマを上回る性能を達成しました。(この研究では、リーグ戦方式の対戦で強化学習することをマルチエージェント強化学習と呼んでいるので、普通のマルチエージェント強化学習とはイメージが異なります。)
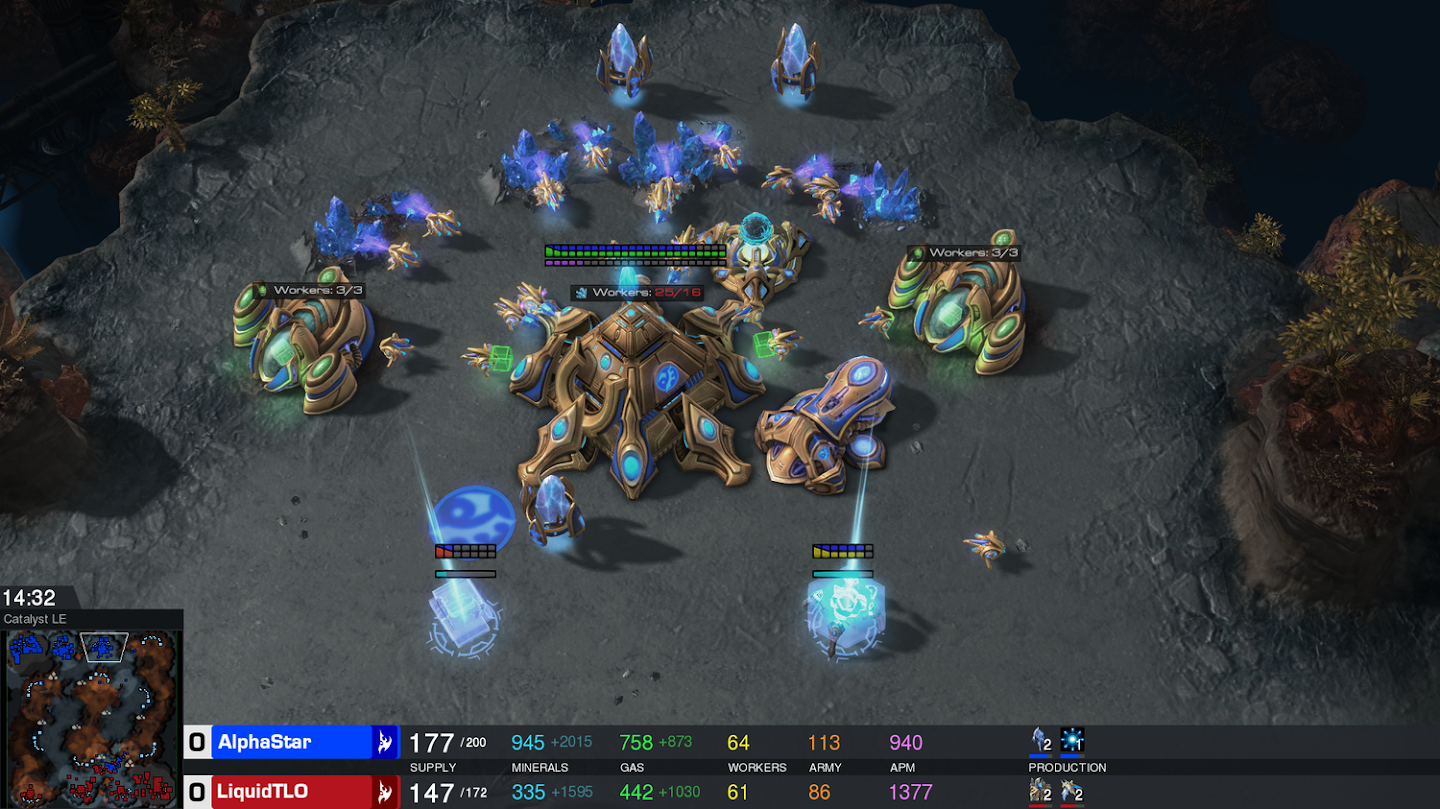
Dota IIでは、5つのキャラクター(エージェント)を選択し、これらのエージェントをマルチエージェント強化学習することで、ゲーマーのグランドマスター・レベルの性能を達成しています。学習にはDPPO(Distributed PPO)を使っています。実験では、5つのAI vs 5つのAI, 5つのAI vs 5人のゲーマー、AIとゲーマーの混合チーム vs AIとゲーマーの混合チームの対戦を行っています。興味深いのは、 AIとゲーマーの混合チームの対戦において、ゲーマーが「AIの方が人間よりも協力的だった」とコメントしていることです。

Hide and Seekでは、任意のマップにおける複数の自律エージェントの協調制御をマルチエージェント強化学習しています。これも学習にはDPPO(Distributed PPO)を使っています。これはエージェントがとてもキュートです。エージェントのアーキテクチャには、Transformer ですっかり有名になったアテンション機構が空間的に使われていて勉強になりました。ただし、エージェント数は 2 vs 2 なので、多数とまでは言えません。
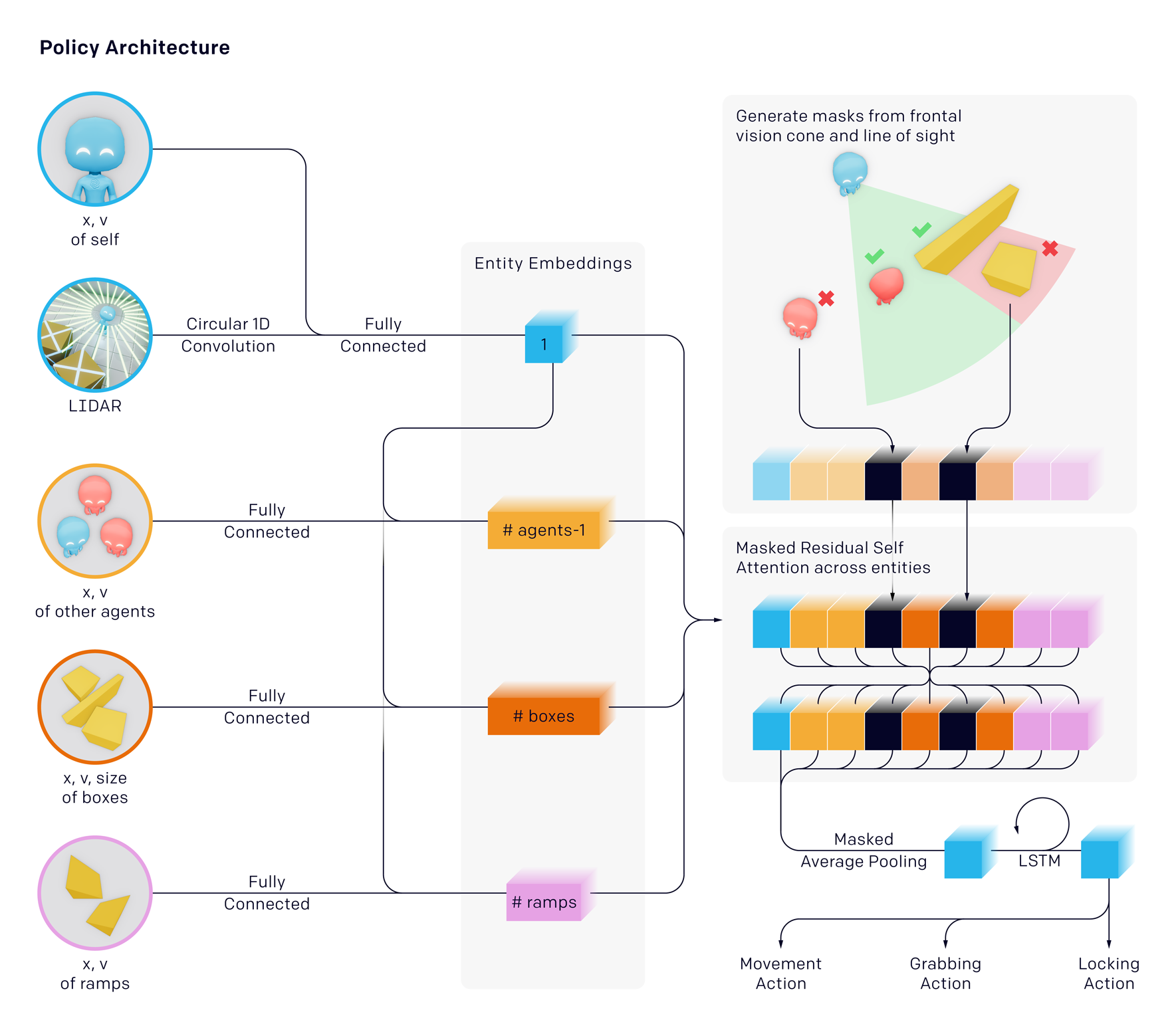
これらの華やかな成果を受けて、遅まきながら諸外国の軍関連の機関でも強化学習の応用研究が進められています。(マルチエージェント強化学習の応用研究は、軍事ではまだ見たことがありませんが、きっとやっていると思います)。
複数エンティティによる戦闘プランニングを強化学習した研究には、ランド研究所の "Air Dominance Through Machine earning: A Preliminary Exploration of Artificial Intelligence–Assisted Mission Planning" (機械学習による航空支配), 2020 が挙げられます。これについては、実装も含めて下記記事として纏めています。この研究自体の方向性は AlphaStar に近いもので、中央集権的なエージェントによる複数エンティティのプランニングになっています。軍事では、任意数のエンティティを取り扱えることは重要です。このレポート自体は任意数のエンティティを取り扱うものではありませんが、将来研究の項で、戦場をグリッドに分割し、任意数のエンティティを取り扱う構想が述べられています。このアイデアは参考になりました。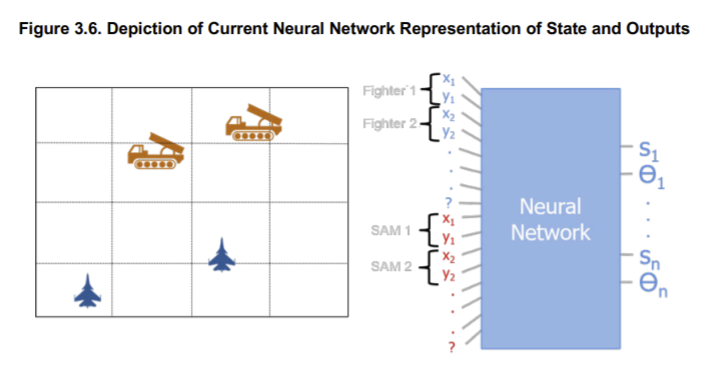
ランド研究所のレポートと同様の方向をめざした研究としては、強化学習により、複数のSUV(無人艦艇)の編隊ナビゲーションをプランニングするUniversity Collage of London のチームの研究(2019)が挙げられます。
ランド研究所のレポートと同様の方向をめざした研究としては、強化学習により、複数のSUV(無人艦艇)の編隊ナビゲーションをプランニングするUniversity Collage of London のチームの研究(2019)が挙げられます。
US Marine Corps(海兵隊)の研究 "Developing Combat Behavior through Reinforcement Learning in Wargames and Simulations", 2020 では、中隊(company)、小隊(platoon)レベルの戦闘行動を、強化学習により生成することを試みています。
今回は、これを大いに参考にしました。この研究では、戦闘をターン制のゲームとしてとらえ、タイムステップ当たり1つの中隊又は小隊の戦闘行動を生成するようネットをトレーニングしています。イメージとしては、「信長の野望」をAI化したと思えば近いものになります。(私が知っている「信長の野望」は数十年前のものなので、最近は変わっているかもしれません)。
ターン制なので、登場エンティティ数が多ければ多いほど、小隊・中隊の行動が一巡するのに時間がかかってしまうため、実際の戦闘とは異なったものとなってしまいます。これを避けるために、この研究では、後に述べるランチェスター・モデルの戦闘効率をかなり小さく採って、影響が現れないようにしていました。これは、シミュレーションのタイムステップを非常に小さく採っていることと同等なので、1回のシミュレーションに要する時間が長くなるという問題があります。(つまり、計算リソースが無い私のような趣味人には厳しい)。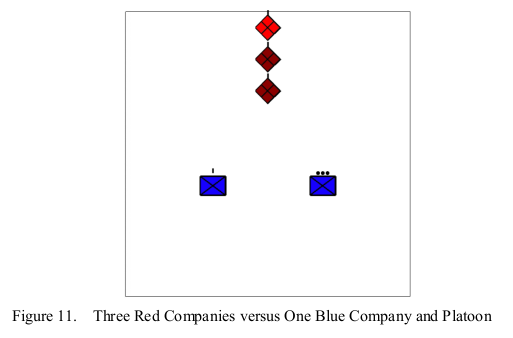
この海兵隊の研究では、学習した戦術を "Mass"(集中)と "Economy of Force"(力の経済性)の観点から分析している点が海兵隊らしく面白いと思いました。"Mass" と、"Economy of Force" は、海兵隊教本 MCDP "1-0 Operations" において、それぞれ以下で定義されています。
Mass:決定的な結果をもたらすために、決定的な場所と時間に友軍能力を集中すること。力の統合(Consolidation of Force)
Economy of Force:プライマリーな目的を達成するために、最小限必要な戦力(Minimum essential combat power)を副次的な目的に割り当てること
研究の目的
本記事では、これらの軍事研究と DeepMind や OpenAI の研究等とを参考にして、問題をマルチエージェント強化学習のセッティングにすることで、戦場に散開した複数の群(swarm)の自律的な協調戦闘戦術の生成を試みました。最も類似している研究は、海兵隊の研究ですが、ターン制ではなく、マルチエージェントによる協調問題として解くことで、多数の群が同時に自律行動できるようにしました。
また、マルチエージェント強化学習のフレームワークとすることで扱える群の数も任意数となりました。解こうとしている最終的な問題環境、自群、友群、敵群の各種情報が、2次元地図(n x nでグリッド化)に表現されているものとします。群の一番判りやすいイメージは、海兵隊の研究で使われている中隊、小隊です。以下では、「我」を Red team、「彼」を Blue teamとし、各チームは大きさ(構成メンバー数)と保有する武器が異なる複数の群で構成されているものとします。
また、便宜上、各群をエージェントと呼ぶことにします。したがって、Red team, Blue teamは夫々複数のエージェントの集合体になります。
※ 本稿では、群の構成メンバーの戦術ではなく、「群の戦術」を生成するのが目的なので、群の構成メンバーがエージェントではなく、群=エージェント、複数の群=マルチエージェントと呼ぶことに留意してください。勿論、極限として構成メンバーが一人の群を考えれば、生成される戦術は群の構成メンバーの戦術とみなすこともできますが、それを特に企図している訳ではありません。
目的は、これらエージェント(群)が、取得したマップから自律的に戦況を判断して行動し、敵のエージェント(群)を殲滅する戦術を強化学習により学習することです。自群をagent-i、自群以外の友群を{agent-j, j≠i}とします。また、エージェントの兵力数(群の構成メンバー数)をForce、群の戦闘効率(武器性能)をEfficiencyと呼ぶことにします。
Force は戦闘によってランチャスター・モデル(後出)に従って消耗して行きますが、Efficiencyは戦闘期間を通じて一定の値をとるものとします。
グリッド化されたマップには、自群、友群、敵群、環境等の各種情報が、別々のマップとして表現されるものとします。具体的には、下図に示すように、各マップが夫々別の特徴量を表すものとします。この辺りのマップ化は、AlphaZero のチェスや将棋を参考にしました。
1) 自群位置、自群兵力(agent-i force)、自群戦闘効率(agent-i efficiency,)
2) 友群位置、友群兵力、友群戦闘効率(戦域に異なる戦闘効率の群が混在する時は、戦闘効率毎にマップ化されているものとします)。
3) 敵群位置、敵群兵力、敵群戦闘効率
4) 環境情報(壁のように通過できない建造物の位置を示すマップ、川や沼のように通過は出来るが、通過時に戦闘効率や移動速度が低下する環境位置を示すマップ等で、これらは環境の種類・特性ごとにマップ化されているものとします)。

戦闘目的によっては、さらに、防護エリアマップ、ターゲット・エリアマップ等のような目的を表すマップが追加で与えられるものとします。
自群、友群、敵群、環境等をマップで表すメリットは幾つかあります。
- 任意数の敵群エージェント数(群数)を取り扱うことが可能です。
- 自群と友群を別のマップにすることで、任意数の友群エージェント数(友群数)を取り扱うことも可能になります。
- 自群と友群を別のマップにすることで、自律システムに適したマルチエージェント設定で問題を解くことが可能になります。
- 数値で表すよりも簡単に、複雑な環境や戦闘目的を、表現することが可能です。これは、人と自律システムが会話する際の重要な要件だと思います。
一方、ディメリットは、(マルチエージェント)強化学習が困難、或いは長時間かかるようになることです。Ai にとって、例えばマップ上で位置を認識することは、(x, y)座標値で位置を認識するよりも、ずっと困難です。
これらのマップは、それぞれ nxn の2次元配列(nxnx1 のテンソル)になるので、マップが c 枚ある時は、エージェント(群)に与えられるマップ全体は nxnxc のテンソルとして与えられることになります。群が自律群(Autonomous swarm)であれば、これらのマップは、エージェント自身が有するインテリジェント・センサによって取得されます。一方、非自律群(Non-autonomous swarm)であれば、群を指揮統制する C4I 系(Command, Control, Comunication, Control and Intelligence)から通信を介してマップが与えられます。(実際は、両者の中間になると思います)。
いずれの場合も、(特に、自身のセンサで取得する場合は)、マップ情報は、エージェント毎に異なる可能性があります。したがって、部分観測マルコフ決定過程(POMDP, Partially Observable Markov Decision Process)と呼ばれる、もう一つの厄介さがさらに追加になります。
各タイムステップで、各エージェントは、これらのマップ情報と学習したポリシーに従って、東西南北いずれかへの移動、又は移動しないの5択から群としてのアクションを決定します。このアクションのシーケンスが、群の戦術ということになります。
この際、エージェント間(群間)には通信が無いものとします。(最前線にいるエージェント間に通信ネットワークがあるという仮定は、電子戦の時代には無理な気がします)。このため、各エージェントの決心は、同じタイム・ステップでは他のエージェントには判りません。他エージェントの決心は、あくまで次タイムステップで取得したマップからのみ認識できることになります。つまり、他エージェントの決心を知るまでには時間遅れが生じます。
したがって、各エージェントは、他エージェントの意図をマップから予測してアクションを起こす必要があります。つまり、エージェントの協調行動は、「阿吽の呼吸」として創発される必要があります。
なお、Red team と Blue team は、同じグリッドに入ると自動的に戦闘を開始し、同じグリッドにいる間は戦闘を継続するものとします。
群 vs 群の戦闘モデル(ランチェスター・戦闘モデル)
群 vs 群の戦闘モデルとしては、海兵隊の研究と同様にランチェスターモデルを用います。このモデルは決定論的(Deterministic)ですが、海兵隊の研究では確率論的(Stochastic)なモデルも検討されています。今回は、問題をシンプルにするために、オリジナルの決定論的なランチェスター・モデルを用います。
ランチェスター・モデルでは、x を自群の兵力(Force, 構成メンバー数)、y を敵群の兵力、α を自群の戦闘効率(Efficiency, 武器性能)、β を敵群の戦闘効率、Δt を経過時間(タイム・ステップの大きさ)とすると、自群、敵群の兵力の消耗量 Δx, Δy は、それぞれ以下で与えられます。
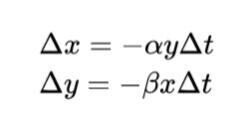
時間経過 Δt が小さい場合、上式は常微分方程式で近似出来ます。
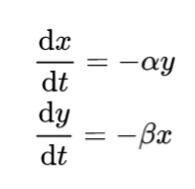
ランチェスターモデルから導出される重要な結果の一つが、分割戦略です。
これは、戦闘力が小さな軍隊でも、何らかの方法で敵を分割することが出来た場合は、順繰りに敵を個別撃破していくことで、最終的に勝利を収めることが出来るというものです。これは、海兵隊の "mass" と "economy of force" の基になっている考え方です(と教本に書いてあったと記憶しています)。
下図に、シミュレーションの結果を示します。横軸が戦闘開始からの経過時間、縦軸が各 team の残存兵力です。青ラインが Blue team の残存兵力、橙ラインが red team の残存兵力の遷移を示します。red team の初期兵力は 400、blue team の初期兵力は 500 としています。彼我の武器性能 (efficiency=0.7) は同一としています。したがって、1対1のガチンコ勝負の場合、red team に勝ち目はありません。
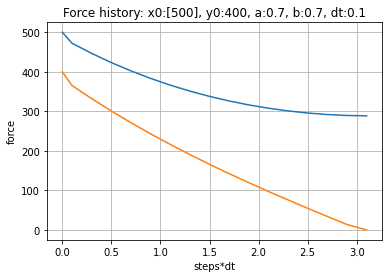
しかしながら、red team が何らかの方法により、blue team を (250,250) の群に2分割できた場合、これらに順繰りに(シーケンシャルに)対処していくことで red team は勝利することが出来ます。シミュレーションは、戦闘中の敵群兵力が消滅したら、次の敵群と戦うと仮定して計算しています。
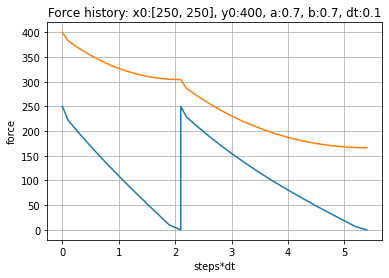
この効果は、blue team を小さな多数群に分割できた場合ほど大きくなります。例えば、blue team の兵力を (100, 100, 100, 100, 100) と5つの小群に分割できたような場合、初期兵力では劣っていた red team が、想像以上の圧勝を得ることになります。
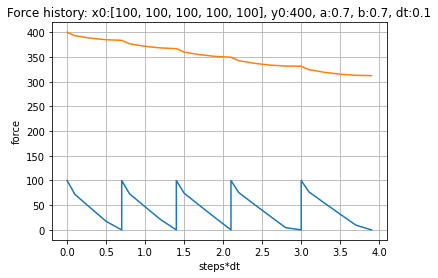
これから、小出しに戦力投入することがいかに不利で、海兵隊が重要視する "mass(consolidation of force)" がいかに重要かが判ります。
以上から、戦場に様々な兵力や戦闘効率のエージェント(群)が散開している場合、勝利を収めるためには、散開した様々な戦力のエージェントは、陽には与えられていないランチェスターモデルを理解し、自己、友群、敵群、環境状況、残存兵力、戦闘効率等をマップから認知・識別し、彼我の動きを阿吽の呼吸で予測して、適切な "Mass" と "Economy of force" を得ることが出来る協調戦術に変換し、各自のアクションとして自律的に実行することを学習しなければならないことが判ります。
これを、「マルチエージェント強化学習の枠組みで学習」させてみようというのが今回の趣旨になります。
使用するマルチエージェント強化学習
今回は、マルチエージェント強化学習に係る初期の論文 "Multiagent Cooperation and Competition with Deep Reinforcement Learning"、(2015) と同じく、最も単純な実装にしました。平たく言えば、報酬設計だけでなんとかしよう、という考え方です。
red team の全エージェントは、同じ一つのニューラル・ネットをブロードキャストしたコピーを持ちます。これは、少し見方を変えると、全エージェントが1つのニューラルネットを共有していることになります。環境とのインタラクション(ロールアウト)時には他のエージェントは環境の一部とみなします。そして、全エージェントが、ロールアウトして収集した遷移情報を使って、確率的勾配法でこの共有しているネットを更新することで学習を進めます。バッチ分のデータを使った更新が終わると、新しいネットのコピーを各エージェントにブロードキャストし、次のサイクルに入ります。
学習後の実行については、エージェントは、自分が持っているニューラルネットのコピーを使って、他のエージェントの決心とは独立して、観測から行動を自ら決心します。
したがって、全体のフレームワークとしては、学習は中央集約的、学習用のデータ収集と学習後の意思決定・実行は自律分散的となります。

まとめ
これから、マルチエージェント強化学習で解こうとしている問題について整理しました。このままでは、少し問題が複雑すぎるので、次回は、この問題をもう少しシンプルにして、初トライとして適当なレベルの問題を設定します。
追記 @2021.10.08
わりと似たことをやっているスタンフォード大のレポートを見つけました。PPOではなく、DQNを使っています。2016年ごろのレポートではないかと思います。
http://cs231n.stanford.edu/reports/2016/pdfs/122_Report.pdf